1. self-attention
文章原文: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
李弘毅视频学习: https://www.bilibili.com/video/BV1Wv411h7kN?p=23
概念讲解: https://luweikxy.gitbook.io/machine-learning-notes/self-attention-and-transformer
-
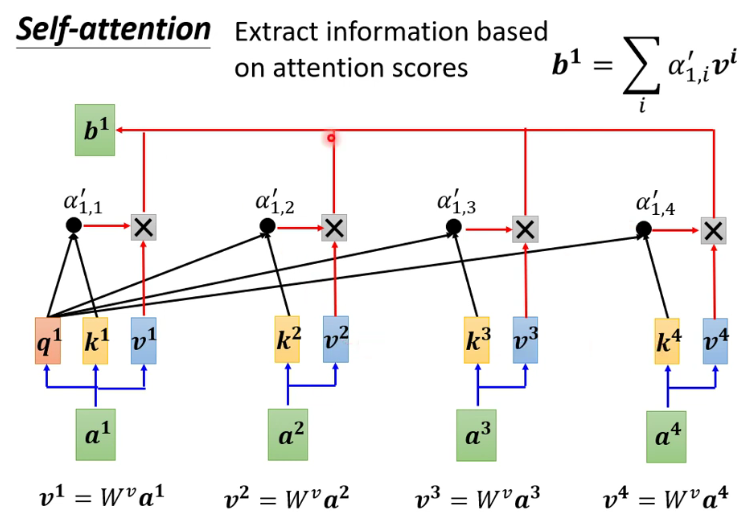
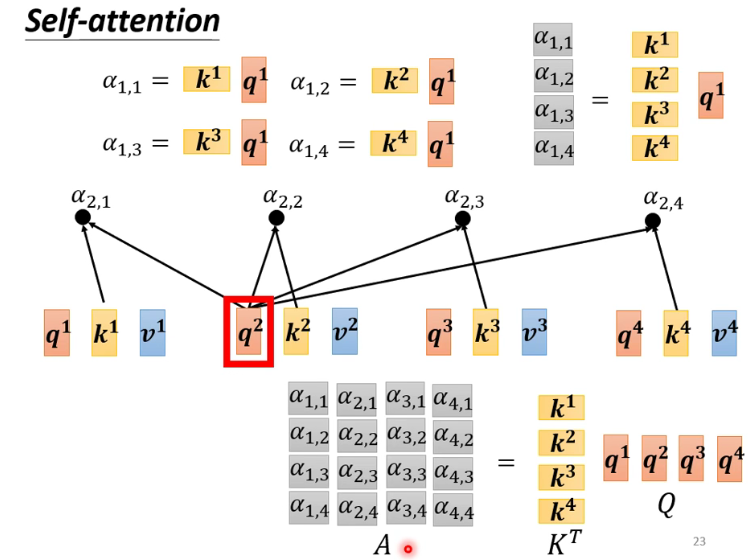
1
-
2
-
3
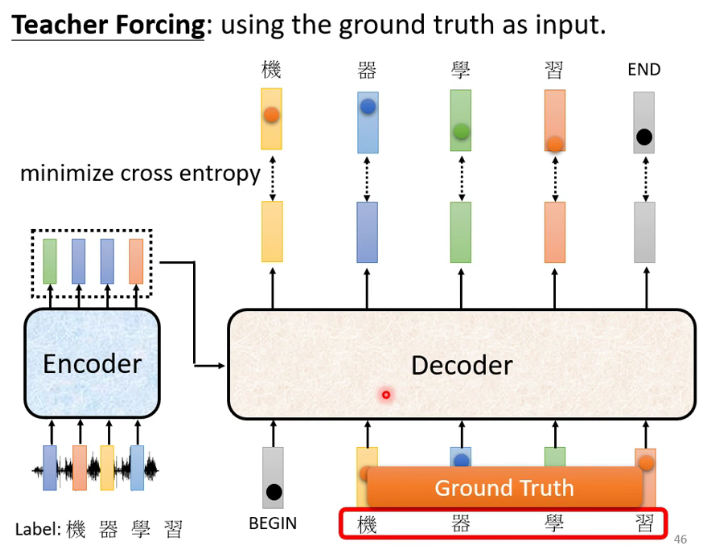
注:红框为transformer的常用方法 -
4
注:其中,除了可以使用softmax以外,Relu等也可以使用。 -
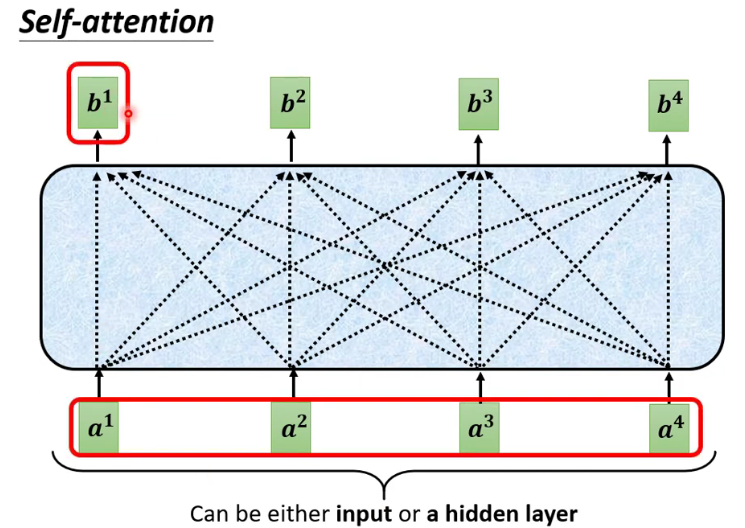
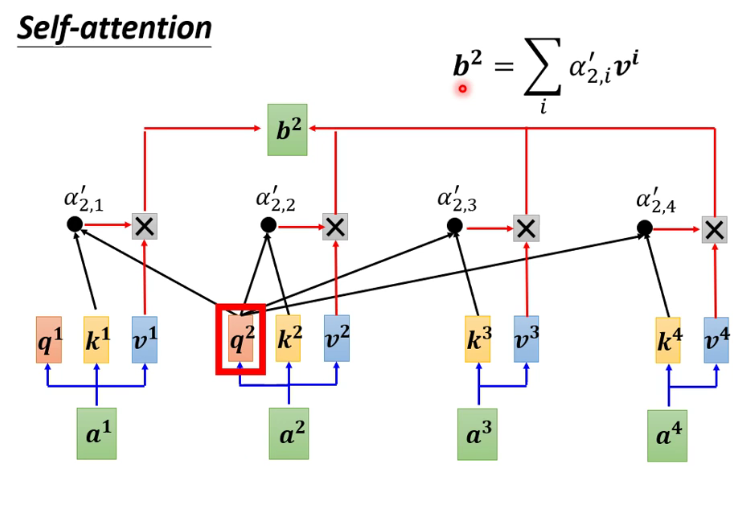
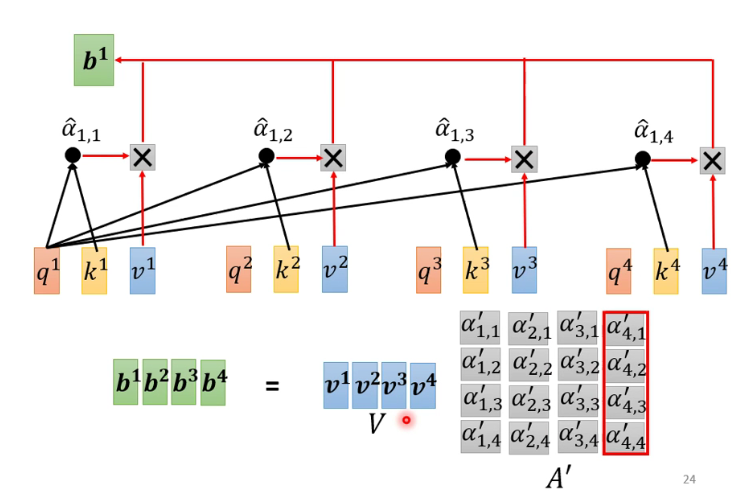
5
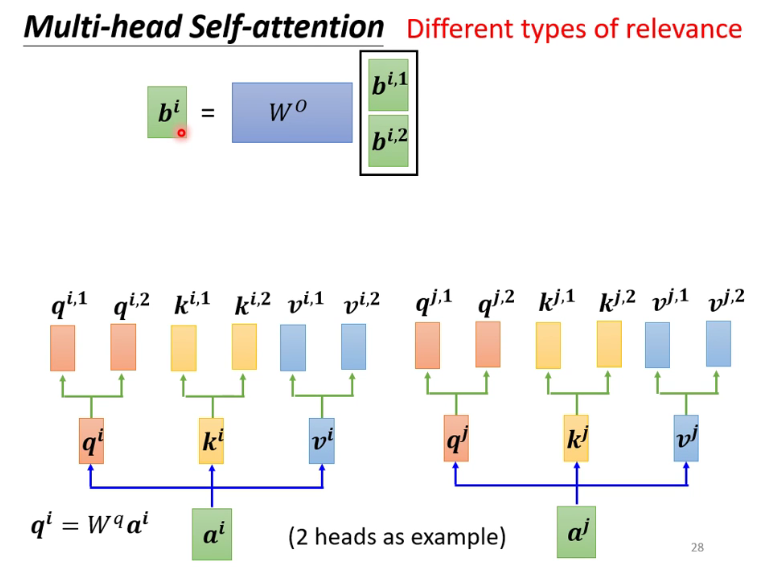
注: b1到b2是并行计算的 -
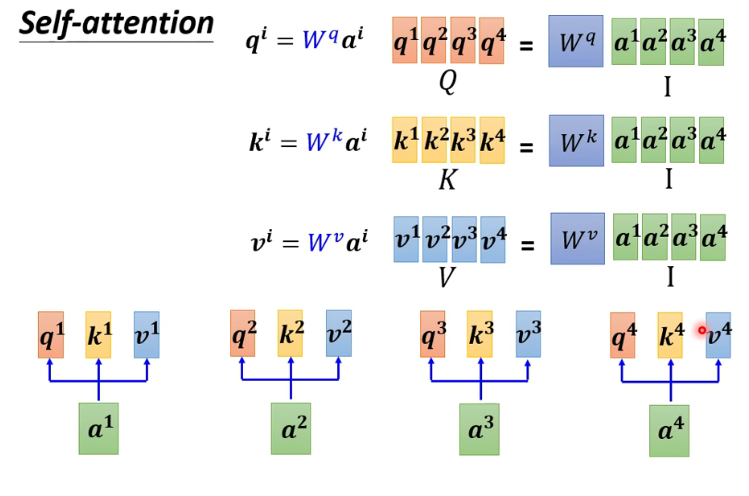
6
-
7
-
8
-
9
-
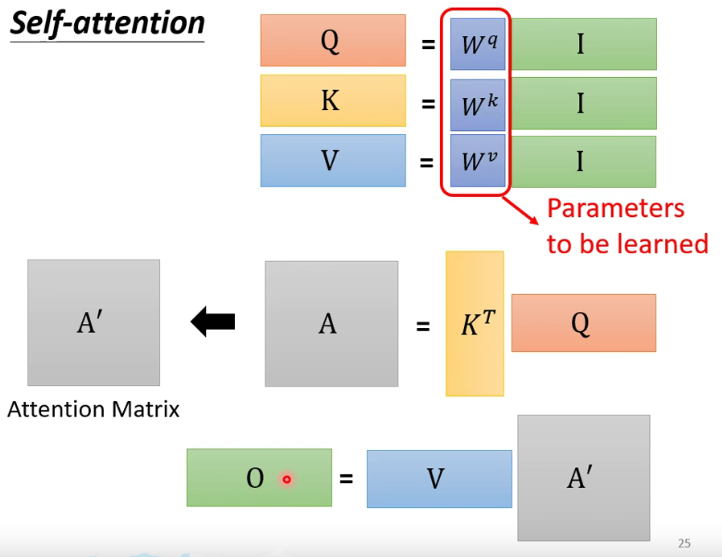
10
注: 整个seif-attention的操作就是从I到O -
11
-
12
-
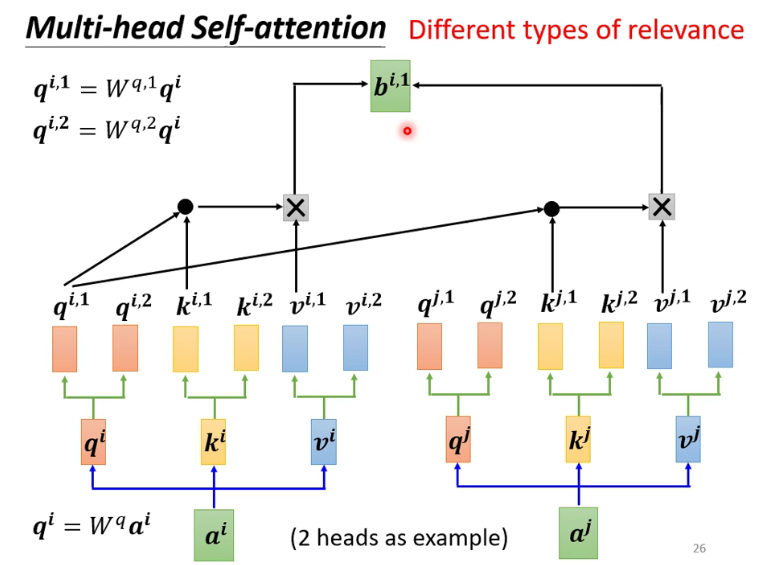
13
-
14
-
15
-
16
-
17
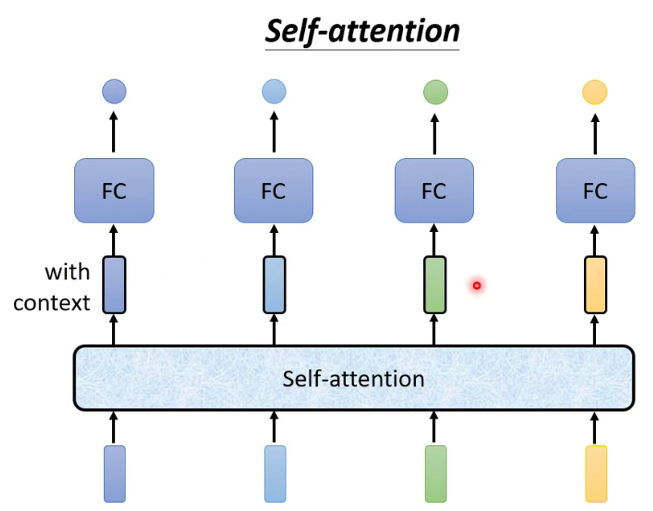
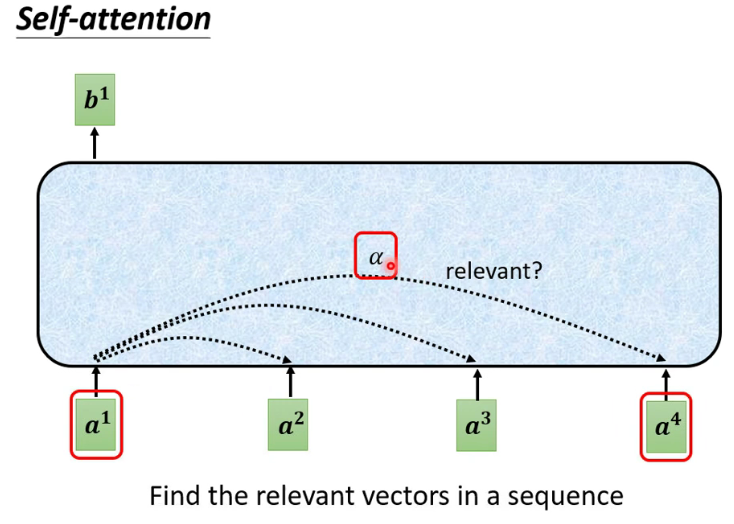
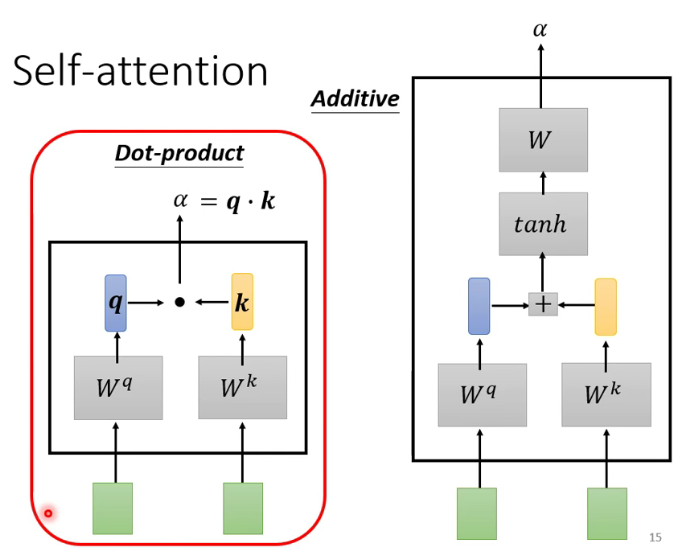
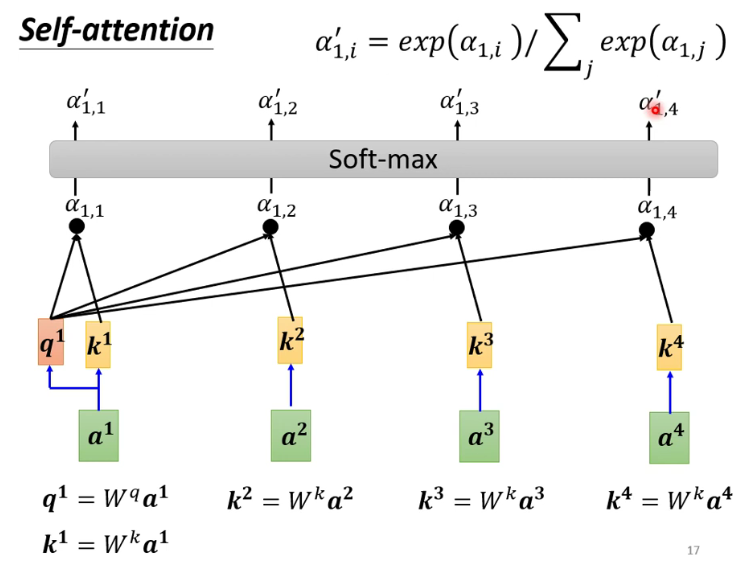
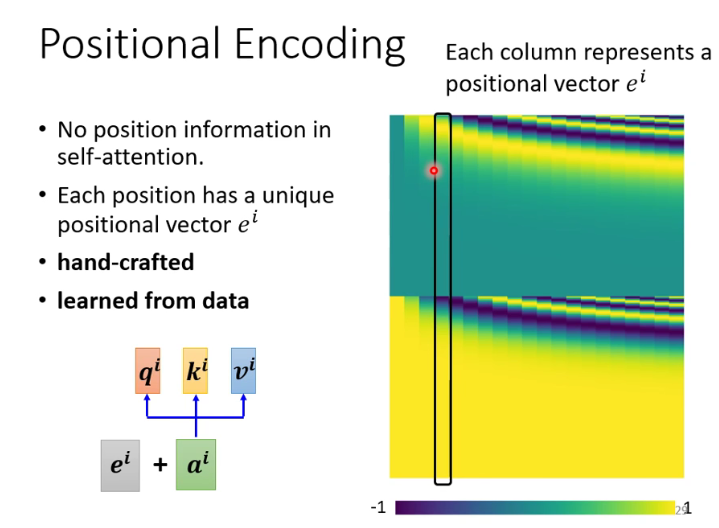
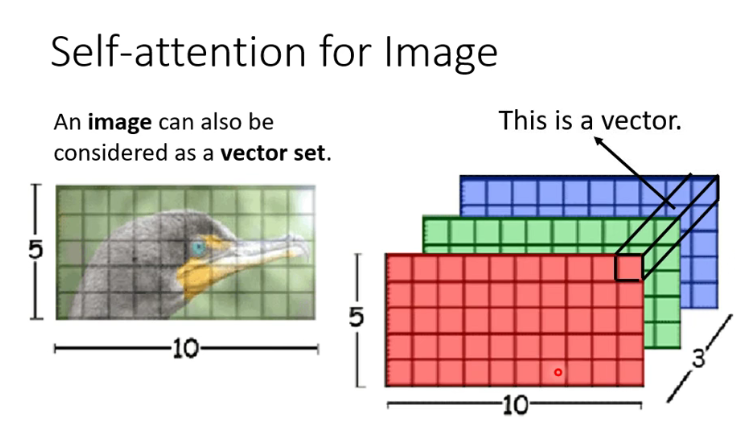

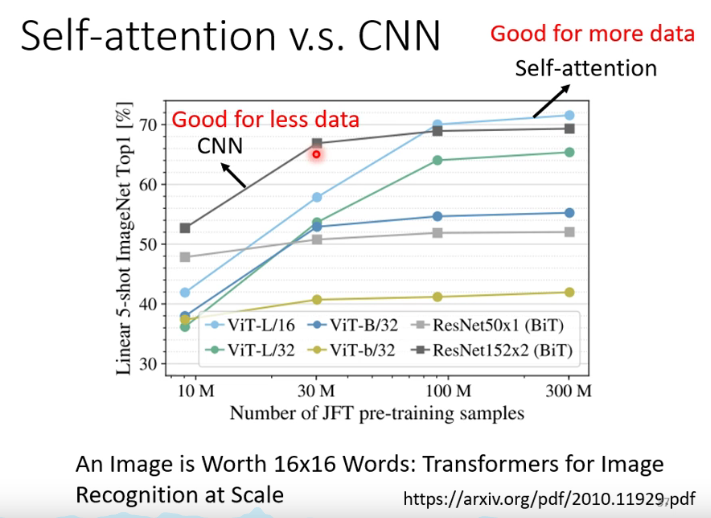
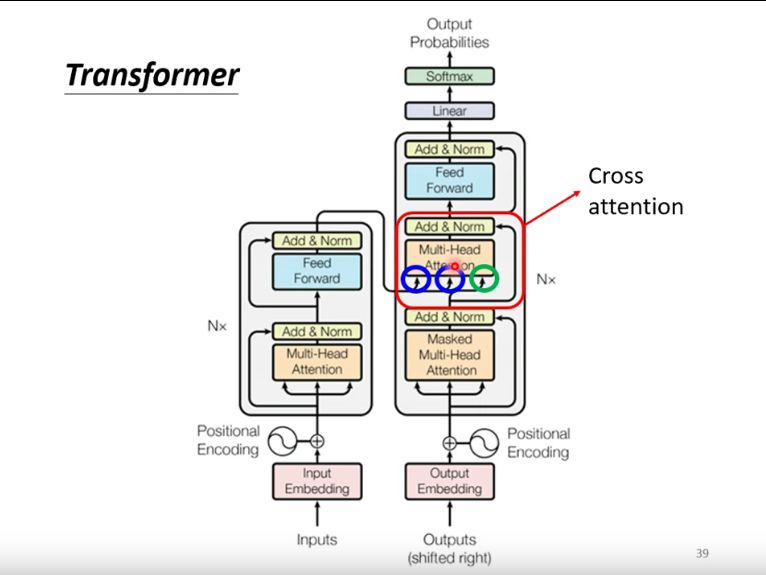
2. Transformer
文章原文: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
李弘毅视频讲解: https://www.bilibili.com/video/BV1Wv411h7kN?p=34
概念讲解:
https://luweikxy.gitbook.io/machine-learning-notes/self-attention-and-transformer
https://zhuanlan.zhihu.com/p/48508221
Transformer特点
优点:
1.每层计算复杂度比RNN要低。
2.可以进行并行计算。
3.从计算一个序列长度为n的信息要经过的路径长度来看, CNN需要增加卷积层数来扩大视野,
RNN需要从1到n逐个进行计算,而Self-attention只需要一步矩阵计算就可以。
Self-Attention可以比RNN更好地解决长时依赖问题。当然如果计算量太大,
比如序列长度N大于序列维度D这种情况,也可以用窗口限制Self-Attention的计算数量。
4.Self-Attention模型更可解释,Attention结果的分布表明了该模型学习到了一些语法和语义信息。
缺点:
1.有些RNN轻易可以解决的问题Transformer没做到,比如复制String,或者推理时碰到的sequence长度比训练时更长(因为碰到了没见过的position embedding)
2.理论上:transformers不是computationally universal(图灵完备),而RNN图灵。完备,这种非RNN式的模型是非图灵完备的的,无法单独完成NLP中推理、决策等计算问题(包括使用transformer的bert模型等等)。
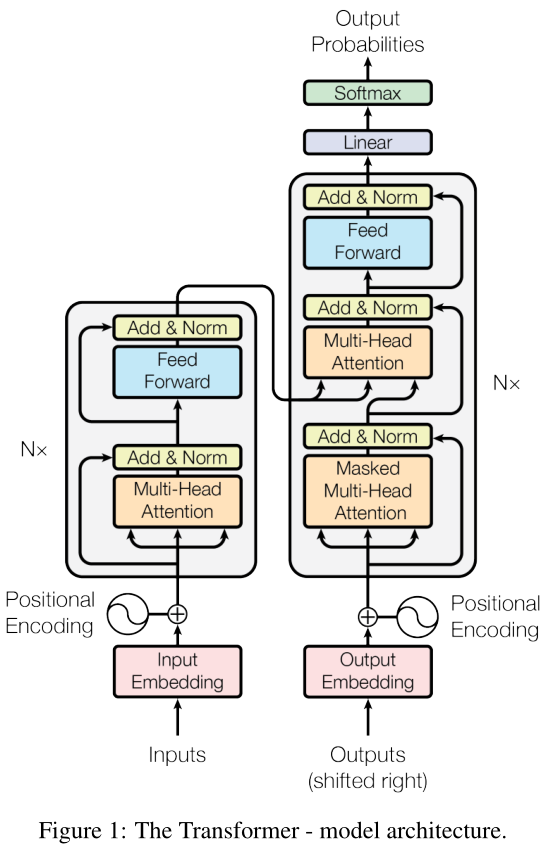
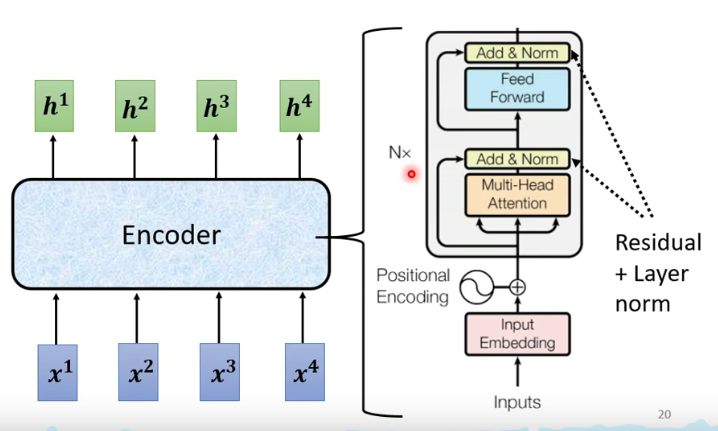
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。
-
1
-
2
-
3
-
4
-
5
-
6
-
7
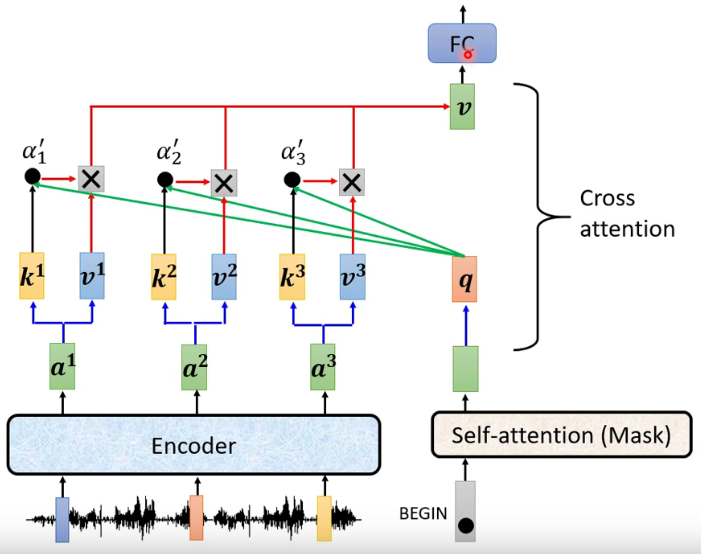
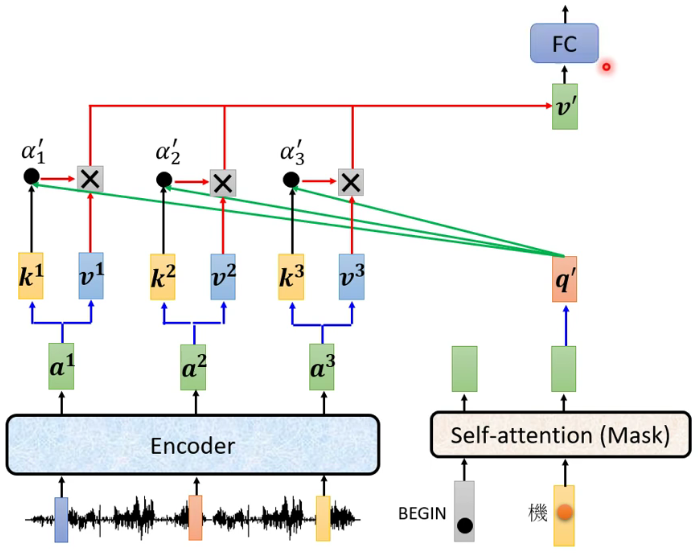
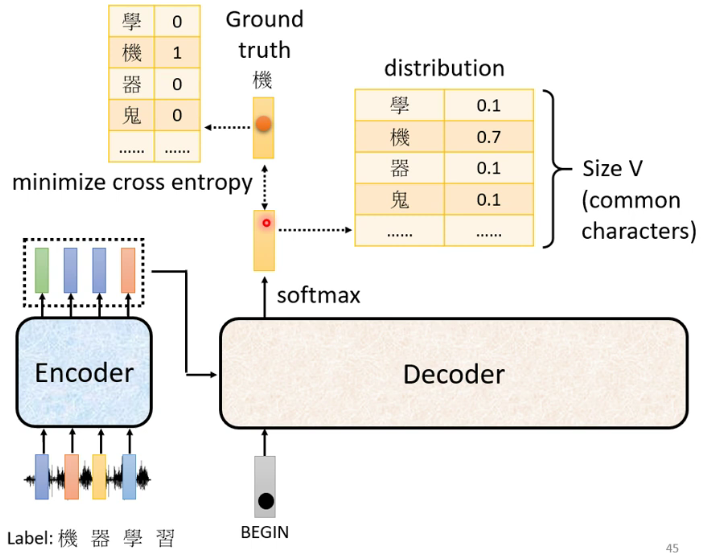
Q是query向量,决定key中哪些信息需要被关注。K是key向量,和Q相乘用的,作用就是一个key了。V是value向量。K和Q相乘,再过一个Relu,得到的筛选向量决定value中哪些信息需要被关注。
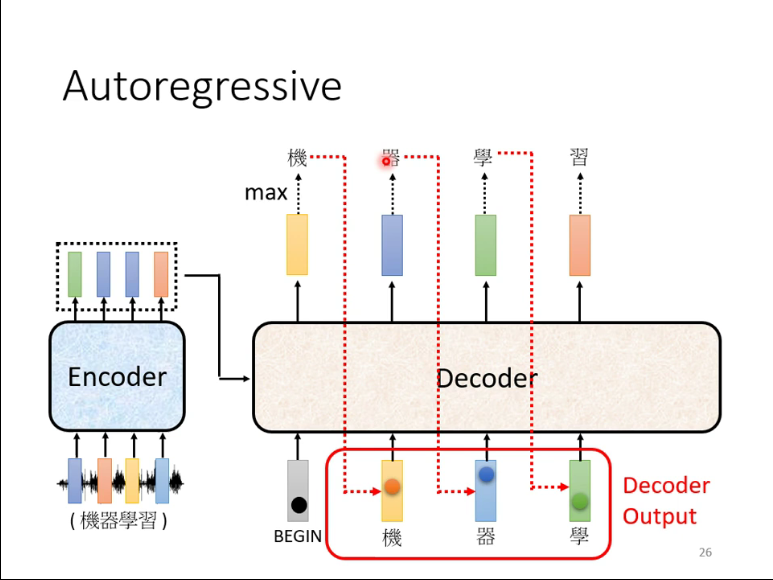
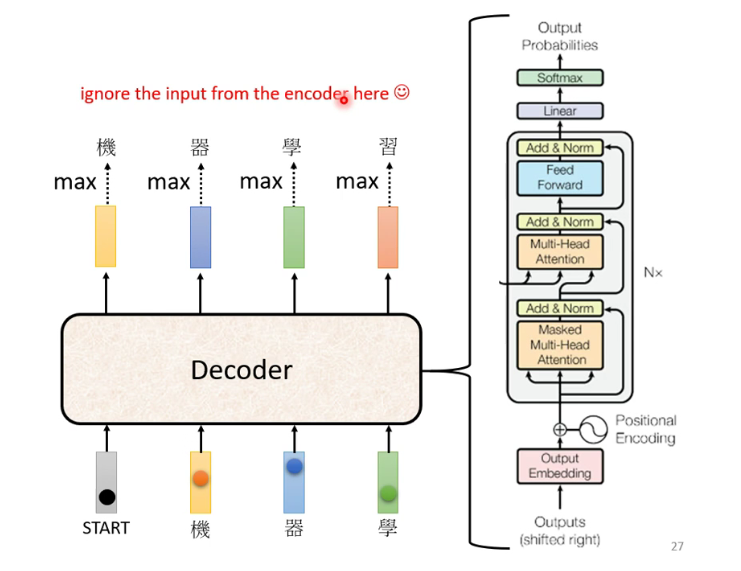
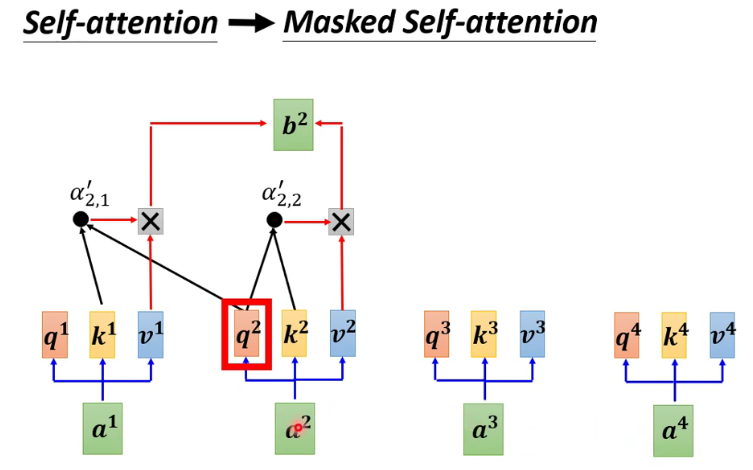
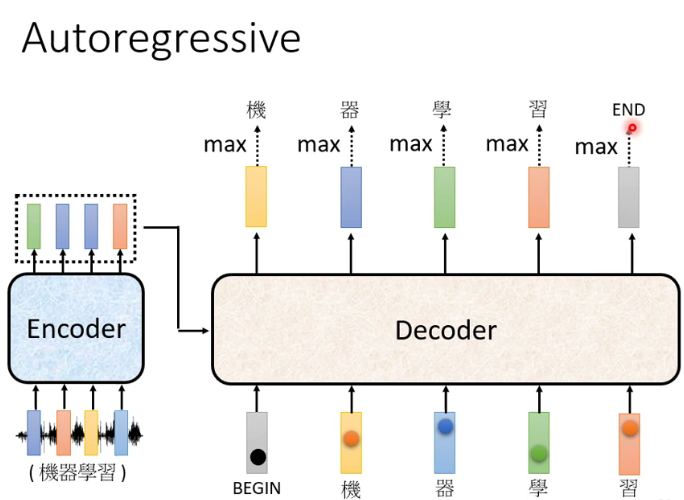
注: 由于是根据前一个的信息去学习,所以只能学习左边的,无法学习到右边的(Mask) -
8
-
9
-
10
-
11
-
12
-
13
-
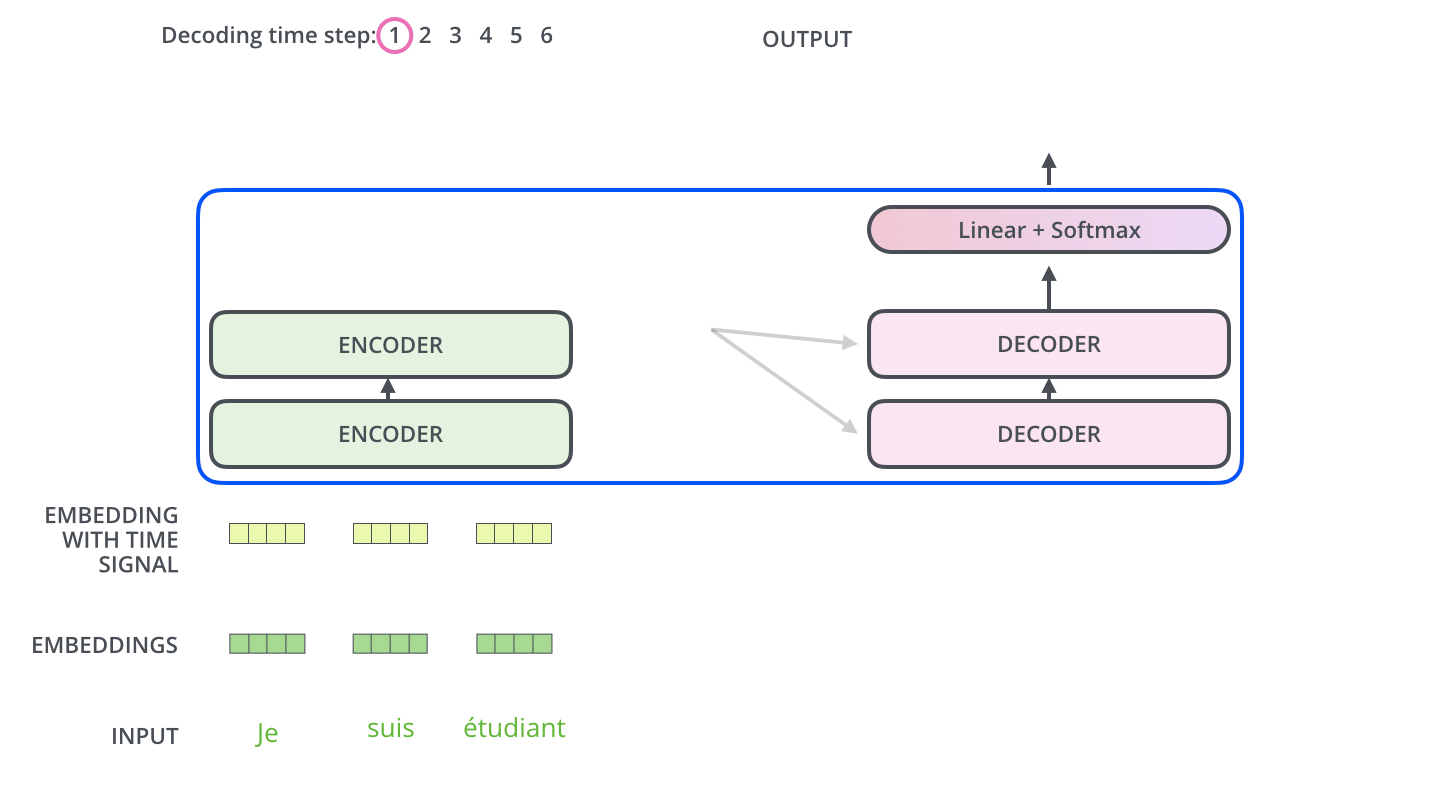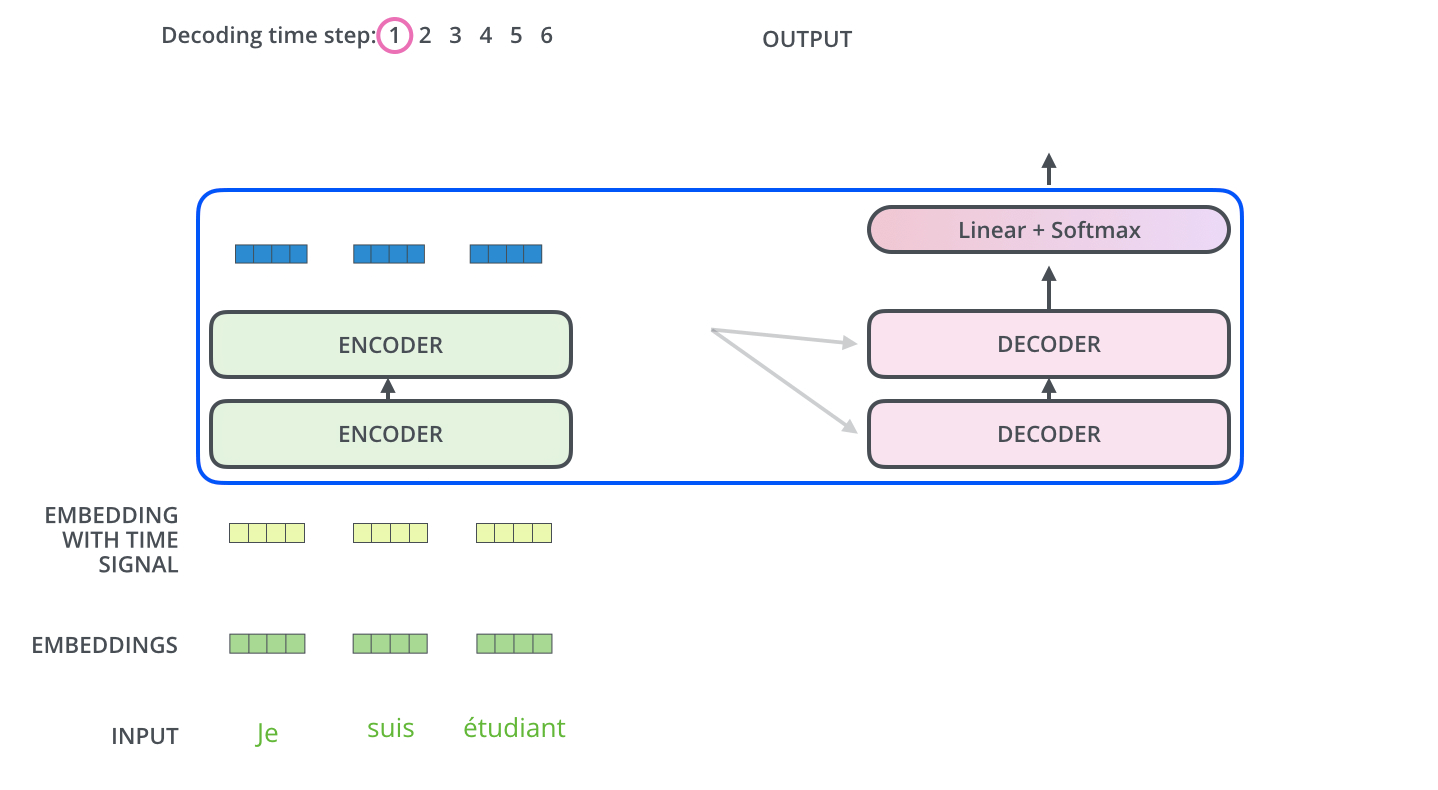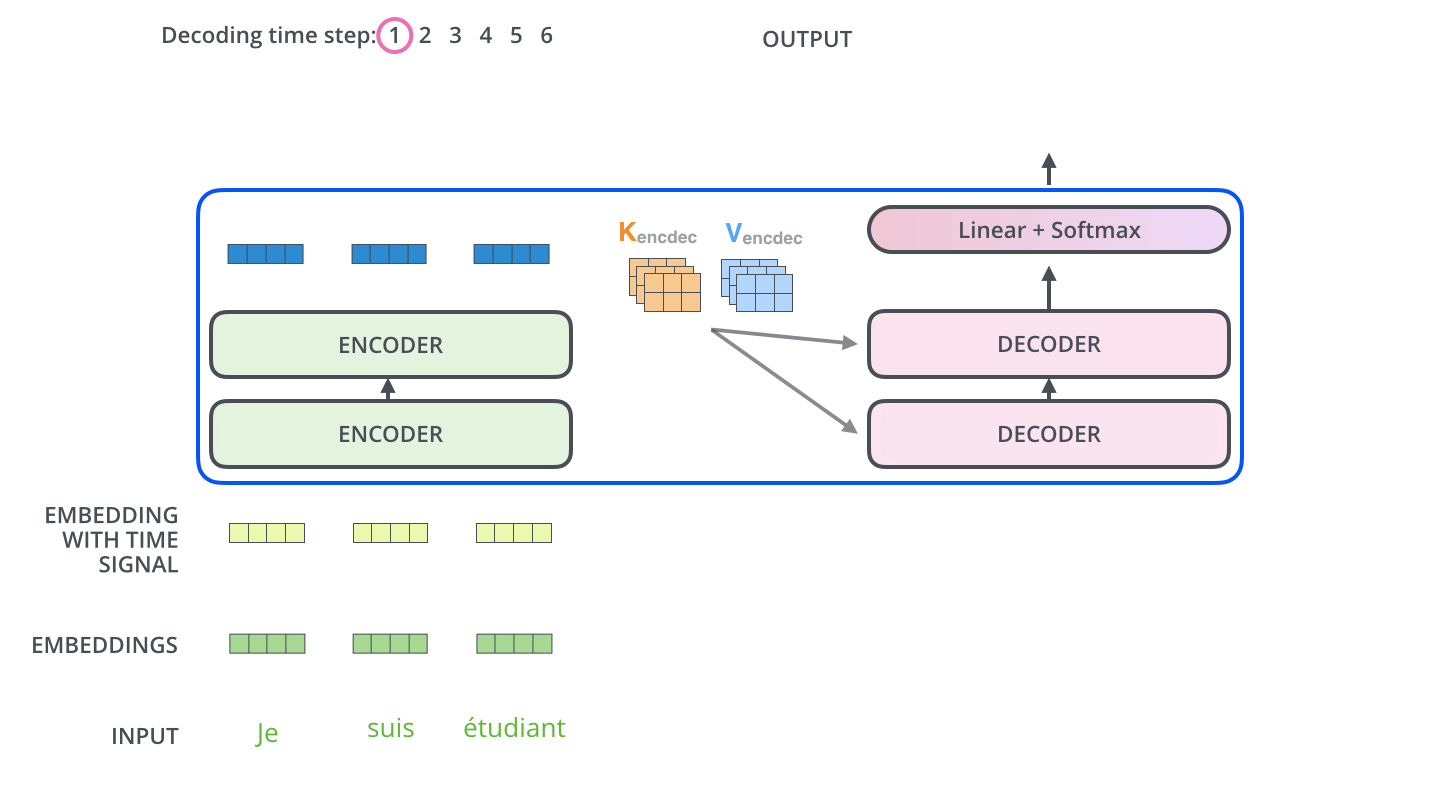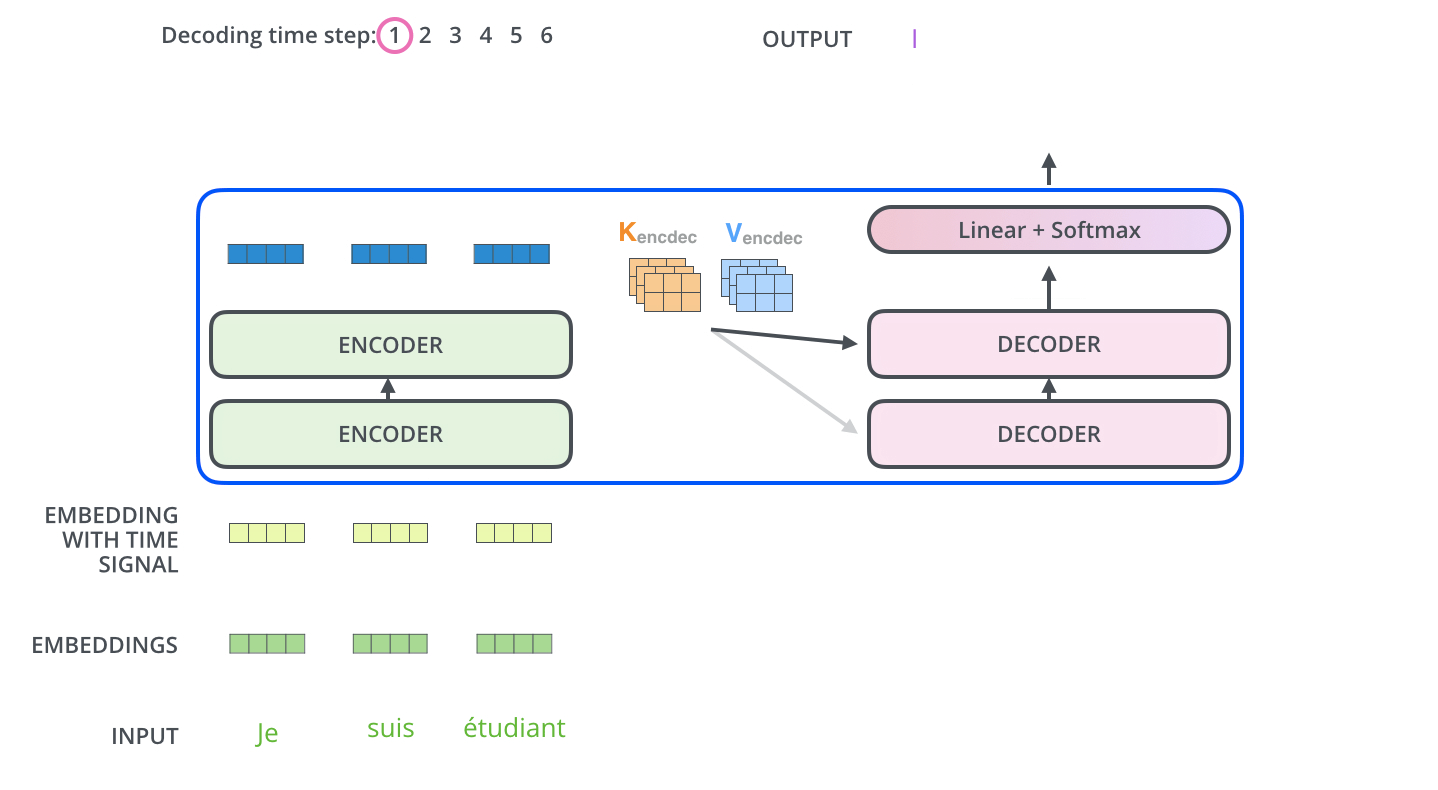
transformer-process-1
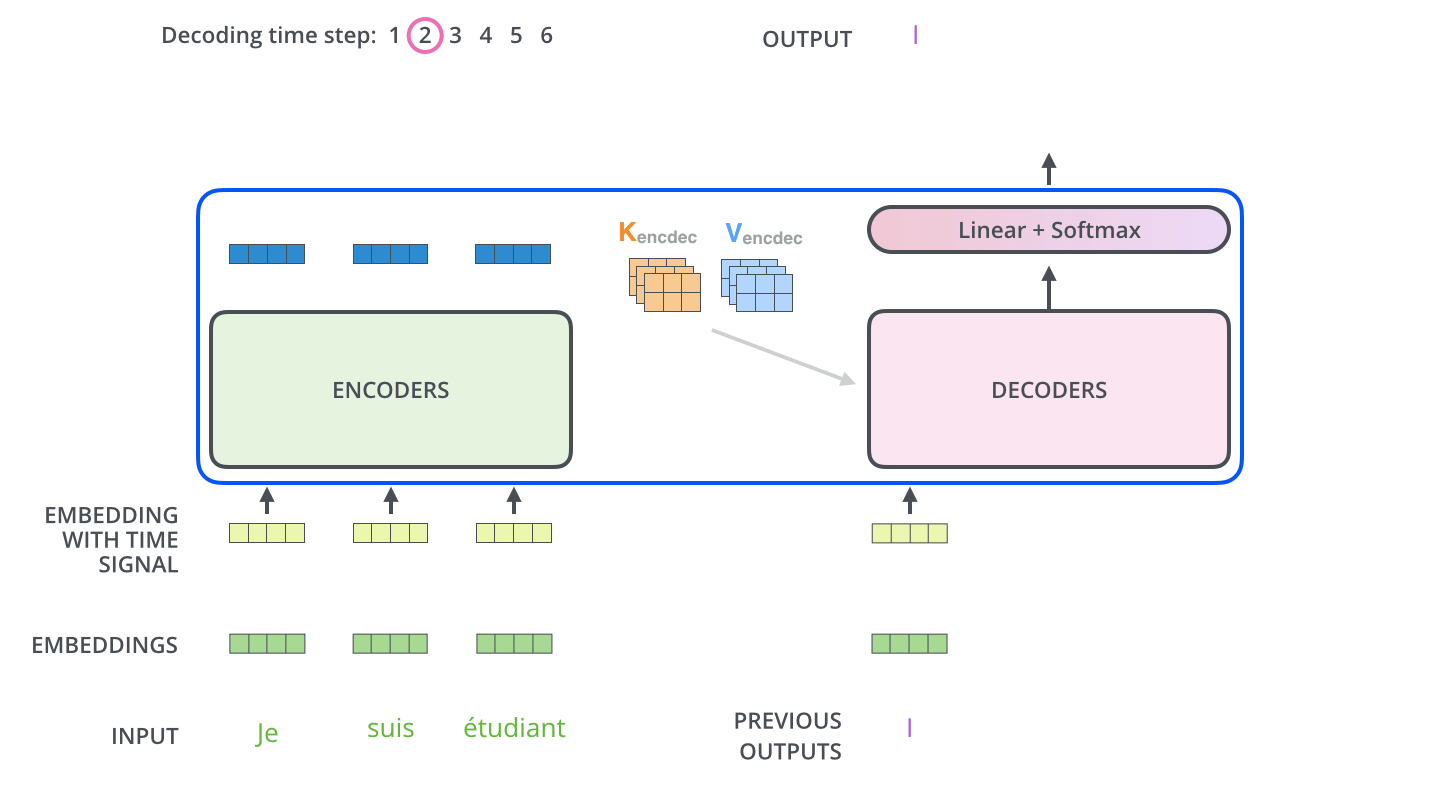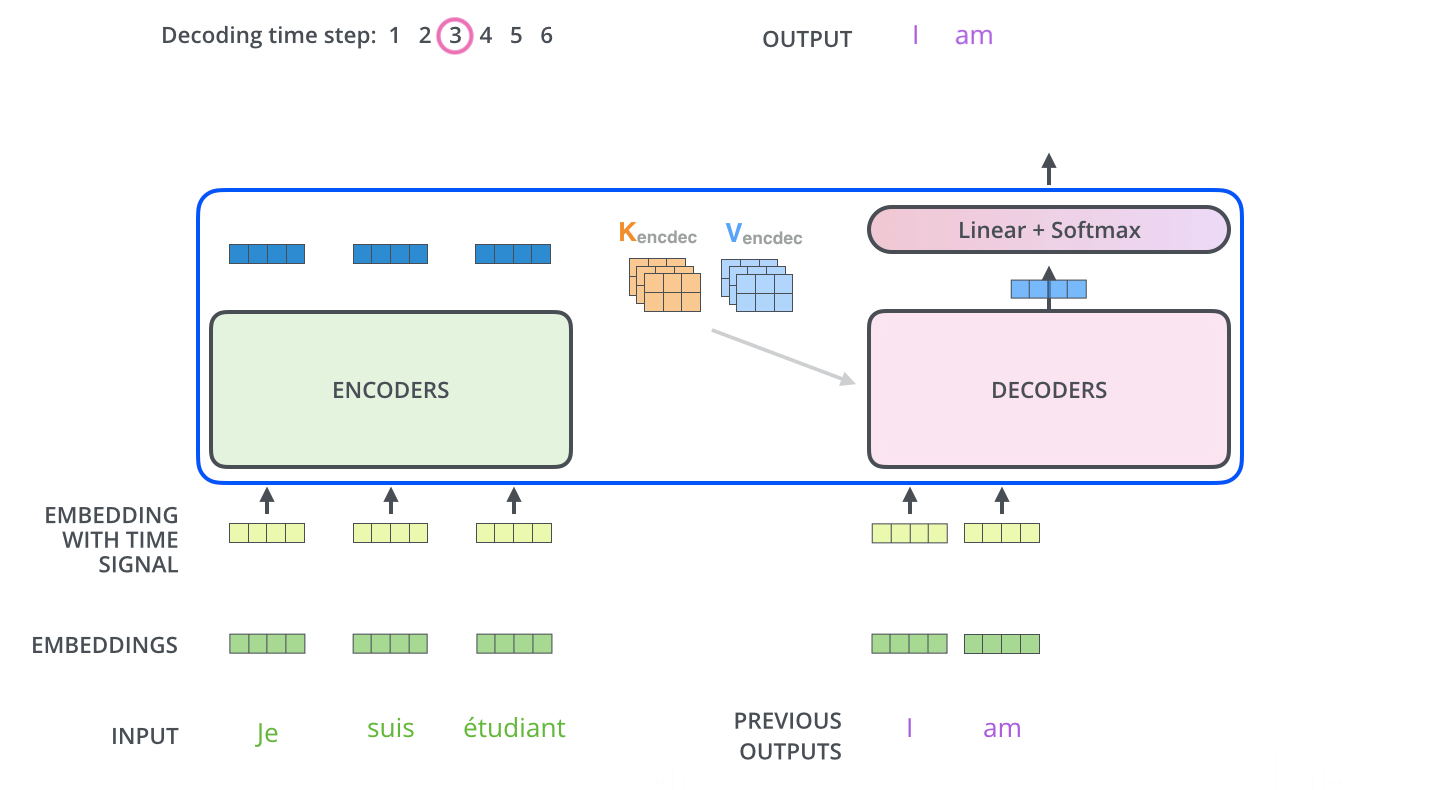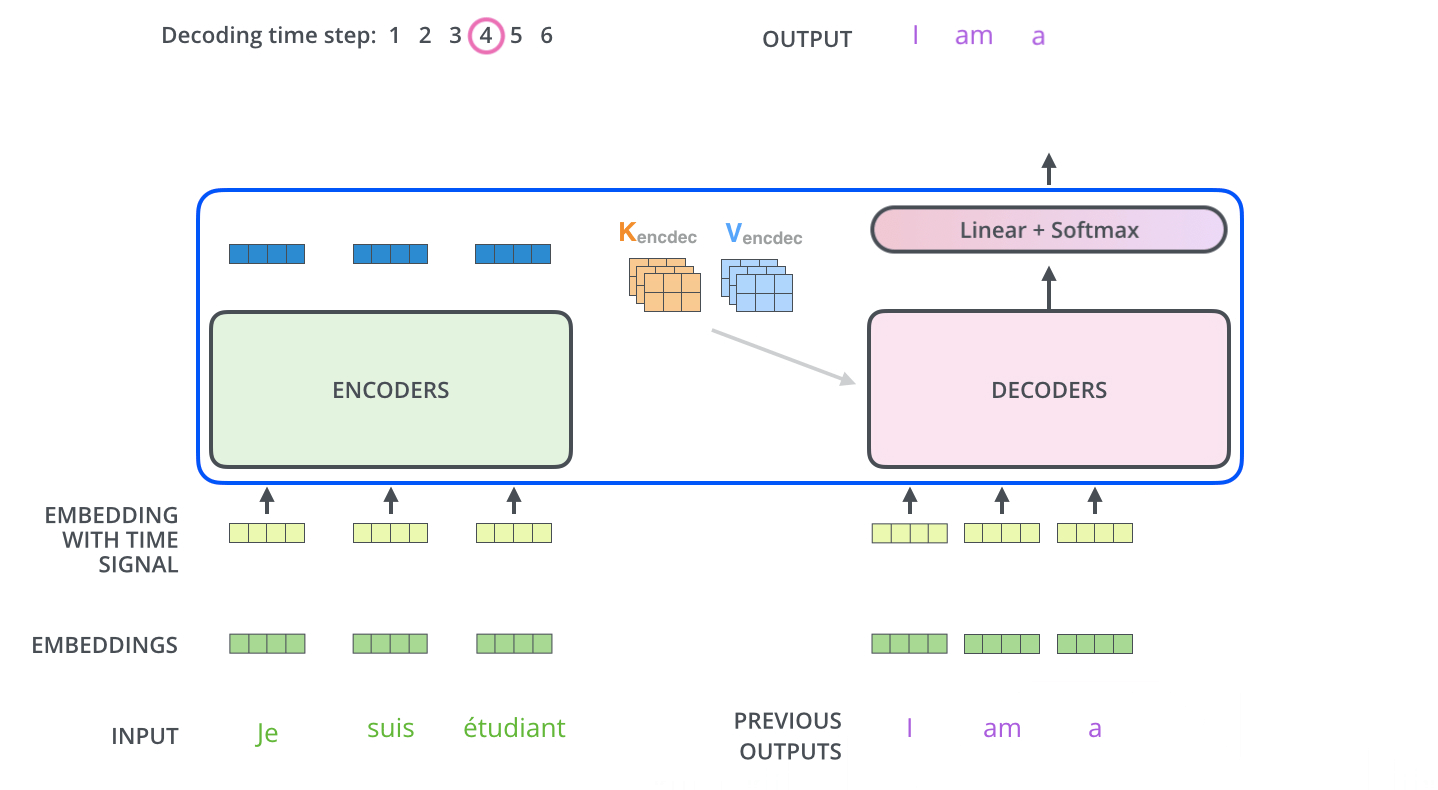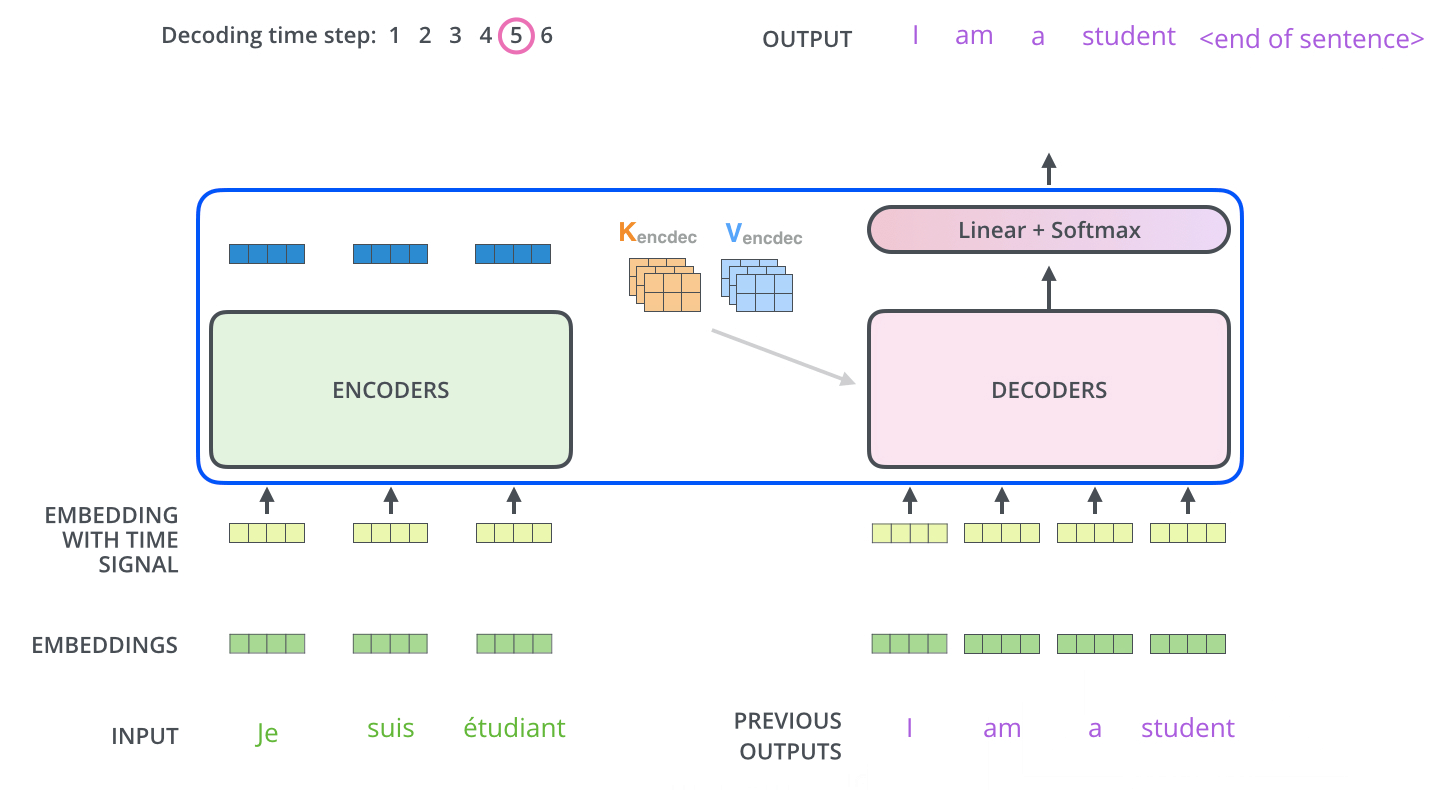
Encoder通过处理输入序列开启工作。Encoder顶端的输出之后会变转化为一个包含向量(键向量)和(值向量)的注意力向量集 ,这是并行化操作。这些向量将被每个Decoder用于自身的“Encoder-Decoder注意力层”,而这些层可以帮助Decoder关注输入序列哪些位置合适:
-
transformer-process-2
在完成Encoder阶段后,则开始Decoder阶段。Decoder阶段的每个步骤都会输出一个输出序列(在这个例子里,是英语翻译的句子)的元素。接下来的步骤重复了这个过程,直到到达一个特殊的终止符号,它表示Transformer的解码器已经完成了它的输出。每个步骤的输出在下一个时间步被提供给底端Decoder,并且就像Encoder之前做的那样,这些Decoder会输出它们的Decoder结果 。
-
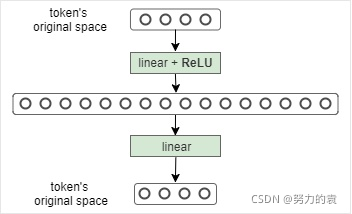
Feed-Forward Layer
将Multi-Head Attention得到的提炼好的向量再投影到一个更大的空间(论文里将空间放大了4倍)在那个大空间里可以更方便地提取需要的信息(使用Relu激活函数),最后再投影回token向量原来的空间。这个可以借鉴SVM来理解:SVM对于比较复杂的问题通过将特征其投影到更高维的空间使得问题简单到一个超平面就能解决。这里token向量里的信息通过Feed Forward Layer被投影到更高维的空间,在高维空间里向量的各类信息彼此之间更容易区别,即使像ReLU这样的也可以完成提取信息的任务。
https://zhuanlan.zhihu.com/p/47510705 -
多层感知机(Multilayer Perceptron,MLP)
神经网络要解决的基本问题是分类问题。
引自:https://zhuanlan.zhihu.com/p/63184325
3. ViT
文章原文: https://arxiv.org/pdf/2010.11929.pdf
文章解析:
https://blog.csdn.net/ViatorSun/article/details/115586005
https://zhuanlan.zhihu.com/p/342261872
ViT的主要几个部分:
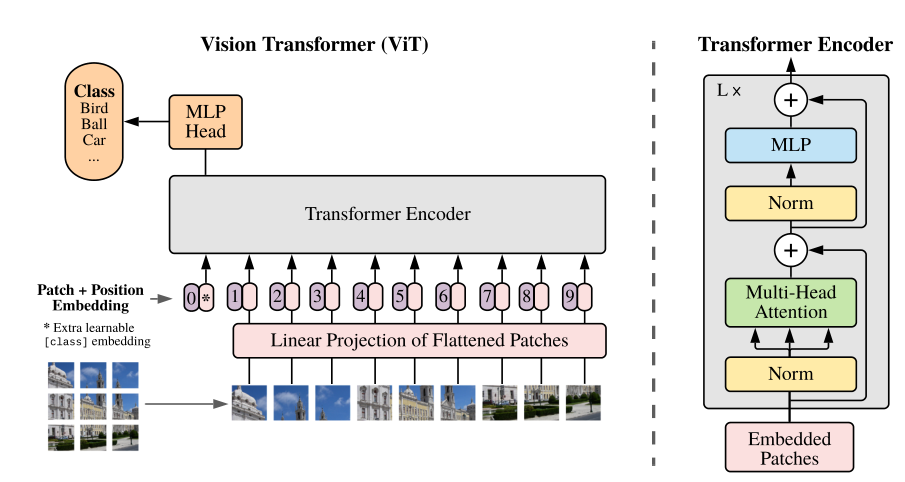
1.数据处理部分:
先对图片作分块,再将每个图片块展平成一维向量
2.数据嵌入部分:
Patch Embedding:对每个向量都做一个线性变换
Positional Encoding:通过一个可学习向量加入序列的位置信息
3.编码部分:
class_token:额外的一个用于分类的可学习向量,与输入进行拼接
4.分类部分:
mlp_head:使用 LayerNorm 和两层全连接层实现的,采用的是GELU激活函数
ViT的动态过程:
整个流程:

- 一个图片256x256,分成了64个32x32的patch;
- 对这么多的patch做embedding,成64个1024向量;
- 再拼接一个cls_tokens,变成65个1024向量;
- 再加上pos_embedding,还是65个1024向量;
- 这些向量输入到transformer中进行自注意力的特征提取;
- 输出的是64个1024向量,然后对这个50个求均值,变成一个1024向量;
- 然后线性层把1024维变成 mlp_head维从而完成分类任务的transformer模型。
ViT的pytorch代码:
import torch
import torch.nn as nn
import math
class MLP(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super(MLP, self).__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, input):
output = self.net(input)
return output
class MSA(nn.Module):
"""
dim就是输入的维度,也就是embeding的宽度
heads是有多少个patch
dim_head是每个patch要多少dim
dropout是nn.Dropout()的参数
"""
def __init__(self, dim, heads=8, dim_head=64, dropout=0.):
super(MSA, self).__init__()
self.dim = dim
self.heads = heads
self.dropout = dropout
# 论文里面的Dh
self.Dh = dim_head ** -0.5
# self-attention里面的Wq,Wk和Wv矩阵
inner_dim = dim_head * heads
self.linear_q = nn.Linear(dim, inner_dim, bias=False)
self.linear_k = nn.Linear(dim, inner_dim, bias=False)
self.linear_v = nn.Linear(dim, inner_dim, bias=False)
self.output = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
)
def forward(self, input):
"""
:param input: 输入是embeding,[batch, N, D]
:return: MSA的计算结果的维度和输入维度是一样的
"""
# 首先计算q k v
# [batch, N, inner_dim]
q = self.linear_q(input)
k = self.linear_k(input)
v = self.linear_v(input)
# 接着计算矩阵A
# [batch, N, N]
A = torch.bmm(q, k.permute(0,2,1)) * self.Dh
A = torch.softmax(A.view(A.shape[0],-1), dim=-1)
A = A.view(A.shape[0], int(math.sqrt(A.shape[1])), int(math.sqrt(A.shape[1])))
# [batch, N, inner_dim]
SA = torch.bmm(A, v)
# [batch, N, D]
out = self.output(SA)
return out
class TransformerEncoder(nn.Module):
def __init__(self, dim, hidden_dim=64):
super(TransformerEncoder, self).__init__()
self.norm = nn.LayerNorm(dim)
self.msa = MSA(dim)
self.mlp = MLP(dim, hidden_dim)
def forward(self, input):
output = self.norm(input)
output = self.msa(output)
output_s1 = output + input
output = self.norm(output_s1)
output = self.mlp(output)
output_s2 = output + output_s1
return output_s2
class VIT(nn.Module):
def __init__(self, dim, hidden_dim=64, num_classes=10, num_layers=10):
super(VIT, self).__init__()
self.layers = nn.ModuleList([])
for _ in range(num_layers):
self.layers.append(TransformerEncoder(dim, hidden_dim))
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, x):
for layer in self.layers:
x = layer(x)
x = x.mean(dim=1)
x = self.mlp_head(x)
return x
if __name__ == "__main__":
vit = VIT(64).cuda()
seq = torch.rand(2,16,64).cuda()
out = vit(seq)
print(out.shape)
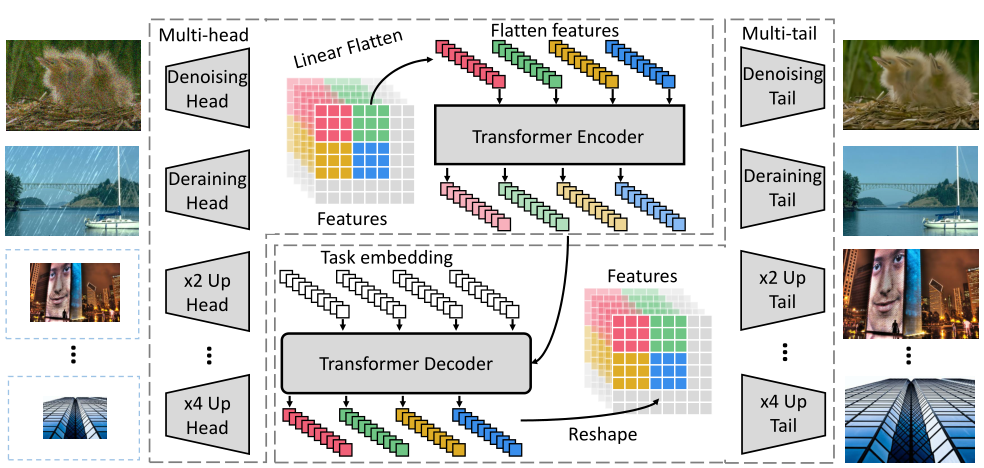
4. IPT
文章原文: https://arxiv.org/pdf/2012.00364.pdf
文章解析: https://zhuanlan.zhihu.com/p/342261872
代码: https://github.com/huawei-noah/Pretrained-IPT
IPT的整体结构分为以下几个部分:
IPT代码

-
common:
# 2021.05.07-Changed for IPT # Huawei Technologies Co., Ltd. <[email protected]> import math import torch import torch.nn as nn import torch.nn.functional as F def default_conv(in_channels, out_channels, kernel_size, bias=True): return nn.Conv2d( in_channels, out_channels, kernel_size, padding=(kernel_size//2), bias=bias) class MeanShift(nn.Conv2d): def __init__( self, rgb_range, rgb_mean=(0.4488, 0.4371, 0.4040), rgb_std=(1.0, 1.0, 1.0), sign=-1): super(MeanShift, self).__init__(3, 3, kernel_size=1) std = torch.Tensor(rgb_std) self.weight.data = torch.eye(3).view(3, 3, 1, 1) / std.view(3, 1, 1, 1) self.bias.data = sign * rgb_range * torch.Tensor(rgb_mean) / std for p in self.parameters(): p.requires_grad = False class BasicBlock(nn.Sequential): def __init__( self, conv, in_channels, out_channels, kernel_size, stride=1, bias=False, bn=True, act=nn.ReLU(True)): m = [conv(in_channels, out_channels, kernel_size, bias=bias)] if bn: m.append(nn.BatchNorm2d(out_channels)) if act is not None: m.append(act) super(BasicBlock, self).__init__(*m) class ResBlock(nn.Module): def __init__( self, conv, n_feats, kernel_size, bias=True, bn=False, act=nn.ReLU(True), res_scale=1): super(ResBlock, self).__init__() m = [] for i in range(2): m.append(conv(n_feats, n_feats, kernel_size, bias=bias)) if bn: m.append(nn.BatchNorm2d(n_feats)) if i == 0: m.append(act) self.body = nn.Sequential(*m) self.res_scale = res_scale def forward(self, x): res = self.body(x).mul(self.res_scale) res += x return res class Upsampler(nn.Sequential): def __init__(self, conv, scale, n_feats, bn=False, act=False, bias=True): m = [] if (scale & (scale - 1)) == 0: # Is scale = 2^n? for _ in range(int(math.log(scale, 2))): m.append(conv(n_feats, 4 * n_feats, 3, bias)) m.append(nn.PixelShuffle(2)) if bn: m.append(nn.BatchNorm2d(n_feats)) if act == 'relu': m.append(nn.ReLU(True)) elif act == 'prelu': m.append(nn.PReLU(n_feats)) elif scale == 3: m.append(conv(n_feats, 9 * n_feats, 3, bias)) m.append(nn.PixelShuffle(3)) if bn: m.append(nn.BatchNorm2d(n_feats)) if act == 'relu': m.append(nn.ReLU(True)) elif act == 'prelu': m.append(nn.PReLU(n_feats)) else: raise NotImplementedError super(Upsampler, self).__init__(*m) -
IPT主结构:
# 2021.05.07-Changed for IPT # Huawei Technologies Co., Ltd. <[email protected]> # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved from model import common import math import torch import torch.nn.functional as F from torch import nn, Tensor from einops import rearrange import copy def make_model(args, parent=False): return ipt(args) class ipt(nn.Module): def __init__(self, args, conv=common.default_conv): super(ipt, self).__init__() self.scale_idx = 0 self.args = args n_feats = args.n_feats kernel_size = 3 act = nn.ReLU(True) self.sub_mean = common.MeanShift(args.rgb_range) self.add_mean = common.MeanShift(args.rgb_range, sign=1) # 从退化图像中提取特征 self.head = nn.ModuleList([ nn.Sequential( conv(args.n_colors, n_feats, kernel_size), common.ResBlock(conv, n_feats, 5, act=act), common.ResBlock(conv, n_feats, 5, act=act) ) for _ in args.scale ]) # 主要结构,用于恢复丢失的数据 self.body = VisionTransformer(img_dim=args.patch_size, patch_dim=args.patch_dim, num_channels=n_feats, embedding_dim=n_feats*args.patch_dim*args.patch_dim, num_heads=args.num_heads, num_layers=args.num_layers, hidden_dim=n_feats*args.patch_dim*args.patch_dim*4, num_queries = args.num_queries, dropout_rate=args.dropout_rate, mlp=args.no_mlp ,pos_every=args.pos_every,no_pos=args.no_pos,no_norm=args.no_norm) # 最后映射特征 self.tail = nn.ModuleList([ nn.Sequential( common.Upsampler(conv, s, n_feats, act=False), conv(n_feats, args.n_colors, kernel_size) ) for s in args.scale ]) def forward(self, x): x = self.sub_mean(x) x = self.head[self.scale_idx](x) res = self.body(x,self.scale_idx) res += x x = self.tail[self.scale_idx](res) x = self.add_mean(x) return x def set_scale(self, scale_idx): self.scale_idx = scale_idx class VisionTransformer(nn.Module): def __init__( self, img_dim, patch_dim, num_channels, embedding_dim, num_heads, num_layers, hidden_dim, num_queries, positional_encoding_type="learned", dropout_rate=0, no_norm=False, mlp=False, pos_every=False, no_pos = False ): super(VisionTransformer, self).__init__() assert embedding_dim % num_heads == 0 assert img_dim % patch_dim == 0 self.no_norm = no_norm self.mlp = mlp self.embedding_dim = embedding_dim self.num_heads = num_heads self.patch_dim = patch_dim self.num_channels = num_channels self.img_dim = img_dim self.pos_every = pos_every self.num_patches = int((img_dim // patch_dim) ** 2) self.seq_length = self.num_patches self.flatten_dim = patch_dim * patch_dim * num_channels self.out_dim = patch_dim * patch_dim * num_channels self.no_pos = no_pos # 多层感知器MLP if self.mlp==False: self.linear_encoding = nn.Linear(self.flatten_dim, embedding_dim) self.mlp_head = nn.Sequential( nn.Linear(embedding_dim, hidden_dim), nn.Dropout(dropout_rate), nn.ReLU(), nn.Linear(hidden_dim, self.out_dim), nn.Dropout(dropout_rate) ) self.query_embed = nn.Embedding(num_queries, embedding_dim * self.seq_length) encoder_layer = TransformerEncoderLayer(embedding_dim, num_heads, hidden_dim, dropout_rate, self.no_norm) self.encoder = TransformerEncoder(encoder_layer, num_layers) decoder_layer = TransformerDecoderLayer(embedding_dim, num_heads, hidden_dim, dropout_rate, self.no_norm) self.decoder = TransformerDecoder(decoder_layer, num_layers) if not self.no_pos: self.position_encoding = LearnedPositionalEncoding( self.seq_length, self.embedding_dim, self.seq_length ) self.dropout_layer1 = nn.Dropout(dropout_rate) if no_norm: for m in self.modules(): if isinstance(m, nn.Linear): nn.init.normal_(m.weight, std = 1/m.weight.size(1)) def forward(self, x, query_idx, con=False): x = torch.nn.functional.unfold(x,self.patch_dim,stride=self.patch_dim).transpose(1,2).transpose(0,1).contiguous() if self.mlp==False: x = self.dropout_layer1(self.linear_encoding(x)) + x query_embed = self.query_embed.weight[query_idx].view(-1,1,self.embedding_dim).repeat(1,x.size(1), 1) else: query_embed = None if not self.no_pos: pos = self.position_encoding(x).transpose(0,1) if self.pos_every: x = self.encoder(x, pos=pos) x = self.decoder(x, x, pos=pos, query_pos=query_embed) elif self.no_pos: x = self.encoder(x) x = self.decoder(x, x, query_pos=query_embed) else: x = self.encoder(x+pos) x = self.decoder(x, x, query_pos=query_embed) if self.mlp==False: x = self.mlp_head(x) + x x = x.transpose(0,1).contiguous().view(x.size(1), -1, self.flatten_dim) if con: con_x = x x = torch.nn.functional.fold(x.transpose(1,2).contiguous(),int(self.img_dim),self.patch_dim,stride=self.patch_dim) return x, con_x x = torch.nn.functional.fold(x.transpose(1,2).contiguous(),int(self.img_dim),self.patch_dim,stride=self.patch_dim) return x class LearnedPositionalEncoding(nn.Module): def __init__(self, max_position_embeddings, embedding_dim, seq_length): super(LearnedPositionalEncoding, self).__init__() self.pe = nn.Embedding(max_position_embeddings, embedding_dim) self.seq_length = seq_length self.register_buffer( "position_ids", torch.arange(self.seq_length).expand((1, -1)) ) def forward(self, x, position_ids=None): if position_ids is None: position_ids = self.position_ids[:, : self.seq_length] position_embeddings = self.pe(position_ids) return position_embeddings class TransformerEncoder(nn.Module): def __init__(self, encoder_layer, num_layers): super().__init__() self.layers = _get_clones(encoder_layer, num_layers) self.num_layers = num_layers def forward(self, src, pos = None): output = src for layer in self.layers: output = layer(output, pos=pos) return output class TransformerEncoderLayer(nn.Module): def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, no_norm = False, activation="relu"): super().__init__() self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, bias=False) # Implementation of Feedforward model self.linear1 = nn.Linear(d_model, dim_feedforward) self.dropout = nn.Dropout(dropout) self.linear2 = nn.Linear(dim_feedforward, d_model) self.norm1 = nn.LayerNorm(d_model) if not no_norm else nn.Identity() self.norm2 = nn.LayerNorm(d_model) if not no_norm else nn.Identity() self.dropout1 = nn.Dropout(dropout) self.dropout2 = nn.Dropout(dropout) self.activation = _get_activation_fn(activation) nn.init.kaiming_uniform_(self.self_attn.in_proj_weight, a=math.sqrt(5)) def with_pos_embed(self, tensor, pos): return tensor if pos is None else tensor + pos def forward(self, src, pos = None): src2 = self.norm1(src) q = k = self.with_pos_embed(src2, pos) src2 = self.self_attn(q, k, src2) src = src + self.dropout1(src2[0]) src2 = self.norm2(src) src2 = self.linear2(self.dropout(self.activation(self.linear1(src2)))) src = src + self.dropout2(src2) return src class TransformerDecoder(nn.Module): def __init__(self, decoder_layer, num_layers): super().__init__() self.layers = _get_clones(decoder_layer, num_layers) self.num_layers = num_layers def forward(self, tgt, memory, pos = None, query_pos = None): output = tgt for layer in self.layers: output = layer(output, memory, pos=pos, query_pos=query_pos) return output class TransformerDecoderLayer(nn.Module): def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, no_norm = False, activation="relu"): super().__init__() self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, bias=False) self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, bias=False) # Implementation of Feedforward model self.linear1 = nn.Linear(d_model, dim_feedforward) self.dropout = nn.Dropout(dropout) self.linear2 = nn.Linear(dim_feedforward, d_model) self.norm1 = nn.LayerNorm(d_model) if not no_norm else nn.Identity() self.norm2 = nn.LayerNorm(d_model) if not no_norm else nn.Identity() self.norm3 = nn.LayerNorm(d_model) if not no_norm else nn.Identity() self.dropout1 = nn.Dropout(dropout) self.dropout2 = nn.Dropout(dropout) self.dropout3 = nn.Dropout(dropout) self.activation = _get_activation_fn(activation) def with_pos_embed(self, tensor, pos): return tensor if pos is None else tensor + pos def forward(self, tgt, memory, pos = None, query_pos = None): tgt2 = self.norm1(tgt) q = k = self.with_pos_embed(tgt2, query_pos) tgt2 = self.self_attn(q, k, value=tgt2)[0] tgt = tgt + self.dropout1(tgt2) tgt2 = self.norm2(tgt) tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos), key=self.with_pos_embed(memory, pos), value=memory)[0] tgt = tgt + self.dropout2(tgt2) tgt2 = self.norm3(tgt) tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2)))) tgt = tgt + self.dropout3(tgt2) return tgt def _get_clones(module, N): return nn.ModuleList([copy.deepcopy(module) for i in range(N)]) def _get_activation_fn(activation): """Return an activation function given a string""" if activation == "relu": return F.relu if activation == "gelu": return F.gelu if activation == "glu": return F.glu raise RuntimeError(F"activation should be relu/gelu, not {activation}.") if __name__ == "__main__": from option import args """ #transformer parser.add_argument('--patch_dim', type=int, default=3) parser.add_argument('--num_heads', type=int, default=12) parser.add_argument('--num_layers', type=int, default=12) parser.add_argument('--dropout_rate', type=float, default=0) parser.add_argument('--no_norm', action='store_true') parser.add_argument('--freeze_norm', action='store_true') parser.add_argument('--post_norm', action='store_true') parser.add_argument('--no_mlp', action='store_true') parser.add_argument('--pos_every', action='store_true') parser.add_argument('--no_pos', action='store_true') parser.add_argument('--num_queries', type=int, default=1) """ model = ipt(args) print(model)model运行结果:
ipt( (sub_mean): MeanShift(3, 3, kernel_size=(1, 1), stride=(1, 1)) (add_mean): MeanShift(3, 3, kernel_size=(1, 1), stride=(1, 1)) (head): ModuleList( (0): Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ResBlock( (body): Sequential( (0): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (1): ReLU(inplace=True) (2): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) ) ) (2): ResBlock( (body): Sequential( (0): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (1): ReLU(inplace=True) (2): Conv2d(64, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) ) ) ) ) (body): VisionTransformer( (linear_encoding): Linear(in_features=576, out_features=576, bias=True) (mlp_head): Sequential( (0): Linear(in_features=576, out_features=2304, bias=True) (1): Dropout(p=0, inplace=False) (2): ReLU() (3): Linear(in_features=2304, out_features=576, bias=True) (4): Dropout(p=0, inplace=False) ) (query_embed): Embedding(1, 147456) (encoder): TransformerEncoder( (layers): ModuleList( (0): TransformerEncoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) ) (1): TransformerEncoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) ) (2): TransformerEncoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) ) (3): TransformerEncoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) ) (4): TransformerEncoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) ) (5): TransformerEncoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) ) (6): TransformerEncoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) ) (7): TransformerEncoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) ) (8): TransformerEncoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) ) (9): TransformerEncoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) ) (10): TransformerEncoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) ) (11): TransformerEncoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) ) ) ) (decoder): TransformerDecoder( (layers): ModuleList( (0): TransformerDecoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (multihead_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm3): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) (dropout3): Dropout(p=0, inplace=False) ) (1): TransformerDecoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (multihead_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm3): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) (dropout3): Dropout(p=0, inplace=False) ) (2): TransformerDecoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (multihead_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm3): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) (dropout3): Dropout(p=0, inplace=False) ) (3): TransformerDecoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (multihead_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm3): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) (dropout3): Dropout(p=0, inplace=False) ) (4): TransformerDecoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (multihead_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm3): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) (dropout3): Dropout(p=0, inplace=False) ) (5): TransformerDecoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (multihead_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm3): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) (dropout3): Dropout(p=0, inplace=False) ) (6): TransformerDecoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (multihead_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm3): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) (dropout3): Dropout(p=0, inplace=False) ) (7): TransformerDecoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (multihead_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm3): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) (dropout3): Dropout(p=0, inplace=False) ) (8): TransformerDecoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (multihead_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm3): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) (dropout3): Dropout(p=0, inplace=False) ) (9): TransformerDecoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (multihead_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm3): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) (dropout3): Dropout(p=0, inplace=False) ) (10): TransformerDecoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (multihead_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm3): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) (dropout3): Dropout(p=0, inplace=False) ) (11): TransformerDecoderLayer( (self_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (multihead_attn): MultiheadAttention( (out_proj): Linear(in_features=576, out_features=576, bias=False) ) (linear1): Linear(in_features=576, out_features=2304, bias=True) (dropout): Dropout(p=0, inplace=False) (linear2): Linear(in_features=2304, out_features=576, bias=True) (norm1): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm2): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (norm3): LayerNorm((576,), eps=1e-05, elementwise_affine=True) (dropout1): Dropout(p=0, inplace=False) (dropout2): Dropout(p=0, inplace=False) (dropout3): Dropout(p=0, inplace=False) ) ) ) (position_encoding): LearnedPositionalEncoding( (pe): Embedding(256, 576) ) (dropout_layer1): Dropout(p=0, inplace=False) ) (tail): ModuleList( (0): Sequential( (0): Upsampler( (0): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): PixelShuffle(upscale_factor=2) (2): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (3): PixelShuffle(upscale_factor=2) ) (1): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) ) ) ) Process finished with exit code 0