迈向快速、准确且稳定的 3D 密集人脸对齐
亮点:主要是提出了一系列的优化方案来加速2D图片到3D模型的转换。提出了一个数据增强手段,来帮助模型在视频序列中也很稳定的生成3Dmesh
1:采用轻量级的网络模型回归出3DMM的参数,然后为该网络设置了meta-joint optimization优化策略,动态的组合wpdc和vdc损失函数,从而加速了拟合的速度,也使得拟合的效果更加精确 ;
2:提出landmark-regression regularization(特征点回归正则化)来加速拟合的速度和精确度;
3:为了解决在video上的三维人脸对齐任务(相邻帧之间的三维重建更加稳定,快速,连续性),在基于video数据上训练的模型,但video视频数据库缺乏时,提出了3D aided short-video-synthesis(三维辅助短视频合成技术),将一个静止的图片在平面内还有平面外旋转变成一个短视频;
2: obj文件: 将人脸保存为obj文件 即保存了这个特征点的形状属性,又保存了这个点的纹理属性(r1, g1, b1) ;
ply文件:将人脸保存为ply文件, 只保存了这个特征点的形状属性(x1, y1, z1),不保存纹理属性;
摘要
现有的3D密集人脸对齐方法主要集中在准确性上,从而限制了其实际应用范围。在本文中,我们提出了一种名为3DDFA-V2的新型回归框架,该框架在速度、准确性和稳定性之间取得了平衡。首先,在轻量级主干网络的基础上,我们提出了一种元联合优化策略,以动态回归一小组3D形态模型(3DMM)参数,这极大地同时提升了速度和准确性。为了进一步提高视频上的稳定性,我们提出了一种虚拟合成方法,该方法可以将一张静态图像转换为包含平面内和平面外面部运动的短视频。在保持高精度和稳定性的前提下,3DDFA-V2在单个CPU核心上的运行速度超过50帧/秒,并且同时优于其他最先进的重型模型。在几个具有挑战性的数据集上进行的实验验证了我们的方法的有效性。预训练模型和代码可在https://github.com/cleardusk/3DDFA_V2。
1 引言
3D密集人脸对齐对于许多与人脸相关的任务至关重要,例如识别[45,7,26,24,13,51]、动画[10]、化身重定向[9]、跟踪[50]、属性分类[4,22,21]、图像修复[52,12,11]、防伪[49,55,40,54,25]。
近期的研究主要分为两类:3D形态模型(3DMM)参数回归[29,59,34,36,48,60,23]和密集顶点回归[28,18]。密集顶点回归方法通过全卷积网络直接回归所有3D点(通常超过20,000个)的坐标[28,18],取得了最先进的性能。然而,重建人脸的分辨率取决于特征图的大小,且这些方法依赖于如沙漏网络[38]或其变体等重型网络,这些网络在推理时速度较慢且内存消耗大。加快其速度的自然方法是修剪通道。我们尝试在最先进的PRNet[18]上修剪77.5%的通道,以实现CPU上的实时速度,但发现误差大幅增加了44.8%(从3.62%增加到5.24%)。此外,一个明显的缺点是反卷积算子导致的棋盘格伪影,这在补充材料中有所呈现。另一种策略是回归一小组3DMM参数(通常少于200个)。与密集顶点相比,3DMM参数具有低维度和低冗余性,适合通过轻量级网络进行回归。然而,不同的3DMM参数对重建的3D人脸[59]的影响不同,这使得回归具有挑战性,因为我们必须根据训练期间每个参数的重要性动态地重新加权。级联结构[59,36,60]总是被用来逐步更新参数,但计算成本随着级联阶段的数量线性增加。
在本文中,我们的目标是同时加速到CPU实时速度并实现最先进的性能。为此,我们选择使用快速主干网络(如MobileNet)来回归3D形态模型(3DMM)参数。为了解决参数回归框架的优化问题,我们采用了两种不同的损失项:WPDC和VDC[59](见第2.2节),并提出了我们的元联合优化方法来结合它们的优点。元联合优化在元训练批次上使用WPDC和VDC进行k步前瞻,然后根据元测试批次上的误差动态选择更好的一个。这样做可以使整个优化过程更快收敛,并比传统的联合优化方法获得更好的性能。此外,我们还引入了地标回归正则化来进一步缓解优化问题,以实现更高的准确性。除了单张图像外,3D人脸在视频中的应用也越来越广泛[10,9,31,30],其中在连续帧之间重建稳定的结果非常重要,但这一点往往被最近的方法所忽视[59,28,18,60]。为了提高二维人脸对齐的稳定性,通常采用基于视频的训练[39,35,17,44]。然而,对于3D密集人脸对齐,目前没有公开的视频数据库。为了解决这一问题,我们提出了一种3D辅助短视频合成方法,该方法模拟平面内和平面外的面部运动,将一张静态图像转换为短视频,从而使我们的网络能够调整连续帧的结果。实验表明,我们的短视频合成方法显著提高了视频中的稳定性。
总的来说,我们提出的框架3DDFA-V2具有以下特点:(i)速度快:以单张图像为输入时,它仅需约7.2毫秒(比PRNet快近24倍),在单个CPU核心上运行时可达到50帧以上每秒(19.2毫秒),在多个CPU核心(i5-8259U处理器)上运行时则可达到130帧以上每秒(7.2毫秒);(ii)精度高:通过结合快速WPDC和VDC的新型元优化策略动态优化3DMM参数,我们在严格的推理计算负担下超越了最先进的结果[59,28,18,60];以及(iii)稳定性好:在一个小批量中,一张静态图像被轻微且平滑地转换为一个包含平面内和平面外旋转的短合成视频,这为训练提供了相邻帧的时间信息。在四个数据集上的大量实验结果表明,我们的方法在整体性能上表现最佳。
2 方法论
本节详细介绍了我们提出的方法。首先,我们讨论了3D可变形模型(3DMM)[6]。然后,我们介绍了所提出的元联合优化、地标回归正则化和3D辅助短视频合成方法。整体流程如图2所示,算法在算法1中进行了描述。

图2:3DDFA-V2概述。我们的架构由四部分组成:用于预测3D可变形模型(3DMM)参数的轻量级主干网络(如MobileNet)、fWPDC和VDC的元联合优化、地标回归正则化以及用于训练的短视频合成。在推理过程中,会丢弃地标回归分支,因此不会增加任何计算负担。
2.1 Preliminary of 3DMM
2.2 Meta-joint Optimization
我们首先回顾了[59]中的顶点距离成本(VDC)和加权参数距离成本(WPDC),然后推导出元关节优化,以促进参数回归。
如果经过fWPDC训练的模型通过VDC进行微调,我们可以得到一个比fWPDC小得多的误差。
VDC从头训练难以收敛,后期fWPDC没有对网络进行充分训练。
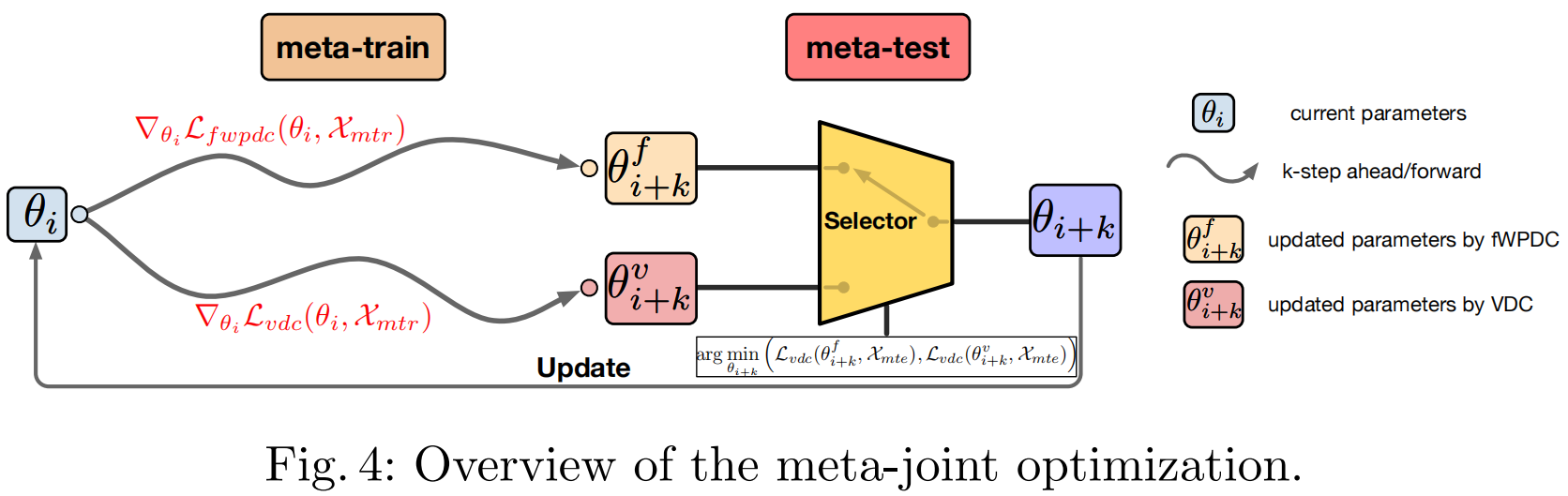
元联合优化。基于上述讨论,对两个项进行加权以执行基本的联合优化是自然而然的:L_vanilla-joint = βL_fwpdc + (1-β) * |L_fwpdc|/|L_vdc| * L_vdc,其中β∈[0,1]控制fWPDC和VDC之间的重要性。然而,基本的联合优化依赖于手动设置的超参数β,并且在图3中并未取得令人满意的结果。受Lookahead[57]和MAML[19]的启发,我们提出了一种元联合优化策略来动态地结合fWPDC和VDC。元联合优化的概述如图4所示。在训练过程中,模型在k个元训练批次Xmtr上以前瞻k步的方式使用fWPDC或VDC的成本,然后根据元测试批次上的顶点误差在fWPDC和VDC中选择更好的一个。具体来说,整个元联合优化包括四个步骤:(i)为元训练采样k批训练样本Xmtr,并为元测试采样一批样本Xmte;(ii)元训练:分别在Xmtr上用fWPDC和VDC通过k步更新当前模型参数θi,得到两个参数状态θi_f+k和θi_v+k;(iii)元测试:在Xmte上评估θi_f+k和θi_v+k的顶点误差;(iv)选择误差较低的参数来更新θi。所提出的元联合优化可以直接嵌入到标准训练方案中。从图3中我们可以观察到,元联合优化比基本联合优化收敛得更快,且误差更低。
2.3 地标回归正则化 Landmark-regression Regularization
在3D人脸重建领域[16,15,47,46,20]中,投影后的2D稀疏地标通常被用作额外的正则化手段,以促进参数回归。在我们的回归框架中,我们发现将2D稀疏地标视为一个辅助回归任务会带来更多益处。如图2所示,我们在全局池化层上添加了一个额外的地标回归任务,并使用L2损失进行训练。
传统的地标正则化与我们的地标回归正则化之间的区别在于,后者引入了额外的参数来回归地标。换句话说,地标回归正则化是一种任务级别的正则化。从图3的番茄曲线中,我们可以看到,通过引入地标回归正则化,我们获得了更低的误差。表3中的比较结果显示,我们提出的地标回归正则化方法在AFLW2000-3D数据集上表现优于传统的地标正则化(3.59% vs. 3.71%)。
地标回归正则化的公式为:
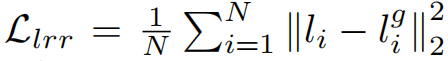
其中,N为136(因为我们使用了68个2D地标,并将其展平为一个136维的向量)
2.4 3D Aided Short-video-synthesis
基于视频的三维人脸应用近年来变得越来越流行[10,9,31,30]。在这些应用中,三维密集人脸对齐方法需要在视频上运行,并在相邻帧之间提供稳定的重建结果。这里的稳定性意味着相邻帧之间重建的三维人脸的变化应该与真实人脸在精细层面上的移动保持一致。然而,大多数现有方法[59,60,28,18]都忽略了这一要求,导致预测结果出现随机抖动。在二维人脸对齐中,像时间滤波这样的后处理是一种减少抖动的常见策略,但它会降低精度并导致帧延迟。此外,由于没有公开的三维密集人脸对齐视频数据库,因此视频训练策略[17,39,44,35]在这里无法应用。于是出现了一个挑战:在训练时只有静态图像可用的情况下,我们能否提高视频上的稳定性?
为了应对这一挑战,我们提出了一种批量级别的三维辅助短视频合成策略,该策略将一个静态图像扩展为几个相邻帧,在一个小批量中形成一个短的合成视频。视频中的常见模式可以建模为:(i)噪声。我们将噪声建模为P(x) = x + N(0, Σ),其中Σ = σ²I。(ii)运动模糊。运动模糊可以表示为M(x) = K * x,其中K是卷积核(运算符*表示卷积)。(iii)平面内旋转。给定两个相邻帧xt和xt+1,从xt到xt+1的平面内时间变化可以描述为一个相似变换T(·):
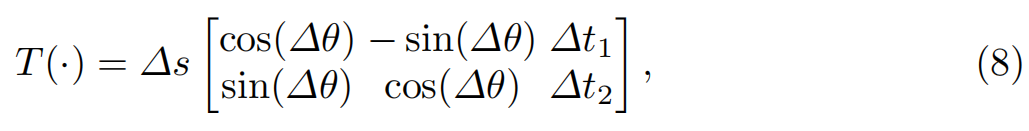
其中∆s是尺度扰动,∆θ是旋转扰动,∆t1和∆t2是平移扰动。(iv)由于人脸具有相似的三维结构,我们还能够合成平面外的脸部运动。原本用于解决大姿态人脸对齐问题的人脸轮廓化[59]F(·)被用来逐步增加人脸的偏航角∆φ和俯仰角∆γ。具体来说,我们在一个小批量中采样几个静态图像,对于每个静态图像x0,我们对其进行轻微且平滑的变换,以生成一个具有n个相邻帧的合成视频:
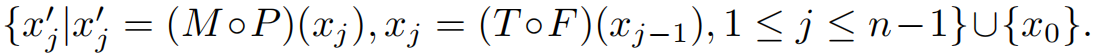
。在图5中,我们展示了如何将这些变换应用于图像以生成几个相邻帧的示例。

3 实验
本节首先介绍数据集和评估协议;然后,我们对准确性和稳定性进行了对比实验;其次,评估了复杂性和运行速度;最后进行了广泛的讨论。我们提出的方法的实现细节、泛化能力和扩展能力见补充材料。
3.1 数据集和评估协议
我们的实验使用了五个数据集:300W-LP[59](300W跨大姿态)由300W[41]中的合成大姿态人脸图像组成,包括AFW[61]、LFPW[3]、HELEN[58]、IBUG[41]和XM2VTS[37]。具体来说,采用了人脸轮廓生成方法[59]来生成122,450个跨大姿态的样本。AFLW[32]包含21,080张野外拍摄的大姿态人脸图像(遵循[60,23]),偏航角从-90°到90°。每张图像都标注了多达21个可见的地标。AFLW2000-3D[59]由[59]构建,用于评估3D人脸对齐性能,包含前2000个AFLW样本的真实3D人脸和对应的68个地标。Florence[2]是一个3D人脸数据集,包含53个受试者,其真实3D网格数据是通过结构光扫描系统获取的。为了评估,我们按照VRN[28]和PRNet[18]的方法为每个受试者生成了不同姿态的渲染图像。Menpo-3D[56]提供了一个基准,用于评估野外任意姿态下的3D面部地标定位算法。具体来说,Menpo-3D为300-VW[43]竞赛中的55个视频提供了3D面部地标。
协议
对于AFLW数据集,我们遵循[59]的协议,并报告了由边界框大小归一化的平均误差(NME)。对于AFLW2000-3D数据集,我们应用了两个协议:第一个协议遵循AFLW的评估方式,另一个协议则遵循[18]来评估由边界框大小归一化的3D人脸重建的NME。对于Florence数据集,我们遵循[28,18]的评估方式,来评估由外眼间距归一化的3D人脸重建的NME。至于Menpo-3D数据集,我们评估了静态帧的NME以及相邻帧之间的稳定性。我们按照[44]的方法计算稳定性,通过测量相邻帧的预测偏移量与真实偏移量之间的NME来实现。具体来说,在帧t-1和t处,真实地标偏移量为Δp = pt - pt-1,预测偏移量为Δq = qt - qt-1,由边界框大小归一化的误差Δp - Δq代表了稳定性。由于300W-LP仅包含68个地标的索引,为了保持一致性,我们使用Menpo-3D中的68个地标进行评估。
4 结论
在本文中,我们提出的3DDFA-V2成功实现了快速、准确且稳定的3D密集人脸对齐。为实现这一目标,我们主要做出了以下三项努力:(i)提出了名为fWPDC的快速WPDC以及结合fWPDC和VDC的元联合优化方法,以缓解优化问题;(ii)增加了额外的地标回归正则化,以提升性能至最优水平;(iii)提出了3D辅助短视频合成方法,以提高视频中的稳定性。实验结果表明,我们提出的方法是有效且高效的。我们的有前景的结果为实际应用中的实时3D密集人脸对齐铺平了道路,且所提方法可通过减少GPU消耗的大量能源所释放的二氧化碳量来改善环境。