首先什么是Hadoop
Hadoop是一个能够对大量数据进行分布式处理的软件框架。以一种可靠,高效,可伸缩的方式进行数据处理。广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。主要解决,海量数据的存储和海量数据的分析计算问题。
主要包括三部分内容:Hdfs,MapReduce,Yarn。

Hadoop的优势
其优势有四点:
- 高可靠 :Hadoop底层维护了多个副本,即使Hadoop的某个计算或存储元素出现了故障,也不会造成数据的丢失。
- 高扩展:在集群间分配任务数据,可方便的扩展数以千计的节点。
- 高效性 :在MapReduce的思想下,Hadoop是并行工作的,而不是串行,以加快任务处理速度。
- 高容错 :能够自动将失败的任务重新分配。
Hadoop1.0,2.0,3.0的区别(面试题)
Hadoop1.0:由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中HDFS由一个NameNode和多个DateNode组成,MapReduce由一个JobTracker和多个TaskTracker组成。
缺点:容易导致单点故障,拓展性差,性能低,支持编程模型单一。
Hadoop2.0:即为克服Hadoop1.0中的不足,提出了以下关键特性:
Yarn:它是Hadoop2.0引入的一个全新的通用资源管理系统,完全代替了Hadoop1.0中的JobTracker。Yarn 还支持多种应用程序和框架,提供统一的资源调度和管理功能。
优点:NameNode 单点故障得以解决—Hadoop2.2.0 同时解决了 NameNode 单点故障问题和内存受限问题,并提供 NFS,QJM 和 Zookeeper 三种可选的共享存储系统
Hadoop3.0:相比于Hadoop2.0,Hadoop3.0 是直接基于 JDK1.8 发布的一个新版本。引入了一些重要的功能和特性:
HDFS可擦除编码:这项技术使HDFS在不降低可靠性的前提下节省了很大一部分存储空间
多NameNode支持:在Hadoop3.0中,新增了对多NameNode的支持。当然,处于Active状态的NameNode实例必须只有一个。也就是说,从Hadoop3.0开始,在同一个集群中,支持一个 ActiveNameNode 和 多个 StandbyNameNode 的部署方式。
MR Native Task优化,Yarn基于cgroup 的内存和磁盘 I/O 隔离等
Hadoop组成
我们基于mapreduce框架编写分布式计算程序。该程序会被部署到yarn上,分布在yarn的各个机器上运行。在运行时,会从hdfs读取数据或者是将数据写出到hdfs。
(1)Hadoop HDFS:(hadoop distribute file system )一个高可靠、高吞吐量的分布式文件系统。
(2)Hadoop MapReduce:一个分布式的离线并行计算框架。
(3)Hadoop YARN:作业调度与集群资源管理的平台。
(4)Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)。
Hadoop之HDFS
HDFS的定义
HDFS是存储文件的分布式文件系统,适合一次写入多次读出场景,仅支持数据追加(append),不支持文件修改,适合用做数据分析。
架构图如下:
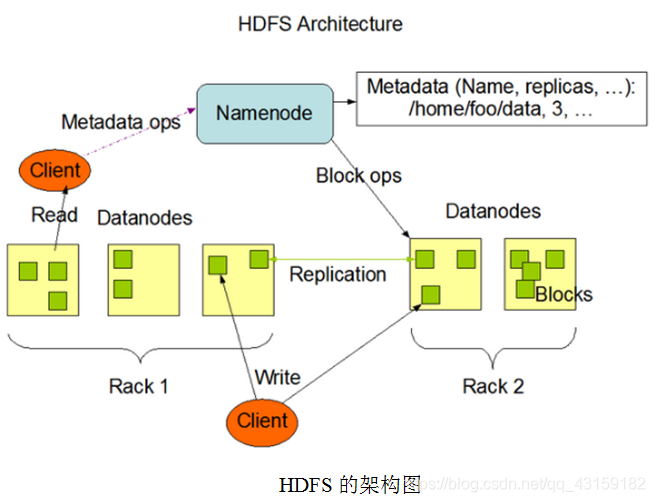
1)Client:就是客户端。
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行存储;
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,比如启动或者关闭HDFS;
(5)Client可以通过一些命令来访问HDFS;
2)NameNode:就是Master,它是一个主管、管理者。
(1)管理HDFS的名称空间;
(2)管理数据块(Block)映射信息;
(3)配置副本策略;
(4)处理客户端读写请求。
3) DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作。
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
4)Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量;
(2)定期合并Fsimage和Edits,并推送给NameNode;
(3)在紧急情况下,可辅助恢复NameNode。