目录
1. ViT 模型
视觉变换器(ViT)是一种神经网络架构,它将变换器架构的原理应用于视觉数据。最初,Transformers主要用于自然语言处理任务,但ViT将其应用扩展到计算机视觉任务。
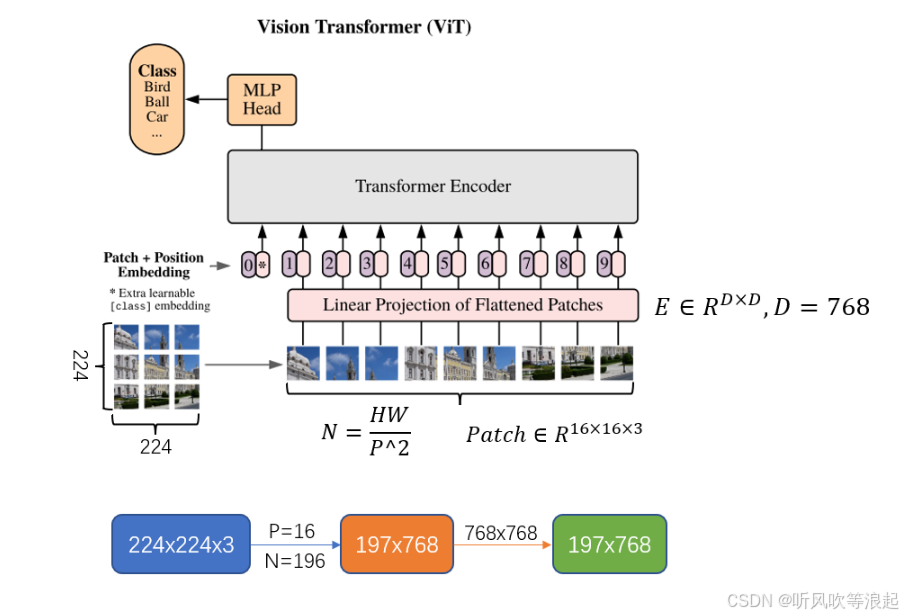
ViT的关键见解是将图像表示为补丁序列,补丁是固定大小的小图像区域。这些补丁被展平为1D向量,并作为输入传递给Transformer编码器。Transformer编码器通过关注所有补丁并学习它们之间的关系来处理补丁序列。
ViT还引入了类似于其他基于Transformer的架构的可学习位置嵌入。位置嵌入捕获了斑块的空间信息,并帮助模型理解斑块在图像中的相对位置。
为了处理高分辨率图像中的大量补丁,ViT应用了一种补丁合并技术,将补丁分组在一起并降低其维度。
为了训练ViT,通常会在Transformer编码器中添加一个辅助分类头。该头预测图像的类标签,整个模型使用标准的监督学习技术进行训练。
ViT在各种图像分类基准测试中表现出了令人印象深刻的性能,与参数较少的卷积神经网络(CNN)相比,通常可以获得相当甚至更好的结果。然而,它可能需要更多的计算资源和大量的训练数据,才能在更大、更复杂的数据集上达到与CNN类似的性能水平。
总体而言,视觉变换器为将变换器架构应用于计算机视觉任务开辟了新的可能性,展示了自我关注机制在建模视觉数据方面的潜力。
ViT 模型有:

2. 早期秧苗分类
ViT 实现的model部分代码如下面所示,这里如果采用官方预训练权重的话,会自动导入官方提供的最新版本的权重
这里提供了5种网络结构,分别对应base、large不同的patch

2.1 数据集
数据集文件如下:

标签如下:
{
"0": "corn",
"1": "rice",
"2": "wheat"
}其中,训练集的总数为633,验证集的总数为269

2.2 训练
训练的参数如下:
parser.add_argument("--model", default='vit_b_16', type=str,help='vit_b_16,vit_b_32,vit_h_14,vit_l_16,vit_l_32')
parser.add_argument("--pretrained", default=True, type=bool) # 采用官方权重
parser.add_argument("--freeze_layers", default=True, type=bool) # 冻结权重
parser.add_argument("--batch-size", default=8, type=int)
parser.add_argument("--epochs", default=10, type=int)
parser.add_argument("--optim", default='SGD', type=str,help='SGD,Adam,AdamW') # 优化器选择
parser.add_argument('--lr', default=0.01, type=float)
parser.add_argument('--lrf',default=0.001,type=float) # 最终学习率 = lr * lrf
parser.add_argument('--save_ret', default='runs', type=str) # 保存结果
parser.add_argument('--data_train',default='./data/train',type=str) # 训练集路径
parser.add_argument('--data_val',default='./data/val',type=str) # 测试集路径网络分类的个数不需要指定,摆放好数据集后,代码会根据数据集自动生成!
网络模型信息如下:
"train parameters": {
"model": "vit_b_16",
"pretrained": true,
"freeze_layers": true,
"batch_size": 8,
"epochs": 10,
"optim": "SGD",
"lr": 0.01,
"lrf": 0.001,
"save_folder": "runs"
},
"dataset": {
"trainset number": 633,
"valset number": 269,
"number classes": 3
},
"model": {
"total parameters": 57300483.0,
"train parameters": 2307,
"flops": 11285488896.0
},2.3 训练结果
所有的结果都保存在 save_ret 目录下,这里是 runs :
weights 下有最好和最后的权重,在训练完成后控制台会打印最好的epoch
这里只展示部分结果:
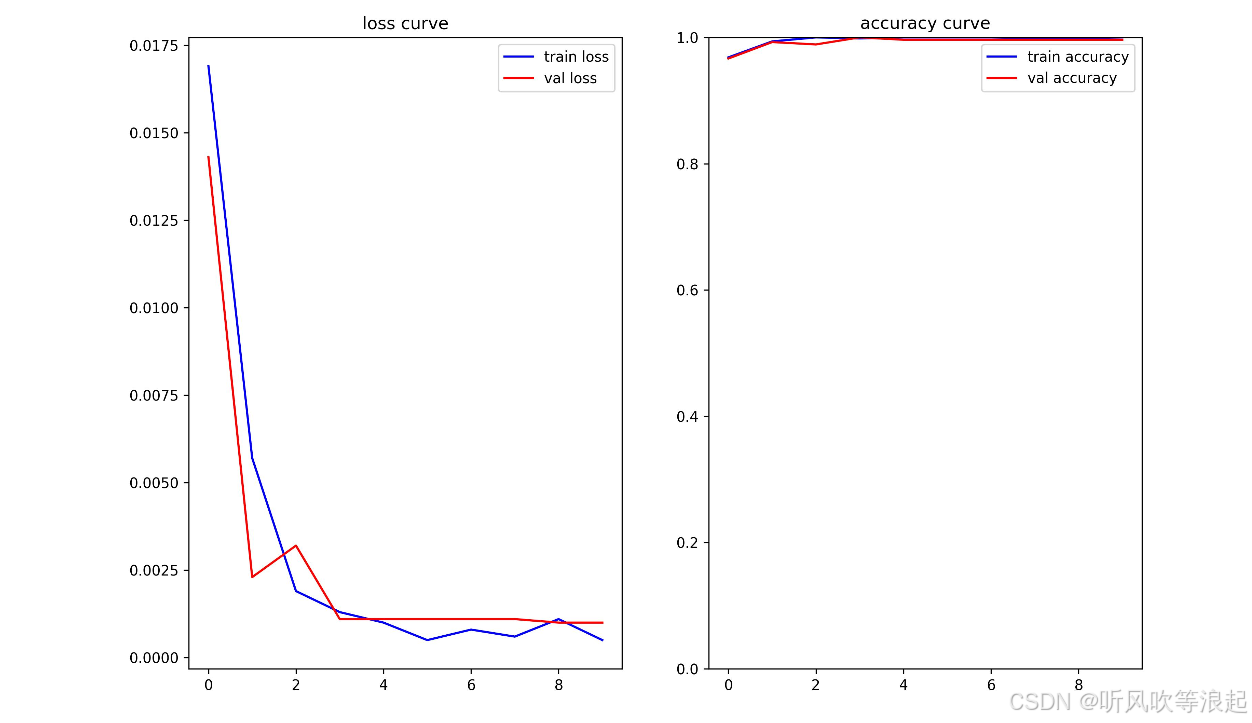
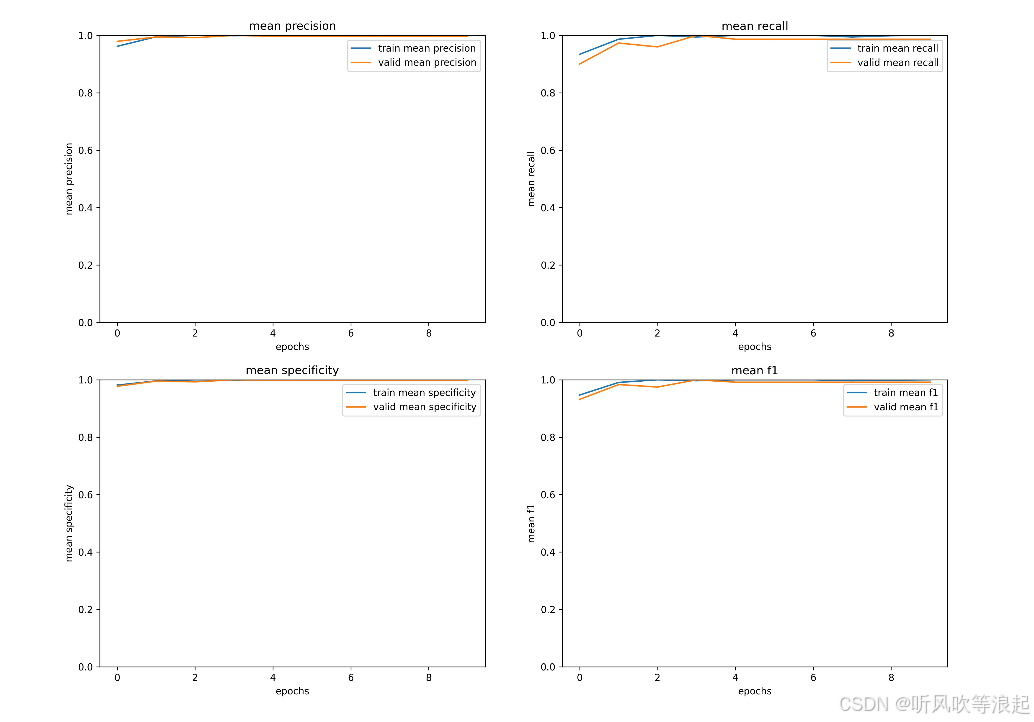
训练日志:
"epoch:9": {
"train info": {
"accuracy": 0.9999999999842022,
"corn": {
"Precision": 1.0,
"Recall": 1.0,
"Specificity": 1.0,
"F1 score": 1.0
},
"rice": {
"Precision": 1.0,
"Recall": 1.0,
"Specificity": 1.0,
"F1 score": 1.0
},
"wheat": {
"Precision": 1.0,
"Recall": 1.0,
"Specificity": 1.0,
"F1 score": 1.0
},
"mean precision": 1.0,
"mean recall": 1.0,
"mean specificity": 1.0,
"mean f1 score": 1.0
},
"valid info": {
"accuracy": 0.9962825278440043,
"corn": {
"Precision": 1.0,
"Recall": 1.0,
"Specificity": 1.0,
"F1 score": 1.0
},
"rice": {
"Precision": 0.9908,
"Recall": 1.0,
"Specificity": 0.9938,
"F1 score": 0.9954
},
"wheat": {
"Precision": 1.0,
"Recall": 0.96,
"Specificity": 1.0,
"F1 score": 0.9796
},
"mean precision": 0.9969333333333333,
"mean recall": 0.9866666666666667,
"mean specificity": 0.9979333333333334,
"mean f1 score": 0.9916666666666667
}训练集和测试集的混淆矩阵:
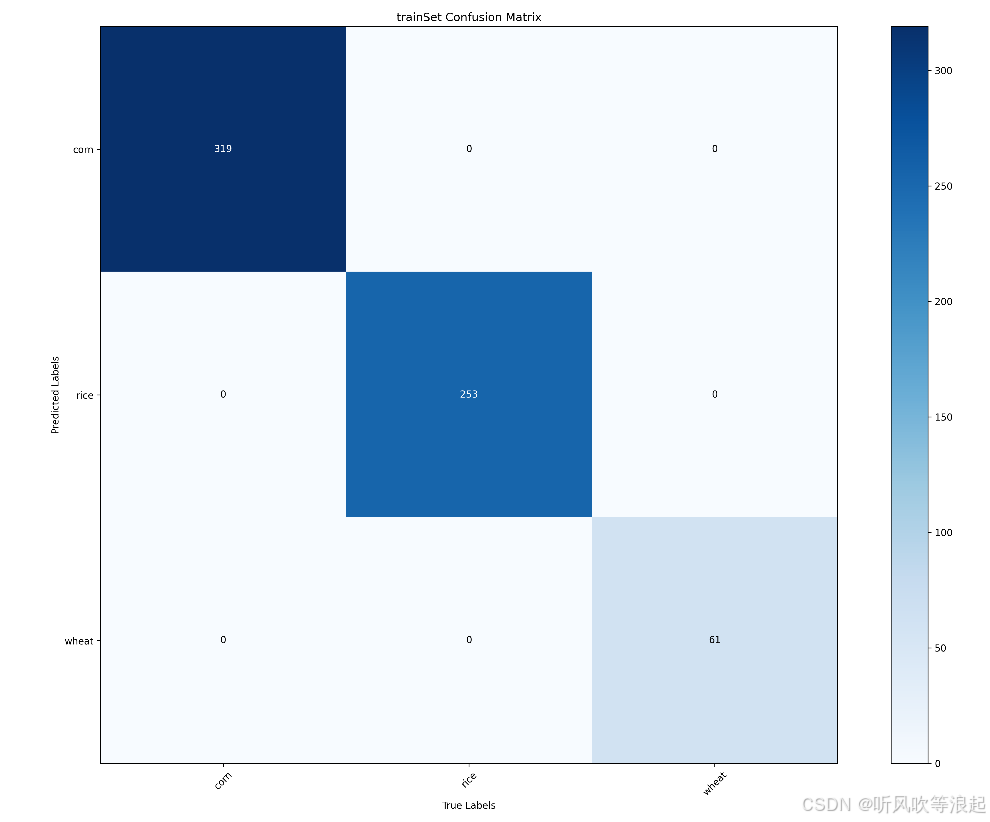
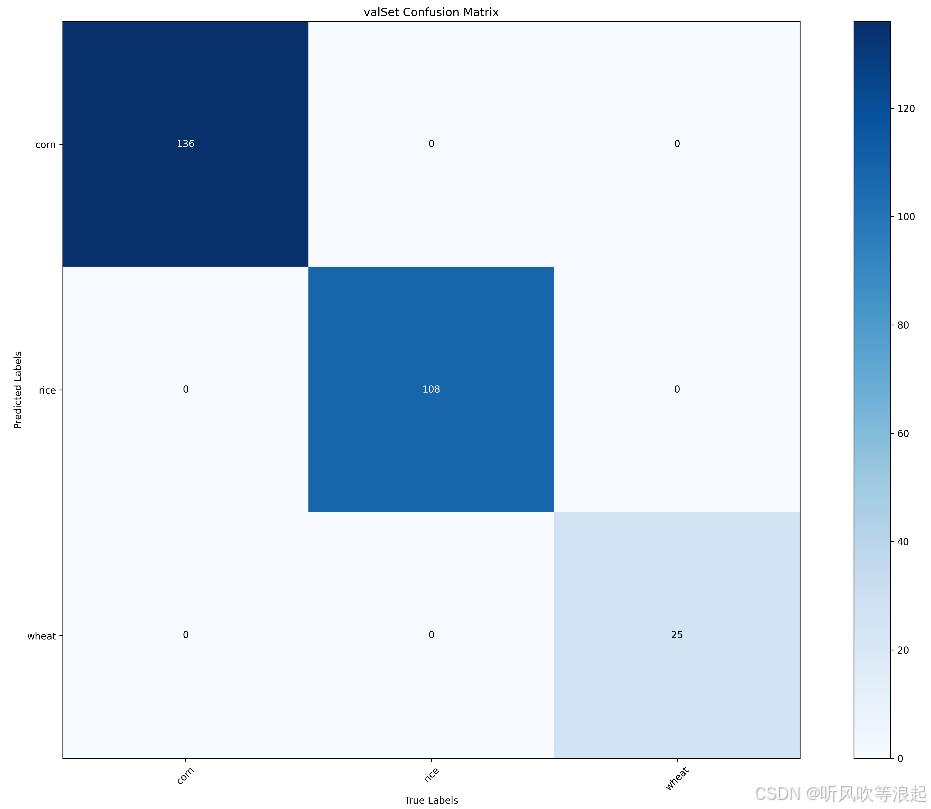
2.4 可视化网页推理
推理是指没有标签,只有图片数据的情况下对数据的预测,这里使用了网页推理
值得注意的是,如果训练了自己的数据集,需要对infer脚本进行更改,如下:
1. 都需要绝对路径,这个是代码自动生成的类别文件,在runs下
2. 这里是训练好的模型,也在runs下,可以选择best或者last都可以
3. 这个是默认展示的demo图片位置
接下来在控制台运行下面命令即可:这里貌似也需要绝对路径
streamlit run D:\project\VisionTransformer\infer.py
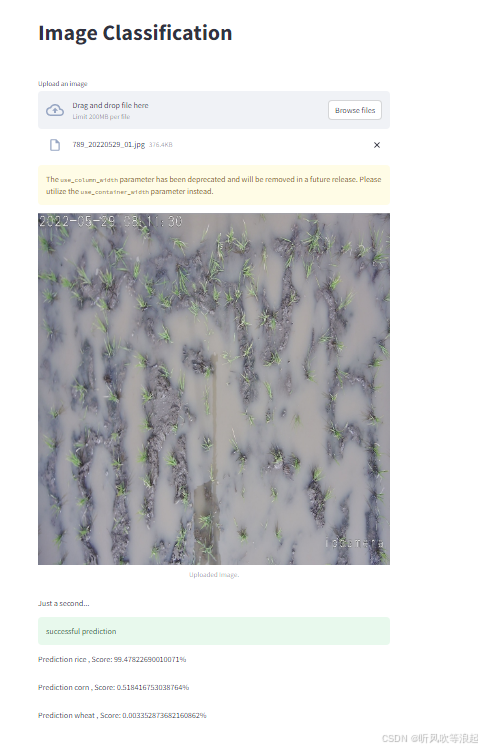
有的会自动弹出网页,有的会生成本地的网址,点进去就行了,展示如下:
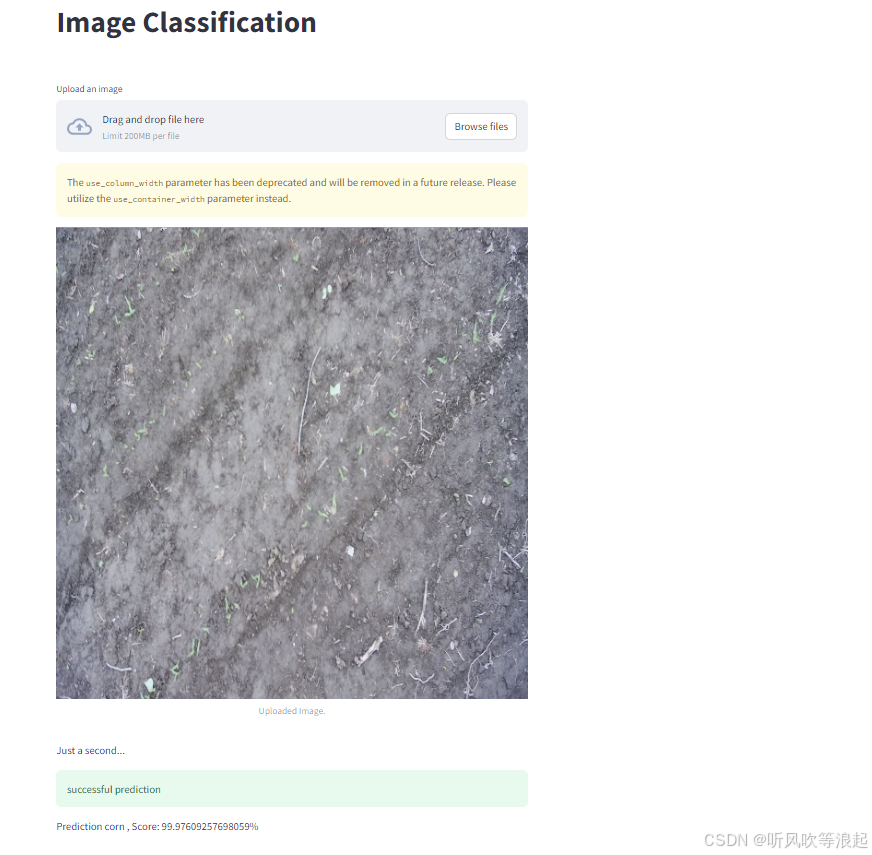
上传本地的图片,也可以进行推理:
3. 下载
关于本项目代码和数据集、训练结果的下载:
计算机视觉项目:vision-Transformer模型实现的图像识别项目:小麦、水稻、玉米早期秧苗图像分类资源-CSDN文库
关于图像分类网络的改进可以参考: