指针
指针 是存储变量地址的变量,可以用来间接访问和操作变量的值。
(1)在 Go 中:
- 声明指针 使用
*符号。 - 获取变量地址 使用
&符号。 - 解引用指针 使用
*符号。
package main
import "fmt"
func main() {
a := 42 // 定义普通变量
p := &a // 获取 a 的地址,赋值给指针变量 p
fmt.Println(p) // 输出指针地址
fmt.Println(*p) // 解引用指针,输出 42
*p = 100 // 通过指针修改 a 的值
fmt.Println(a) // 输出 100
}
& 是取地址操作符,返回变量的内存地址。
* 是解引用操作符,用于访问指针指向的值。
(2)指针作为函数参数
package main
import "fmt"
func modify(p *int) {
*p = *p + 1 // 修改指针指向的值
}
func main() {
a := 42
modify(&a) // 传递变量地址
fmt.Println(a) // 输出 43
}
(3)指针和切片的关系
切片本身是一个指向底层数组的结构体,因此切片本质上已经是引用类型。对切片的修改会直接反映到底层数组上,无需显式使用指针。
(4)Go 中不能使用指针的地方
- 不能指向常量:Go 不允许取常量的地址,因为常量本质上不存在具体的内存地址。
- 不能进行指针运算:Go 中不支持像 C 那样的指针运算,无法对指针进行加减操作,这是为了避免内存安全问题。
(5)指针的常见误区
- 指针未初始化 指针默认值为
nil,对未初始化的指针解引用会导致运行时错误。
package main
func main() {
var p *int
*p = 10 // 运行时错误:nil pointer dereference
}
要解决这个问题,需要为指针分配内存,让它指向合法的内存区域。
package main
import "fmt"
func main() {
var p *int
//*p = 10 // 运行时错误:nil pointer dereference
p = new(int)
*p = 10
fmt.Println(*p)
}
(6)Go 提供了两种内存分配方法:new 和 make,分别用于不同的用途。
new函数
- 用于分配内存。
- 返回一个指向指定类型零值的指针。
- 适合简单类型(如
int、struct)的内存分配。
make函数:
- 用于初始化内置的数据结构(
slice、map和channel)。 - 返回初始化后的引用,不能用于简单的类型分配。
| 特性 | new | make |
|---|---|---|
| 作用 | 分配内存,返回指针,未初始化 | 分配并初始化内置数据结构 |
| 适用类型 | 值类型(如 int、struct) | 引用类型(slice、map、channel) |
| 返回值 | 指针(*T) | 初始化后的引用(slice、map 或 channel) |
| 是否初始化数据 | 分配零值内存,未完全初始化 | 初始化完成,直接可用 |
| 常见场景 | 指针分配、数据封装 | 切片、映射、通道的初始化 |
new 用于为值类型分配内存,并返回指向该内存的指针。
- new 只负责分配内存,并初始化为零值。
- 不做任何其他复杂操作。
- 返回值是一个指针,可以直接解引用操作。
package main
import "fmt"
func main() {
p := new(int) // 分配一个 int 的内存
fmt.Println(p) // 输出:内存地址,例如 0xc000012078
fmt.Println(*p) // 输出:0,指针指向的零值
*p = 42 // 修改指针指向的值
fmt.Println(*p) // 输出:42
}
type Node struct {
Value int
Next *Node
}
root := new(Node) // 分配内存并初始化为零值
root.Value = 10
fmt.Println(root) // 输出:&{10 <nil>}
make 用于初始化内置的引用类型:slice、map 和 channel。这些类型在分配内存后,必须进行初始化才能正常使用。不分配默认是 nil,无法直接使用,必须通过 make 初始化后,底层数组才会分配内存。
package main
import "fmt"
func main() {
slice := make([]int, 3, 5) // 创建长度为 3,容量为 5 的切片
fmt.Println(slice) // 输出:[0 0 0]
}
package main
import "fmt"
func main() {
m := make(map[string]int) // 创建空 map
m["key"] = 42
fmt.Println(m) // 输出:map[key:42]
}
package main
import "fmt"
func main() {
ch := make(chan int, 2) // 创建一个缓冲区大小为 2 的通道
ch <- 1
fmt.Println(<-ch) // 输出:1
}
Map
map 是一种无序集合,用于存储键值对。
- 键的要求:键必须是可以比较的类型(如 int、string、float、struct,但不能是 slice、map 或 function)。
- 值的类型:可以是任何类型,包括另一个 map、slice 或自定义类型。
- 零值:未初始化的 map 是 nil,对其进行操作会导致运行时错误。
(1)make初始化
package main
import "fmt"
func main() {
m := make(map[string]int) // 创建一个空的 map
m["key1"] = 10
m["key2"] = 20
fmt.Println(m) // 输出:map[key1:10 key2:20]
}
(2)使用字面量初始化
package main
import "fmt"
func main() {
m := map[string]int{
"key1": 10,
"key2": 20,
}
m["key3"] = 30
fmt.Println(m) // 输出:map[key1:10 key2:20 key3:30]
}
(3)插入-更新-删除
package main
import "fmt"
func main() {
m := make(map[string]int)
m["key1"] = 42 // 插入
m["key2"] = 11 // 插入
fmt.Println(m) // 输出:map[key1:42 key2:11]
m["key1"] = 100 // 更新
fmt.Println(m) // map[key1:100 key2:11]
delete(m, "key1") // 删除
fmt.Println(m) // 输出:map[key2:11]
}
(4)查找-判断键是否存在-遍历
package main
import "fmt"
func main() {
m := make(map[string]int)
m["key1"] = 42 // 插入
m["key2"] = 11 // 插入
value := m["key1"] // 如果 key 存在,返回对应值;如果不存在,返回值类型的零值
fmt.Println(value) // 输出:0
value_new, exists := m["key3"]
if exists {
fmt.Println("Key exists with value:", value_new)
} else {
fmt.Println("Key does not exist")
}
for key, value := range m {
fmt.Printf("Key: %s, Value: %d\n", key, value)
}
/**
42
Key does not exist
Key: key1, Value: 42
Key: key2, Value: 11
*/
}
(5)嵌套 map
package main
import "fmt"
func main() {
nestedMap := make(map[string]map[string]int)
nestedMap["outer"] = make(map[string]int)
nestedMap["outer"]["inner"] = 42
fmt.Println(nestedMap) // 输出:map[outer:map[inner:42]]
}
Map的实现原理
(1)在 Go 中,map 使用 哈希表(hash table) 实现。每个 map 由以下部分组成:
- 桶(bucket)
- map 将键通过哈希函数转换为哈希值,并将哈希值分配到特定的桶中。
- 每个桶存储多个键值对。
- 哈希函数
- 根据键生成一个哈希值,确定键存储的桶位置。
- 哈希函数确保键均匀分布,减少冲突。
-
溢出桶
当一个桶中的键值对超出容量时,会创建溢出桶链表,存储额外的数据。 -
存储模型
type hmap struct {
count int // 当前键值对数量
buckets unsafe.Pointer // 指向桶数组
hash0 uint32 // 哈希种子,防止哈希冲突攻击
...
}
- 桶的结构:
type bmap struct {
tophash [bucketSize]uint8 // 哈希值的高位,快速比较
keys [bucketSize]KeyType
values [bucketSize]ValueType
overflow *bmap // 指向溢出桶
}
- map 的操作原理
- 插入
a. 使用哈希函数计算键的哈希值。
b. 根据哈希值分配到对应桶。
c. 如果桶未满,直接插入;如果满了,创建溢出桶。 - 查找
a. 通过哈希函数定位桶。
b. 遍历桶中键值对,比较键值。
c. 如果找不到,查找溢出桶。 - 删除
a. 定位桶,找到键所在的位置。
b. 将键值对置为无效,但不释放内存。
- map 的特性和性能
- 性能
a. 时间复杂度:- 插入、删除、查找的平均时间复杂度为 O(1)。
- 在最坏情况下(大量哈希冲突),复杂度为 O(n)。
- 哈希函数的性能和均匀分布性决定了 map 的效率。
- 无序性
a. map 是无序的,因为键值对分布在不同的桶中。
b. 遍历顺序可能会随运行环境而变化。 - 扩容
a. 当键值对数量超过负载因子(通常为桶总数的 6.5 倍)时,map 会进行扩容。- 扩容过程:
- 分配更大的桶数组。
- 重新计算所有键的哈希值并分配到新桶中。
- map 的常见问题
a. 使用未初始化的 map
var m map[string]int
m["key"] = 42 // 运行时错误:assignment to entry in nil map
解决方法:使用 make 初始化:
m := make(map[string]int)
m["key"] = 42
b. 并发读写问题
map 不是线程安全的。如果多个 goroutine 同时读写 map,会导致运行时错误。 解决方法:
- 使用
sync.Mutex或sync.RWMutex保护 map。 - 使用
sync.Map,这是线程安全的 map。
更详细:https://cloud.tencent.com/developer/article/1468799
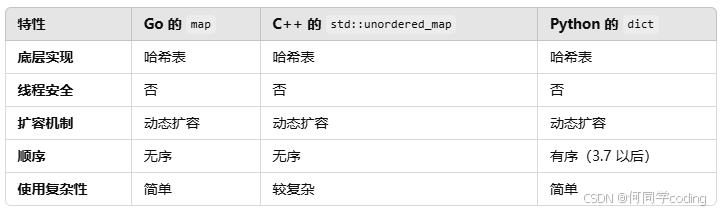
结构体
(1)Go 语言中的结构体(struct)是复合数据类型,用于将多个字段组合成一个对象。结构体是 Go 面向对象编程的核心,用来组织数据和关联行为。掌握结构体的使用和底层实现对编写高效、清晰的 Go 程序非常重要。
- 定义结构体
type Person struct {
Name string
Age int
}
零值初始化:
var p Person
fmt.Println(p) // 输出:{ 0}
字面量初始化:
字段顺序初始化(不推荐):
p := Person{"Alice", 25}
fmt.Println(p) // 输出:{Alice 25}
- 字段操作
- 访问字段
package main
import "fmt"
type Person struct {
Name string
Age int
}
func main() {
p := Person{
Name: "Alice",
Age: 25,
}
fmt.Println(p.Name) // 输出:Alice
p.Age = 30 // 修改字段值
fmt.Println(p) // 输出:{Alice 30}
}
- 指针操作 使用指针操作结构体时,语法会自动解引用:
ptr := &p
ptr.Age = 35
fmt.Println(p) // 输出:{Alice 35}
- 方法与结构体
Go 中没有类的概念,但可以为结构体定义方法。方法通过 receiver(接收者)关联到结构体上。
定义方法:
- a. 值接收者方法
func (p Person) Greet() {
fmt.Printf("Hello, my name is %s.\n", p.Name)
}
p := Person{Name: "Alice", Age: 25}
p.Greet() // 输出:Hello, my name is Alice.
- b. 指针接收者方法 如果需要修改结构体字段,使用指针接收者:
func (p *Person) IncrementAge() {
p.Age++
}
p.IncrementAge()
fmt.Println(p.Age) // 输出:26
- 匿名字段和嵌套
匿名字段(继承的替代)
- 匿名字段使结构体可以嵌套另一个结构体,而不需要显式字段名。
- 类似于继承,但 Go 语言没有真正的继承。
type Address struct {
City, Country string
}
type Employee struct {
Name string
Address // 匿名字段
}
e := Employee{Name: "John", Address: Address{City: "New York", Country: "USA"}}
fmt.Println(e.City) // 输出:New York
嵌套结构体
可以显式嵌套字段:
type Employee struct {
Name string
Address Address
}
e := Employee{Name: "John", Address: Address{City: "New York", Country: "USA"}}
fmt.Println(e.Address.City) // 输出:New York
- 结构体的比较
可比较性:
如果结构体的所有字段都是可比较的类型,则结构体本身也是可比较的。【包含切片、映射等不可比较字段的结构体不能直接比较。】
type Point struct {
X, Y int
}
p1 := Point{1, 2}
p2 := Point{1, 2}
fmt.Println(p1 == p2) // 输出:true
- 结构体与内存布局
对齐与内存优化
结构体字段在内存中按照 对齐原则 分布。字段类型和顺序会影响内存使用:
type A struct {
Bool bool
Int8 int8
Int64 int64
}
// 内存布局:Bool (1B) + 填充(7B) + Int8 (1B) + 填充(7B) + Int64 (8B)
// 总大小为 24 字节
优化:
type B struct {
Int64 int64
Int8 int8
Bool bool
}
// 内存布局:Int64 (8B) + Int8 (1B) + Bool (1B) + 填充 (6B)
// 总大小为 16 字节
- 结构体的零值与内存分配
- a. 零值:
未初始化的结构体的每个字段都是对应类型的零值。 - b. 分配内存:
使用 new 分配结构体的指针:
p := new(Person) // 返回 *Person
fmt.Println(*p) // 输出:{"" 0}
使用 make 初始化包含结构体的切片、映射或通道。
slice := make([]Person, 0)
- 结构体标签(Tags)
结构体字段可以包含标签,用于元信息存储,如 JSON、数据库映射。
package main
import (
"encoding/json"
"fmt"
)
type User struct {
ID int `json:"id"`
Name string `json:"name"`
}
func main() {
u := User{ID: 1, Name: "Alice"}
data, _ := json.Marshal(u)
fmt.Println(string(data)) // 输出:{"id":1,"name":"Alice"}
}