GoogLeNet
论文链接:https://arxiv.org/abs/1409.4842
介绍
GoogLeNet 在 2014 年由 Google 团队提出,斩获当年 lmageNet 竞赛中 Classification Task (分类任务)第一名。L 大写是为了致敬 LeNet 。
网络中的亮点:
- 引入了 Inception 结构(融合不同尺度的特征信息)
- 使用 1 × 1 1\times1 1×1 的卷积核进行降维以及映射处理
- 添加两个辅助分类器帮助训练
- 丢弃全连接层,使用平均池化层(大大减少模型参数)
在 AlexNet 和 VGG 中都只有一个输出层,GoogLeNet 有三个输出层(其中两个辅助分类层)。
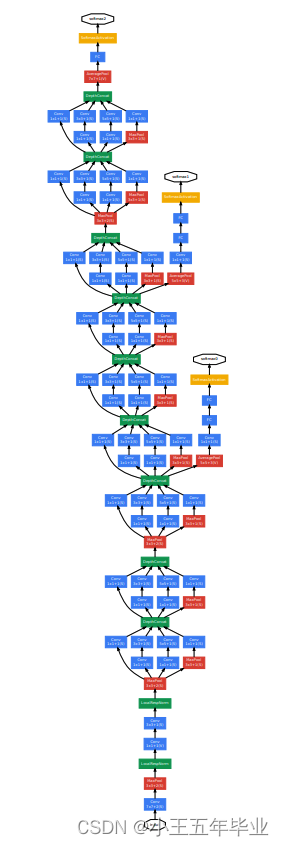
如图 1 所示,**最上方的黄色为主分类器,下方的两个为辅助分类器。**图中的 LRN 操作在此支撑之前被证实过无效,故代码可以不使用。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UdfRLLSU-1657719876636)(.\图片\GoogLeNet\GooLeNet网络参数.png)]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2Q1Y2M4N2Q0N2M3YTQyOGQ5YTdjY2NmMjM2NTEzZmU2LnBuZw%3D%3D)
第 1 1 1 列:名称;第 2 2 2 列:参数(卷积核大小和布局);第 3 3 3 列:输出的特征矩阵的维度;第 5 → 9 5\to9 5→9 列:Inception结构配置的个数(如图 3 3 3);
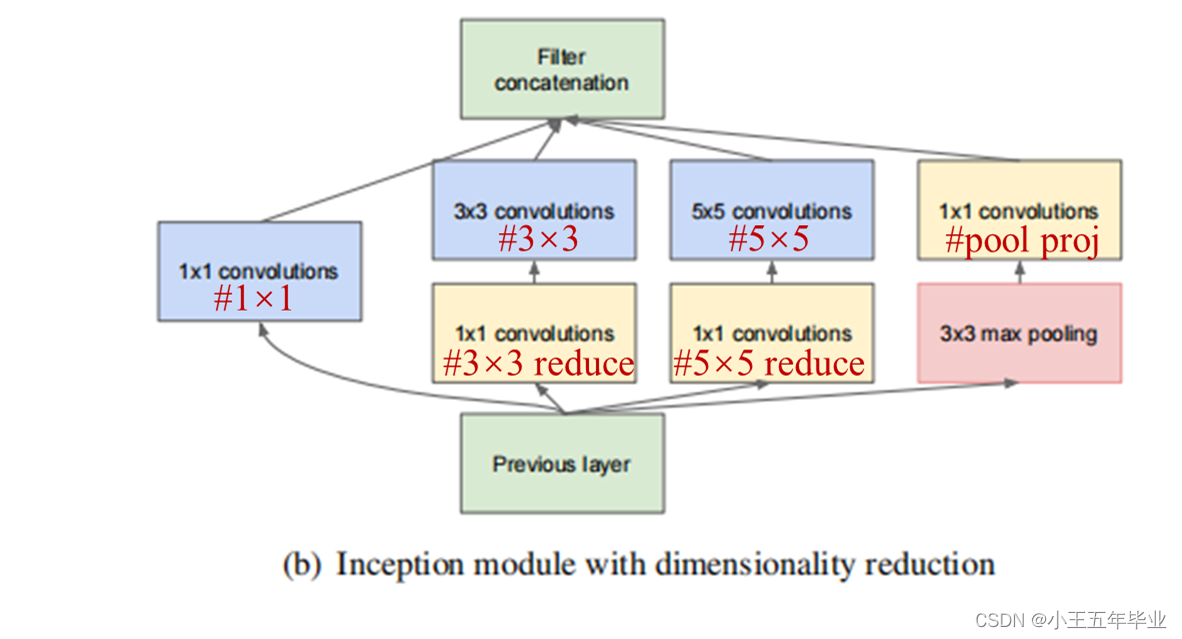
Inception结构
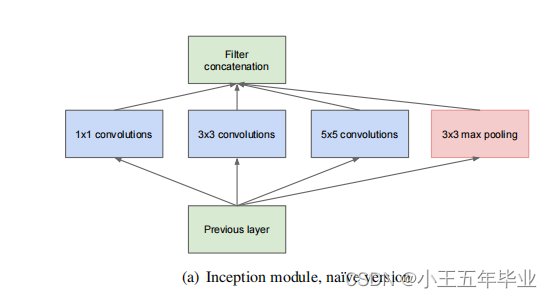
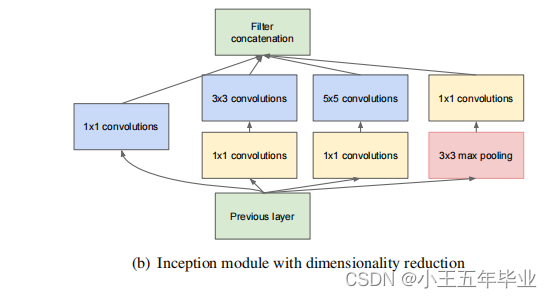
(a)通过为
1
×
1
1\times1
1×1 的卷积层,
3
×
3
3\times3
3×3 的卷积层,
5
×
5
5\times5
5×5 的卷积层和
3
×
3
3\times3
3×3 的最大池化层并行的结构。
(b)在(a)的基础上加入了
3
3
3 个
1
×
1
1\times1
1×1 的卷积层(该卷积层的作用为降维)。
注:每个分支所得的特征矩阵的高和宽必须相同。
示例:
输入通道数为512,只使用 64 个 5 × 5 5\times5 5×5 的卷积核进行卷积:参数数量为: 5 × 5 × 512 × 64 = 819200 5\times5\times512\times64=819200 5×5×512×64=819200
输入通道数为512,先使用 24 个
1
×
1
1\times1
1×1 的卷积核进行卷积,再使用 64 个
5
×
5
5\times5
5×5 的卷积核进行卷积:参数数量为:
第一步:
1
×
1
×
512
×
24
=
12288
1\times1\times512\times24=12288
1×1×512×24=12288
第二步:
5
×
5
×
24
×
64
=
38400
5\times5\times24\times64=38400
5×5×24×64=38400
总计:
12288
+
38400
=
50688
<
819200
12288+38400=50688<819200
12288+38400=50688<819200
从示例可以知道,通过使用 1 × 1 1\times1 1×1 的卷积核有效的减少了模型的参数。
辅助分类器(Auxiliary Classifier)
The exact structure of the extra network on the side, including the auxiliary classifier, is as follows:
- An average pooling layer with 5 × 5 5\times5 5×5 filter size and stride 3 3 3, resulting in an 4 × 4 × 512 4\times4\times512 4×4×512 output for the ( 4 a 4a 4a), and 4 × 4 × 528 4\times4\times528 4×4×528 for the ( 4 d 4d 4d) stage.
- A 1 × 1 1\times1 1×1 convolution with 128 128 128 filters for dimension reduction and rectified linear activation.
- A fully connected layer with 1024 1024 1024 units and rectified linear activation.
- A dropout layer with 70 70% 70 ratio of dropped outputs.
- A linear layer with softmax loss as the classifier (predicting the same 1000 1000 1000 classes as themain classifier, but removed at inference time).
以上是原论文中对辅助分类器的描述。
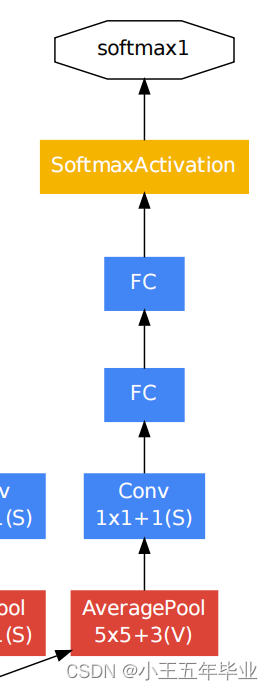
根据原论文和论文中辅助分类的描述( 如图 5 5 5 ),我们可以得到:
- 首先,使用了一个平均池化层(Average Pooling Layer):池化核(filter size)大小为
5
×
5
5\times5
5×5 ,步距(stride)为
3
3
3 。
对于Inception 4a 的特征矩阵的维度是 14 × 14 × 512 14\times14\times512 14×14×512 ,Inception 4d 的特征矩阵的维度是 14 × 14 × 528 14\times14\times528 14×14×528 。通过上方的平均池化层输入为 4 × 4 × 512 4\times4\times512 4×4×512 ( 4 a 4a 4a) 、 4 × 4 × 528 4\times4\times528 4×4×528 ( 4 d 4d 4d) 。 - 接着,使用了 128 128 128 个 1 × 1 1\times1 1×1 卷积核的卷积层,目的是降维,并且使用了 ReLU 激活函数。
- 其次,使用了一个 1024 1024 1024 个单位的全连接层,并且使用了 ReLU 激活函数。
- 再次,释放 70 % 70 \% 70% 的神经元,再输出。
- 最后,一个线性层并且使用了 softmax 函数( ImageNet 中是 1000 1000 1000 个类别)。
对比
最后我们对比 VGG 和 GoogLeNet ,我们发现 GoogLeNet 的模型参数更少,但搭建较为复杂,所以很多论文仍使用 VGG 。