50 亿数据如何去重?
面对一个如此大的数据集进行去重(例如50亿数据条目),我们需要考虑内存和存储空间的限制,同时还需要有一个高效的算法。一般来说,这样的数据量无法直接载入内存进行处理,因此需要采用磁盘存储和分布式处理的技术。以下是一些可行的方法:
- 外部排序:
将数据分为多个批次,每个可以加载到内存中。
对每一批数据进行排序和去重,然后存回磁盘。
对所有排序且去重后的批次进行归并排序,同时去重。
- 哈希切分(Hash partitioning):
使用哈希函数将数据分配到不同的桶(Bucket)或文件中,确保相同的数据项会落到同一个桶里。
对每个桶的数据进行内存中去重操作。
对所有桶进行并行处理以提升效率,并最终合并结果。
- Bitmap方法:
使用Bitmap算法,每一位表示一个数据,此方法适用于非负整数数据,尤其是范围较小的情况。
如果数据范围过大,可以结合哈希切分使用。
- Bloom过滤器:
使用Bloom Filter预处理数据,快速刷选出可能重复的数据。
通过更精确的方法再次检查这部分数据以确认去重。
分布式系统处理:
如果单机处理能力有限,可以使用分布式计算框架如Hadoop或Spark。
在这样的系统中可以使用MapReduce或Spark的RDD/DataFrame转化操作来进行分布式去重。
- 数据库和NoSQL解决方案:
利用支持强大索引机制的数据库进行去重操作。
使用如Redis这样的内存数据库,通过其内置的数据结构和算法进行高效去重处理,特别是需要实时去重的场景。
针对50亿这样大规模的数据,任何单一的技术可能都不足够,通常需要结合使用多种技术和算法。务必考虑实际应用场景,数据的特性和可用资源。处理如此大量数据通常还伴随着各种系统层面的优化,包括IO优化、内存管理和并发控制等方面。
50 亿数据如何排序?
处理50亿数据的排序问题时,传统单机内存排序是不现实的,因为这样的数据量远远超出了常规服务器的内存容量。因此,需要采用一些特殊的技术和方法来处理这种大规模数据集。以下是几种处理这类问题的方法:
- 外部排序:
最基本的处理大数据排序的方法是外部排序,特别是当数据无法全部加载到内存中时。外部排序的基本思路是将大文件分割成多个小文件,小文件加载到内存中进行排序,然后再将排序后的小文件合并成一个有序的大文件。
这个过程通常涉及到数据的分块、排序、合并等步骤。经典的算法是多路归并排序(K-way Merge Sort)。
- 分布式排序:
使用分布式计算框架,如Hadoop或Spark,可以将数据分布到多个节点上并行处理。
在Hadoop上可以使用MapReduce编程模型实现分布式排序,其中Map阶段进行局部排序,Reduce阶段负责将所有结果合并成全局有序的数据。
Spark提供了更为高效的内存计算能力,可以使用它的sortBy或orderBy函数来进行分布式数据排序。
- 利用数据库:
可以将数据导入关系型数据库或NoSQL数据库中,利用数据库的索引和查询优化器来实现排序。关系型数据库对于排序功能的支持很成熟,可以很方便地处理外部排序。
使用排序软件:
有一些专门的大数据排序软件和工具,如Unix/Linux环境下的sort命令,它支持对大文件进行外部排序。通过合理地配置参数,sort命令可以在处理大文件时,自动将数据分割、排序和合并。
- 堆排序和内存映射:
对于稍微小一些的数据集或者可以被划分为小块进行处理的数据集,可以使用堆排序结合内存映射文件的技术。内存映射文件可以让你以接近内存速度访问磁盘上的数据,而堆排序可以帮助你有效地从中找到最小(或最大)元素。
处理50亿数据排序的关键在于将问题分解,并利用并行处理和磁盘I/O优化等方法来提升效率。在实际操作中,要根据数据的具体特征和可用资源来选择最合适的方法。
举例:40亿QQ号如何设计算法去重(相同的QQ号码仅保留一个,内存限制为1个G)
腾讯的QQ号都是4字节正整数,所以QQ号码的个数是43亿左右,理论值2^32-1个,又因为是无符号的,翻倍了一下,所以43亿左右。
方法1:排序
这估计也是最多人能够想到的解决方法,那就是排序,重复的QQ肯定会挨在一起,然后保留第一个,去重就行了。排序后的去重比较简单就不在这里赘述。
但是这么做的问题显然很大,时间复杂大太高了,效率低下。
方法2:hsahmap
hashmap的意思:
如果使用hashmap,好处是由于hashmap的去重性质,就可以做到去重。看似上个问题的效率问题解决了,但是又遇到了新的问题,1g的内存太小,解决不了。
方法3:文件切割
对于海量数据问题,可以使用文件切割方式,避免内存过大。但是还是需要使用文件间的归并排序、桶排序、堆排序等等,但是这么多文件操作,40亿的数据量还是比较大,那么有没有更好的方法。
方法4:bitmap位图操作
可以对hashmap进行优化,采用bitmap这种数据结构,可以顺利地同时解决时间问题和空间问题。
在很多实际项目中,bitmap经常用到。
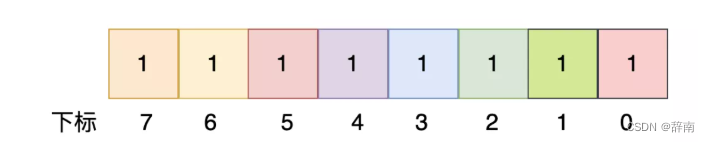
bitmap就是一种位图。(位图的每一位都只有0和1两个状态)
上面是一个unsigned char类型的位图,一共有八位,那么取值范围就是0-255,就可以标识0-7数字都在,就比如说bitmap【6】=1,那么就可以理解为,QQ号为6的号码是存在的。
那么可以理解为实际上是利用他的下标来表示某个号码是否存在的。
一个unsigned int类型数据是4个字节,那么就是可以表示0-31这 32个数字是否存在。
那么两个unsigned int就是8个字节,那么8x8bit就是0-63个数字表示是否存在。
显然,容易推到,只需要申请512MB的空间大小就可以标识所有QQ号码是否存在,那么就可以完成题目要求了。 形成一个bitmap,例如 bitmap【118677520】= 1(ture)就代表我这个QQ号码是存在的。
然后从小到大遍历所有的正整数(4个字节),当bitmap【】=1的时候,就可以表明是存在的了。
这里再回顾下最开始的问题:40亿QQ号如何设计算法去重,相同的QQ号码仅保留一个,内存限制为1个G。
现在进行问题拓展:
1、文件中有40亿个互不相同的QQ号码,请设计算法对QQ号码进行排序,内存限制1G.
很显然还是上面的思路,直接用bitmap,然后输出,输出后的正整数序列就是排序后的序列了。
2、文件中有40亿个互不相同的QQ号码,求这些QQ号码的中位数,内存限制1G.
还是用bitmap排序比较合适。
3、文件中有40亿个互不相同的QQ号码,求这些QQ号码的top-K,内存限制1G.
可以使用小顶堆或者文件切割,但是用bitmap会更好一些。
经过上面的问题,会发现这类问题有趣多了,明显是有套路通解的。
海量数据题总结
1.Hash算法处理海量数据部分
【题目1】给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
【题目2】海量日志数据,提取出某日访问百度次数最多的那个IP。
【题目3】有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
【题目4】有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
2.Top-K海量数据部分
【题目1】(360公司 2012) 100万条记录的文本文件,取出重复数最多的前10条。
【题目2】(360公司 2012) 100亿条记录的文本文件,取出重复数最多的前10条。
【题目3】(腾讯公司 2011) 服务器内存1G,有一个2G的文件,里面每行存着一个QQ号(5-10位数),怎么最快找出出现过最多次的QQ号。
【题目4】(腾讯公司 2015 牛客网) 搜索引擎的日志要记录所有查询串,有一千万条查询,不重复的不超过三百万,要统计最热门的10条查询串,内存<1G,字符串长 0-255。
(1) 主要解决思路;(2) 算法及其复杂度分析。
3.bit海量数据部分
【题目1】(腾讯公司)给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
【题目2】(July整理) 在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数。
【题目3】40亿QQ号如何设计算法去重,相同的QQ号码仅保留一个,内存限制为1个G。
Hash算法处理海量数据
hash:任意长度的输入通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,其实hash就是找到一种数据内容和数据存放地址之间的映射关系。
hash有几种常用的hash函数:
直接取余法、乘法取余法、平方取中法。
数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组”,如上图所示。
适用范围:快速查找,删除的基本数据结构,通常需要总数据量可以放入内存。
那么hash算法在海量数据中的应用过程可以分这么几步:
1、分而治之思想、hash思想。
也就是说采用hash取模进行等价映射,将巨大的文件进行等价分割,注意,如果采用hash取模,不论是什么hash函数,符合一定规律也就是同一种规律或同类数据都是会被分割到同一个小文件中的,变成若干个小文件的操作。这个方法对于数据量很大的时候,内存有限制的时候是十分有效的。
2、利用haspmap在内存中进行统计。
通过Hash映射将大文件分割为小文件后,就可以采用HashMap这样的存储结构来对小文件中的关注项进行频率统计。具体的做法是将要进行统计的Item作为HashMap的key,此Item出现的次数作为value。
3、对存储在HashMap中的数据根据出现的次数进行排序。
排序我们可以采用堆排序、快速排序、归并排序等方法。
现在可以看看具体的解法了。
题目1:给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
思路: 还是老一套,先Hash映射降低数据规模,然后统计排序。
具体做法:
(1) 分析现有数据的规模
按照每个url64字节来算,每个文件有50亿个url,那么每个文件大小为5G*64=320G(按照1000换算10亿字节=1GB)。320G远远超出内存限定的4G,所以不能将其全部加载到内存中来进行处理,需要采用分而治之的方法进行处理。
(2) Hash映射分割文件
逐行读取文件a,采用hash函数:Hash(url)%1000将url分割到1000个小文件中,文件即为f1_1,f1_2,f1_3,…,f1_1000。那么理想情况下每个小文件的大小大约为300M左右。再以相同的方法对大文件b进行相同的操作再得到1000个小文件,记为: f2_1,f2_2,f2_3,…,f2_1000。
经过一番折腾后我们将大文件进行了分割并且将相同url都分割到了这2组小文件中下标相同的两个文件中,其实我们可以将这2组文件看成一个整体:
f1_1& f2_1, f1_2& ,f2_2, f1_3& f2_3,…, f1_1000& f2_1000
那么我们就可以将问题转化成为求这1000对小文件中相同的url就可以了。接下来,求每对小文件中的相同url,首先将每对对小文件中较小的那个的url放到HashSet结构中,然后遍历对应这对小文件中的另一个文件,看其是否存才刚刚构建的HashSet中,如果存在说明是一样的url,将这url直接存到结果文件就ok了。如果存在大文件接着hash划分即可。

Top-K问题解决

bitmap处理海量数据


这类题的方法涉及到很多知识,包括:
Bloom Filter、Hash、Bit-Map、堆(Heap)、分而治之、数据库索引、倒排索引、外排序、Trie树(字典树)、MapReduce