DCU整体硬件架构
DCU整体硬件架构
首先,DCU通过PCI-E总线与CPU处理器相连,它是CPU主机系统的一个硬件扩展,其存在的目的是为了对程序某些模块或者函数进行加速。虽然DCU是原硬件系统的一个扩展,接受CPU调度指挥,但是在运行程序时,它又保持相对独立性,又可以将其视为一个独立的系统。因此,DCU的硬件构造较为完整,例如有自己的计算单元、内存控制器、线程调度器等。同时一个主机系统在PCI-E总线上可以插入多张DCU与CPU进行互连,这使得一台主机的算力具有可扩展性,合理的利用多DCU程序可以获得更好的加速效果。
DCU是个相对完整的系统,由以下几个关键模块组成:
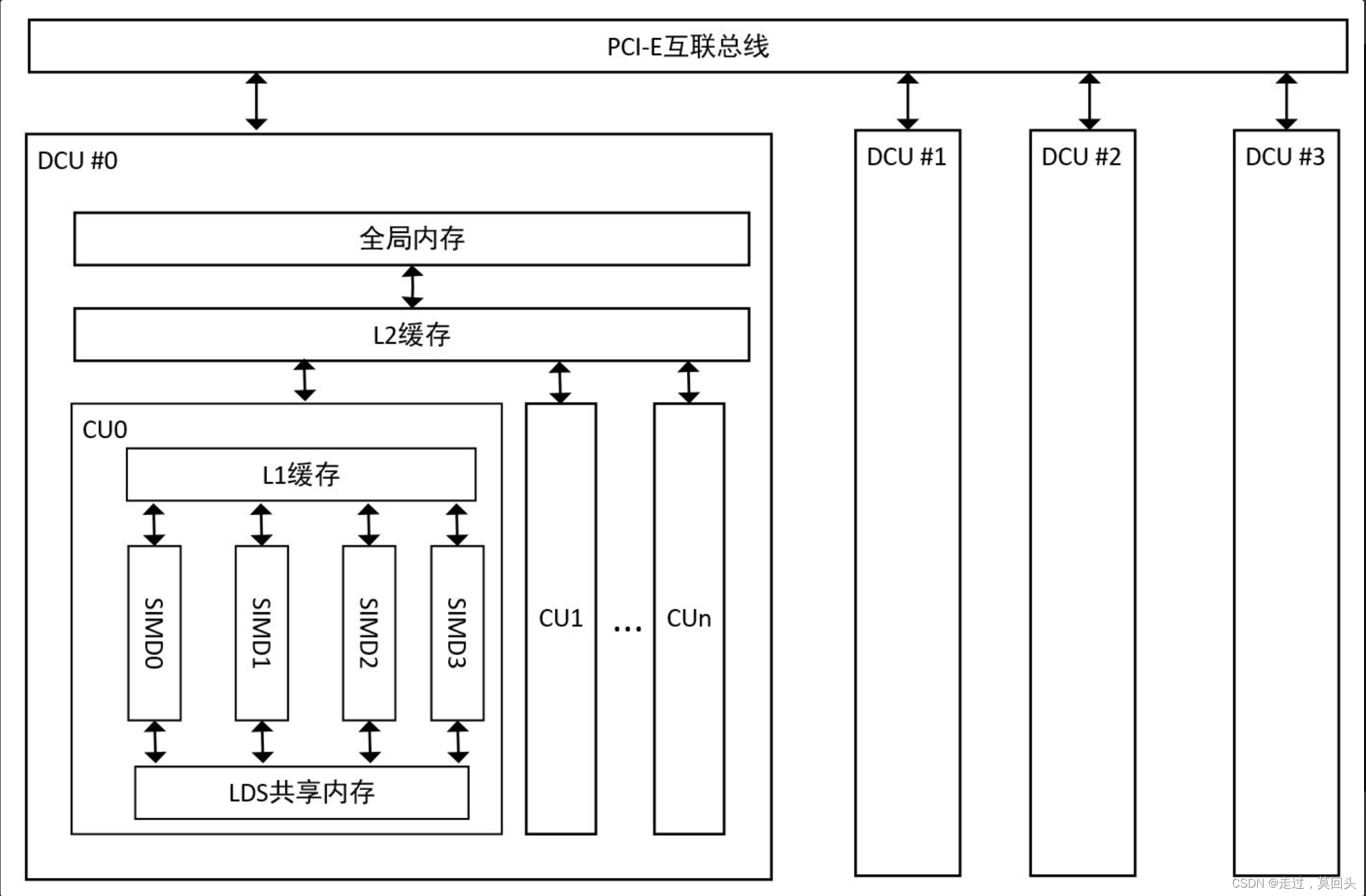
- 计算单元阵列,如图CU0、CU1等
- 缓存系统(L1一级缓存,L2二级缓存)
- 全局内存(global memory)
- CPU和DCU数据通路(DMA)
DCU芯片上有64个独立的计算单元(CU),每个CU又有4个独立的SIMD(单指令多数据)单元,每个SIMD单元又有16个向量ALU(算数逻辑单元),通俗的讲,可以认为一块DCU芯片上有4096个核心,每个向量ALU就对应一个线程。
虽然线程从概念上是独立执行的,但从DCU硬件来说是64个线程一组并行执行的,即一条指令发布后,一个SIMD单元中的16个ALU执行4轮完成,这64个线程被称为线程束(warp);一个SIMD单元有10个线程束的指令缓冲,所以最多可以同一时间段内并发执行10个线程束(受其他硬件资源的限制)。这样算64个计算单元×4个SIMD单元×10线程束×64线程=163840,这是DCU硬件最大同时支持的线程数。此外,这10个线程束可以来自不同的线程块或者核函数,意味着我们的DCU支持多个核函数并发。
计算单元上有高速的寄存器文件,每个SIMD单元有64KB的向量寄存器配额供向量ALU使用,负责存储我们在核函数中每个线程独有的局部变量。每个计算单元有64KB的局域数据共享(Local Data Share),负责存储核函数中以__shared__修饰符声明的变量,以实现同一线程块或同一线程束内的数据共享。