Multi-view Classification Using Hybrid Fusion and Mutual Distillation
Intro
多视角问题可以分为两类:
- Structured。固定视角,或预先定义的视角的问题。
- unstructured。
本文的三大contributions:
- 引入了混合的多视角融合策略。
- 使用了互蒸馏策略。具体而言,对多视角融合预测,与单视角预测均值,采用distillation loss。
- 证实了在多种多视角任务当中的有效性。
Related Work
Fusion策略分类。
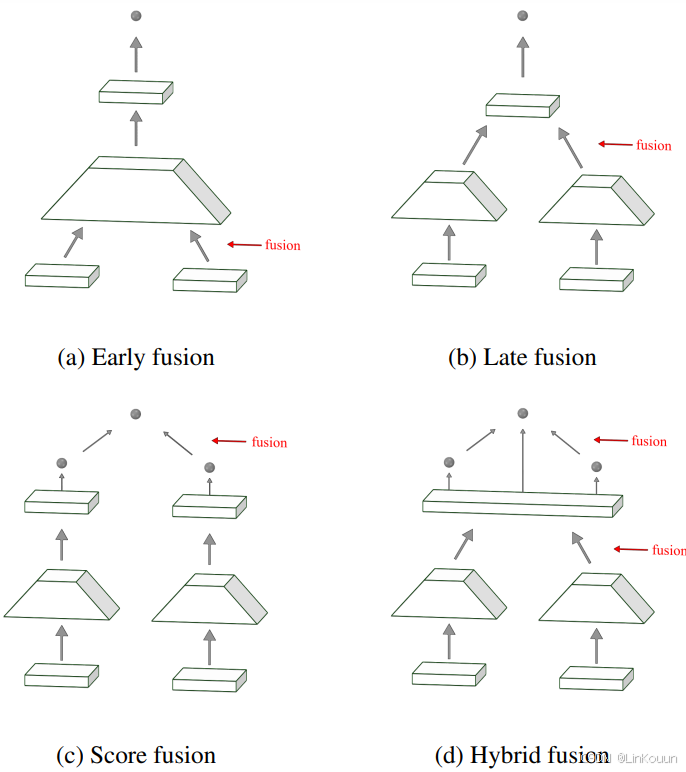
- Early Fusion:在low-level对feature进行融合,之后的训练过程与单视角情况一致。
缺点:low-level feature没经过网络的深层次处理,过早的融合特征可能会将一些task-irrelevant features融入进去。 - Late Fusion:先利用某些网络(如CNN)独立从input中学习feature,然后对特征进行融合。
比如:简单的串接feature,然后再对融合后的特征做池化。 - Score Fusion:极端的late fusion。每个单视角分别预测,然后只融合最后的预测vector(预测分数)。
- 本文采用 Hybrid 策略:结合了score fusion和score fusion。
- 本文引入了多视角预测与score-fused的单视角预测(具体而言是,求所有单个视角预测分数的均值)的互蒸馏。
Method
整体Pipeline如下:
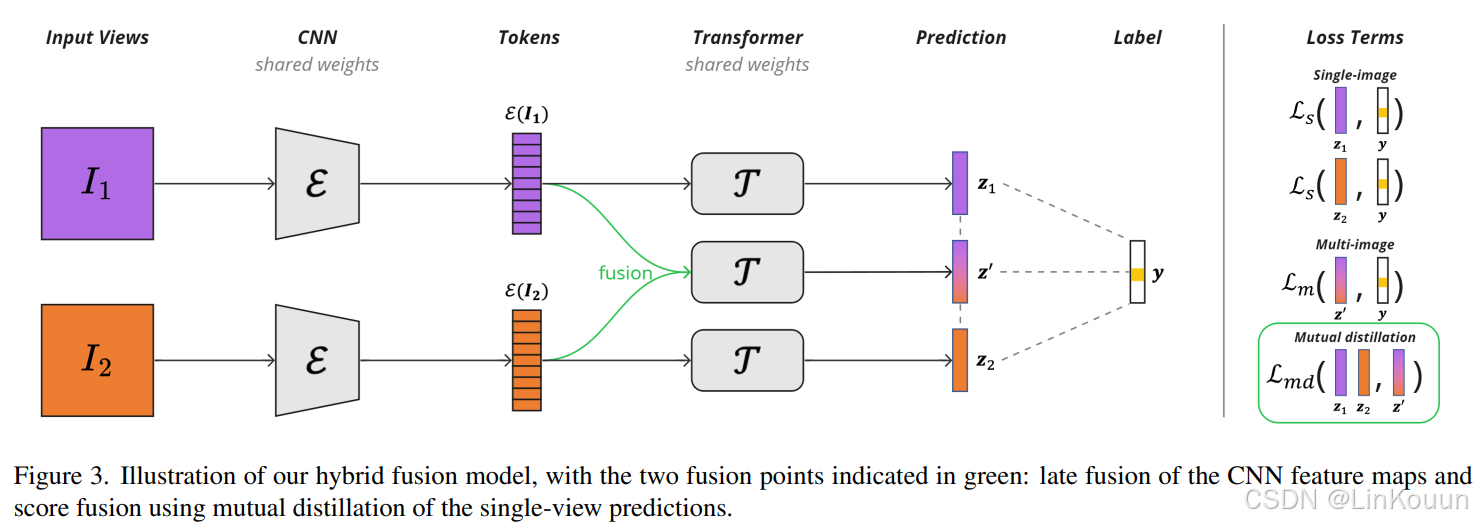
算法流程:
-
I 1 I_1 I1为第一个视角的输入样本。每个视角的输入分别送入CNN中,得到feature:
- C ( I ) ∈ R h × w × c \mathcal{C}(I) \in \mathbb{R}^{h \times w \times c} C(I)∈Rh×w×c:CNN输出特征。维度分别为高,宽,通道数。
-
将 C ( I ) \mathcal{C}(I) C(I)转为Token形式,以便之后送入Transformer:首先将空间维度 ( h , w ) (h,w) (h,w)拉成一维 S = h w S = hw S=hw;然后将其encode成token形式:
E ( I ) = C ( I ) E + E p o s \begin{equation} \mathcal{E}\left(\boldsymbol{I}\right)=\mathcal{C}\left(\boldsymbol{I}\right)\mathbf{E}+\mathbf{E}_{\mathbf{pos}} \end{equation} E(I)=C(I)E+Epos- E ∈ R c × d \mathbf{E} \in \mathbb{R}^{c \times d} E∈Rc×d:投影矩阵。
- E pos \mathbf{E}_\textbf{pos} Epos:可学习的positional encoding。
- 最后将Eq1结果串接一个
x
class
∈
R
1
×
d
x_\textbf{class} \in \mathbb{R}^{1 \times d}
xclass∈R1×d
E ( I ) ∈ R S × d \mathcal{E}\left(\boldsymbol{I}\right) \in \mathbb{R}^{S \times d} E(I)∈RS×d,相当于长度为S的序列,每个token维度为d。
-
将 E ( I ) \mathcal{E}\left(\boldsymbol{I}\right) E(I)送入Transformer中。其中单个视角分别送入各自的Transformer,输出单一视角预测;多个视角特征融合,送入一个Transformer,输出多视角预测。N个视角的输入图像,对应N+1个Transformer。
-
单视角预测:
z = T ( [ x c l a s s ; E ( I ) ] ) \begin{equation} z=\mathcal{T}\left(\left[x_{\mathbf{class}};\mathcal{E}\left(\boldsymbol{I}\right)\right]\right) \end{equation} z=T([xclass;E(I)])
T \mathcal{T} T表示Transformer -
多视角预测:
z ′ = T ( [ x c l a s s ; E ′ ( I 1 ) ; E ′ ( I 2 ) ; . . . ; E ′ ( I N ) ] ) \begin{equation} \boldsymbol{{z}^{\prime}}=\mathcal{T}\left(\left[\boldsymbol{x}_{\mathbf{class}};\mathcal{E}^{\prime}\left(\boldsymbol{I}_{1}\right);\mathcal{E}^{\prime}\left(\boldsymbol{I}_{2}\right);...;\mathcal{E}^{\prime}\left(\boldsymbol{I}_{N}\right)\right]\right) \end{equation} z′=T([xclass;E′(I1);E′(I2);...;E′(IN)])
其中 z , z ′ ∈ R 1 × k \boldsymbol{z}, \boldsymbol{z}^\prime \in \mathbb{R}^{1 \times k} z,z′∈R1×k为prediction vector。 k k k为分类个数。
-
-
使用联合损失函数:
L = L m + L s + λ L m d \begin{equation} \mathcal{L}=\mathcal{L}_m+\mathcal{L}_s+\lambda\mathcal{L}_{md} \end{equation} L=Lm+Ls+λLmd
分为三大部分:- L m \mathcal{L}_m Lm:多视角预测损失。为多视角融合特征的预测结果,与ground-truth label的损失。
- L s \mathcal{L}_s Ls:单视角平均预测损失:所有单视角预测损失的平均值(score-fused)。
- L m d \mathcal{L}_{md} Lmd:互蒸馏损失。
L m d ( { z 1 , . . . , z N } , z ′ ; τ ) = 1 2 τ 2 ( L k d ( z ˉ ^ , z ′ ; τ ) + L k d ( z ^ ′ , z ˉ ; τ ) ) \begin{align} & \mathcal{L}_{md}\left(\{\boldsymbol{z}_1,...,\boldsymbol{z}_N\},\boldsymbol{z}^{\prime};\tau\right) \notag \\ = & \frac{1}{2}\tau^2 \left(\mathcal{L}_{kd}\left(\hat{\bar{\boldsymbol{z}}},\boldsymbol{z^{\prime}};\tau\right)+\mathcal{L}_{kd}\left(\hat{\boldsymbol{z}}^{\prime},\bar{\boldsymbol{z}};\tau\right)\right) \end{align} =Lmd({z1,...,zN},z′;τ)21τ2(Lkd(zˉ^,z′;τ)+Lkd(z^′,zˉ;τ))
- $\bold{\hat{}} \quad $:表示不进行反向传播的tensor(gradient-detached copy)。
- z ˉ = 1 N ∑ i = 1 N z i \bar{\boldsymbol{z}}=\frac{1}{N}\sum_{i=1}^N\boldsymbol{z}_i zˉ=N1∑i=1Nzi。N表示N个视角。
- z ˉ = 1 N ∑ i = 1 N z i \bar{\boldsymbol{z}}=\frac{1}{N}\sum_{i=1}^N\boldsymbol{z}_i zˉ=N1∑i=1Nzi。N表示N个视角。