1. 前提回顾
前面我们说到redis的String数据结构在底层有多种编码方式。例如我们执行下面两条语句
set k1 v1
set age 17
我们查看类型,发现这类型都是String类型
我们现在查看底层的编码类型,发现编码类型一个是embstr一个是int类型,虽然都是String字符串,但redis根据value的不同类型设置了不同的编码方式


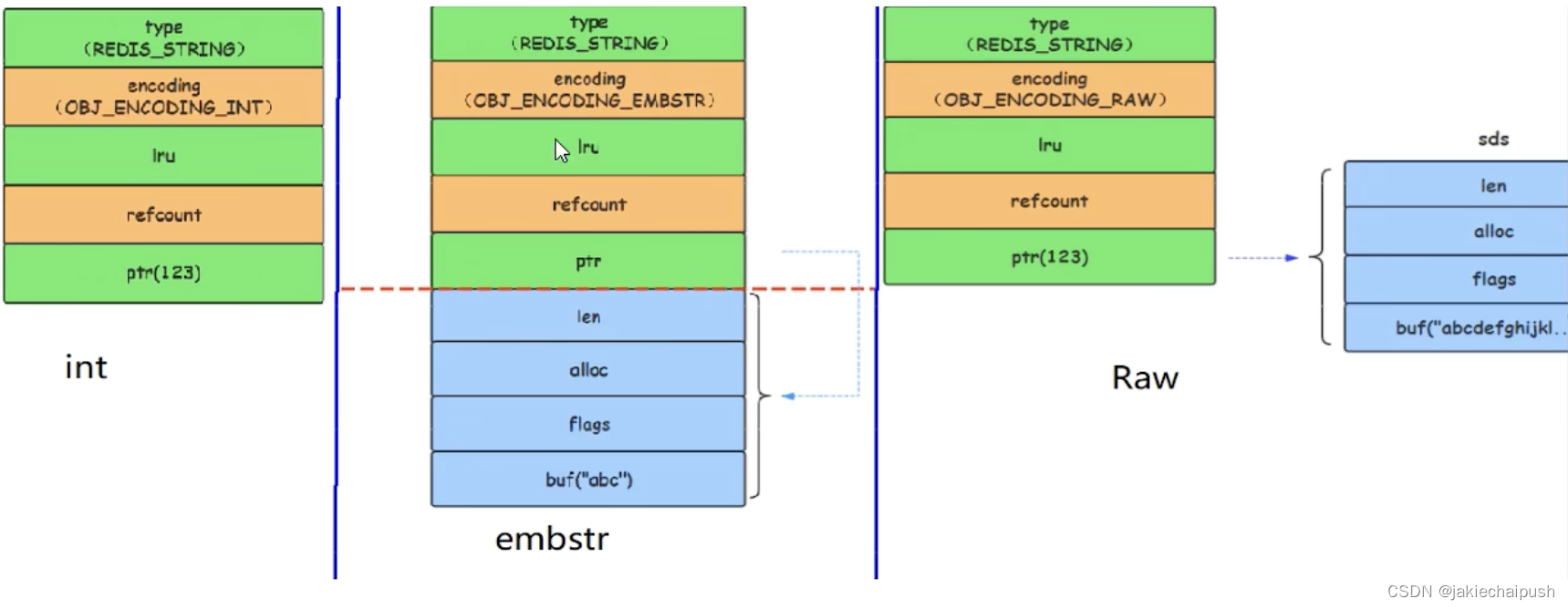
redisObject内部对应3大物理编码:int、embstr和raw

2. RedisObject三大数据类型简介
- int
它保存long型(长整型)的64位(8个字节)有符号整数(9223372036854775807,最高19位)。
只有整数才会使用int类型去编码,如果是浮点数,redis内部其实先将浮点数转化为字符串值,然后再保存。


- emstr
代表embstr格式的SDS(Simple Dynamic String 简单动态字符串),保存长度小于44字节的字符串,embstr即embedded String,表示嵌入式的String
- raw
保存长度大于44字节的字符串
下面给演示一下各个类型的使用:
首先长度小于19位的数字,类型为int

浮点数底层为emstr

长度超过19的数字,类型为emstr

普通字符串是emstr

长度超过44的字符串,为raw类型

长度超过44的浮点数,为raw类型

3. SDS字符串
我们知道c语言底层表示字符串本质上是用的一个char数组。但是redis没有直接复用C语言的字符串的底层实现,而是新建了属于自己的结构—SDS,在redis数据库里,包含字符串值的键值对都是由SDS实现的(redis中所有的键都是由字符串对象实现的即底层是由SDS实现,Redis所有的值对象中包含的字符串对象底层也是SDS实现的)
我们看一下sds结构体的源码:
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
可以看到redis底层工定义了五种sds字符串的结构,分别是:sdshdr5、sdshdr8、sdshdr16、sdshdr32和sdshdr64。那么各个字段是什么意思:
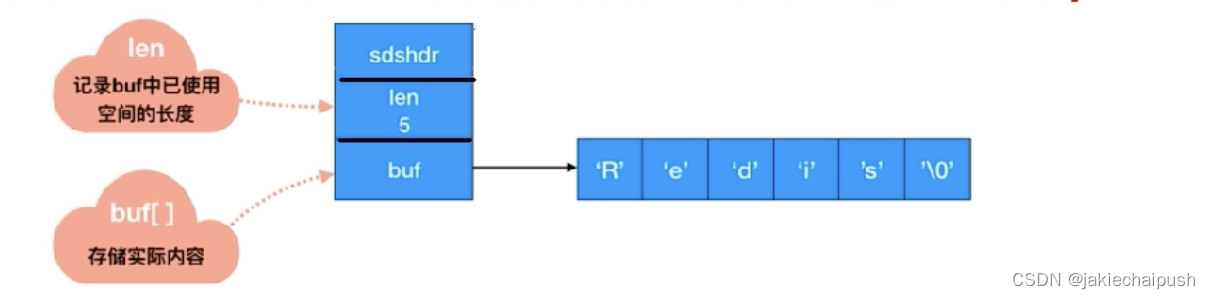
- len:代表存储的字符串的长度
- alloc:存储了为字符串分配的内存空间的长度(即实际分配的空间大小,不包括结构体头部和字符串结束符 \0)
- flags:代表SDS字符串的类型,上面介绍类型的五种之一
- buf[]:真正存储字符串的char数组
那上面五种类型有什么不同?
sdshdr5:表示 2 5 2^5 25即共32个字节
sdshdr8:表示 2 8 2^8 28即256个字节
sdshdr16:表示 2 16 2^{16} 216即65536个字节,64KB
sdshdr32:表示 2 32 2^{32} 232即4GB
sdshdr64:表示 2 64 2^{64} 264即17179869184G个字节
len表示SDS实际的长度,使我们在获取字符串的时候能够在O(1)时间复杂度情况下拿到,而不需要遍历一遍char数组
alloc:可以用来计算free就是字符串已经分配的未使用空间,这个值就可以引入预分配空间算法了,而不用去考虑内存分配问题
buf:字符串数组,真正存数据的
alloc 字段的作用是提供了对字符串进行动态增长的能力。当字符串需要扩容时,Redis 可以根据需要重新分配更大的内存空间,并将原有的内容复制到新的内存中,然后释放原来的内存。这样做的好处是可以减少频繁地进行内存分配和释放操作,提高了性能。举个例子,假设有一个 SDS 字符串,其实际长度为 10,但为了防止频繁的内存分配和释放操作,alloc 被设置为了 20。当这个字符串需要扩容时,Redis 可以直接在内存中分配一个长度为 20 的新空间,然后将原字符串内容复制到新的空间中,同时更新 len 和 alloc 字段。这样即使字符串长度增长,也不需要每次都重新分配内存,减少了系统的开销。
现在思考一个问题:Redis为什么不直接使用char数组,而是自己重写设计来一个SDS数据结构?
这是因为C语言没有Java里面的String类型,只能是靠自己的char[]来实现,字符串在C语言中的存储方式,如果现在我们想通过strlen命令获取value的长度,我们就需要从头开始遍历,知道遇到\0即可,这样操作的时间复杂度是O(n),所以redis没有直接使用C语言传统的字符串标识,而是自己构建了一种名为简单动态字符串类型SDS,并作为redis的默认字符串类型。

4. SDS字符串源码分析
当我们输入set k1 v1 底层到底发生了什么?这里我们详细分析一下
首先看t_string.c文件
/* SET key value [NX] [XX] [KEEPTTL] [GET] [EX <seconds>] [PX <milliseconds>]
* [EXAT <seconds-timestamp>][PXAT <milliseconds-timestamp>] */
void setCommand(client *c) {
//key的过期时间
robj *expire = NULL;
//时间的单位是s
int unit = UNIT_SECONDS;
int flags = OBJ_NO_FLAGS;
if (parseExtendedStringArgumentsOrReply(c,&flags,&unit,&expire,COMMAND_SET) != C_OK) {
return;
}
//c->args[2]就是value,这里调用tryObjectEncoding就是尝试堆value值进行编码,编码后的结果再保存到c->args[2]中
c->argv[2] = tryObjectEncoding(c->argv[2]);
setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL);
}
当我们在cli写set k1 v1时,它底层本质上调用的是上面的
setCommand命令
从上面代码代码可以看出字符串的编码和tryObjectEncoding这个函数时紧密相关的,我们来分析一下底层是怎么做的
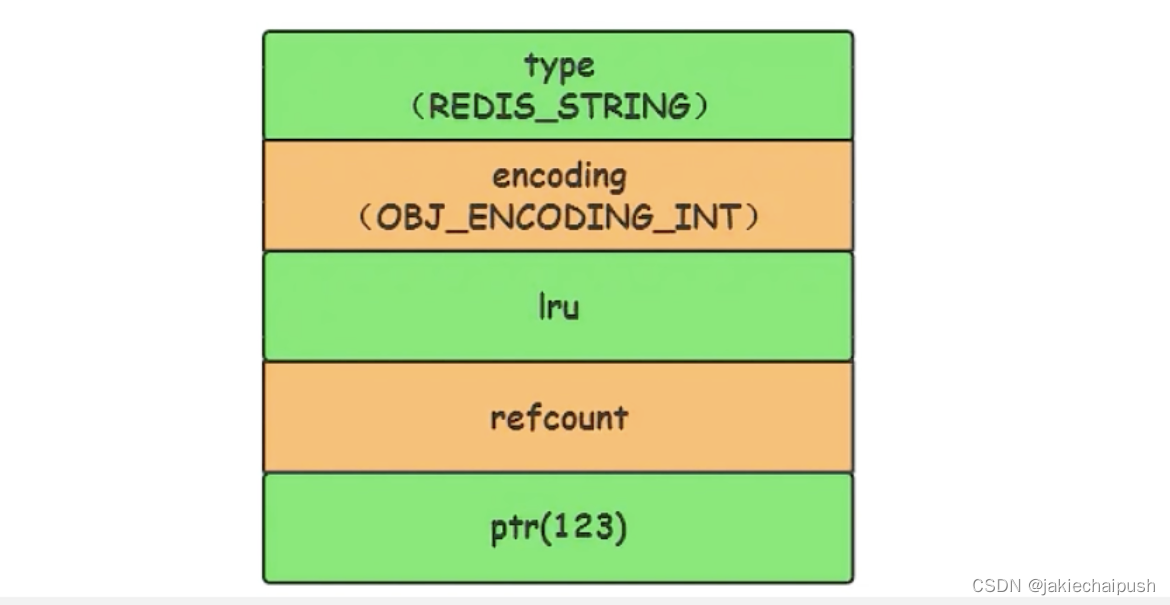
- int
当字符串键值的内存可以用一个64位有符号整数表示时,Redis会将键值转化为long型来存储,此时即对于OBJ_ENDOCDING_INT编码类型。内存内存结构如下:
OBJECT_ENCODING_INT这个时Redis定义的一个常量,我们可以在object.c文件中看到
char *strEncoding(int encoding) {
switch(encoding) {
case OBJ_ENCODING_RAW: return "raw";
case OBJ_ENCODING_INT: return "int";
case OBJ_ENCODING_HT: return "hashtable";
case OBJ_ENCODING_QUICKLIST: return "quicklist";
case OBJ_ENCODING_LISTPACK: return "listpack";
case OBJ_ENCODING_INTSET: return "intset";
case OBJ_ENCODING_SKIPLIST: return "skiplist";
case OBJ_ENCODING_EMBSTR: return "embstr";
case OBJ_ENCODING_STREAM: return "stream";
default: return "unknown";
}
}
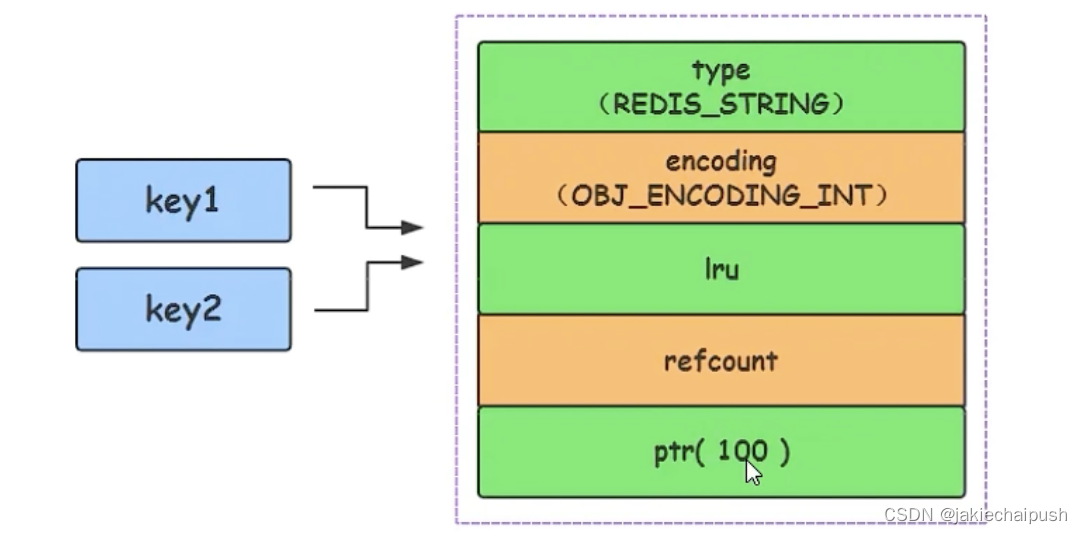
Redis启动时会预先建立10000个分别存储0~9999的redisObject变量做为共享变量,这意味着如果set字符串的键值在0~10000之间的话,就可以直接指向功效变量,而不需要再建立新对象,此时键值不占内存。(这和java中有些包装类设置缓存的原理一样)。如下面两条命令:
set k1 100
set k2 100
上面的缓存可以再server.h中可以看到定义:
#define OBJ_SHARED_INTEGERS 10000 //缓存去大小
struct sharedObjectsStruct {
robj *ok, *err, *emptybulk, *czero, *cone, *pong, *space,
*queued, *null[4], *nullarray[4], *emptymap[4], *emptyset[4],
*emptyarray, *wrongtypeerr, *nokeyerr, *syntaxerr, *sameobjecterr,
*outofrangeerr, *noscripterr, *loadingerr,
*slowevalerr, *slowscripterr, *slowmoduleerr, *bgsaveerr,
*masterdownerr, *roslaveerr, *execaborterr, *noautherr, *noreplicaserr,
*busykeyerr, *oomerr, *plus, *messagebulk, *pmessagebulk, *subscribebulk,
*unsubscribebulk, *psubscribebulk, *punsubscribebulk, *del, *unlink,
*rpop, *lpop, *lpush, *rpoplpush, *lmove, *blmove, *zpopmin, *zpopmax,
*emptyscan, *multi, *exec, *left, *right, *hset, *srem, *xgroup, *xclaim,
*script, *replconf, *eval, *persist, *set, *pexpireat, *pexpire,
*time, *pxat, *absttl, *retrycount, *force, *justid, *entriesread,
*lastid, *ping, *setid, *keepttl, *load, *createconsumer,
*getack, *special_asterick, *special_equals, *default_username, *redacted,
*ssubscribebulk,*sunsubscribebulk, *smessagebulk,
*select[PROTO_SHARED_SELECT_CMDS],
*integers[OBJ_SHARED_INTEGERS],
*mbulkhdr[OBJ_SHARED_BULKHDR_LEN], /* "*<value>\r\n" */
*bulkhdr[OBJ_SHARED_BULKHDR_LEN], /* "$<value>\r\n" */
*maphdr[OBJ_SHARED_BULKHDR_LEN], /* "%<value>\r\n" */
*sethdr[OBJ_SHARED_BULKHDR_LEN]; /* "~<value>\r\n" */
sds minstring, maxstring;
};
下面我们看看redis时如何利用这些缓存起来的对象的
/* Try to encode a string object in order to save space */
robj *tryObjectEncodingEx(robj *o, int try_trim) {
long value;
sds s = o->ptr;
size_t len;
serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);
if (!sdsEncodedObject(o)) return o;
if (o->refcount > 1) return o;
len = sdslen(s);
if (len <= 20 && string2l(s,len,&value)) {
if ((server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS)
{
decrRefCount(o);
return shared.integers[value];
} else {
if (o->encoding == OBJ_ENCODING_RAW) {
sdsfree(o->ptr);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*) value;
return o;
} else if (o->encoding == OBJ_ENCODING_EMBSTR) {
decrRefCount(o);
return createStringObjectFromLongLongForValue(value);
}
}
}
/* If the string is small and is still RAW encoded,
* try the EMBSTR encoding which is more efficient.
* In this representation the object and the SDS string are allocated
* in the same chunk of memory to save space and cache misses. */
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
if (o->encoding == OBJ_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s));
decrRefCount(o);
return emb;
}
/* We can't encode the object...
* Do the last try, and at least optimize the SDS string inside */
if (try_trim)
trimStringObjectIfNeeded(o, 0);
/* Return the original object. */
return o;
}
robj *tryObjectEncoding(robj *o) {
return tryObjectEncodingEx(o, 1);
}
关键是下面这几句代码
if ((server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS)
{
decrRefCount(o);
return shared.integers[value];
} else {
if (o->encoding == OBJ_ENCODING_RAW) {
sdsfree(o->ptr);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*) value;
return o;
} else if (o->encoding == OBJ_ENCODING_EMBSTR) {
decrRefCount(o);
return createStringObjectFromLongLongForValue(value);
}
}
value < OBJ_SHARED_INTEGERS判断当前值是否小于10000,如何小于shared.integers[value]中直接拿值,上面也是对INT类型编码的核心源码
- embstr
上面我们分析了int类型是如何编码的,下面我们看看embstr类型是如何编码的
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
//创建redisObject对象并分配内存,使用 zmalloc 函数分配了一块内存,用于存储字符串对象。这块内存的大小包括了字符串对象结构体 robj 的大小、sdshdr8 结构体的大小以及字符串的长度 len 加上一个字节用于字符串的结束符 \0。
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
//定义了一个 sdshdr8 结构体指针 sh,它指向了 robj 结构体之后的内存地址。这是因为 robj 结构体之后的内存空间被用来存储字符串数据的头信息。
struct sdshdr8 *sh = (void*)(o+1);
//类型表示为String类型
o->type = OBJ_STRING;
//编码为embstr编码
o->encoding = OBJ_ENCODING_EMBSTR;
//设置了 robj 结构体中的 ptr 字段为指向 sdshdr8 结构体之后的内存地址,即指向字符串的实际内容。
o->ptr = sh+1;
//引用计数为1
o->refcount = 1;
//使用次数0
o->lru = 0;
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
首先len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT判断当前字符串的长度是否小于44,这前面也讲过为什么是44,如果小于则符合emstr类型,则调用createEmbeddedStringObject方法。我们看到ptr指针指向的位置为sh+1。我们从源码可以看出sh是robj 结构体位置,这就说明一个现象,即字符串SDS结构体和其对应的redisObject对象分配在同一连续内存空间,就像讲sds嵌入到redisObject中。
简单来说redisObject和对应的sdshdr8是在内存汇总紧挨着的,使用 embstr 编码时,字符串的内容直接存储在 robj 结构体之后的内存空间中,而不需要额外分配存储空间。这样做的好处是减少了内存分配和内存碎片,提高了内存使用效率。
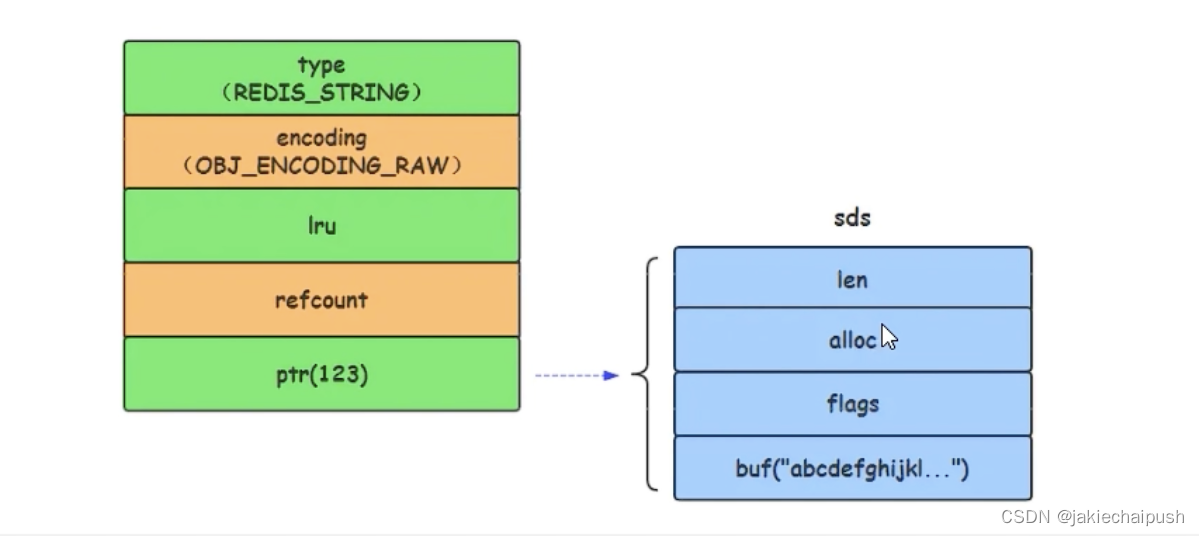
- raw
我们继续回到tryEncodingEx方法,如果我们对象的字节数大于44,我们此时就是创建raw类型
obj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
o->lru = 0;
return o;
}
当字符串长度大于44的超长字符串时,Redis则将键值的内部编码方式改为OBJ_ENCODING_RAW格式,这与OBJ_ENCODING_EMBSTR的编码方式不同,此时动态字符串sds的内存与其依赖的redisObject内存不再连续。
下面看一种特殊情况:

5. 总结
redis底层会根据用户给的键值使用不同的编码格式,自适应地选择较优化的内存编码格式,而这一切对用户完全透明!