深度学习中的常见网络结构backbone汇总:
1、LeNet5
LeNet5源自论文“Gradient-Based Learning Applied to Document Recognition”
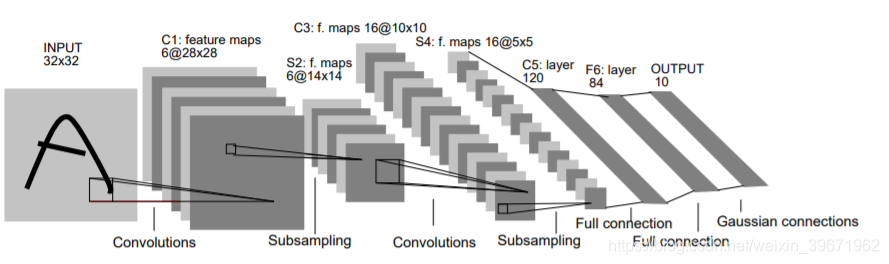
1998年,Yann LeCun等提出的LeNet5,用于手写数字识别的卷积神经网络。
LeNet5一共有5层:2个卷积层(conv1,conv2)+3个全连接层(fc3,fc4,fc5),基本架构为:conv1->pool1->conv2->pool2->fc3->fc4->fc5->softmax,总共有60k参数。
| layer | Kernel size | output |
|---|---|---|
| Input | / | 32×32×3 |
| Conv1 | 5×5×6,stride=1 | 6×28×28 |
| Maxpooling1 | 5×5,stride=1 | 6×28×28 |
| Conv2 | 5×5×16,stride=1 | 16×10×10 |
| Maxpooling2 | 2×2,stride=2 | 16×5×5 |
| Fc3 | 120 | |
| Fc4 | 84 | |
| Fc5 | 10 |
2、AlexNet
AlexNet源于论文 “ImageNet Classification with Deep Convolutional
Neural Networks”
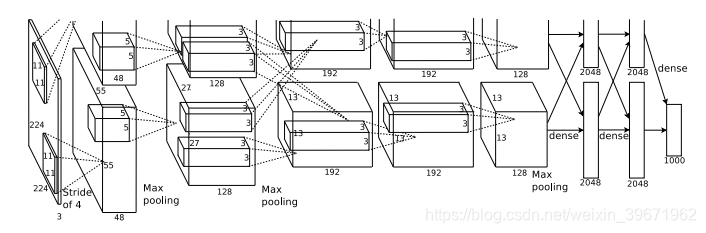
2012年,Alex Krizhevsky等提出AlexNet。AlexNet是LSVRC-2012的冠军网络,在ImageNet LSVRC-2012的比赛中,取得了top-5错误率为15.3%的成绩。
AlexNet一共有8层:5个卷积层(conv1,conv2,conv3,conv4,conv5)+3个全连接层(fc6,fc7,fc8),基本架构为:conv1->pool1->conv2->pool2->conv3–>conv4->conv5->pool5->fc6->fc7->fc8->softmax,总共有60M参数
| layer | Kernel size | output |
|---|---|---|
| Input | / | 227×227×3 |
| Conv1 | 11×11×96,stride=4 | 96×55×55 |
| Maxpooling1 | 3×3,stride=2 | 96×27×27 |
| Conv2 | 5×5×256,stride=1 | 256×27×27 |
| Maxpooling2 | 3×3,stride=2 | 256×13×13 |
| Conv3 | 3×3×384,stride=1 | 384×13×13 |
| Conv4 | 3×3×384,stride=1 | 384×13×13 |
| Conv5 | 3×3×256,stride=1 | 256×13×13 |
| Maxpooling5 | 3×3,stride=2 | 256×6×6 |
| Fc6 | 4096 | |
| Fc7 | 4096 | |
| Fc8 | 1000 |
AlexNet的关键点:
1、网络更深,参数更多。AlexNet的网络结构与LeNet-5相似:LeNet-5共有5层(2个卷积层+3个全连接层),60k参数;AlexNet共有8层(5个卷积层+3个全连接层),60M参数。
2、使用ReLU作为激活函数,训练更快。
3、 局部响应归一化(Local Response Normalization,LRN),在ReLU之后进行归一化处理。
4、采用数据增强和dropout来减少过拟合。
3、VGG
VGG源于论文“ Very Deep Convolutional Networks for Large-Scale Image Recognition”
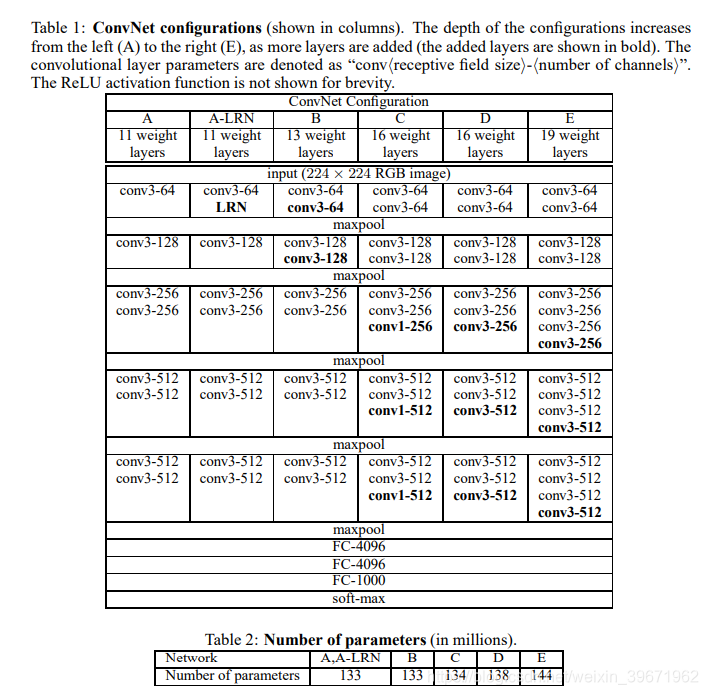
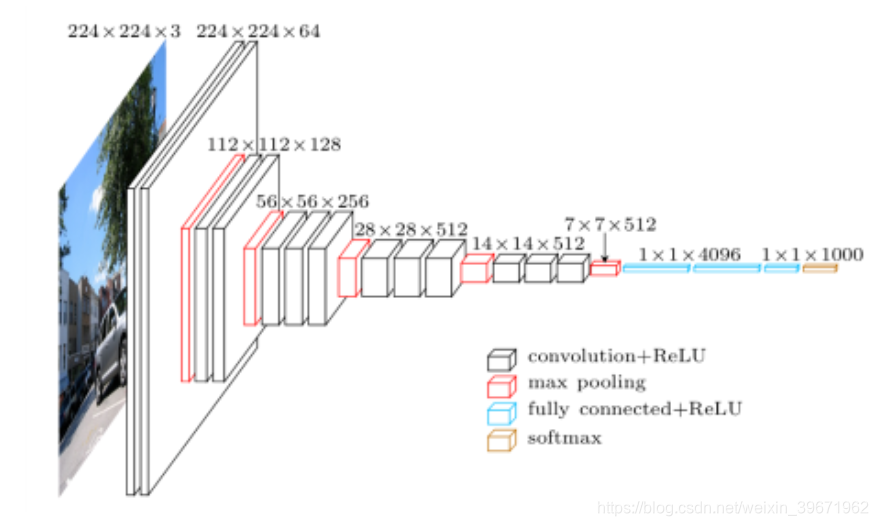
2014年,Karen Simonyan和Andrew Zisserman提出VGG,并获得了ILSVRC 2014比赛分类项目的第2名。VGG有两种结构:VGG-16和VGG-19,16表示有16层(conv+fc),19表示有19层,两者没有本质区别,只是VGG-19比VGG-16的网络更深。VGG的网络如下图:
VGG16一共有16层:13个卷积层(conv1-conv13)+3个全连接层(fc14,fc15,fc16),基本架构为:conv1->conv2->maxpooling->
conv3->conv4->maxpooling->conv5->conv6->conv7->maxpooling->conv8->conv9->conv10->maxpooling->conv11->conv12->conv13->maxpooling->fc14->fc15->fc16->softmax,总共有138M参数。
| layer | Kernel size | output |
|---|---|---|
| Input | / | 224×224×3 |
| Conv1 | 3×3×64,stride=1 | 224×224×64 |
| Conv2 | 3×3×64,stride=1 | 224×224×64 |
| maxpooling | 2×2,stride=2 | 112×112×64 |
| Conv3 | 3×3×128,stride=1 | 112×112×128 |
| Conv4 | 3×3×128,stride=1 | 112×112×128 |
| maxpooling | 2×2,stride=2 | 56×56×128 |
| Conv5 | 3×3×256,stride=1 | 56×56×256 |
| Conv6 | 3×3×256,stride=1 | 56×56×256 |
| Conv7 | 3×3×256,stride=1 | 56×56×256 |
| maxpooling | 2×2,stride=2 | 28×28×256 |
| Conv8 | 3×3×512,stride=1 | 28×28×512 |
| Conv9 | 3×3×512,stride=1 | 28×28×512 |
| Conv10 | 3×3×512,stride=1 | 28×28×512 |
| maxpooling | 2×2,stride=2 | 14×14×512 |
| Conv11 | 3×3×512,stride=1 | 14×14×512 |
| Conv12 | 3×3×512,stride=1 | 14×14×512 |
| Conv13 | 3×3×512,stride=1 | 14×14×512 |
| maxpooling | 2×2,stride=2 | 7×7×512 |
| Fc14 | 4096 | |
| Fc15 | 4096 | |
| Fc16 | 1000 |
VGG的关键点:
1、VGG的结构简洁,卷积层使用了相同大小的卷积核(3×3);汇合层采用最大池化(2×2,s=2)
2、采用小卷积核(3×3)组合,以取得大卷积核(7×7)相同的感受野,减少计算量。
感受野:两个3×3的卷积层串联的感受野相当于1个5×5的卷积层;3个3×3的卷积层串联的感受野相当于1个7×7的卷积层;
超参数量:3个3×3的卷积层串联:3×3×3×Cin×Cout ;1个7×7的卷积层:7×7×Cin×Cout。(其中,Cin表示输入的通道数,Cout表示输出的通道数)
3、证明了加深网络结构可提升性能
4、GoogLeNet/Inception
GoogLeNet源于论文 Going Deeper with Convolutions
2014年,Christian Szegedy等提出GoogLeNet,并获得了ILSVRC 2014挑战赛的第1名。GoogLeNet是基于Inception模块的深度网络模型,有4个版本(v1-v4)。
4.1 Inception V1
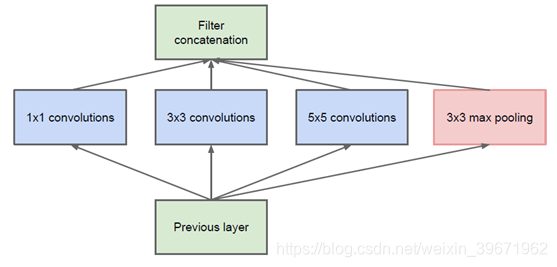
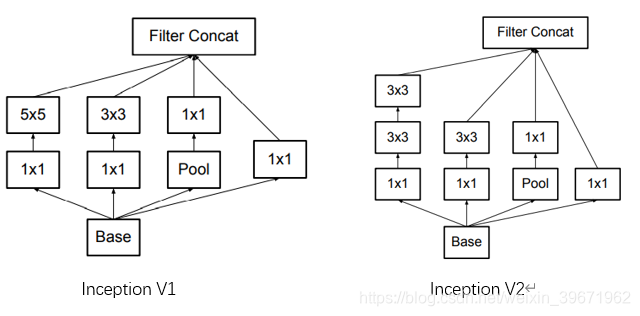
Inception就是把卷积和池化操作堆叠在一起,组装成一个模块,这种方法可以增加网络的宽度(3个卷积+1个池化通道相加),也增加了网络对尺度的适应性(采用了3个不同尺寸的卷积核1×1、3×3、5×5,起到了图像金字塔的作用),如下图:
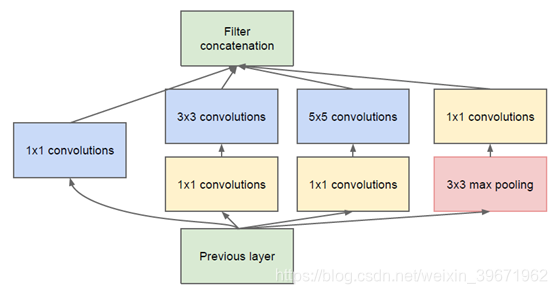
由于5x5的卷积核计算量太大,造成参数过多,特征图厚重,因此,将上述Inception改为下图:
对比改进前的Inception结构,我们可以发现,改进后的Inception只是在3x3前、5x5前、maxpooling后分别加上了1x1的卷积核。那么,1x1的卷积核起什么作用呢?这个1x1卷积的主要是为了减少维度,还用于修正线性激活(ReLU)。
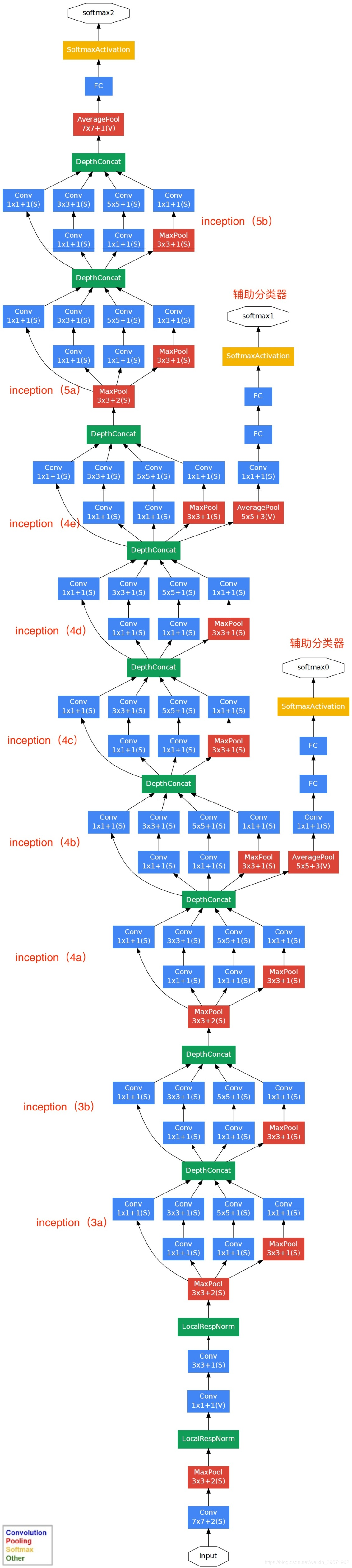
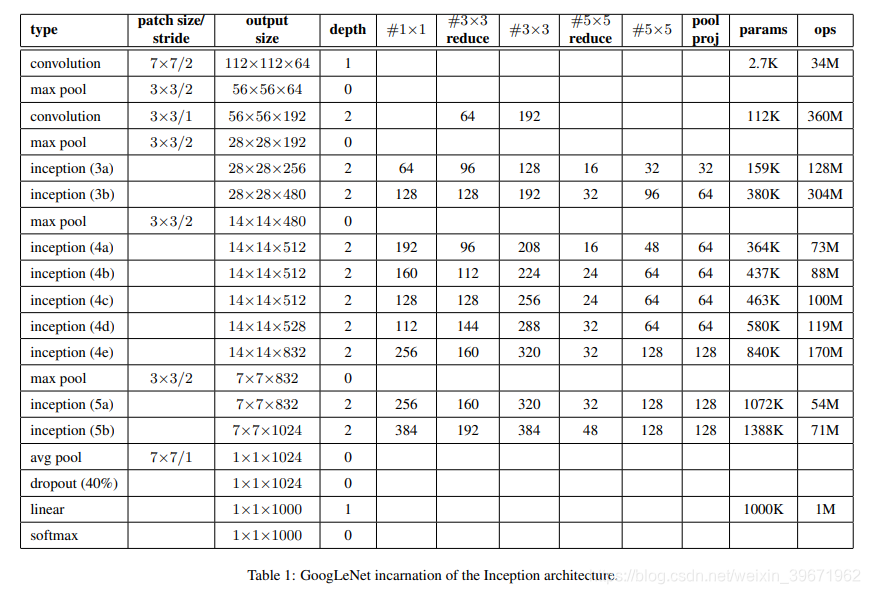
基于Inception的GoogLeNet网络结构:conv1 -> maxpool1 -> conv2-> maxpool2 -> Inception3 (3a, 3b) -> maxpool3 -> Inception4(4a,4b,4c,4d,4e)-> maxpool4 ->Inception5 (5a, 5b) -> avgpool5 -> FC->softmax,如下图:
GoogLeNet的关键点:
1、采用多分支结构(多分支分别计算,再级联结果),模块化结构(Inception)
2、采用1x1卷积的主要是为了减少维度;
3、使用average pooling(平均池化)来代替FC(全连接层);
4、为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的softmax会被去掉。
4.2 Inception V2、Inception V3
Inception V2和Inception V3源自论文“Rethinking the Inception Architecture for Computer Vision”
Inception V2、V3的突破点:
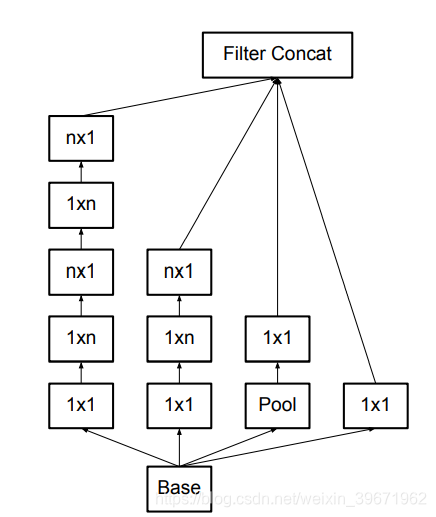
1、大卷积核分解成几个小卷积核替代:大尺寸的卷积核可以带来更大的感受野,但是会产生大量的参数,增加计算量。用2个3x3的卷积核替代一个5x5的卷积核,感受野不变,但是参数量减少了(Inception V2)。任意n×n的卷积都可以用1×n卷积后接n×1卷积来替代(Inception V3)。
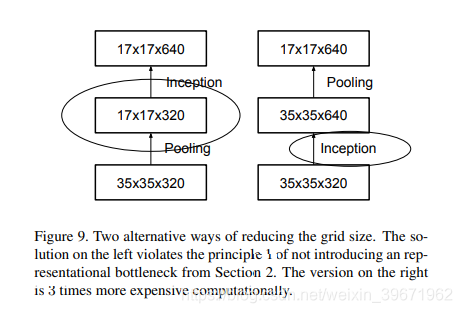
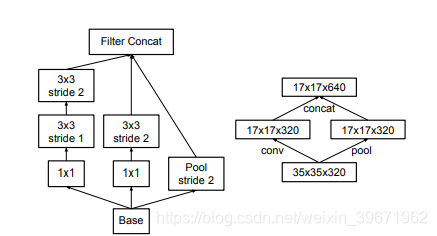
2、降低特征图的大小:降低特征图大小的两种方式:方式一:先池化,再Inception卷积(如下左图),这种方式会导致特征缺失;方式二:先Inception卷积,再池化(如下右图),这种方式会增加计算量。因此,在InceptionV2中,卷积核池化并行执行,再合并,这种并行化的网络结构可以降低计算量。
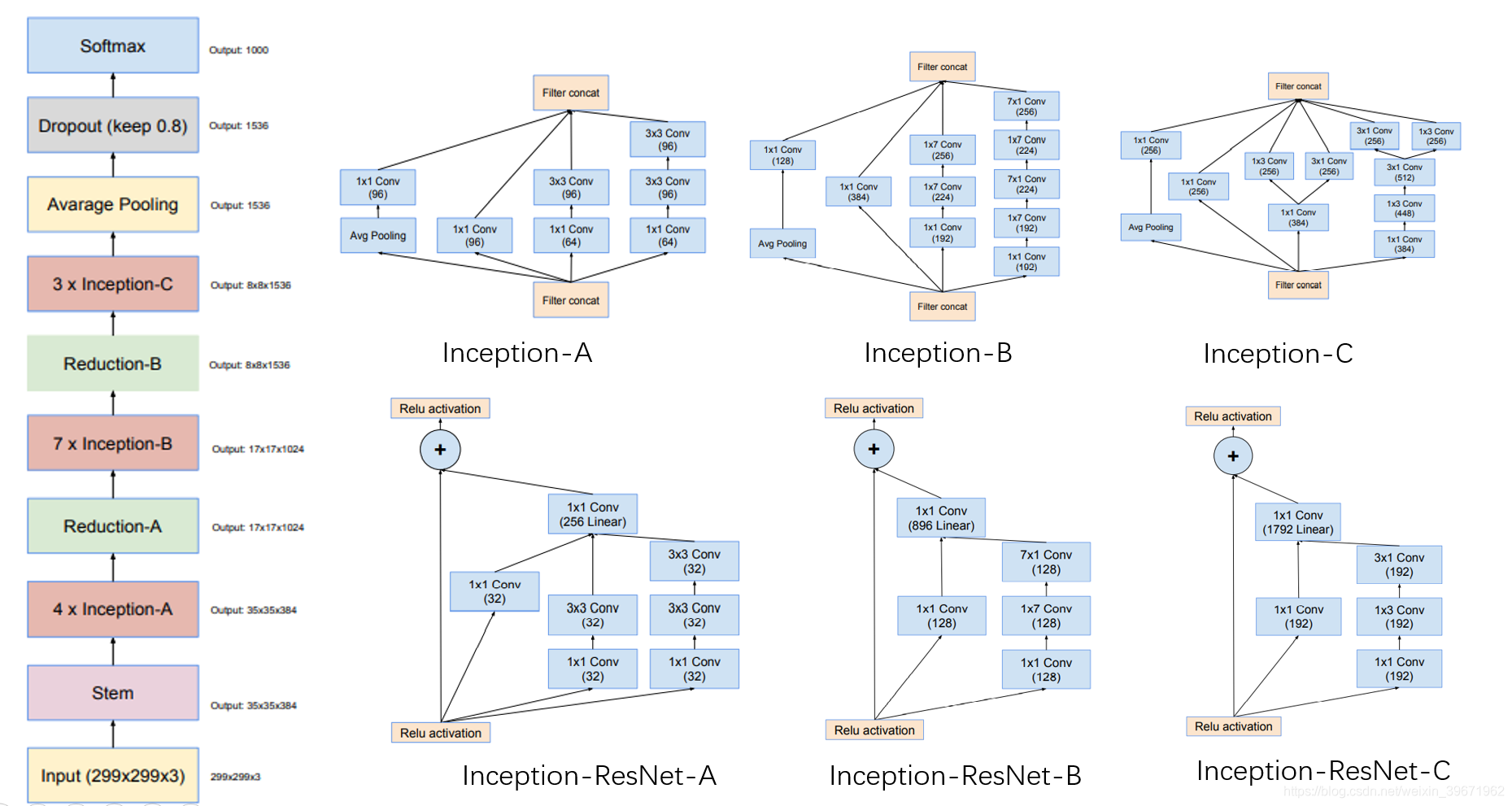
4.3 Inception V4
Inception V4源于论文“Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning”
Inception V4利用Inception模块与残差连接相结合,
5、ResNet
ResNet源自论文“Deep Residual Learning for Image Recognition”
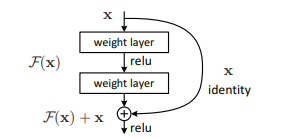
2015年,何凯明等提出了ResNet。ResNet是ILSVRC 2015的冠军网络,旨在解决网络加深后训练难度增大的问题。ResNet引入了残差网络结构(residual network),通过这种短路连接(如下图)来缓解反向传播时由于深度过深导致的梯度消失现象。
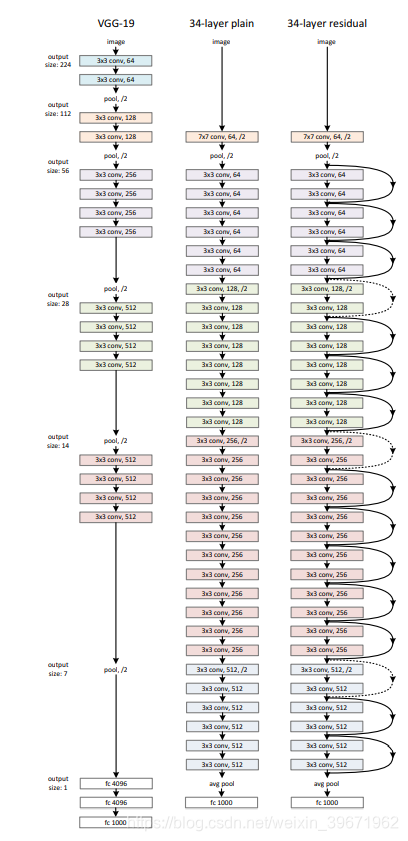
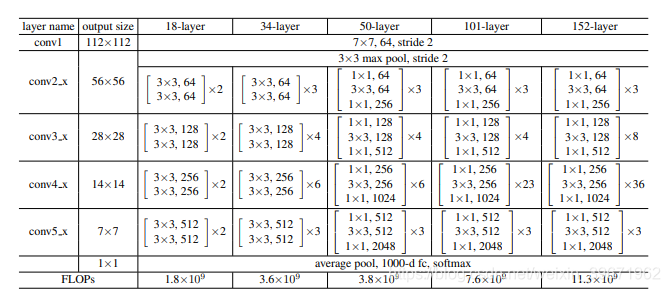
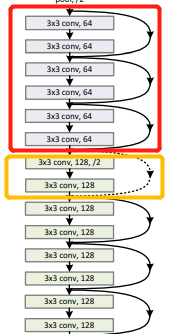
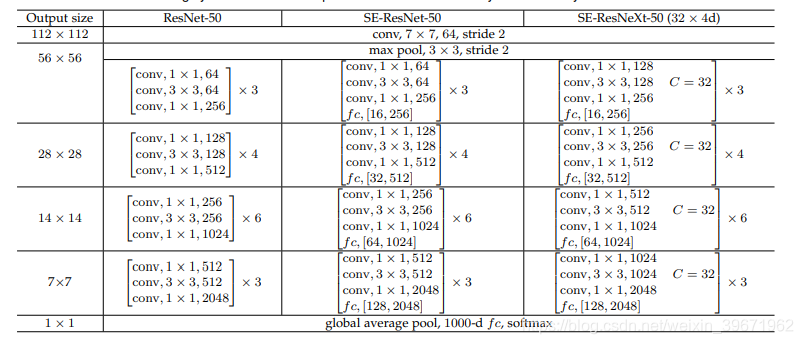
ResNet有18、34、50、101和152层的,网络结构如下所示:
ResNet的关键点:
1、采用短路连接来缓解由于网络深度过深导致的梯度消失现象。ResNet18、ResNet34采用下图左的连接方式,对于很深的网络(ResNet50、ResNet101、ResNet152)采用下图右的连接方式,主要是降低参数的数目,减少计算量。
2、ResNet大量使用了批量归一层。
3、ResNet 除了开头和结尾有pooling层,中间均采用Conv stride=2的卷积操作代替了pooling。
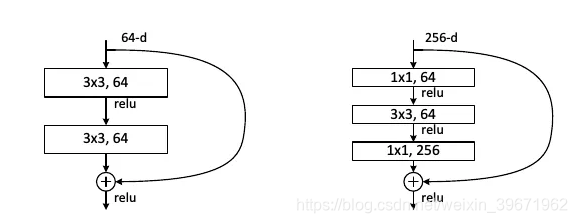
4、从ResNet的网络结构中,可以看出shortcut connections有实线和虚线连接之分。
实线连接部分(如红框):表示通道相同,计算方式为:H(x)=F(x)+x
虚线连接部分(如红框):表示通道不同,计算方式为:H(x)=F(x)+Wx,其中W是卷积操作,用来调整x维度的。
关于ResNet的改进主要有两种:一种是让ResNet更深(如preResNet);另一种是让ResNet更宽(比如 ResNeXt)。
5.1 preResNet
preResNet源于论文“Identity Mappings in Deep Residual Networks”
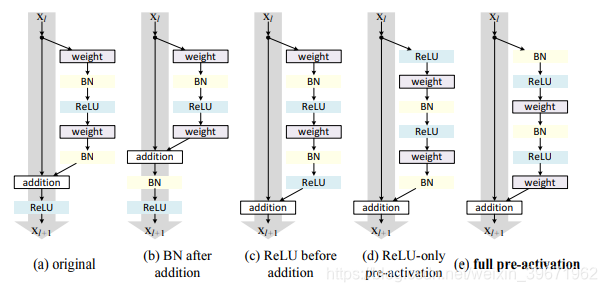
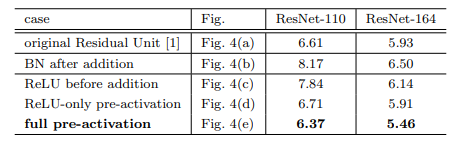
preResNet调整了residual模块中各层的顺序,如下图:
图(a):ResNet中的经典residual模块;
图(b):将BN移到addition后面,这样会影响信息的短路传播,使网络更难训练、性能也更差
图©:将ReLU移到addition前面,会使该分支的输出始终非负,使网络表示能力下降;
图(d):将ReLU提前,解决了(e)的非负问题,但ReLU无法享受BN的效果;
图(e):将ReLU和BN都提前解决了(d)的问题。
preResNet的短路连接(e)能更加直接的传递信息,进而取得了比ResNet更好的性能。
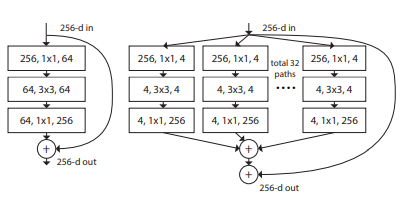
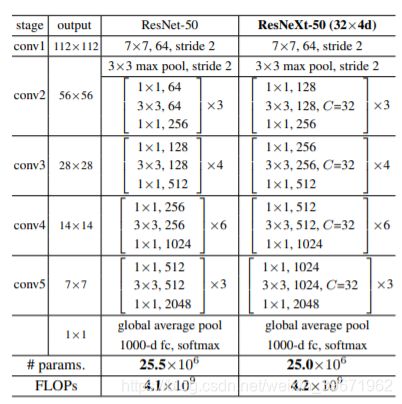
5.2 ResNeXt
ResNeXt源于论文“Aggregated Residual Transformations for Deep Neural Networks”,是ILSVRC 2016的冠军网络
ResNeXt是ResNet和Inception的结合体,通过调整了网络的宽度(借鉴Inception),增加分支数加宽了网络,有效的提升网络的性能。
6、DenseNet
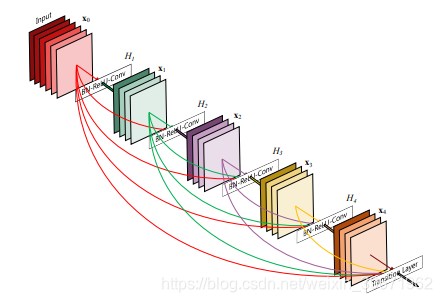
DenseNet源于论文“Densely Connected Convolutional Networks”
DenseNet作为CVPR2017年的Best Paper, 从特征的角度考虑,通过特征重用和旁路(Bypass)设置,减少了网络的参数量,缓解了梯度消失,这区别于ResNet(加深网络层数)和Inception(加宽网络结构)增强网络性能的方式。
DenseNet的优点:
1.缓解了梯度消失和模型退化的问题。
2.加强了feature的传递
3.旁路加强了特征的重用
4.一定程度上减少了参数数量。


7、SE Net
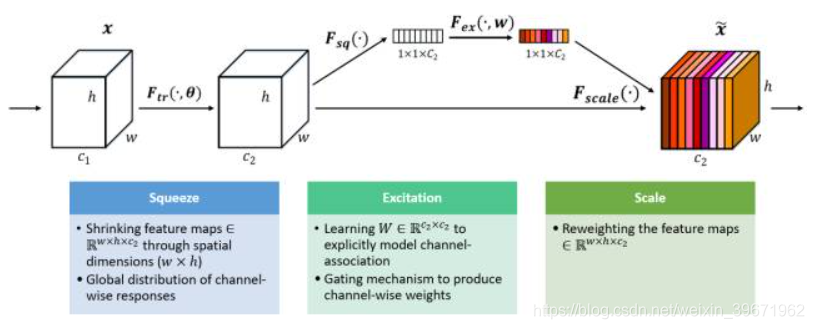
SE Net来源于论文“Squeeze-and-Excitation Networks”
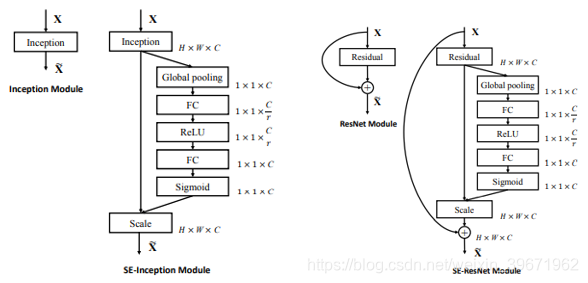
SE Net 是2017 ILSVR竞赛的冠军。SE模块如下图所示:
给定一个输入x,其通道数为c1,通过Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。
Squeeze操作:顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
Excitation操作:它是一个类似于循环神经网络中门的机制。通过参数来为每个特征通道生成权重,其中参数被学习用来显式地建模特征通道间的相关性。
SE Net的关键点:
1、SE Net从建模特征通道之间的关系去提升网络性能,而不是从空间维度层面(如:Inception嵌入多尺度信息,Inside-Outside网络中考虑了空间中的上下文信息等)来提升性能,通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
2、SE Net结构简单,不需要引入新的函数或者层,即可直接部署在现有的网络结构中。
上述网络不断增加层数以获得更好的性能:LeNet-5(5层)->AlexNet(8层)->VGG(16)->GoogLeNet(22)->ResNet(152)-> DenseNet(264)。随着层数的增加,网络性能也得到了提高,但是由于存储空间和功耗、速度等的限制,神经网络模型在设备上的计算和存储还是一个巨大的挑战。接下来,就需要我们的轻量化模型登场了。
目前,设计轻量型神经网络模型主要有4个方向:
1、手工设计轻量化神经卷积网络;
2、基于神经网络架构搜索(Neural Architecture Search,NAS)的自动化设计神经网络;
3、CNN模型压缩;
4、基于AutoML的自动模型压缩。
手工设计轻量化模型主要思想在于设计更高效的“网络计算方式”(主要针对卷积方式),从而使网络参数减少,并且不损失网络性能。那么,手工设计轻量化网络,需要怎么实现呢?
1、优化网络结构,如ShuffleNet
2、减少网络参数,如SqueezeNet
3、优化卷积操作,如MobileNet
4、剔除全连接层,如SqueezeNet
8、SqueezeNet
SqueezeNet来源于论文“ SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size”
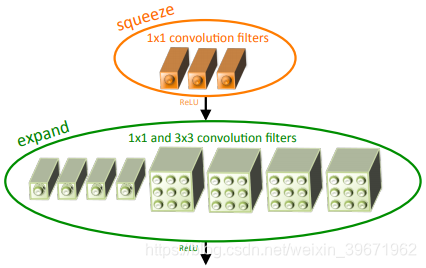
2016年,Forrest N. Iandola等提出了SqueezeNet,仅用 AlexNet 1/50 的参数就取得了与 AlexNet 相当的精度。SqueezeNet提出了Fire module,
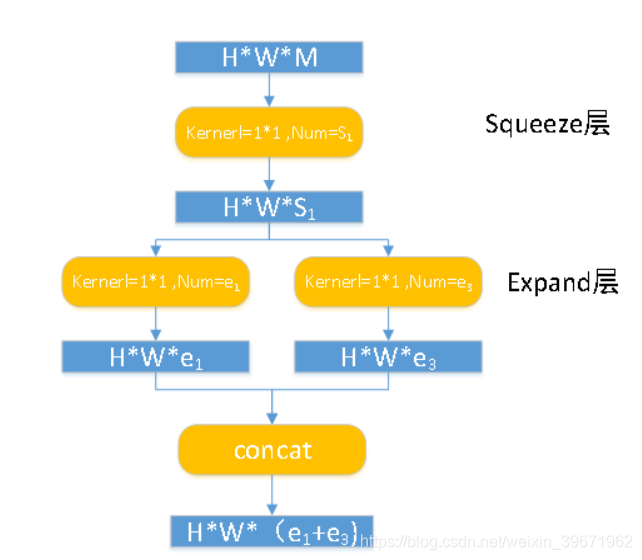
Fire module由squeeze层和expand层组成,如下图所示:
squeeze层:1×1的卷积。通过1×1的卷积可以保持feature map维数的同时减少channel。(有没有似曾相识。GoogLeNet!!)
expand层:1×1的卷积+3×3的卷积。
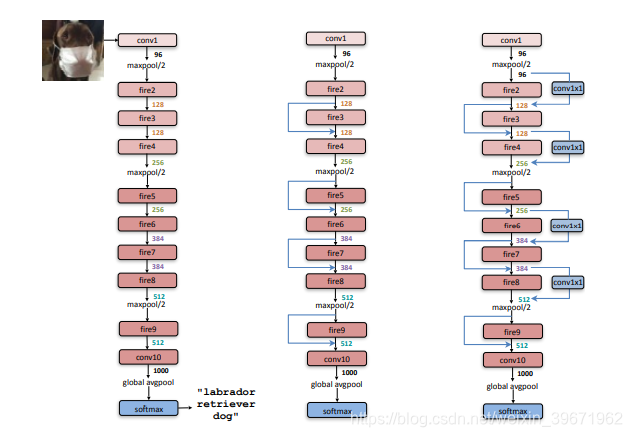
SqueezeNet 的网络结构如下图,可以看出,SqueezeNet 网络由Fire module堆叠组成的,还去除了全连接层。
SqueezeNet的关键点:
1、提出了Fire module,网络由Fire module堆叠组成的;
2、使用 1×1 卷积减少参数
3、去除了全连接层
9、MobileNet
MobileNet 来源于论文“MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications”
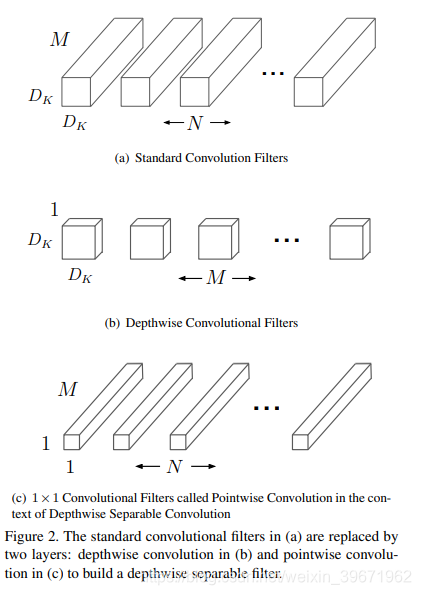
2017年,google团队提出了移动端和嵌入式视觉应用的MobileNets模型。MobileNets基于深度可分离卷积(depthwise separable convolutions)来构造网络的,如下图所示:
标准卷积(a)可分解为:深度卷积depthwise convolution(b)和逐点卷积pointwise convolution(c)。
深度卷积depthwise convolution(b):使用 一个Dk×Dk的滤波器对每个输入通道进行卷积,特征数量保持不变;
逐点卷积pointwise convolution(c):使用一个 1×1 卷积,将M个输入特征变为 N个输出特征
标准卷积层:输入特征图F:F×F× M;输出特征图G: G×G× N;卷积层可以参数化为 K×K× N× N 卷积核,输出的特征图计算如下:
深度卷积(depthwise convolution)计算量为:
深度可分离卷积(Depthwise separable convolutions)的计算量为:
深度可分离卷积(Depthwise separable convolutions)比深度卷积(depthwise convolution)可减少的计算量为:
MobileNets使用3*3的深度可分离卷积,比使用标准卷积减少了8-9倍的计算量
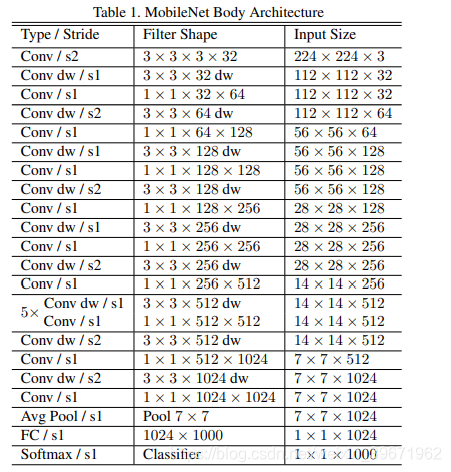
MobileNets共28层,卷积层采用Conv+BN+ReLU,网络结构中采用s=2的Conv进行下采样,具体的网络结构如下:
MobileNet 关键点:
1、采用了深度可分离卷积(Depthwise separable convolutions),分为深度卷积depthwise convolution和逐点卷积pointwise convolution,减少计算量,提升速度。
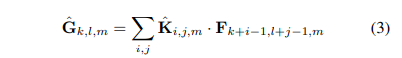
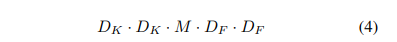
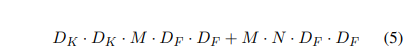
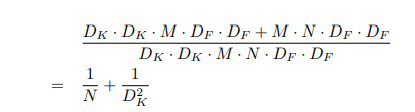

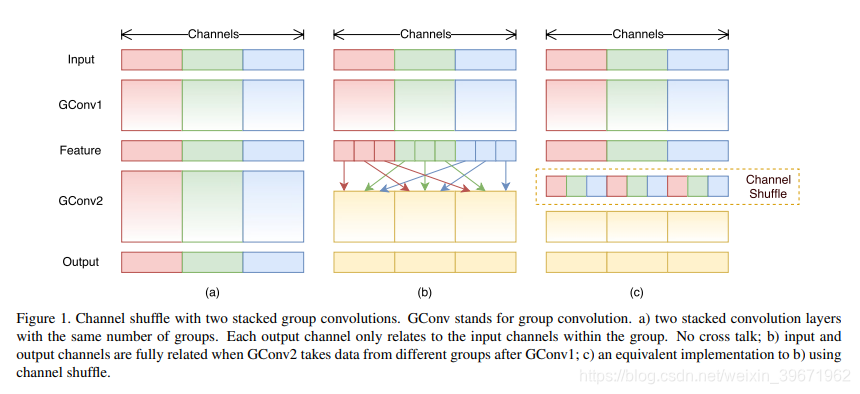
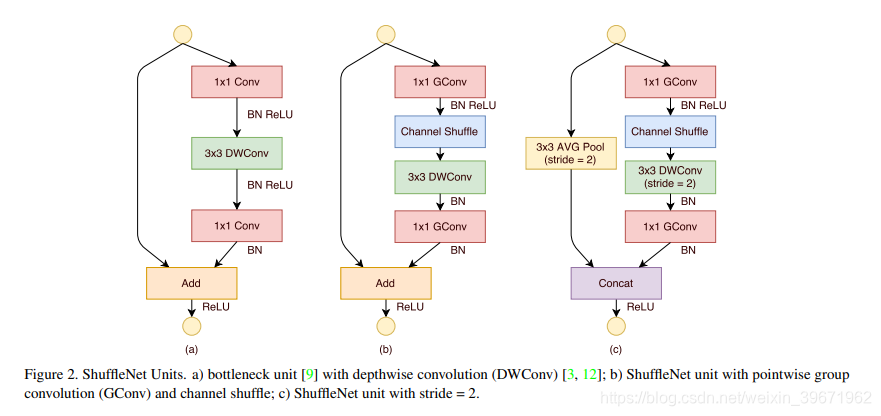
10、ShuffleNet
ShuffleNet 源自论文“ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices”
2017年,Face++提出ShuffleNet 。
未完待续。。。。
参考:
1、深度学习中的经典基础网络结构(backbone)总结
2、大话CNN经典模型:GoogLeNet(从Inception v1到v4的演进)
3、计算机视觉四大基本任务(分类、定位、检测、分割)
4、SE-Net论文讲解
5、纵览轻量化卷积神经网络:SqueezeNet、MobileNet、ShuffleNet、Xception