数据库连接池
文章目录
一:知识准备
1:什么是数据库连接池?
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;
释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。
这项技术能明显提高对数据库操作的性能
2:数据库连接池基本原理
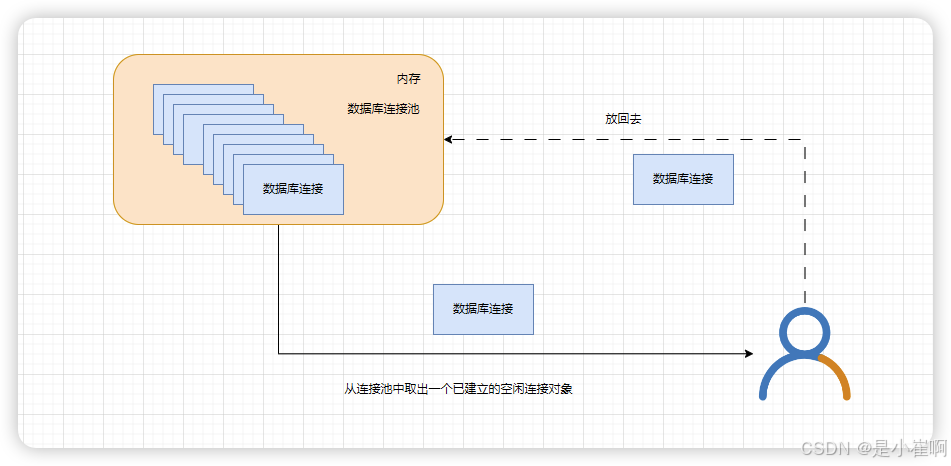
连接池基本的思想是在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。
使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用。
而连接的建立、断开都由连接池自身来管理。
同时,还可以通过设置连接池的参数来控制连接池中的初始连接数、连接的上下限数以及每个连接的最大使用次数、最大空闲时间等等。
也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。
数据库连接池的最小连接数和最大连接数的设置要考虑到下列几个因素:
- 最小连接数
是连接池一直保持的数据库连接,所以如果应用程序对数据库连接的使用量不大,将会有大量的数据库连接资源被浪费。
- 最大连接数
是连接池能申请的最大连接数,如果数据库连接请求超过此数,后面的数据库连接请求将被加入到等待队列中,这会影响之后的数据库操作。
- 最小连接数与最大连接数差距
最小连接数与最大连接数相差太大,那么最先的连接请求将会获利,之后超过最小连接数量的连接请求等价于建立一个新的数据库连接。
不过,这些大于最小连接数的数据库连接在使用完不会马上被释放,它将被放到连接池中等待重复使用或是空闲超时后被释放
二:HikariCP连接池
1:简单使用
spring:
datasource:
url: jdbc:mysql://localhost:3306/test_db?useSSL=false&autoReconnect=true&characterEncoding=utf8
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: bfXa4Pt2lUUScy8jakXf
# 指定为HikariDataSource
type: com.zaxxer.hikari.HikariDataSource
# hikari连接池配置
hikari:
#连接池名
pool-name: HikariCP
#最小空闲连接数
minimum-idle: 5
# 空闲连接存活最大时间,默认10分钟
idle-timeout: 600000
# 连接池最大连接数,默认是10
maximum-pool-size: 10
# 此属性控制从池返回的连接的默认自动提交行为,默认值:true
auto-commit: true
# 此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认30分钟
max-lifetime: 1800000
# 数据库连接超时时间,默认30秒
connection-timeout: 30000
# 连接测试query
connection-test-query: SELECT 1
2:进一步理解
2.1:是SpringBoot2.x默认连接池
从SpringBoot自动初始化配置 和 默认的数据源 两个角度理解
SpringBoot自动初始化配置
然后可以找到HikariCP数据源的配置
可以发现,为了支持动态更新配置(基于MXBean),这里还设计了一层HikariConfigMXBean接口
为什么说是默认的数据源呢
- springboot-starter-jdbc中默认加载了Hikari

- 在配置初始化或者加载时都是第一个被加载的
private static <T extends DataSource> MappedDataSourceProperties<T> lookupPooled(ClassLoader classLoader,
Class<T> type) {
MappedDataSourceProperties<T> result = null;
result = lookup(classLoader, type, result, "com.zaxxer.hikari.HikariDataSource",
HikariDataSourceProperties::new);
result = lookup(classLoader, type, result, "org.apache.tomcat.jdbc.pool.DataSource",
TomcatPoolDataSourceProperties::new);
result = lookup(classLoader, type, result, "org.apache.commons.dbcp2.BasicDataSource",
MappedDbcp2DataSource::new);
result = lookup(classLoader, type, result, "oracle.ucp.jdbc.PoolDataSourceImpl",
OraclePoolDataSourceProperties::new, "oracle.jdbc.OracleConnection");
return result;
}
2.2:为什么会成为默认连接池
字节码精简:优化代码,直到编译后的字节码最少,这样,CPU缓存可以加载更多的程序代码;优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码,只有BoneCP的十分之一;自定义数组类型(FastStatementList)代替ArrayList:避免每次get()调用都要进行range check,避免调用remove()时的从头到尾的扫描;自定义集合类型(ConcurrentBag):提高并发读写的效率;其它:针对BoneCP缺陷的优化,比如对于耗时超过一个CPU时间片的方法调用的研究等
三: 集成数据库Druid连接池
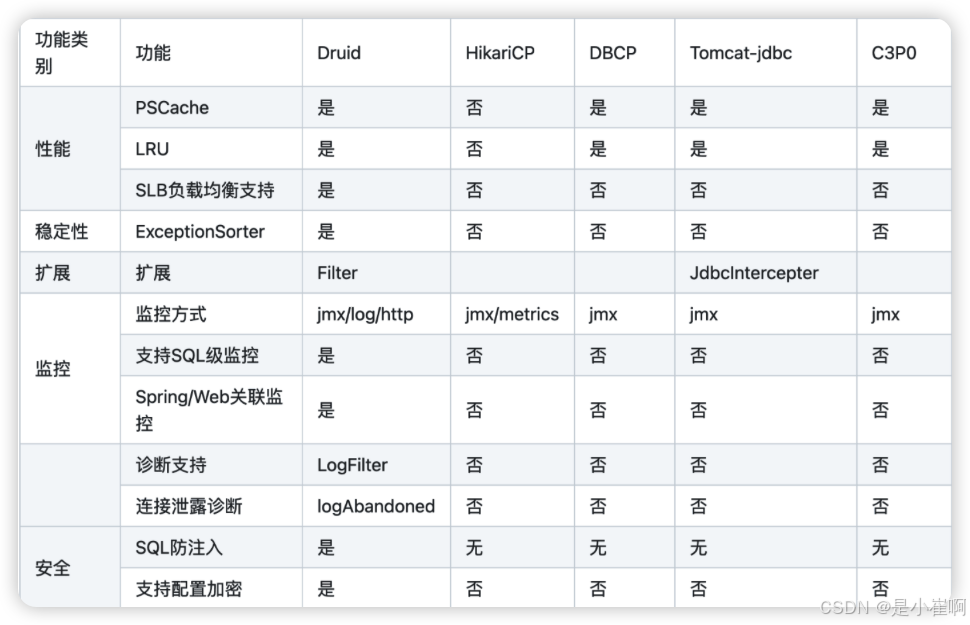
Druid连接池是阿里巴巴开源的数据库连接池项目。Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能。
功能强大,能防SQL注入,内置Loging能诊断Hack应用行为。
- Github项目地址 https://github.com/alibaba/druid
- 文档 https://github.com/alibaba/druid/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98
- 下载 http://repo1.maven.org/maven2/com/alibaba/druid/
- 监控DEMO http://120.26.192.168/druid/index.html
1:简单使用
<!-- https://mvnrepository.com/artifact/com.alibaba/druid-spring-boot-starter -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.9</version>
</dependency>
spring:
datasource:
url: jdbc:mysql://localhost:3306/test_db?useSSL=false&autoReconnect=true&characterEncoding=utf8
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: bfXa4Pt2lUUScy8jakXf
# Druid datasource
type: com.alibaba.druid.pool.DruidDataSource
druid:
# 初始化大小
initial-size: 5
# 最小连接数
min-idle: 10
# 最大连接数
max-active: 20
# 获取连接时的最大等待时间
max-wait: 60000
# 一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 300000
# 多久才进行一次检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 60000
# 配置扩展插件:stat-监控统计,log4j-日志,wall-防火墙(防止SQL注入),去掉后,监控界面的sql无法统计
filters: stat,wall
# 检测连接是否有效的 SQL语句,为空时以下三个配置均无效
validation-query: SELECT 1
# 申请连接时执行validationQuery检测连接是否有效,默认true,开启后会降低性能
test-on-borrow: true
# 归还连接时执行validationQuery检测连接是否有效,默认false,开启后会降低性能
test-on-return: true
# 申请连接时如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效,默认false,建议开启,不影响性能
test-while-idle: true
# 是否开启 StatViewServlet
stat-view-servlet:
enabled: true
# 访问监控页面 白名单,默认127.0.0.1
allow: 127.0.0.1
login-username: admin
login-password: admin
# FilterStat
filter:
stat:
# 是否开启 FilterStat,默认true
enabled: true
# 是否开启 慢SQL 记录,默认false
log-slow-sql: true
# 慢 SQL 的标准,默认 3000,单位:毫秒
slow-sql-millis: 5000
# 合并多个连接池的监控数据,默认false
merge-sql: false
2:进一步理解
2.1:更多功能
Druid连接池最初就是为监控系统采集jdbc运行信息而生的,它内置了StatFilter 功能,能采集非常完备的连接池执行信息Druid连接池内置了能和Spring/Servlet关联监控的实现,使得监控Web应用特别方便Druid连接池内置了一个监控页面,提供了非常完备的监控信息,可以快速诊断系统的瓶颈
监控信息采集的StatFilter
Druid连接池的监控信息主要是通过StatFilter 采集的,采集的信息非常全面,包括SQL执行、并发、慢查、执行时间区间分布等。
- 监控不影响性能
Druid增加StatFilter之后,能采集大量统计信息,同时对性能基本没有影响。
StatFilter对CPU和内存的消耗都极小,对系统的影响可以忽略不计。
监控不影响性能是Druid连接池的重要特性。
- SQL参数化合并监控
实际业务中,如果SQL不是走PreparedStatement,SQL没有参数化,这时SQL需要参数化合并监控才能真实反映业务情况。
如下SQL:
select * from t where id = 1
select * from t where id = 2
select * from t where id = 3
参数化后:
select * from t where id = ?
参数化合并监控是基于SQL Parser语法解析实现的,是Druid连接池独一无二的功能。
- 执行次数、返回行数、更新行数和并发监控
StatFilter能采集到每个SQL的执行次数、返回行数总和、更新行数总和、执行中次数和和最大并发。
并发监控的统计是在SQL执行开始对计数器加一,结束后对计数器减一实现的。
可以采集到每个SQL的当前并发和采集期间的最大并发。
- 慢查监控
缺省执行耗时超过3秒的被认为是慢查,统计项中有包括每个SQL的最后发生的慢查的耗时和发生时的参数。
- Exception监控
如果SQL执行时抛出了Exception,SQL统计项上会Exception有最后的发生时间、堆栈和Message,根据这些信息可以很容易定位错误原因
诊断支持
Druid连接池内置了LogFilter,将Connection/Statement/ResultSet相关操作的日志输出
可以用于诊断系统问题,也可以用于Hack一个不熟悉的系统。
LogFilter可以输出连接申请/释放,事务提交回滚,Statement的Create/Prepare/Execute/Close
ResultSet的Open/Next/Close,通过LogFilter可以详细诊断一个系统的Jdbc行为。
LogFilter有Log4j、Log4j2、Slf4j、CommsLog等实现
防止SQL注入
SQL注入攻击是黑客对数据库进行攻击的常用手段,Druid连接池内置了WallFilter 提供防SQL注入功能,在不影响性能的同时防御SQL注入攻击。
- 基于语意的防SQL注入
Druid连接池内置了一个功能完备的SQL Parser,能够完整解析mysql、sql server、oracle、postgresql的语法
通过语意分析能够精确识别SQL注入攻击。
- 极低的漏报率和误报率
基于SQL语意分析,大量应用和反馈,使得Druid的防SQL注入拥有极低的漏报率和误报率。
- 防注入对性能影响极小
内置参数化后的Cache、高性能手写的Parser,使得打开防SQL注入对应用的性能基本不受影响
2.2:如何评价阿里的Druid连接池
客观的来说,阿里Druid只能说是中文开源中功能全且广泛的连接池为基础的监控组件
但是(仅从连接池的角度)在生态,维护性,开源规范性,综合性能等方面和HikariCP比还是有很大差距
功能上
首先,仅从功能上看,Druid并不是一个存粹的连接池,它还承载了监控,诊断,安全的功能。
从产品的角度看,all in one 也是有代价的,如果我只期望使用连接池的功能,其它的功能对于使用者来说就是鸡肋;
而我们没有看到其长期架构设计(比如插拔式架构,分包设计等), 大概率是当时Druid这种开源的驱动方式并不是一个完善规范的开源软件开发方式
如果你仅仅从功能上比较,就已经输了,因为这种比较根本不在一个维度上;
维护
文档的规范性,发包规范性,bug修复,生态构建等方面国产开源在那时(当下及未来一段时间)还有很长的路要走。
来看看相关Isusse,2k多个issues哈,没有专职维护