文章目录
前言
本文为大家总结了监督学习和无监督学习中常用算法原理简单介绍,包括了代码的详细详解,是机器学习的入门学习,同时也是AI算法面试的重点问题。
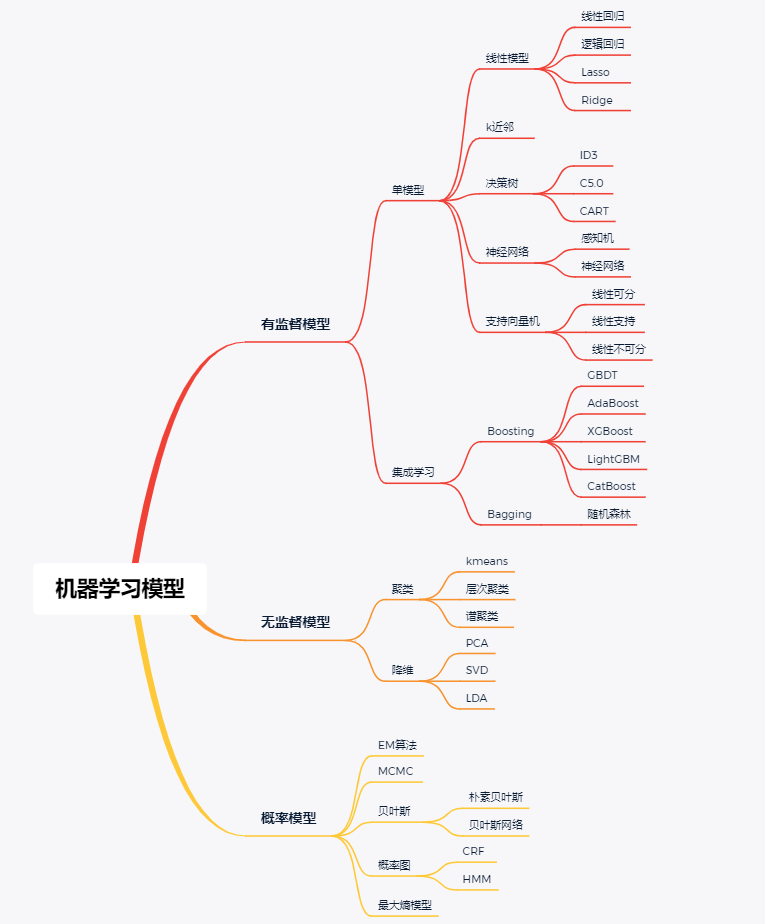
一、监督学习和无监督学习
1. 监督学习
定义:提供输入数据和其对应的标签数据,然后搭建一个模型,模型经过训练后准确的找到输入数据和标签数据之间的最优映射关系,从而对新的未标记数据进行预测或分类。
定义看懵逼了吧?接下来说人话!!!
假如有一群草泥马和牛马组成的马群,这时候需要一个机器对马群进行分类,但是这个机器不知道草泥马和牛马长什么样儿,所以我们首先拿一堆草泥马和牛马的照片给机器看,告诉机器草泥马和牛马长什么样儿。机器经过反复的看,形成肌肉记忆,可以对草泥妈和牛马形成自己的定义,然后机器就可以准确的对马群进行分类。
在这个过程中,草泥马和牛马的照片就叫做标签,反复的看理解为训练,形成的肌肉记忆叫做模型,这就是监督学习的过程。
2. 无监督学习
定义:训练数据只包含输入样本,没有相应的标签或目标。
包装一下:我们没有拿草泥马和牛马的照片对机器进行系统的训练,机器也不知道这两个马儿长什么样,而是直接让机器对这两个马儿进行分类。这就是无监督学习。
3. 两者主要区别以及优缺点
如图所示,左图是无监督学习的过程,虽然数据被分成了两类,但是没有对应的数据标签,统一用蓝色的圆点表示,这更像是把具有相同的特征的数据聚集在一起,所以无监督学习实现分类的算法又叫做聚类。右图是监督学习中二分类的过程,标签在图中体现为三角和圆。
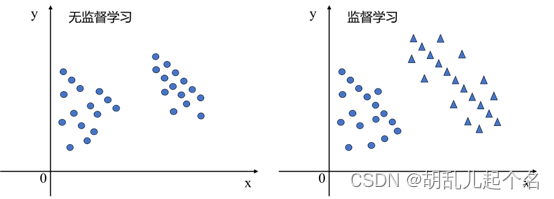
无监督学习的关键优势是它可以在没有人工标签的情况下自动从大量未标记的数据中获取知识。这使得无监督学习在数据探索、数据预处理和模式发现方面具有广泛的应用。它也可以用作监督学习的预处理步骤,以减少标记数据的需求或改善模型的性能。缺点是无监督学习的性能很大程度上依赖于输入数据的质量和特征。如果数据存在噪声、缺失值或异常值,这些因素可能会对模型的性能产生负面影响。
监督学习的优势是使用标记的训练数据来指导模型的学习过程,因此可以获得相对准确的预测结果。通过与真实标签进行比较,模型可以进行纠正和优化,提高预测的准确性。缺点是监督学习模型在训练阶段是通过学习训练数据的模式和规律来进行预测。如果模型在训练数据上过度拟合,可能在新的未见过的数据上表现不佳,泛化能力受到限制。
4. 半监督学习
为了综合两者的优点,半监督学习诞生了。半监督学习是介于监督学习和无监督学习之间的一种机器学习方法。在半监督学习中,模型使用同时包含标记和未标记样本的训练数据进行学习。
半监督学习的优势在于:
- 利用未标记数据:未标记数据通常更容易获取,半监督学习可以充分利用这些数据来提高模型的性能和泛化能力,尤其在标记数据有限或获取成本高的情况下。
- 提高泛化能力:通过利用更多的数据进行学习,半监督学习可以帮助模型更好地捕捉数据的潜在结构,提高模型在新数据上的泛化能力。
- 减少标记成本:相比于完全依赖标记数据进行训练,半监督学习可以使用较少的标记数据来达到类似的性能,从而降低了标记数据的需求和成本。
二、常用机器学习算法介绍
1.监督学习
1.1 线性回归算法
线性回归是一种用于建立自变量(输入)和因变量(输出)之间线性关系的模型,其重点如下:
- 通过提供数据训练模型,让模型得到自变量和因变量对应的映射关系。
- 映射关系是连续且线性的
下面通过图来更加直观的看线性回归问题:
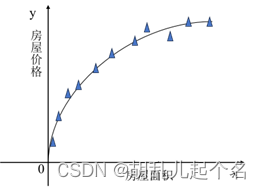
Y—房屋价格; 弧线—线性映射模型;
如果我们想要房屋面积对应的价格的话,通过这个线性回归模型,就可以很快的进行预测,这就是线性回归的整个过程。代码如下(示例):
import numpy as np
from sklearn.linear_model import LinearRegression
# 输入数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 创建线性回归模型
model = LinearRegression()
# 拟合模型
model.fit(X, y)
# 预测
X_test = np.array([[6], [7]])
y_pred = model.predict(X_test)
# 输出预测结果
print(y_pred)
1.2 逻辑回归算法
逻辑回归实际上是一种分类算法,它的输出是一个概率值,表示样本属于某个类别的概率。逻辑回归模型的数学表示如下:
逻辑回归实际上是一种分类算法,它的输出是一个概率值,表示样本属于某个类别的概率。逻辑回归模型的数学表示如下:
- 假设函数(Hypothesis):
hθ(x)> = g(θ^T * x)
其中,hθ(x) 表示预测函数,g(z) 表示逻辑函数(Sigmoid函数),θ 是模型参数,x 是输入特征向量。
- 逻辑函数(Sigmoid函数):
g(z)> = 1 / (1 + e^(-z))
其中,e 表示自然指数,z 是线性回归模型的输出。
- 损失函数(Cost Function):
J(θ)= -1/m * ∑[y * log(hθ(x)) + (1 - y) * log(1 - hθ(x))]
其中,m 表示样本数量,y 表示实际标签
在实际应用中,逻辑回归可以用于各种二分类问题,例如垃圾邮件分类、疾病诊断、广告点击预测等。它的优点包括模型简单、计算效率高、可解释性好等特点。然而,逻辑回归也有一些限制,例如对于非线性问题的建模能力较弱。在处理多分类问题时,可以使用一对多(One-vs-Rest)或多项式逻辑回归进行扩展。代码如下(示例):
import numpy as np
from sklearn.linear_model import LogisticRegression
# 输入数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([0, 0, 1, 1, 1])
# 创建逻辑回归模型
model = LogisticRegression()
# 拟合模型
model.fit(X, y)
# 预测
X_test = np.array([[6], [7]])
y_pred = model.predict(X_test)
# 输出预测结果
print(y_pred)
1.3 决策树算法
决策树算法用于解决分类和回归问题。它通过构建一棵树形结构来进行决策,每个内部节点表示一个特征或属性(色泽和触感),每个叶节点表示一个类别或一个数值(好瓜、坏瓜)。
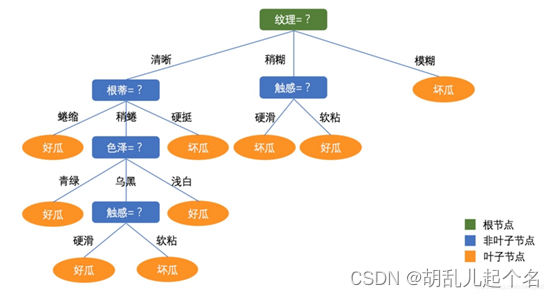
- 特征选择:根据某个准则选择最佳的特征作为当前节点的划分依据。常用的特征选择准则包括信息增益、信息增益比、基尼指数等。
- 决策树生成:根据特征选择的结果,递归地生成决策树的内部节点和叶节点。每个内部节点表示一个特征,根据该特征的取值将样本划分到不同的子节点中。
- 决策树剪枝:为了防止过拟合,可以进行决策树的剪枝操作。剪枝过程可以通过预剪枝或后剪枝来实现。预剪枝是在决策树生成过程中进行判断,如果划分不再显著提高性能,则停止划分。后剪枝是在决策树生成之后,通过剪枝操作来减小决策树的复杂度。
常见的决策树算法有ID3、C5.0和CART,CART的分类效果一般要优于其他决策树。
ID3的核心思想是基于信息增益来选择最优的特征进行节点的划分。
import numpy as np
def entropy(y):
classes, counts = np.unique(y, return_counts=True)
probabilities = counts / len(y)
entropy = -np.sum(probabilities * np.log2(probabilities))
return entropy
def information_gain(X, y, feature_index):
total_entropy = entropy(y)
feature_values = np.unique(X[:, feature_index])
weighted_entropy = 0
for value in feature_values:
subset_indices = np.where(X[:, feature_index] == value)
subset_y = y[subset_indices]
subset_entropy = entropy(subset_y)
subset_weight = len(subset_y) / len(y)
weighted_entropy += subset_weight * subset_entropy
information_gain = total_entropy - weighted_entropy
return information_gain
def id3(X, y, features):
if len(np.unique(y)) == 1:
# 所有样本属于同一类别,返回叶节点
return y[0]
if len(features) == 0:
# 没有可用的特征,返回多数类别
classes, counts = np.unique(y, return_counts=True)
majority_class = classes[np.argmax(counts)]
return majority_class
# 选择最佳特征
gains = [information_gain(X, y, feature_index) for feature_index in range(X.shape[1])]
best_feature_index = np.argmax(gains)
best_feature = features[best_feature_index]
# 创建决策树节点
tree = {best_feature: {}}
remaining_features = np.delete(features, best_feature_index)
# 递归构建子树
feature_values = np.unique(X[:, best_feature_index])
for value in feature_values:
value_indices = np.where(X[:, best_feature_index] == value)
subset_X = X[value_indices]
subset_y = y[value_indices]
subtree = id3(subset_X, subset_y, remaining_features)
tree[best_feature][value] = subtree
return tree
# 示例数据
X = np.array([
[1, 'S'],
[1, 'M'],
[1, 'M'],
[1, 'S'],
[1, 'S'],
[2, 'S'],
[2, 'M'],
[2, 'M'],
[2, 'L'],
[2, 'L'],
[3, 'L'],
[3, 'M'],
[3, 'M'],
[3, 'L'],
[3, 'L']
])
y = np.array([0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0])
features = np.array([0, 1]) # 特征索引
# 构建决策树
decision_tree = id3(X, y, features)
# 打印决策树
print(decision_tree)
C5.0是ID3算法的改进版本,基于信息增益比来选择最优的特征进行节点的划分,并通过剪枝操作来减小决策树的复杂度。
from C50 import C50Classifier
import pandas as pd
# 读取数据集
data = pd.read_csv('data.csv')
# 划分特征和目标变量
X = data.drop('target', axis=1)
y = data['target']
# 创建C5.0分类器对象
classifier = C50Classifier()
# 拟合模型
classifier.fit(X, y)
# 预测
X_test = pd.DataFrame([[1, 2, 3, 4]]) # 新的测试样本
y_pred = classifier.predict(X_test)
# 输出预测结果
print(y_pred)
CART算法采用二叉划分方式构建决策树,使用基尼指数(Gini Index)作为特征选择的准则,递归分裂的策略来构建决策树。
import numpy as np
class Node:
def __init__(self, feature_index=None, threshold=None, value=None, left=None, right=None):
self.feature_index = feature_index # 分割特征的索引
self.threshold = threshold # 分割阈值
self.value = value # 叶节点的预测值
self.left = left # 左子树
self.right = right # 右子树
class CARTClassifier:
def __init__(self, max_depth=None, min_samples_split=2):
self.max_depth = max_depth # 最大深度
self.min_samples_split = min_samples_split # 最小样本数
def _gini_index(self, y):
classes, counts = np.unique(y, return_counts=True)
probabilities = counts / len(y)
gini_index = 1 - np.sum(probabilities ** 2)
return gini_index
def _split_dataset(self, X, y, feature_index, threshold):
left_indices = np.where(X[:, feature_index] <= threshold)
right_indices = np.where(X[:, feature_index] > threshold)
left_X, left_y = X[left_indices], y[left_indices]
right_X, right_y = X[right_indices], y[right_indices]
return left_X, left_y, right_X, right_y
def _find_best_split(self, X, y):
best_gini = np.inf
best_feature_index = None
best_threshold = None
for feature_index in range(X.shape[1]):
feature_values = np.unique(X[:, feature_index])
for threshold in feature_values:
left_X, left_y, right_X, right_y = self._split_dataset(X, y, feature_index, threshold)
gini = self._gini_index(left_y) * len(left_y) / len(y) + self._gini_index(right_y) * len(right_y) / len(y)
if gini < best_gini:
best_gini = gini
best_feature_index = feature_index
best_threshold = threshold
return best_feature_index, best_threshold
def _build_tree(self, X, y, depth):
if len(np.unique(y)) == 1:
# 所有样本属于同一类别,返回叶节点
return Node(value=y[0])
if self.max_depth is not None and depth >= self.max_depth:
# 达到最大深度,返回叶节点,预测多数类别
classes, counts = np.unique(y, return_counts=True)
majority_class = classes[np.argmax(counts)]
return Node(value=majority_class)
if len(y) < self.min_samples_split:
# 样本数小于最小拆分样本数,返回叶节点,预测多数类别
classes, counts = np.unique(y, return_counts=True)
majority_class = classes[np.argmax(counts)]
return Node(value=majority_class)
best_feature_index, best_threshold = self._find_best_split(X, y)
if best_feature_index is None or best_threshold is None:
# 无法找到最佳拆分,返回叶节点,预测多数类别
classes, counts = np.unique(y, return_counts=True)
majority_class = classes[np.argmax(counts)]
return Node(value=majority_class)
left_X, left_y, right_X, right_y = self._split_dataset(X, y, best_feature_index, best_threshold)
left_child = self._build_tree(left_X, left_y, depth + 1)
right_child = self._build_tree(right_X, right_y, depth + 1)
return Node(feature_index=best_feature_index, threshold=best_threshold, left=left_child, right=right_child)
def fit(self, X, y):
self.root = self._build_tree(X, y, depth=0)
def _predict_sample(self, x, node):
if node.value is not None:
return node.value
if x[node.feature_index] <= node.threshold:
return self._predict_sample(x, node.left)
else:
return self._predict_sample(x, node.right)
def predict(self, X):
predictions = []
for x in X:
prediction = self._predict_sample(x, self.root)
predictions.append(prediction)
return np.array(predictions)
1.4 朴素贝叶斯
朴素贝叶斯算法是基于贝叶斯定理和特征条件独立假设的分类算法。它假设特征之间是相互独立的,然后根据已知的特征和类别的条件概率,计算待分类样本属于每个类别的概率,并选择概率最大的类别作为预测结果。举例说明,图片来自(黑马程序员python)
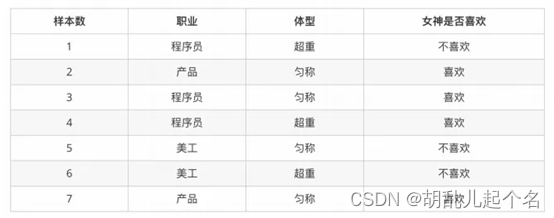
• 1. 女神喜欢的概率?1. 女神喜欢的概率?
• 2. 职业是程序员并且体型匀称的概率?
• 3. 在女神喜欢的条件下,职业是程序员的概率?
• 4. 在女神喜欢的条件下,职业是程序员、体重超重的概率?
计算结果为:
P(喜欢) = 4/7
P(程序员, 匀称) = 1/7(联合概率)
P(程序员|喜欢) = 2/4 = 1/2(条件概率)
P(程序员, 超重|喜欢) = 1/4
示例代码:
import numpy as np
class NaiveBayesClassifier:
def fit(self, X, y):
self.classes = np.unique(y)
self.class_prior_probabilities = self._calculate_class_prior_probabilities(y)
self.feature_probabilities = self._calculate_feature_probabilities(X, y)
def _calculate_class_prior_probabilities(self, y):
class_prior_probabilities = {}
total_samples = len(y)
for class_label in self.classes:
class_samples = np.sum(y == class_label)
class_prior_probabilities[class_label] = class_samples / total_samples
return class_prior_probabilities
def _calculate_feature_probabilities(self, X, y):
feature_probabilities = {}
for class_label in self.classes:
class_indices = np.where(y == class_label)
class_X = X[class_indices]
class_feature_probabilities = {}
for feature_index in range(X.shape[1]):
feature_values = np.unique(X[:, feature_index])
feature_value_probabilities = {}
for feature_value in feature_values:
feature_value_count = np.sum(class_X[:, feature_index] == feature_value)
feature_value_probability = (feature_value_count + 1) / (len(class_X) + len(feature_values))
feature_value_probabilities[feature_value] = feature_value_probability
class_feature_probabilities[feature_index] = feature_value_probabilities
feature_probabilities[class_label] = class_feature_probabilities
return feature_probabilities
def _calculate_class_posterior_probability(self, x, class_label):
class_prior_probability = self.class_prior_probabilities[class_label]
class_feature_probabilities = self.feature_probabilities[class_label]
posterior_probability = class_prior_probability
for feature_index, feature_value in enumerate(x):
if feature_value in class_feature_probabilities[feature_index]:
feature_value_probability = class_feature_probabilities[feature_index][feature_value]
posterior_probability *= feature_value_probability
return posterior_probability
def predict(self, X):
predictions = []
for x in X:
class_scores = []
for class_label in self.classes:
class_score = self._calculate_class_posterior_probability(x, class_label)
class_scores.append(class_score)
predicted_class = self.classes[np.argmax(class_scores)]
predictions.append(predicted_class)
return np.array(predictions)
1.5 K近邻算法
K近邻算法就是如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
import numpy as np
from collections import Counter
class KNNClassifier:
def __init__(self, k):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
def _calculate_distance(self, x1, x2):
# 计算欧氏距离
return np.sqrt(np.sum((x1 - x2) ** 2))
def predict(self, X):
predictions = []
for x in X:
distances = []
for i, x_train in enumerate(self.X_train):
distance = self._calculate_distance(x, x_train)
distances.append((distance, self.y_train[i]))
# 根据距离排序
distances.sort(key=lambda x: x[0])
# 取前k个最近邻
k_nearest_neighbors = distances[:self.k]
# 获取最近邻的标签
k_nearest_labels = [neighbor[1] for neighbor in k_nearest_neighbors]
# 计算最常见的标签
most_common = Counter(k_nearest_labels).most_common(1)
# 预测标签
predicted_label = most_common[0][0]
predictions.append(predicted_label)
return np.array(predictions)
1.6 SVM算法(持续更新)
2.无监督学习
2.1 PCA主成分分析
主成分分析(Principal Component Analysis,PCA)是一种常用的数据降维技术,用于减少高维数据的维数并提取最重要的特征。它通过线性变换将原始数据投影到一个新的子空间上,使得投影后的数据具有最大的方差。
下面是PCA算法的基本步骤:
- 数据预处理:对原始数据进行标准化处理,使得每个特征的均值为0,方差为1。这是为了消除不同特征之间的量纲差异。
- 计算协方差矩阵:根据标准化后的数据计算协方差矩阵。协方差矩阵描述了不同特征之间的相关性。
- 特征值分解:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。特征值表示了数据在特征向量方向上的方差。
- 选择主成分:按照特征值的大小排序特征向量,选择前k个特征向量作为主成分,其中k是降低维度后的目标维数。
- 数据投影:将原始数据投影到选定的主成分上,得到降维后的数据。
PCA的优点包括:
- 数据降维:通过PCA可以将高维数据降低到较低的维度,减少数据存储和计算的复杂性。
- 特征提取:PCA能够提取数据中的主要特征,有助于理解数据的结构和关系。
- 去除冗余和噪声:PCA可以消除数据中的冗余信息和噪声,提高后续分析的准确性。
PCA的缺点:
- 线性关系:PCA基于线性变换,适用于线性相关的数据。对于非线性关系,PCA可能无法正确捕捉数据的结构。
- 方差解释比例:选择主成分时,需要考虑保留的方差解释比例。较低的方差解释比例可能会导致丢失重要信息。
- 敏感性:PCA对数据的缩放和单位选择敏感。在应用PCA之前,应该对数据进行适当的预处理。
import numpy as np
class PCA:
def __init__(self, n_components):
self.n_components = n_components
self.components = None
self.mean = None
def fit(self, X):
# 计算均值
self.mean = np.mean(X, axis=0)
# 中心化数据
X = X - self.mean
# 计算协方差矩阵
cov_matrix = np.cov(X.T)
# 计算特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix)
eigenvectors = eigenvectors.T
# 对特征值进行排序
sorted_indices = np.argsort(eigenvalues)[::-1]
top_indices = sorted_indices[:self.n_components]
# 选择前n个特征向量作为主成分
self.components = eigenvectors[top_indices]
def transform(self, X):
# 中心化数据
X = X - self.mean
# 投影到主成分空间
return np.dot(X, self.components.T)
def fit_transform(self, X):
# 训练模型并进行转换
self.fit(X)
return self.transform(X)
2.2 K-Means算法
K-Means是一种常用的聚类算法,用于将数据集划分为K个不重叠的簇(cluster)。每个簇代表一个数据的集合,其中相似的数据被分配到同一个簇中,K-Means算法的基本思想是通过迭代优化的方式来找到最优的簇划分。
K-Means算法的基本步骤:
选择K个初始聚类中心:从数据集中随机选择K个样本作为初始聚类中心。
分配数据样本到最近的聚类中心:对于每个数据样本,计算它与每个聚类中心的距离,并将其分配到距离最近的聚类中心所属的簇。
更新聚类中心:对于每个簇,计算簇内所有样本的均值,将均值作为新的聚类中心。
重复步骤2和步骤3,直到达到停止条件。停止条件可以是达到最大迭代次数,或者聚类中心不再发生变化。
得到最终的簇划分:当停止条件满足时,算法收敛并得到最终的簇划分结果。
K-Means算法的优点包括:
- 简单而高效:K-Means算法简单易懂,计算效率高,适用于大规模数据集。
- 可解释性:K-Means产生的簇划分结果具有直观的可视化效果,易于解释和理解。
- 可扩展性:K-Means算法可以扩展到高维数据集,并且对于大型数据集也有良好的可扩展性。
然而,K-Means算法也有一些限制和注意事项:
- 初始聚类中心的选择:初始聚类中心的选择可能会影响最终的簇划分结果。不同的初始选择可能导致不同的局部最优解。
- 对离群点敏感:K-Means对离群点(outlier)敏感,离群点可能会影响簇划分的结果。
- 需要事先确定K的值:K-Means算法需要事先确定簇的数量K,但在实际应用中,K的选择可能并不明确。
import numpy as np
class KMeans:
def __init__(self, n_clusters, max_iter=100):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.centroids = None
def fit(self, X):
# 随机初始化聚类中心
random_indices = np.random.choice(len(X), size=self.n_clusters, replace=False)
self.centroids = X[random_indices]
for _ in range(self.max_iter):
# 分配样本到最近的聚类中心
labels = self._assign_clusters(X)
# 更新聚类中心
new_centroids = self._update_centroids(X, labels)
# 检查是否收敛,即聚类中心是否发生变化
if np.allclose(self.centroids, new_centroids):
break
self.centroids = new_centroids
def _assign_clusters(self, X):
labels = []
for x in X:
# 计算样本到每个聚类中心的距离
distances = [np.linalg.norm(x - centroid) for centroid in self.centroids]
# 分配样本到最近的聚类中心
label = np.argmin(distances)
labels.append(label)
return np.array(labels)
def _update_centroids(self, X, labels):
new_centroids = []
for i in range(self.n_clusters):
# 找到属于聚类i的样本
cluster_samples = X[labels == i]
# 计算新的聚类中心
centroid = np.mean(cluster_samples, axis=0)
new_centroids.append(centroid)
return np.array(new_centroids)
def predict(self, X):
# 分配样本到最近的聚类中心
labels = self._assign_clusters(X)
return labels