1.分布式训练的概念
分布式训练(Distributed Training)是指将机器学习或深度学习模型训练任务分解成多个子任
务,并在多个计算设备上并行地进行训练。
一个模型训练任务往往会有大量的训练样本作为输入,可以利用一个计算设备完成,也可以将整个模型的训练任务拆分成子任务,分发给不同的计算设备,实现并行计算。此后,还需要对每个计算设备的输出进行合并,最终得到与单个计算设备等价的计算结果。由于每个计算设备只需要负
责子任务,并且多个计算设备可以并行执行,因此其可以更快速地完成整体计算,并最终实现对整个计算过程的加速。
分布式训练的总体目标就是提升总的训练速度,减少模型训练的总体时间。总训练速度可以使用如下公式计算:
总训练速度∝ 单设备计算速度× 计算设备总量× 多设备加速比
| 条目 | 影响因素 | 优化手段 |
|---|---|---|
| 单设备计算速度 | 单块计算加速芯片的运算速度和I/O能力决定 | 混合精度训练、算子融合、梯度累加等 |
| 计算设备总量 | 分布式训练系统中计算设备数量越多,其理论峰值计算速度就会越高,但是受到通讯效率的影响,计算设备数量增大则会造成加速比急速降低 | 优化加速比 |
| 多设备加速比 | 多设备加速比则是由计算和通讯效率决定 | 结合算法和网络拓扑结构进行优化 |
因此,分布式训练并行策略主要目标就是提升分布式训练系统中的多设备加速比。
分布式训练系统仍然需要克服计算墙、显存墙、通信墙等多种挑战,以确保集群内的所有资源得到充分利用,从而加速训练过程并缩短训练周期。
- 计算墙:单个计算设备所能提供的计算能力与大语言模型所需的总计算量之间存在巨大差异。2022 年3 年发布的NVIDIA H100 SXM 的单卡FP16 算力也只有2000 TFLOPs,而GPT-3则需要314 ZFLOPs 的总算力,两者相差了8 个数量级。
- 显存墙:单个计算设备无法完整存储一个大语言模型的参数。GPT-3 包含1750 亿参数,如果采用FP16 格式进行存储,需要700GB 的计算设备内存空间,而NVIDIA H100 GPU 只有80 GB 显存。
- 通信墙:分布式训练系统中各计算设备之间需要频繁地进行参数传输和同步。由于通信的延迟和带宽限制,这可能成为训练过程的瓶颈。GPT-3 训练过程中,如果分布式系统中存在128个模型副本,那么在每次迭代过程中至少需要传输89.6TB 的梯度数据。而截止2023 年8 月,单个InfiniBand 链路仅能够提供不超过800Gb/s 带宽。
2.分布式并行策略
对于大语言模型来说,训练过程就是根据数据和损失函数,利用优化算法对神经网络模型参数进行更新的过程。单节点模型训练系统结构如图所示,主要由数据和模型两个部分组成。
训练过程会由多个数据小批次(Mini-batch)完成。图中数据表示一个数据小批次。训练系统会利用数据小批次根据损失函数和优化算法生成梯度,从而对模型参数进行修正。针对大语言模型多层神经网络的执行过程,可以由一个计算图(Computational Graph)表示。这个图有多个相互连接的算子(Operator),每个算子实现一个神经网络层(Neural Network Layer),而参数则代表了这个层在训练中所更新的的权重。
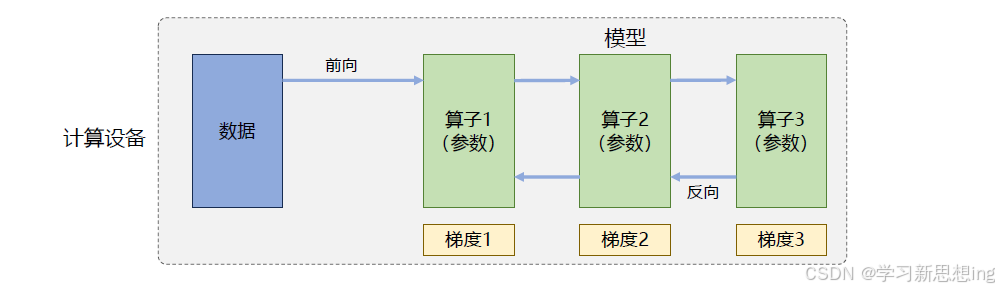
计算图的执行过程可以分为前向计算和反向计算两个阶段。
- 前向计算的过程是将数据读入第一个算子,计算出相应的输出结构,然后依此重复这个前向计算过程,直到最后一个算子结束。
- 反向计算过程,是根据优化函数和损失,每个算子依次计算出梯度,并利用梯度更新本地的参数。
- 在反向计算结束后,该数据小批次的计算完成,系统就会读取下一个数据小批次,继续下一轮的模型参数更新。
综上,,可以看到如果进行并行加速,可以从数据和模型两个维度进行考虑。
- 数据进行切分(Partition),并将同一个模型复制到多个设备上,并行执行不同的数据分片,这种方式通常被称为数据并行(Data Parallelism,DP)。
- 模型进行划分,将模型中的算子分发到多个设备分别完成,这种方式通常被称为模型并行(Model Parallelism,MP)
- 当训练超大规模语言模型时,往往需要同时对数据和模型进行切分,从而实现更高程度的并行,
这种方式通常被称为混合并行(Hybrid Parallelism,HP)。
2.1 数据并行(DP)
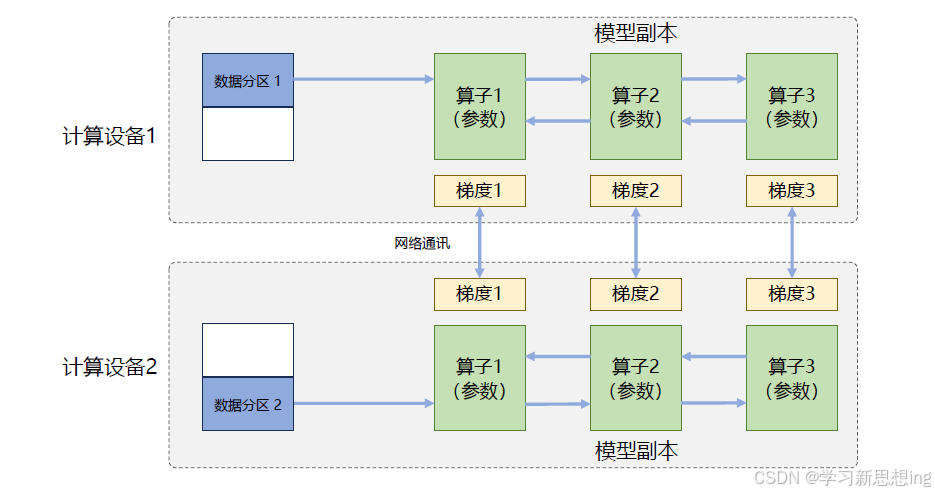
在数据并行系统中,每个计算设备都有整个神经网络模型的完整副本(Model Replica),进行迭代时,每个计算设备只分配了一个批次数据样本的子集,并根据该批次样本子集的数据进行网络模型的前向计算。
假设一个批次的训练样本数为N,使用M 个计算设备并行计算,每个计算设备会分配到N/M 个样本。前向计算完成后,每个计算设备都会根据本地样本计算损失误差得到梯度Gi(i 为加速卡编号),并将本地梯度Gi 进行广播。所有计算设备需要聚合其他加速度卡给出的梯度值,然后使用平均梯度(ΣNi=1Gi)/N 对模型进行更新,完成该批次训练。
2.2 模型并行
模型并行(Model Parallelism)往往用于解决单节点内存不足的问题。以包含1750 亿参数的GPT-3 模型为例,如果模型中每一个参数都使用32 位浮点数表示,那么模型需要占用700GB(即175G× 4 Bytes)内存,如果使用16 位浮点表示,每个模型副本需要也需要占用350GB 内存。H100 加速卡仅支持80GB 显存,无法将整个模型完整放入其中。
模型并行可以从计算图角度,以下两种形式进行切分:
(1)按模型的层切分到不同设备,即层间并行或算子间并行(Inter-operator Parallelism),也称之为流水线并行(Pipeline Parallelism,PP)。
(2)将计算图层内的参数切分到不同设备,即层内并行或算子内并行(Intra-operator Parallelism),也称之为张量并行(Tensor Parallelism,TP)。
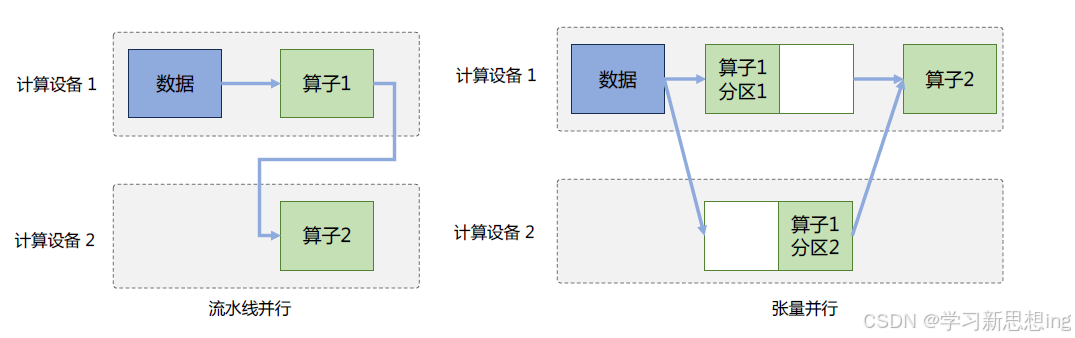
2.2.1流水线并行(PP)
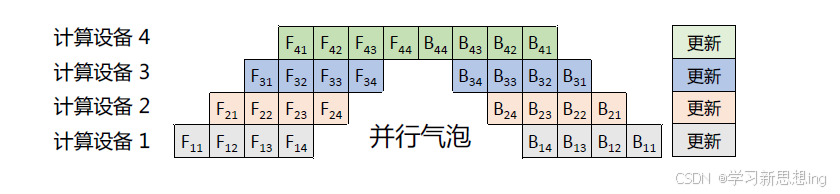
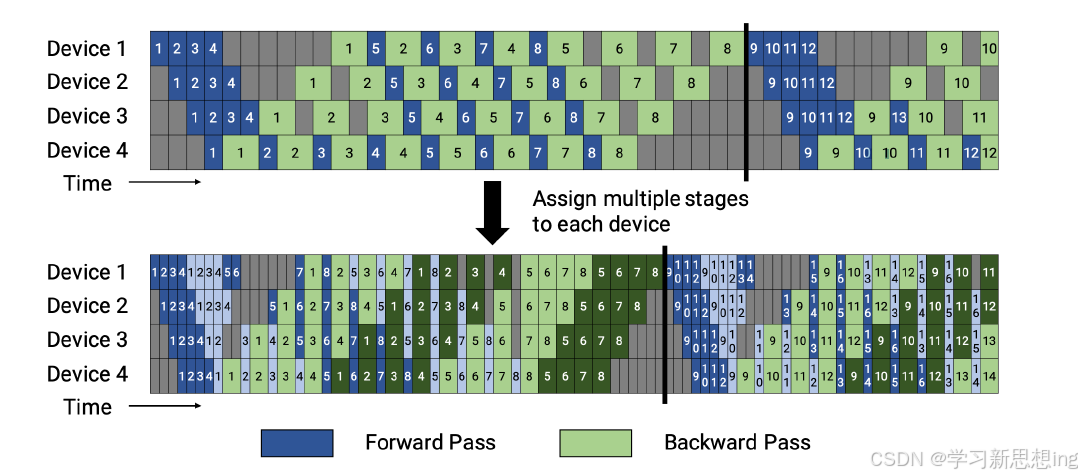
流水线并行(Pipeline Parallelism,PP)是一种并行计算策略,将模型的各个层分段处理,并将每个段分布在不同的计算设备上,使得前后阶段能够流水式、分批进行工作。流水线并行通常应用于大规模模型的并行系统中,以有效解决单个计算设备内存不足的问题。下图给出了一个由四
个计算设备组成的流水线并行系统,包含了前向计算和后向计算。其中F1、F2、F3、F4 分别代表四个前向路径,位于不同的设备上;而B4、B3、B2、B1 则代表逆序的后向路径,也分别位于四个不同的设备上。
2.2.2张量并行(TP)
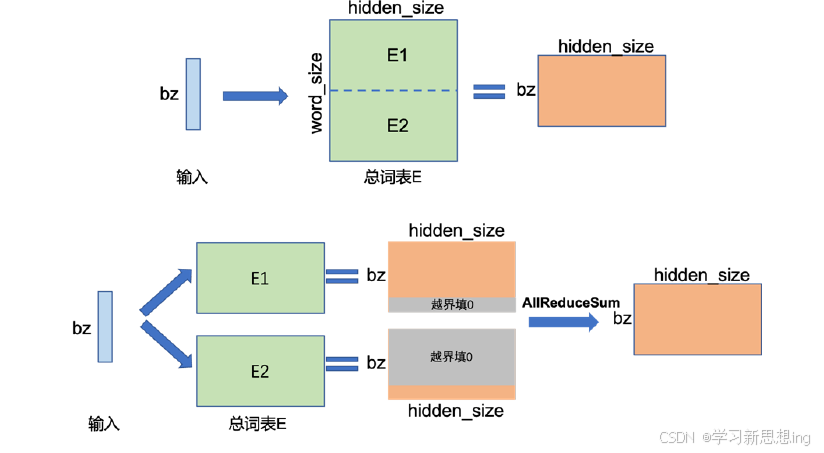
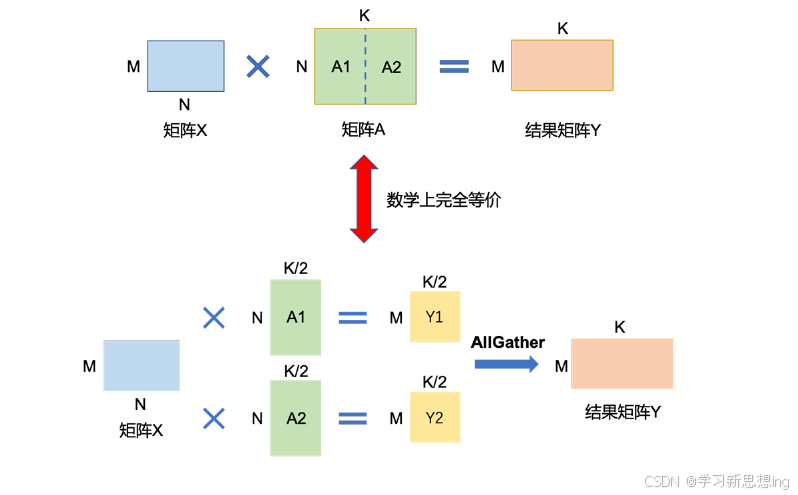
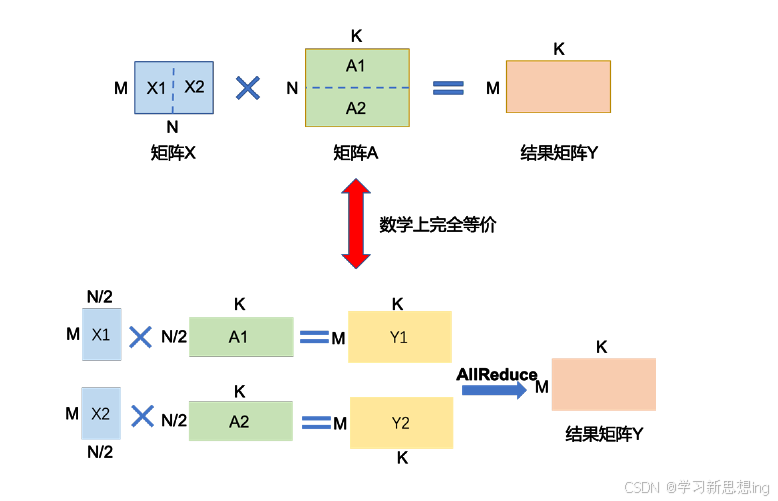
张量并行(Tensor Parallelism,TP)需要根据模型的具体结构和算子类型,解决如何将参数切分到不同设备,以及如何保证切分后数学一致性两个问题。大语言模型都是以Transformer 结构为基础,Transformer 结构主要由以下三种算子构成:嵌入式表(Embedding)、**矩阵乘(MatMul)和交叉熵损失(Cross Entropy Loss)**计算构成。这三种类型的算子有较大的差异,都需要设计对应的张量并行策略,才可以实现将参数切分到不同的设备
-
嵌入表示算子切分
两节点示例
-
矩阵乘切分
两节点示例:
- 交叉熵损失
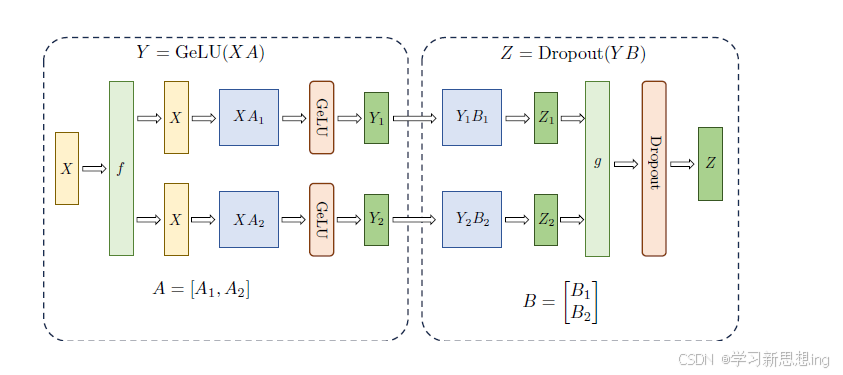
Transformer 中的FFN 结构均包含两层全连接(FC)层,即存在两个矩阵乘,这两个矩阵乘分别采用上述两种切分方式。对第一个FC 层的参数矩阵按列切块,对第二个FC层参数矩阵按行切块。这样第一个FC 层的输出恰好满足第二个FC 层数据输入要求(按列切分),因此可以省去第一个FC 层后的汇总通信操作。
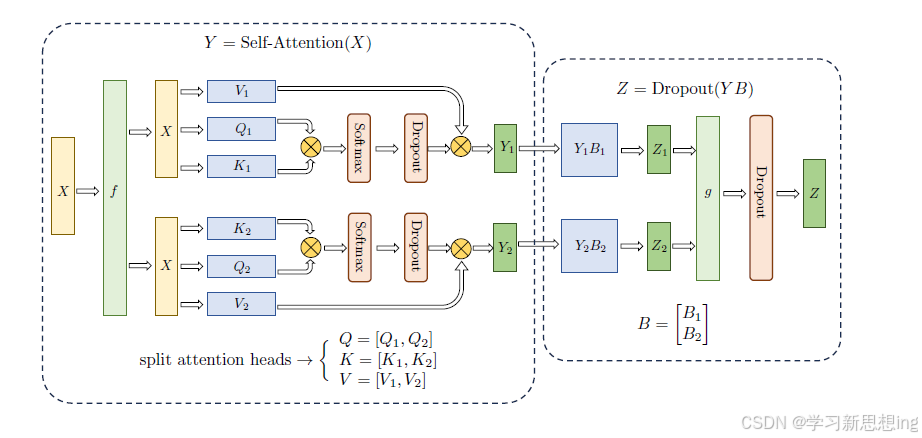
多头自注意力机制的张量并行与FFN 类似,因为具有多个独立的头,因此相较于FFN 更容易实现并行,
分类网络最后一层一般会选用Softmax 和Cross_entropy 算子来计算交叉熵损失(Cross EntropyLoss)。如果类别数量非常大,会导致单计算设备内存无法存储和计算logit 矩阵。针对这一类算子,可以按照类别维度切分,同时通过中间结果通信,得到最终的全局的交叉熵损失。
3.分布式训练的集群架构
分布式训练需要使用由多台服务器组成的计算集群(Computing Cluster)完成。而集群的架构也需要根据分布式系统、大语言模型结构、优化算法等综合因素进行设计。分布式训练集群属于高性能计算集群(High Performance Computing Cluster,HPC),其目标是提供海量的计算能力。在由高速网络组成的高性能计算上构建分布式训练系统,主要有两种常见架构:参数服务器架构(Parameter Server,PS)和去中心化架构(Decentralized Network)。
3.1参数服务器架构
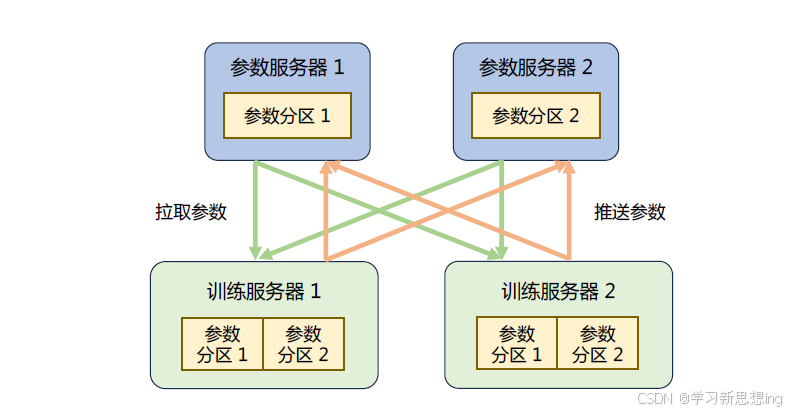
参数服务器(Parameter Server,PS)架构的分布式训练系统中有两种服务器角色:训练服务器和参数服务器。参数服务器需要提供充足内存资源和通信资源,训练服务器需要提供大量的计算资源。
在训练过程中,每个训练服务器都拥有完整的模型,并根据将分配到此服务器的训练数据集切片(Dataset Shard)进行计算,将得的梯度推送到相应的参数服务器。参数服务器会等待两个训练服务器都完成梯度推送,然后开始计算平均梯度,并更新参数。之后,参数服务器会通知训练服务器拉取最新的参数,并开始下一轮训练迭代。
3.2去中心化架构
去中心化(Decentralized Network)架构则采用集合通信实现分布式训练系统。在去中心化架构中,没有中央服务器或控制节点,而是由节点之间进行直接通信和协调。这种架构的好处是可以减少通信瓶颈,提高系统的可扩展性。
由于节点之间可以并行地进行训练和通信,去中心化架构可以显著降低通信开销,并减少通信墙的影响。
在分布式训练过程中,节点之间需要周期性地交换参数更新和梯度信息。可以通过集合通信(Collective communication,CC)技术来实现,常用通信原语包括Broadcast、Scatter、Reduce、All-Reduce、Gather、All-Gather、Reduce-Scatter、All-to-All等。
常见通信原语介绍:
-
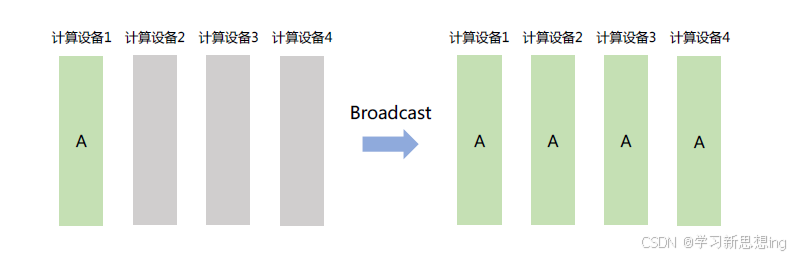
Broadcast:主节点把自身的数据发送到集群中的其他节点。分布式训练系统中常用于网络参数的初始化。如图所示,计算设备1 将大小为1 × N 的张量进行广播,最终每张卡输出均为[1 × N] 的矩阵。
-
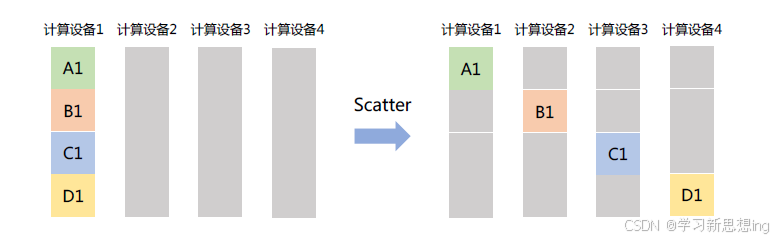
Scatter:主节点将数据进行划分并散布至其他指定的节点。Scatter 与Broadcast 非常相似,但不同的是,Scatter 是将数据的不同部分,按需发送给所有的进程。如图所示,计算设备1 将大小为1 × N 的张量分为4 份后发送到不同节点。
-
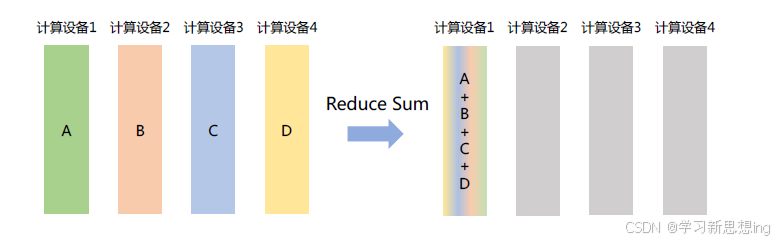
Reduce:是一系列简单运算操作的统称,是将不同节点上的计算结果进行聚合(Aggregation),可以细分为:SUM、MIN、MAX、PROD、LOR 等类型的规约操作。如图所示,ReduceSum 操作将所有其它计算设备上的数据汇聚到计算设备1,并执行求和操作。
-
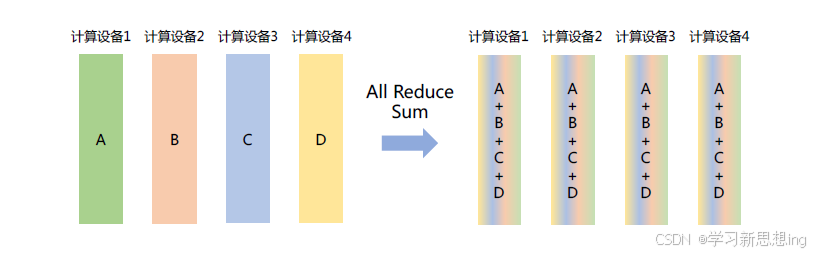
All Reduce:在所有的节点上都应用同样的Reduce 操作。All Reduce 操作可通过单节点上Reduce + Broadcast 操作完成。如图所示,All Reduce Sum 操作将所有计算设备上的数据汇聚到各个计算设备中,并执行求和操作。
-
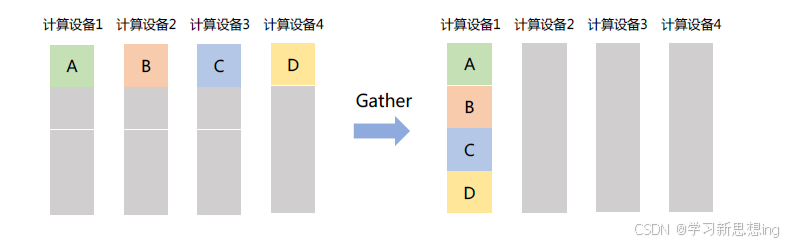
Gather:将多个节点上的数据收集到单个节点上,Gather 可以理解为反向的Scatter。如图所示,Gather 操作将所有计算设备上的数据收集到计算设备1 中。
-
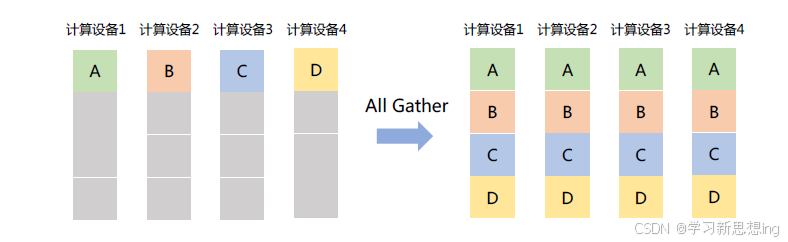
All Gather:将所有节点上收集其他所有节点上的数据,All Gather 相当于一个Gather 操作之后跟着一个Broadcast 操作。如图所示,All Gather 操作将所有计算设备上的数据收集到每个计算设备中。
-
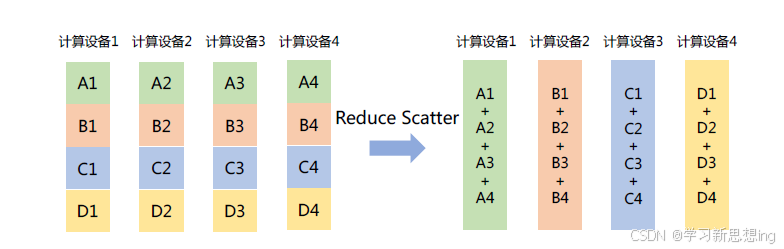
Reduce Scatter:将每个节点中的张量切分为多个块,每个块分配给不同的节点。接收到的块会在每个节点上进行特定的操作,例如求和、取平均值等。如图所示,每个计算设备都将其中的张量切分为4 块,并分发到4 个不同的计算设备中,每个计算设备分别对接收到的分块进行特定操作。
-
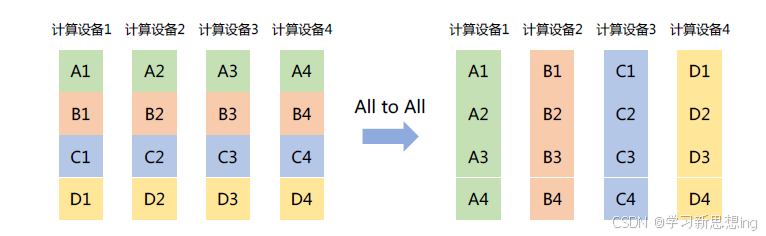
All to All:将每个节点的张量切分为多个块,每个块分别发送给不同的节点。如图所示,每个计算设备都将其中的张量切分为4 块,并分发到4 个不同的计算设备中。
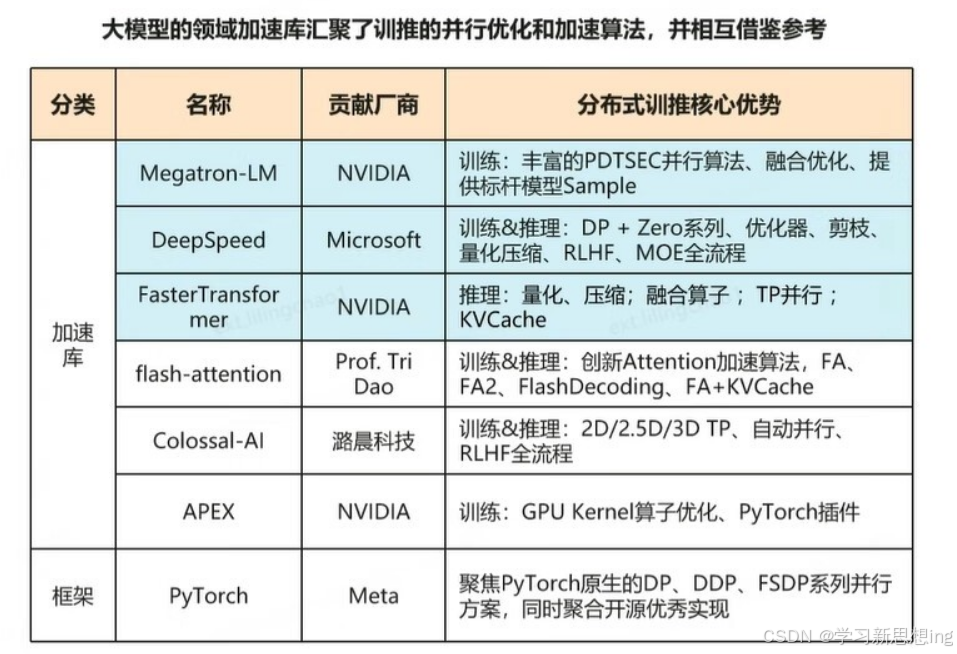
4.常见分布式训练框架
日常学习总结
参考《大规模语言模型:从理论到实践》