KMP算法及其优化
为什么要使用kmp算法?
传统的字符串模式匹配主串和字串的指针在不匹配时都要重复的进行回退。而有些回退的比较意义不大。这就造成了算法的效率不高。时间复杂度为o(mn)。而kmp算法恰恰就是为了解决这一个问题而产生的。在kmp算法中主串指针不必回退。而下一次用字串的哪个字符去匹配只与字串有关,与主串无关,这也就大大的提高了算法的效率,时间复杂度优化到了o(m+n)。
kmp算法的灵魂(next数组)
手算方式1(好理解方便做题的方式)
也就是说无论字串是什么next[1]的值都是0;
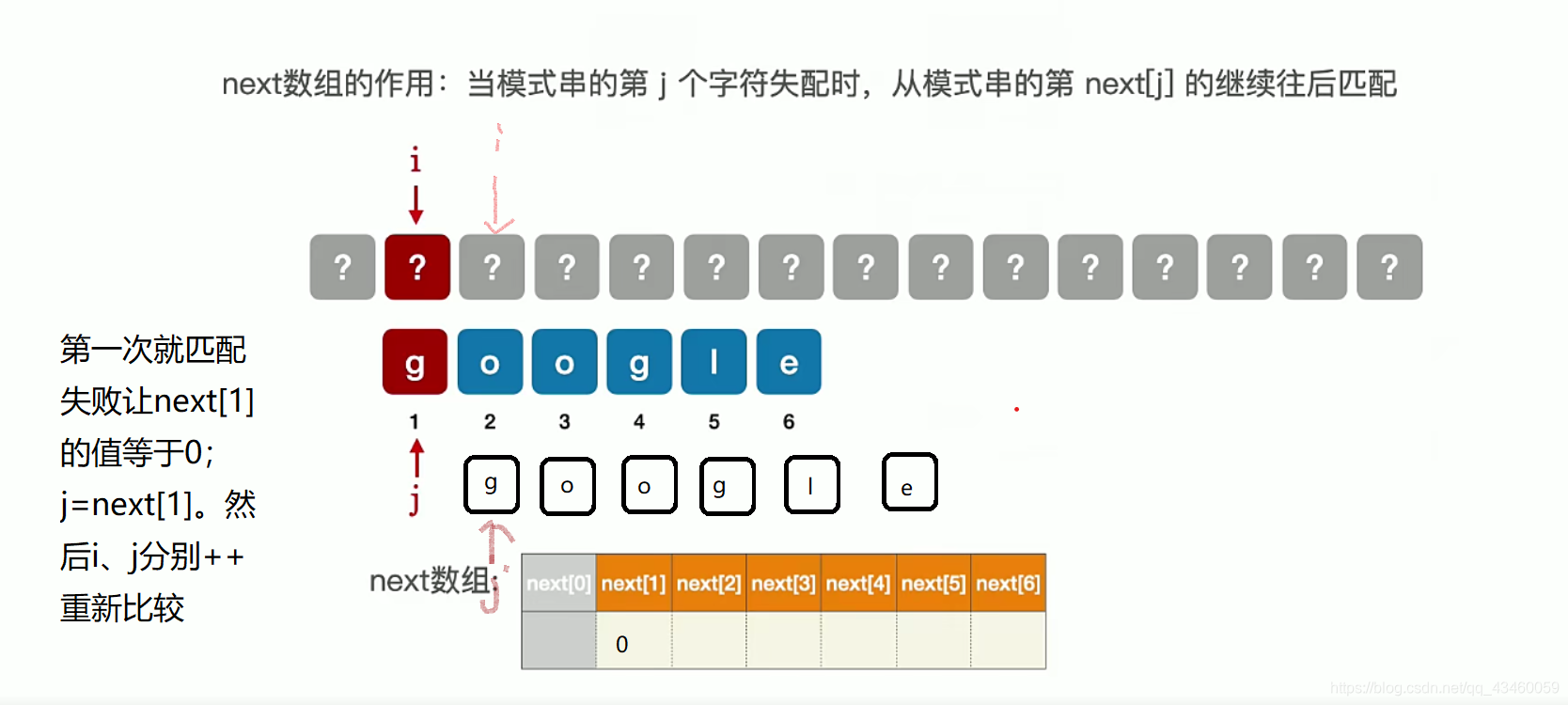
当第二个不匹配的时候,模式串向后滑动一定是从第一个进行比较所以无论子串是什么值next[2]都等于1.
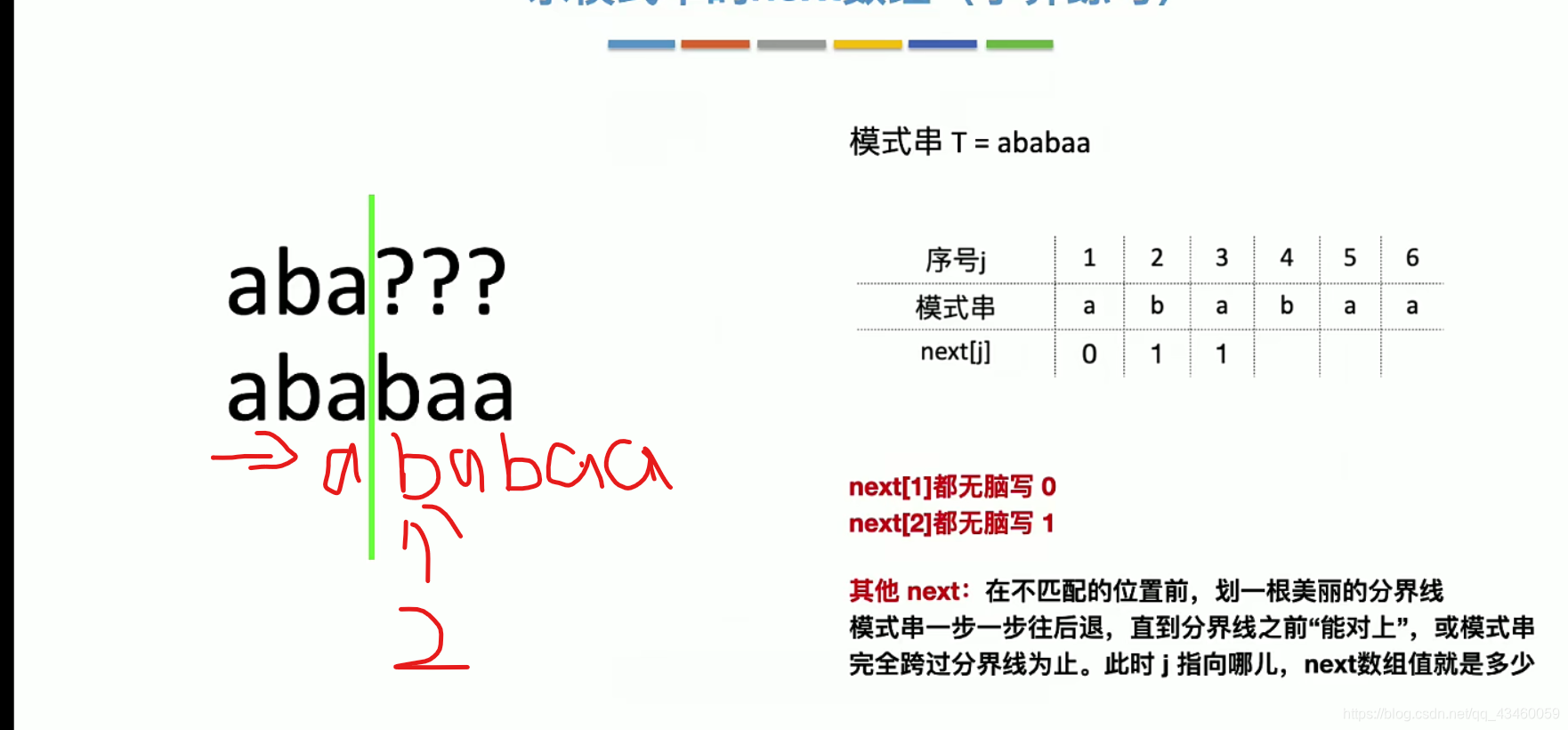
当在第四个元素失配的时候在第四个元素前画一条线。移动子串直到移动后线前的元素再次与移动前的线前元素匹配时,线后第一个元素所指的位置即为next值。之后next[j]的求法与之相同。

手算方法2(和机算方法类似)
方法二主要的思想是算相同的前缀和后缀的最大长度+1。下面是这个方法的演示。

kmp算法求next数组C语言代码实现
void getnext(string t ,int next[]){
int j=0;//前缀的最后一个元素
int i=1;//后缀的最后一个元素
next[1]=0;
while(i<t.length){
if(j==0||t.data[i]==t.data[j]){
i++;
j++;
next[i]=j;
}
else{
j=next[j];//回溯去找到那个最长的前缀
}
}
}
代码分析

代码优化
这段代码在某些类型的字符串中还是会出现缺陷的。如串aaaaab。下面来分析一下它的缺陷及优化思路。

kmp算法优化后完整实现C语言
#include<stdio.h>
#include<stdlib.h>
#define maxsize 255
typedef struct {
char data[maxsize];
int length;
}string;
void init(string &s){
s.length=0;
}
void create(string &s){
init(s);
char x;
printf("请输入串($结束):\n");
scanf(" %c",&x);//前面加个空格防止把回车当成下一个串的输入
int i=1;
while(x!='$'){
s.data[i++]=x;
s.length++;
scanf(" %c",&x);
}
printf("串为\n");
for(int i=1;i<=s.length;i++){
printf("%c ",s.data[i]);
}
printf("\n");
}
void getnext(string t ,int next[]){
int j=0;//前缀的最后一个元素
int i=1;//后缀的最后一个元素
next[1]=0;
while(i<t.length){
if(j==0||t.data[i]==t.data[j]){
i++;
j++;
if(t.data[i]!=t.data[j])//如果是相等的再比较时必然还会适配,重复了很多次无用比较效率低。
{
next[i]=j;
}
else{
next[i]=next[j];//这个时候回溯到层的next看什么时候相不等,直到不等才有意义。
}
}
else{
j=next[j];//回溯去找到那个最长的前缀
}
}
}
int indexkmp(string s,string t,int next[])
{
int i=1,j=1;
while(i<=s.length&&j<=t.length){
if(j==0||s.data[i]==t.data[j]){
i++;
j++;
}
else {
j=next[j];
}
}
if(j>t.length){
printf("匹配成功") ;
printf("%d ",i-t.length) ;
}
else {
printf("匹配失败") ;
}
}
int main(){
string s,t;
int next[maxsize];
create(s);
create(t);
getnext(t,next);
indexkmp(s,t,next);
return 0;
}