一:概念
Spark应用程序的配置,用于将各种Spark参数设置为键值对。
大多数情况下,将使用新的SparkConf(),创建一个SparkConf对象,该对象将从您的应用程序中设置的任何spark.的Java系统属性加载值。 在这种情况下,* 直接在SparkConf对象上设置的参数优先于系统属性 **。
二:使用
无论官方还是自定义,spark配置一定是以“spark.*”开头
scala> :quit
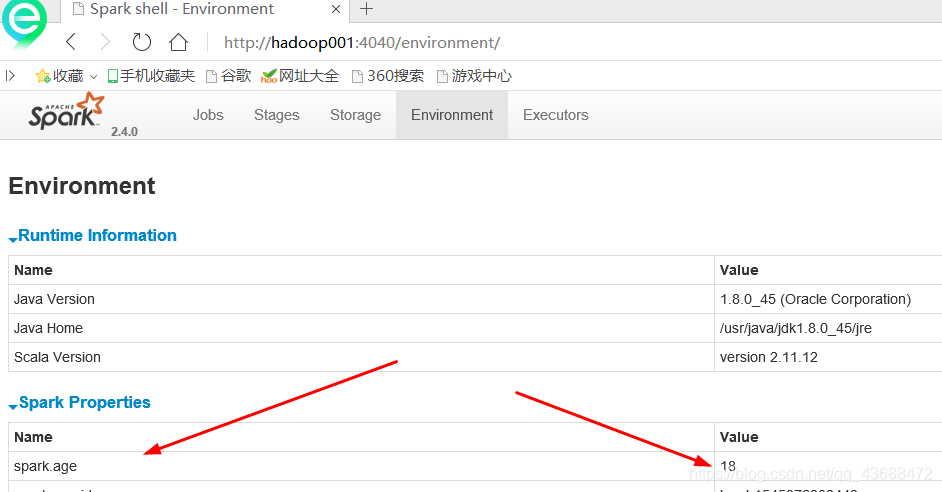
[hadoop@hadoop001 bin]$ ./spark-shell --master local[2] --conf name=suoze --conf spark.age=18
Warning: Ignoring non-spark config property: name=suoze
其中–conf可以写很多,这里就有个警告提示name,去控制台看一下
在哪里去寻找呢。在源码当中:SparkSubmitArguments.scala 可以看到最完整的
三:spark配置文件
[hadoop@hadoop001 conf]$ vi spark-defaults.conf
spark.master local[2][hadoop@hadoop001 conf]$ vi spark-defaults.conf
[hadoop@hadoop001 conf]$ cd ../
[hadoop@hadoop001 spark-2.4.0-bin-2.6.0-cdh5.7.0]$ cd bin
[hadoop@hadoop001 bin]$ ./spark-shell
在配置文件中配置,就可以直接进入了
spark读写数据库,不能写死,就写在配置里面
scala> sc.getconf.get("spark.age")
在配置配置之后,使用这个命令可以取到
这里还可以扩展在优先级参考博客:https://blog.csdn.net/qq_43688472/article/details/85272630