本文尝试用Wireshark+tcpdump查看TCP连接、断开全过程。
一、ping命令
主要作用:(1)用来检测网络的连通情况和分析网络速度;(2)根据域名得到服务器IP;(3)根据ping返回的TTL值来判断对方所使用的操作系统及数据包经过路由器数量。
在Linux下开启一个终端,尝试ping百度,结果如下图:

可以看到连接正常。
二、tcpdump命令
这是个可以根据使用者的定义对网络上的数据包进行截获的包分析工具。 tcpdump可以将网络中传送的数据包的“头”完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句去掉无用的信息。普通情况下,直接启动tcpdump将监视第一个网络接口上所有流过的数据包。
在终端下进入root用户身份,输入下面这条命令:
tcpdump -i any tcp and host 180.101.49.11 -w http.pcap如下图:

选项-i指定网口,any表示所有接口;tcp表示抓取tcp数据包;host表示抓取对应IP地址的数据包;最后的-w表示将捕获到的数据保存下来,保存的文件名为http.pcap,供Wireshark分析。
三、curl命令
在命令行中利用URL进行数据或者文件传输,需要先安装。新开一个终端,使用它来获取前面ping的百度IP地址的网址文本信息:
curl http://180.101.49.11此时回到原来那个终端,按下ctrl+C终止tcpdump命令:

这时候把目录下生成的pcap文件拉到windows端用Wireshark打开。
四、Wireshark
打开后可以看到界面如下
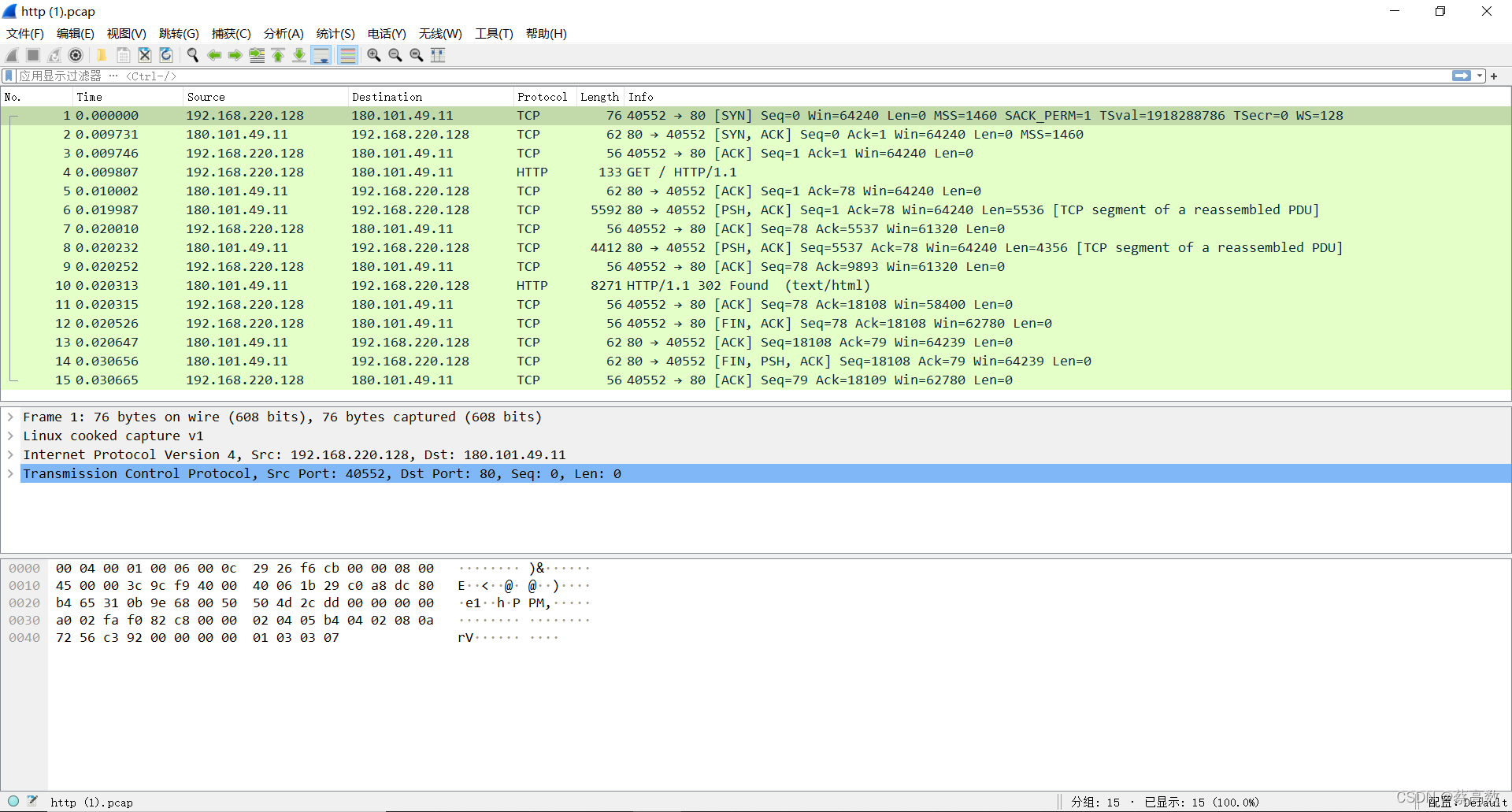
开头的三个包是TCP三次握手建立连接的包,中间是 HTTP 请求和响应的包,最后四个则是四次挥手断开连接的包。
Wireshark 可以用时序图的方式显示数据包交互的过程,从菜单栏中,点击 统计 (Statistics) -> 流量图 (Flow Graph),然后在弹出的界面中的「流量类型」选择 「TCP Flows」,可以更清晰的看到整个过程中 TCP 流 的执行过程:

五、其他Linux命令
1.ifconfig
用于显示或设置网络设备。
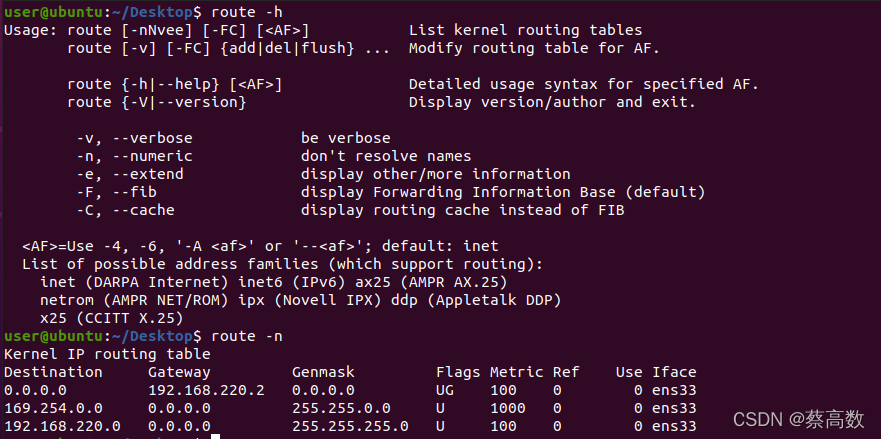
2.route
用于显示和操作IP路由表
选项:
-c 显示更多信息
-n 不解析名字(直接使用IP地址)
-v 显示详细的处理信息
-F 显示发送信息
-C 显示路由缓存
-f 清除所有网关入口的路由表。
3.netstat
用于显示网络状态,了解整个 Linux 系统的网络情况。
选项:
- -i或--interfaces 显示网络界面信息表单。
- -l或--listening 显示监控中的服务器的Socket。
- -M或--masquerade 显示伪装的网络连线。
- -n或--numeric 直接使用IP地址,而不通过域名服务器。
- -N或--netlink或--symbolic 显示网络硬件外围设备的符号连接名称。
- -o或--timers 显示计时器。
- -p或--programs 显示正在使用Socket的程序识别码和程序名称。
- -r或--route 显示Routing Table。

4.cat
输出文件内容到 '>' 后面的文件。选项:
-n 或 --number:由 1 开始对所有输出的行数编号。
-b 或 --number-nonblank:和 -n 相似,只不过对于空白行不编号。
-s 或 --squeeze-blank:当遇到有连续两行以上的空白行,就代换为一行的空白行。
-v 或 --show-nonprinting:使用 ^ 和 M- 符号,除了 LFD 和 TAB 之外。
-E 或 --show-ends : 在每行结束处显示 $。
-T 或 --show-tabs: 将 TAB 字符显示为 ^I。
5.top
用来监控linux的系统状况,是常用的性能分析工具,能够实时显示系统中各个进程的资源占用情况。
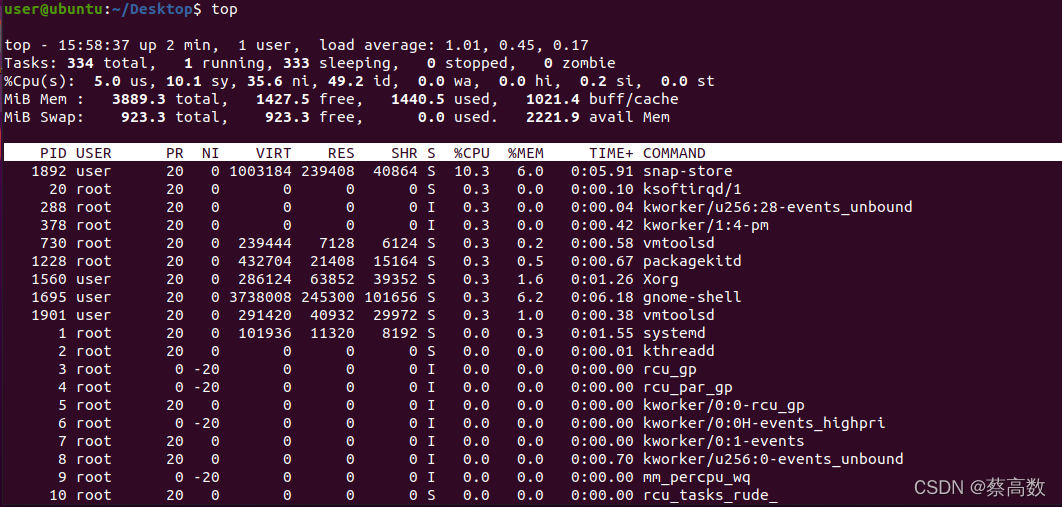
第1行是任务队列信息,其参数如下:
内容 含义
15:58:37 当前时间
up 2min 系统运行时间 格式为时:分
2 users 当前登录用户数
load average: 1.01, 0.45, 0.17 系统负载,即任务队列的平均长度。 三个数值分别为1分钟、5分钟、15分钟前到现在的平均值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第2、3行为进程和CPU的信息.当有多个CPU时,这些内容可能会超过两行,其参数如下:
内容 含义
334total 进程总数
1 running 正在运行的进程数
333 sleeping 睡眠的进程数
0 stopped 停止的进程数
0 zombie 僵尸进程数
5.0 us 用户空间占用CPU百分比
10.1 sy 内核空间占用CPU百分比
35.6 ni 用户进程空间内改变过优先级的进程占用CPU百分比
49.2 id 空闲CPU百分比
0.0 wa 等待输入输出的CPU时间百分比
0.0 hi 硬中断(Hardware IRQ)占用CPU的百分比
0.2 si 软中断(Software Interrupts)占用CPU的百分比
0.0 st
第4、5行为内存信息,其参数如下:
内容 含义
MiB Mem: 3889.3 total 物理内存总量
1427.5 free 空闲内存总量
1440.5 used 使用的物理内存总量
1021.4 buffers(buff/cache) 用作内核缓存的内存量
MiB Swap: 923.3 total 交换区总量
923.3 free 空闲交换区总量
0 used 使用的交换区总量
2221.9 avail Mem 代表可用于进程下一次分配的物理内存数量
计算可用内存数有一个近似的公式:
第四行的free + 第四行的buffers + 第五行的cached
进程信息:
PID 进程id
USER 进程所有者的用户名
PR 优先级
NI nice值。负值表示高优先级,正值表示低优先级
%CPU 上次更新到现在的CPU时间占用百分比
TIME 进程使用的CPU时间总计,单位秒
TIME+ 进程使用的CPU时间总计,单位1/100秒
%MEM 进程使用的物理内存百分比
VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
SWAP 进程使用的虚拟内存中,被换出的大小,单位kb
RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
CODE 可执行代码占用的物理内存大小,单位kb
DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
SHR 共享内存大小,单位kb
nFLT 页面错误次数
nDRT 最后一次写入到现在,被修改过的页面数。
S 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
COMMAND 命令名/命令行
其他使用选项: top [-d number] | top [-bnp]
-d:number代表秒数,表示top命令显示的页面更新一次的间隔。默认是5秒。 -b:以批次的方式执行top。 -n:与-b配合使用,表示需要进行几次top命令的输出结果。 -p:指定特定的pid进程号进行观察。
在top命令显示的页面还可以输入以下按键执行相应的功能(区分大小写):
?:显示在top当中可以输入的命令 P:以CPU的使用资源排序显示 M:以内存的使用资源排序显示 N:以pid排序显示 T:由进程使用的时间累计排序显示 k:给某一个pid一个信号。可以用来杀死进程 r:给某个pid重新定制一个nice值(即优先级) q:退出top(用ctrl+c也可以退出top)。
6.sar
用法
Usage: sar [ options ] [ <interval> [ <count> ] ]选项:
-A:所有报告的总和
-b:显示I/O和传递速率的统计信息
-B:显示换页状态
-d:输出每一块磁盘的使用信息
-e:设置显示报告的结束时间
-f:从制定的文件读取报告
-i:设置状态信息刷新的间隔时间
-P:报告每个CPU的状态
-R:显示内存状态
–u:输出cpu使用情况和统计信息
–v:显示索引节点、文件和其他内核表的状态
-w:显示交换分区的状态
-r:报告内存利用率的统计信息查看CPU运行情况:
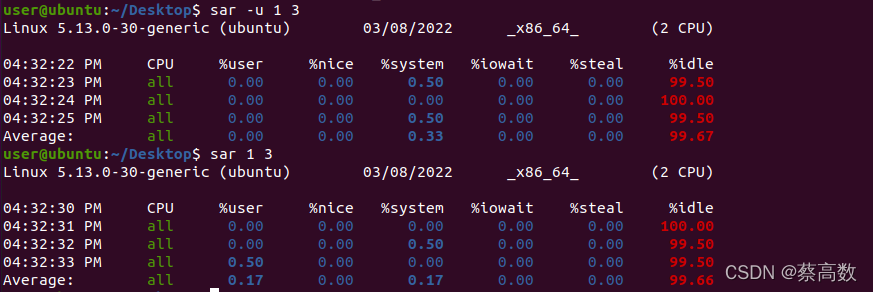
%user 用户空间的CPU使用率
%nice 改变过优先级的进程的CPU使用率
%system 内核空间的CPU使用率
%iowait CPU等待IO的百分比
%steal 虚拟机的虚拟机CPU使用的CPU
%idle 空闲的CPU%iowait过高表示存在I/O瓶颈,即磁盘IO无法满足业务需求,如果%idle过低表示CPU使用率比较严重,需要结合内存使用等情况判断CPU是否瓶颈。
7.ps
ps 命令是 Process Status 的缩写,用来列出系统中当前正在运行的那些进程。

ps 命令常用用法(方便查看系统进程)
1)ps a 显示现行终端机下的所有程序,包括其他用户的程序。
2)ps -A 显示所有进程。
3)ps c 列出程序时,显示每个程序真正的指令名称,而不包含路径,参数或常驻服务的标示。
4)ps -e 此参数的效果和指定"A"参数相同。
5)ps e 列出程序时,显示每个程序所使用的环境变量。
6)ps f 用 ASCII 字符显示树状结构,表达程序间的相互关系。
7)ps -H 显示树状结构,表示程序间的相互关系。
8)ps -N 显示所有的程序,除了执行ps指令终端机下的程序之外。
9)ps s 采用程序信号的格式显示程序状况。
10)ps S 列出程序时,包括已中断的子程序资料。
11)ps -t<终端机编号> 指定终端机编号,并列出属于该终端机的程序的状况。
12)ps -u root 显示root用户信息
13)ps x 显示所有程序,不以终端机来区分。8.grep
grep命令是查找,是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。全称是Global Regular Expression Print,表示全局正则表达式版本。有时和ps一起使用。
用法:
Usage: grep [OPTION]... PATTERNS [FILE]...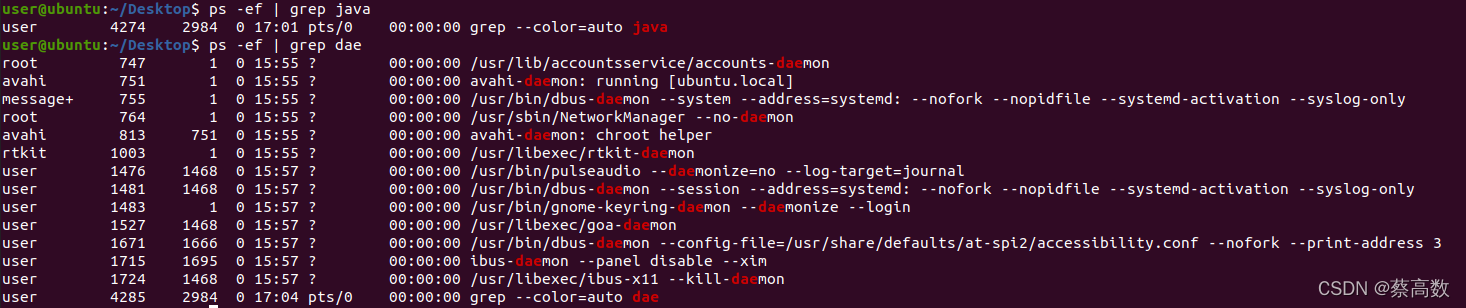
常用选项:
--help
-V, --version
-G, --basic-regexp BRE 模式,也是默认的模式
-E, --extended-regexp ERE 模式
-P, --perl-regexp PRE 模式
-F, --fixed-strings 指定的模式被解释为字符串
-i 忽略大小写
-o 只输出匹配到的部分(而不是整个行)
-v 反向选择,即输出没有没有匹配的行
-c 计算找到的符号行的次数
-n 顺便输出行号9.sed
sed 可依照脚本的指令来处理、编辑文本文件。主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。用法:
Usage: sed [OPTION]... {script-only-if-no-other-script} [input-file]...参数:
- -e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。
- -f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
- -h或--help 显示帮助。
- -n或--quiet或--silent 仅显示script处理后的结果。
- -V或--version 显示版本信息。
10.tail
用于查看文件的内容,命令格式:
tail [参数] [文件]参数:
- -f 循环读取
- -q 不显示处理信息
- -v 显示详细的处理信息
- -c<数目> 显示的字节数
- -n<行数> 显示文件的尾部 n 行内容
- --pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
- -q, --quiet, --silent 从不输出给出文件名的首部
- -s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
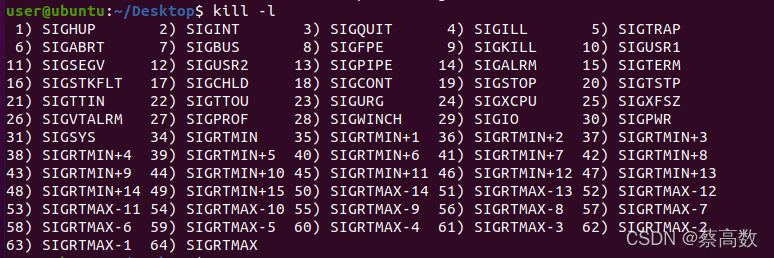
11.kill
向进程发送信号,用法:
kill: kill [-s sigspec | -n signum | -sigspec] pid | jobspec ... or kill -l [sigspec]-l用于列出可用信号
12.awk
awk 是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入、一个或多个文件,或其它命令的输出(即管道)。它支持用户自定义函数和 动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。
awk的处理文本和数据的方式是这 样的,它逐行扫描文件,从第一行到最后一行,寻找匹配的特定模式的行,并在这些行上进行你想要的操作。如果没有指定处理动作,则把匹配的行显示到标准输出 (屏幕),即默认处理动作是print;如果没有指定模式,则所有被操作所指定的行都被处理,即默认指定模式是全部。awk分别代表其作者姓氏的第一个字母。因为它的作者是三个人,分别是Alfred Aho、Brian Kernighan、Peter Weinberger。gawk是awk的GNU版本,它提供了Bell实验室和GNU的一些扩展。
像shell一样,awk也有好几种,常见的如awk、nawk、mawk、gawk。用法:
Usage: mawk [Options] [Program] [file ...]选项参数:
- -F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。- -v var=value or --asign var=value
赋值一个用户定义变量。- -f scripfile or --file scriptfile
从脚本文件中读取awk命令。
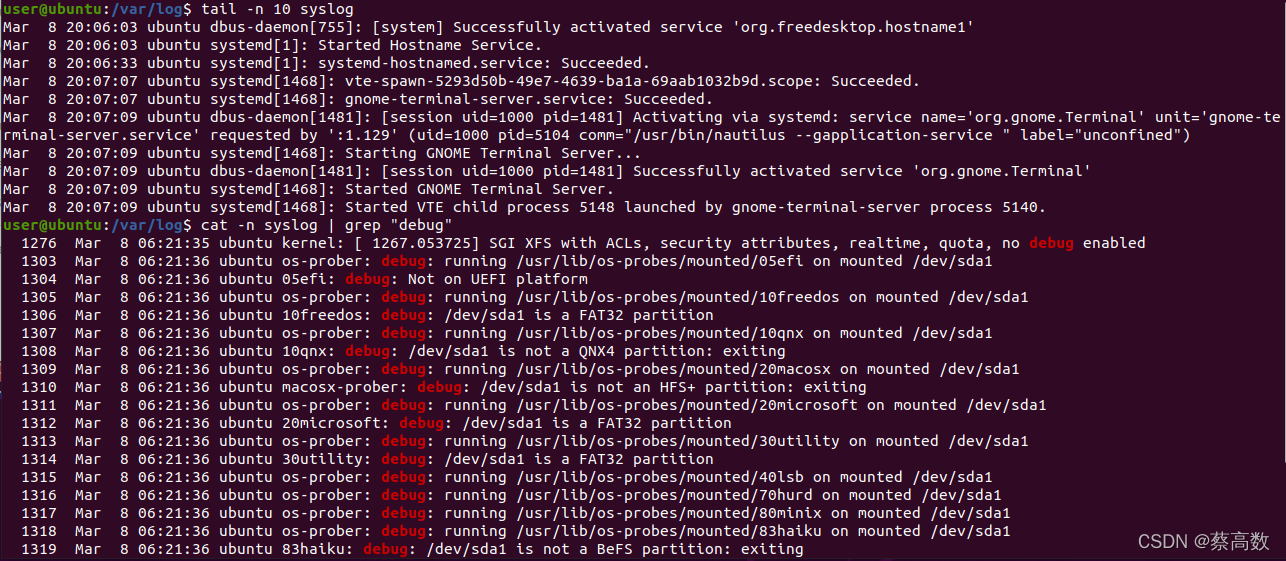
13.查看日志常用命令
tail:
-n 是显示行号;相当于nl命令;例子如下:
tail -100f syslog.log 实时监控100行日志
tail -n 10 syslog.log 查询日志尾部最后10行的日志;
tail -n +10 syslog.log 查询10行之后的所有日志;
head:
跟tail是相反的,tail是看后多少行日志;例子如下:
head -n 10 syslog.log 查询日志文件中的头10行日志;
head -n -10 syslog.log 查询日志文件除了最后10行的其他所有日志;
cat:
tac是倒序查看,是cat单词反写;例子如下:
cat -n syslog.log |grep "debug" 查询关键字的日志示例: