对于数据量的统计,从表是否分区分为分区表和非分区表两者有着不同的统计方式
非分区表
1. 利用传统方法count
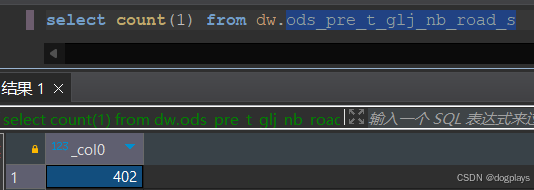
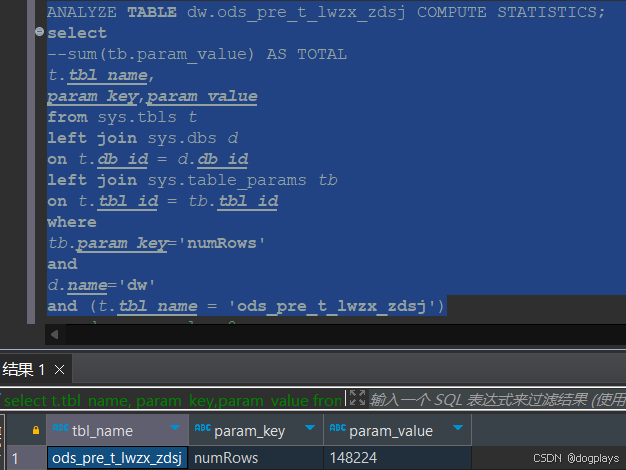
2. 利用元数据计算:
select
sum(tb.param_value) AS TOTAL
from sys.tbls t
left join sys.dbs d
on t.db_id = d.db_id
left join sys.table_params tb
on t.tbl_id = tb.tbl_id
where
tb.param_key='numRows'
and
d.name='dw'
and (t.tbl_name ='ods_pre_t_glj_nb_road_s')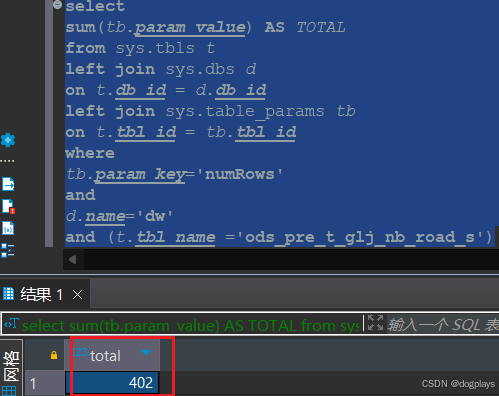
但是有时候会出现特殊情况,有非分区表的numrows为0
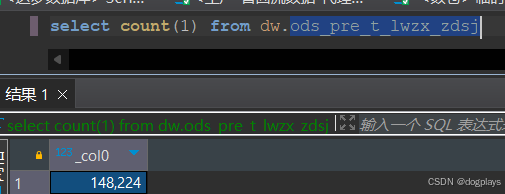
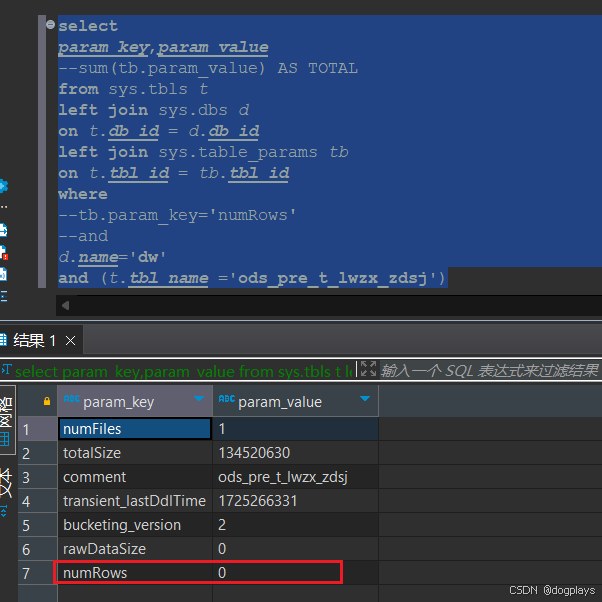
此时需要执行:
ANALYZE TABLE dw.ods_pre_t_lwzx_zdsj COMPUTE STATISTICS;重新再次执行SQL语句:numRows已经有数据了
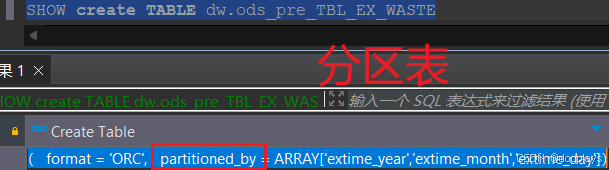
分区表
select
sum(e.PARAM_VALUE) as numRows
from sys.TBLS t
left join sys.DBS d
on t.DB_ID = d.DB_ID
left join sys.PARTITIONS a
on t.TBL_ID=a.TBL_ID
left join sys.PARTITION_PARAMS e
on a.part_id=e.part_id
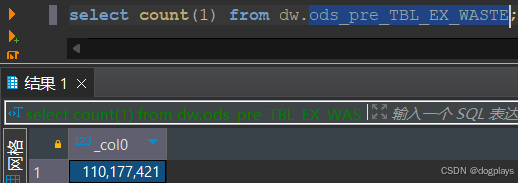
where t.TBL_NAME='ods_pre_tbl_ex_waste'
AND e.PARAM_KEY='numRows'同样也会出现统计数量为0或NULL或者数据量缺少的情况,此时同样需要执行
ANALYZE TABLE dw.ods_pre_t_lwzx_zdsj COMPUTE STATISTICS;ANALYZE TABLE
ANALYZE TABLE是什么?为什么每次元数据信息统计时总会出现个别统计不准确的情况?
ANALYZE TABLE 是 Hive 中用于收集表或分区统计信息的命令。它的作用是通过扫描数据文件来计算表或分区的关键统计信息,例如行数、数据大小、列值分布等。这些统计信息存储在 Hive 的元数据中,用于优化查询计划。
统计不准确的原因有很多,分区未被正确扫描、数据未完全加载或变动后未重新统计、数据文件格式的限制等等。
优化后的SQL:
SELECT
a.tbl_id,a.tbl_name,COALESCE(IF(a.table_numRows=0,b.PARTITION_numRows,a.table_numRows),0) as numRows
FROM
(
-- 各表总行数
SELECT
t.tbl_id,t.tbl_name,COALESCE(param_value,0) as table_numRows
from sys.TBLS t
left join sys.DBS d
on t.DB_ID = d.DB_ID
left join sys.table_params tb
on t.tbl_id = tb.tbl_id
-- 需要统计的数据库
where d.name='dw'
and tb.param_key='numRows'
)a
left join
(
-- 各分区表总行数
select
a.tbl_id,SUM(COALESCE(PARAM_VALUE,0)) as PARTITION_numRows
from
sys.PARTITIONS a
left join
sys.PARTITION_PARAMS b
on a.part_id=b.part_id
WHERE b.PARAM_KEY='numRows'
GROUP BY a.tbl_id
)b
ON a.tbl_id=b.tbl_id没有办法去批量的analyze表,可以写个shell脚本,执行以上优化后的SQL,将查询结果为0的表执行analyze以及所有分区表analyze后,再执行优化后的SQL。