整体介绍
布隆过滤器是一种数据结构,用于快速判断一个元素是否存在于一个集合中。它以牺牲一定的准确性为代价,换取了存储空间的极大节省和查询速度的显著提升。
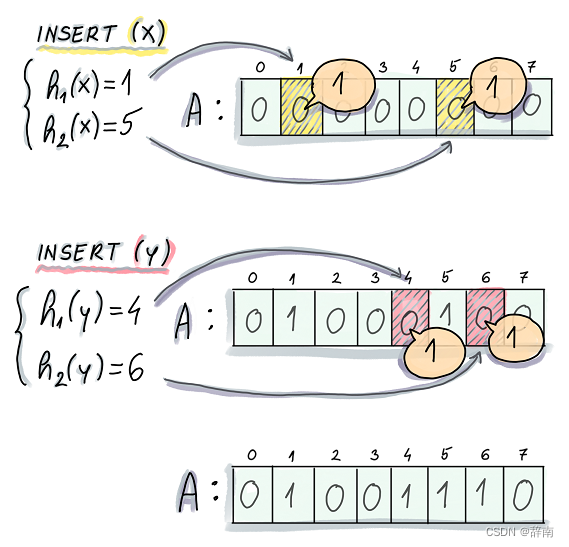
具体来说,布隆过滤器包含一个位数组和一组哈希函数。位数组的初始值全部置为 0。在插入一个元素时,将该元素经过多个哈希函数映射到位数组上的多个位置,并将这些位置的值置为 1。
因为每个元素存储都是以位来存储,而不是字节,所以元素的占用空间非常小。
1 字节(Byte)= 8 位(Bit)在计算机科学中,数据存储的最小单位是位(Bit),而字节(Byte)则是一个常用的数据存储单位,通常由8个位组成。
在查询一个元素是否存在时,会将该元素经过多个哈希函数映射到位数组上的多个位置,如果所有位置的值都为 1,则认为元素存在;如果存在任一位置的值为 0,则认为元素不存在。
布隆过滤器的优点在于它可以高效地判断一个元素是否属于一个大规模集合,且具有极低的存储空间要求。如果存储 1亿元素,误判率设置为 0.001 也就是千分之一,仅需要占用 171M左右的内存。
缺点在于可能会存在一定的误判率。
它在实际应用中常用于缓存场景下缓存穿透问题,对访问请求做一个快速判断机制。使用布隆过滤器能够有效减轻对底层存储系统的访问以及缓存系统的存储压力。
但是布隆过滤器本身也存在一些“弊端”,那就是不支持删除元素。因为它是一种基于哈希的数据结构,删除元素会涉及到多个哈希函数之间的冲突问题,这样会导致删除一个元素可能会影响到其他元素的正确性。
总的来说,布隆过滤器是一种非常高效的数据结构,适用于那些可以容忍一定的误判率的场合。
原理
计算方式
评估布隆过滤器的容量需要考虑两个重要的参数:错误率(false positive rate)和期望插入的元素数量。这两个参数会直接影响布隆过滤器的大小和所需的哈希函数的数量。
错误率(False Positive Rate):错误率是指布隆过滤器误判元素存在的可能性。布隆过滤器唯一可能的错误类型就是误判,即一个元素并未在布隆过滤器中,但进行查询时,布隆过滤器却判断该元素存在。这种误判结果就被称作"假阳性"。布隆过滤器的错误率可以根据应用需求进行调整,一般来说,接受更高的错误率可以减少布隆过滤器所需的空间。
期望插入的元素数量(Expected Number of Insertions):这是布隆过滤器预期要处理的元素数量。如果在创建布隆过滤器时低估了这个数量,错误率可能会比预期高;如果高估了这个数量,可能会造成空间浪费。
有了以上两个参数后,我们可以通过以下公式来估算布隆过滤器的大小和所需哈希函数数量:
布隆过滤器的位数组大小 m = -(n * log§) / (log(2)^2),其中,n 是期望插入的元素数量,p 是错误率。
哈希函数的最佳数量 k = m/n * log(2),其中,m 是位数组大小,n 是期望插入的元素数量。
以上公式可以帮助我们评估和优化布隆过滤器的容量。如果在实际应用中,预先知道了期望插入的元素数量,那么就可以通过这些公式合理设置布隆过滤器的大小和哈希函数数量,达到既能保证错误率,又能有效利用空间的效果。
Redisson 实现的布隆过滤器源码
核心是tryinit()函数,包含预期错误概率和预期插入量两个参数。
/**
* Initializes Bloom filter params (size and hashIterations)
* calculated from <code>expectedInsertions</code> and <code>falseProbability</code>
* Stores config to Redis server.
*
* @param expectedInsertions - expected amount of insertions per element
* @param falseProbability - expected false probability
* @return <code>true</code> if Bloom filter initialized
* <code>false</code> if Bloom filter already has been initialized
*/
boolean tryInit(long expectedInsertions, double falseProbability);
函数的具体实现如下:
@Override
public boolean tryInit(long expectedInsertions, double falseProbability) {
// 删掉了部分合法性校验代码
// 计算布隆过滤器的位数组大小
size = optimalNumOfBits(expectedInsertions, falseProbability);
// 计算最佳的哈希函数个数
hashIterations = optimalNumOfHashFunctions(expectedInsertions, size);
// 创建一个 CommandBatchService 实例,这个服务类用于批量执行 Redis 命令
CommandBatchService executorService = new CommandBatchService(commandExecutor);
// 在 Redis 中异步地执行一个 Lua 脚本,该脚本检查布隆过滤器的配置是否已经存在。
// 如果存在,脚本会断言失败,因为不应该更改已存在的布隆过滤器配置。
executorService.evalReadAsync(configName, codec, RedisCommands.EVAL_VOID,
"local size = redis.call('hget', KEYS[1], 'size');" +
"local hashIterations = redis.call('hget', KEYS[1], 'hashIterations');" +
"assert(size == false and hashIterations == false, 'Bloom filter config has been changed')",
Arrays.<Object>asList(configName), size, hashIterations);
// 异步写入布隆过滤器的配置到Redis
executorService.writeAsync(configName, StringCodec.INSTANCE,
new RedisCommand<Void>("HMSET", new VoidReplayConvertor()), configName,
"size", size, "hashIterations", hashIterations,
"expectedInsertions", expectedInsertions, "falseProbability", BigDecimal.valueOf(falseProbability).toPlainString());
// 尝试执行前面创建的批量命令
try {
executorService.execute();
} catch (RedisException e) {
if (e.getMessage() == null || !e.getMessage().contains("Bloom filter config has been changed")) {
throw e;
}
readConfig();
return false;
}
return true;
}
里面设计的两个计算函数的实现如下,可以看到与我们上面提到的公式一致。
// RedissonBloomFilter hash 函数个数计算方法
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
// RedissonBloomFilter bitmap 位数计算方法
private long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
实际使用
实际使用时候我们也不会直接去手动计算以上大小,可以借助网站工具直接进行计算。
布隆过滤器内存占用预估参考网站: Bloom Filter Calculator
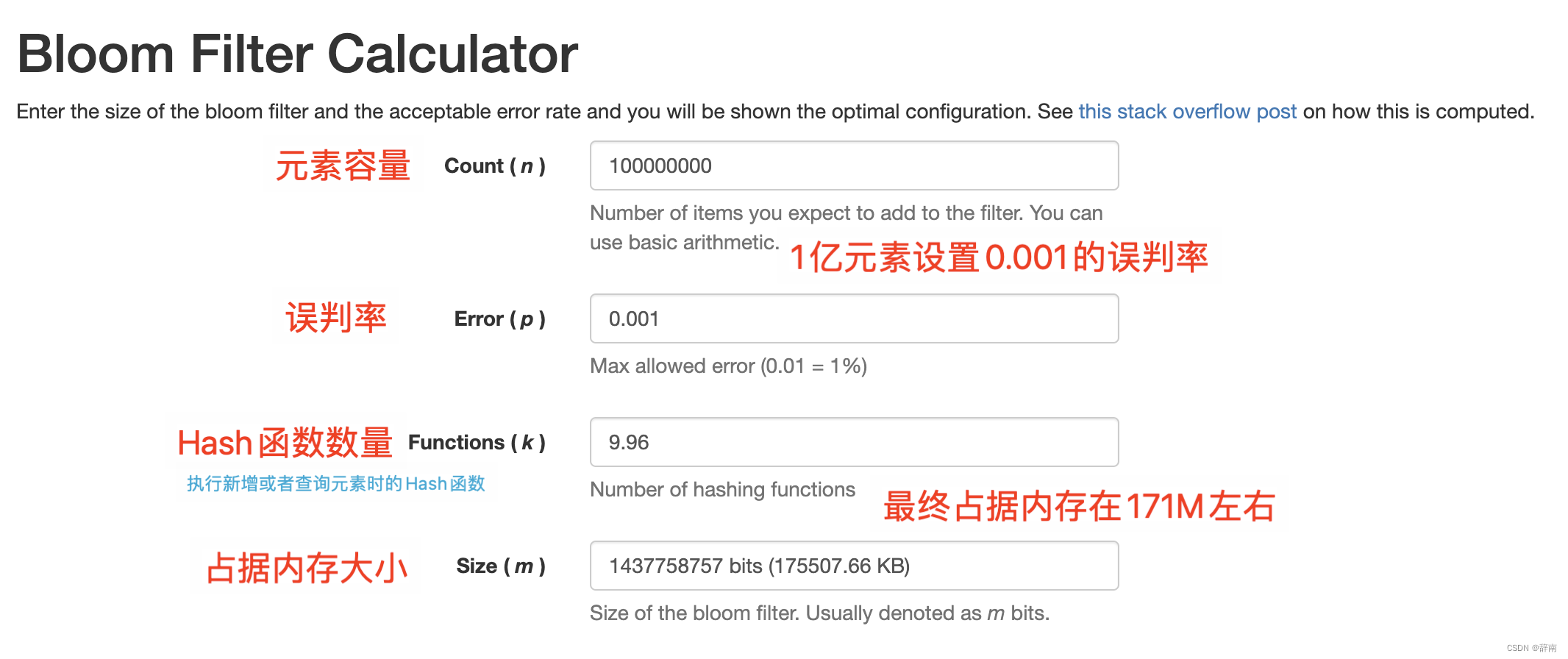
如何判断这个数据的真实性?很简单,你在设置好参数初始化布隆过滤器时,它会初始化一个位数组,这个容量是固定的且一次性申请对应容量的内存。
经过实际测试,基本与上述网站评估一致。另外和大家说个小 Tips,Redisson 布隆过滤器在 Redis 中是以字符串方式存储的,底层数据结构是 Redis 中的 BitMap(位图)。

常见的布隆过滤器
网上布隆过滤器有很多种,比如 Guava 的内存布隆过滤器以及 Redisson 分布式(基于 Redis)布隆过滤器,从实际场景实战上来说,本地内存相对来说更宝贵些,一般都是基于 Redisson 的分布式布隆过滤器。
备注:Redisson 和 Redis 之间的关系。Guava 操作的布隆过滤器是基于 JVM 内存,每次新增都是在 JVM 加一条数据,而 Redisson 则是操作 Redis 进行存储以及查询。
SpringBoot 实际应用(Redisson 布隆过滤器为例)
为了更好了解布隆过滤器,我们就以 SpringBoot 项目整合 Redisson 布隆过滤器来演示。
1)引入 Redisson SpringBoot Starter 依赖包。
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.21.3</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<!-- 默认从SpringBoot父版本中传递依赖 -->
</dependency>
2)配置文件中填充 Redis 相关参数。
spring:
data:
redis:
host: 127.0.0.1
port: 6379
3)创建布隆过滤器实例,假设我们布隆过滤器场景用来防止检查用户是否重复时查询数据库。
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 布隆过滤器配置
*/
@Configuration
public class RBloomFilterConfiguration {
/**
* 防止检查用户是否重复时查询数据库的布隆过滤器
*/
@Bean
public RBloomFilter<String> userRegisterCachePenetrationBloomFilter(RedissonClient redissonClient) {
RBloomFilter<String> cachePenetrationBloomFilter = redissonClient.getBloomFilter("userRegisterCachePenetrationBloomFilter");
cachePenetrationBloomFilter.tryInit(100000000L, 0.001);
return cachePenetrationBloomFilter;
}
}
4)代码中如何使用布隆过滤器。
因为已经把布隆过滤器声明成 Spring 的 Bean 对象了,所以我们可以通过依赖注入的方式将 Bean 引入到我们的业务类中即可。
@Service
public class AService {
@Autowired
private RBloomFilter<String> userRegisterCachePenetrationBloomFilter;
public void testBloomFilter() {
// 新增数据到布隆过滤器中
userRegisterCachePenetrationBloomFilter.add("lisi");
// 判断元素是否存在布隆过滤器
boolean hasUsername = userRegisterCachePenetrationBloomFilter.contains("lisi");
}
}
布隆该过滤器容量不够怎么办?
- 评估容量做好,提前预防
- 有一种特殊的布隆过滤器可以做动态扩容,但是实施比较复杂
- 做一个定时任务,新建一个布隆过滤器,把原布隆过滤器里的数据转移到新的
- 使用多个布隆过滤器,例如使用两个布隆过滤器,通过配置参数进行切换
所以最好的就是,一开始做好容量评估,不要出了问题再想解决方案
为什么不用Set而用布隆过滤器?
1、占用空间过大
当使用布隆过滤器时,它使用了一个位数组来表示元素的存在性。这个位数组的长度通常会根据预期的元素数量进行设置。相比之下,Set 结构需要存储元素的实际值。
因为 Set 结构需要存储实际的元素值。在内存中,每个元素都需要占用一定的空间。对于大量元素的情况,存储这些元素所需的内存空间会相应增加。
举个例子来说明,假设我们有一个存储 1,000,000 个短链接的数据集。如果使用 Set 结构来存储这些短链接,每个短链接可能需要几十个字节的空间。这意味着存储这些元素可能需要数十兆字节的内存。
相比之下,使用布隆过滤器可以显著减少内存消耗,从而节省大量内存空间。
需要注意的是,布隆过滤器的位数组长度和哈希函数的数量会影响到误判率和内存消耗之间的权衡。较小的位数组和较少的哈希函数可能会降低内存消耗,但也会增加误判率。因此,在使用布隆过滤器时,需要根据实际需求和对误判率的容忍程度进行适当的配置。
2、大 Key 问题
设想,我们短链接中如果使用 Set,那么极有可能会发生一个 Set 存储数百万甚至上千万的元素,这就涉及到大 Key 问题。
Redis 中的 “大 Key” 通常指的是一个占用较大内存空间的键(Key)。这可能会对 Redis 的性能产生负面影响,因为大 Key 可能导致内存碎片化、删除延迟以及网络传输时间延长等问题。
“大 Key” 的概念相对主观,具体取决于应用程序的需求、硬件配置以及 Redis 实例的总内存大小。在一般情况下,如果一个键的数据量占用了大量的内存比例,可能就可以被认为是大 Key。
具体的大小标准没有固定的规定,因为这取决于多个因素,我们可以在应用设计时按照一个简约的标准执行:
● String Key 存储内容最多不允许超过 5MB。
● LIST、SET、ZSET 等类型的 Key,成员数量最多不允许超过 20000。
● Hash 类型的 Key,Key 数量参考上条。同时,内部 Key 对应的 Val 不应该过大,不然还是可能成为大 Key。
以上观点参考了多家 Redis 开发规范,但就像上面说的,大 Key 的概念更多取决于应用程序需求、硬件配置以及实例总大小,所以没有标准限制。
大 Key 可能会导致以下问题:
● 内存碎片化:大 Key 占用的内存块较大,可能导致内存碎片化,从而影响 Redis 的内存使用效率。
● 网络传输延迟:传输大 Key 的数据可能会导致较长的网络传输时间,特别是在进行备份、迁移或从节点同步等操作时。
● 删除阻塞:在删除大 Key 的过程中,可能会导致其他操作的响应时间变长。这是因为在删除大 Key 时,需要遍历键中的所有元素,并在内部进行相应的清理操作。在此期间,其他操作会等待删除操作完成。
● 持久化延迟:如果 Redis 实例使用了持久化机制(如 RDB 快照或 AOF 日志),删除大 Key 可能会导致持久化操作的延迟,因为持久化过程也需要处理大 Key 的数据。