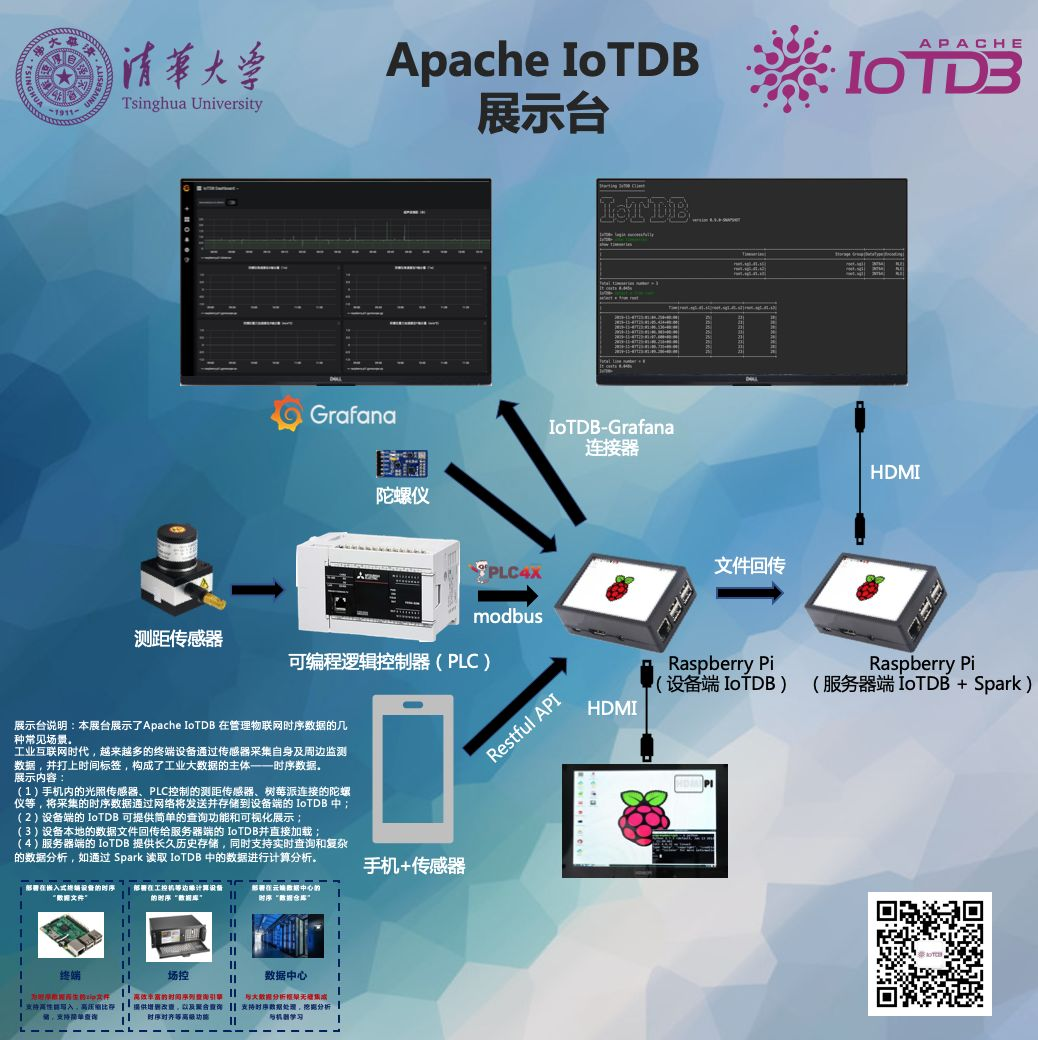
前言思路
一、 MES关系型数据 =》Oracle
二、 工厂实时时序性数据 =》 IoTDB

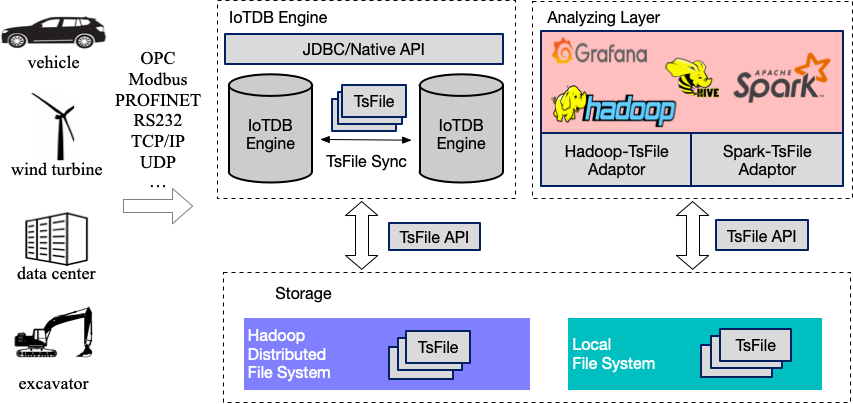
IoTDB 的架构图如上所示,覆盖了对时序数据的采集、存储、查询、分析以及可视化等全生命周期的数据管理功能,其中灰色部分为 IoTDB 组件。
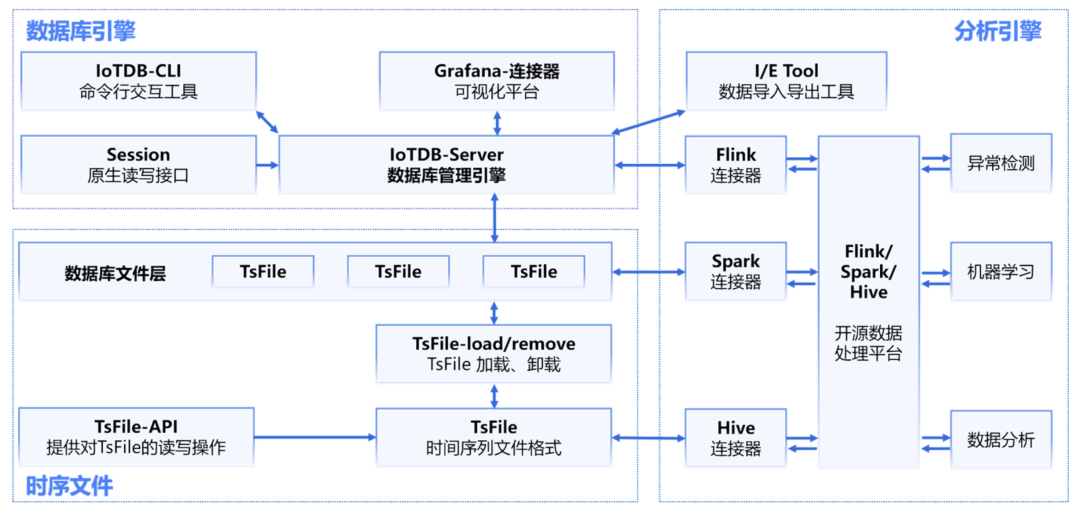
IoTDB 套件由若干个组件构成,共同形成“数据收集-数据写入-数据存储-数据查询-数据可视化-数据分析”等一系列功能。
用户可以通过 JDBC 将来自设备上传感器采集的时序数据、服务器负载和 CPU 内存等系统状态数据、消息队列中的时序数据、应用程序的时序数据或者其他数据库中的时序数据导入到本地或者远程的 IoTDB 中。用户还可以将上述数据直接写成本地(或位于 HDFS 上)的 TsFile 文件。
可以将 TsFile 文件写入到 HDFS 上,进而实现在 Hadoop 或 Spark 的数据处理平台上的诸如异常检测、机器学习等数据处理任务。
对于写入到 HDFS 或者本地的 TsFile 文件,可以利用 TsFile-Hadoop 或 TsFile-Spark 连接器允许 Hadoop 或 Spark 进行数据处理。
对于分析的结果,可以写回成 TsFile 文件。
IoTDB 和 TsFile 还提供了相应的客户端工具,满足用户查看和写入数据的 SQL 形式、脚本形式和图形化形式等多种需求。
官方文档
https://iotdb.apache.org/zh/UserGuide/Master/QuickStart/QuickStart.html
傻瓜式步骤(Linux)
1. 安装环境
安装前需要保证设备上配有 JDK>=1.8 的运行环境,并配置好 JAVA_HOME 环境变量。
设置最大文件打开数为 65535。
1. 配置Java
yum -y install lrzsz 下载上传本地文件工具
cd /export/software/ Linux进入要安装的文件夹
rz 上传java压缩包(版本>=1.8)
tar -zxvf jdk-8u65-linux-x64.tar.gz -C /export/server/ 解压jdk
vim /etc/profile
#在profile文件的最下面插入以下内容
export JAVA_HOME=/export/server/jdk1.8.0_65
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
java -version 查看版本号
2. 配置iotdb
cd /export/software/ Linux进入要安装的文件夹
yum -y install wget 下载安装工具
yum -y install uzip 下载解压zip工具
wget https://archive.apache.org/dist/iotdb/0.13.1/apache-iotdb-0.13.1-all-bin.zip 安装iotdb0.13.1版
unzip apache-iotdb-0.13.1-all-bin.zip 解压iotdb
echo "ulimit -n 65535" >>/etc/profile 修改最大文件数限制
source /etc/profile
ulimit -n 查看是否修改成功
2.1 启动iotdb

cd apache-iotdb-0.11.2/sbin
nohup sbin/start-server.sh -f >/dev/null 2>&1 &
or
nohup sbin/start-server.sh -b
or
./start-server.sh 直接启动server
在上面的服务开启了以后,我们不要管理,另外开启一个窗口,来连接我们的IoTDB。
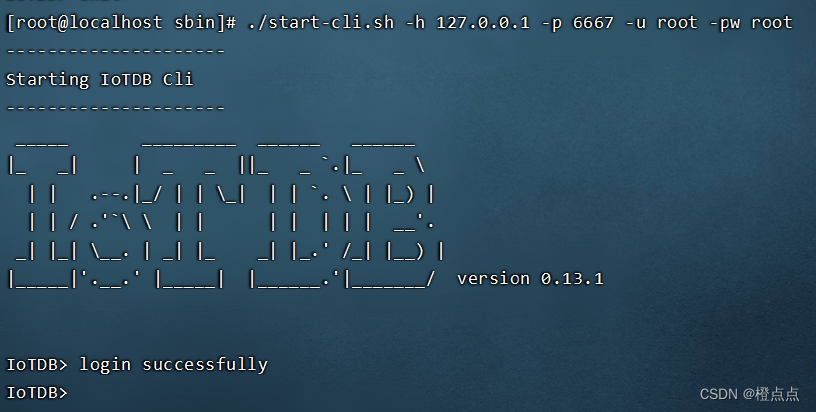
./start-cli.sh 启动cli
./start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root
IoTDB为用户提供多种与服务器交互的方式,在此我们介绍使用Cli工具。
初始安装后的IoTDB中有一个默认用户:root,默认密码为root。
Cli工具启动脚本为sbin文件夹下的start-cli脚本。
启动脚本时需要指定运行ip、port、username和password(若脚本未给定对应参数,则默认参数为"-h 127.0.0.1 -p 6667 -u root -pw -root")
2.2 使用iotdb
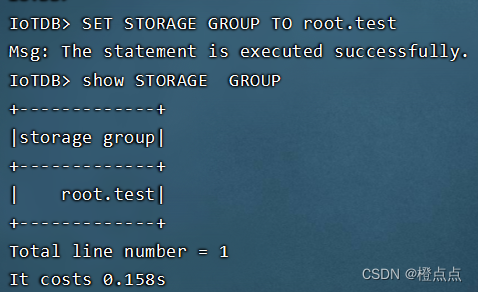
2.2.1 创建存储组
SET STORAGE GROUP TO root.test //定义存储组,相当于创建了一个表。创建的组必须依托于一个用户下,可以理解成在 root用户下创建了一个test的组。但是查询的时候 root.test要作为一个整体,root.test可以看成是一个组的名
SHOW STORAGE GROUP//检查创建的存储组
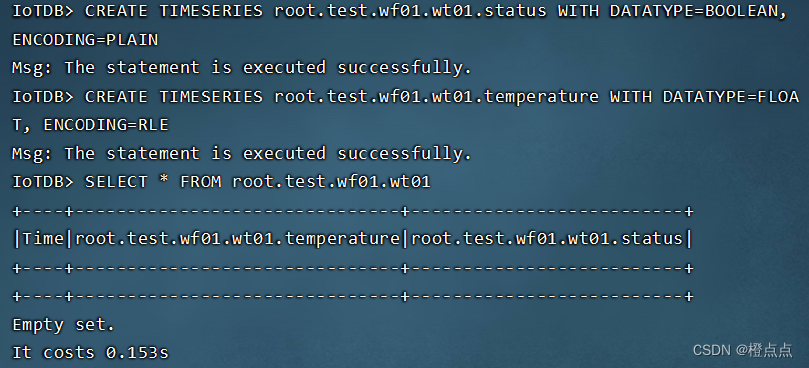
2.2.2 创建时间序列
//DATATYPE为数据类型,ENCODING为编码方式,root.test.wf01.wf01是路径,可以理解为wf01车间的wt01设备
//IoTDB 数据类型: boolean / int32 / int64 / float / double / text
//下列语句表示在 root.test组中创建了status和temperature两个时间序列 ,时间序列相当于表中的字段
CREATE TIMESERIES root.test.wf01.wt01.status WITH DATATYPE=BOOLEAN, ENCODING=PLAIN
CREATE TIMESERIES root.test.wf01.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE
//使用SHOW TIMESERIES语句查看系统中存在的所有时间序列
查询某个设备的相关的序列
SELECT * FROM root.test.wf01.wt01
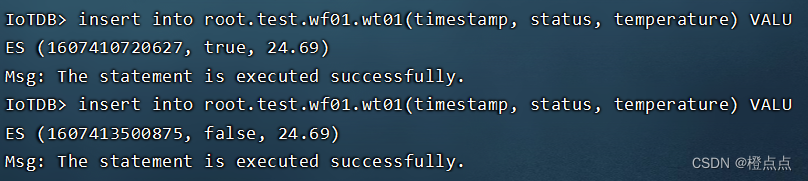
2.2.3 插入数据
insert into root.test.wf01.wt01(timestamp, status, temperature) VALUES (1607410720627, true, 24.69)
insert into root.test.wf01.wt01(timestamp, status, temperature) VALUES (1607413500875, false, 24.69)
2.2.4 查询
//车间
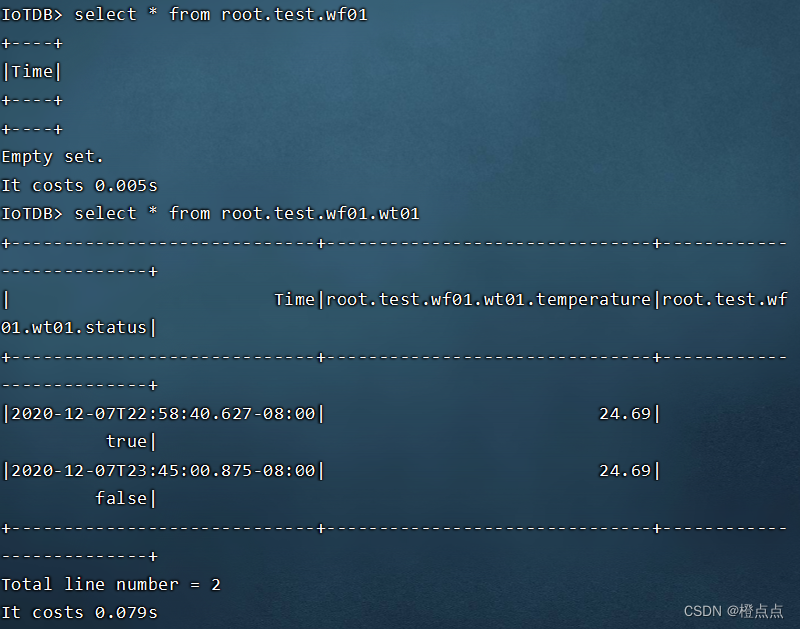
select * from root.test.wf01
//设备
select * from root.test.wf01.wt01
2.3 退出iotdb
exit
or
quit
2. TsFile格式(Time series File)
时间序列(Timeseries)
一个物理实体的某个物理量在时间轴上的记录,是数据点的序列。
一个实体的一个物理量对应一个时间序列,即实体+物理量=时间序列。
时间序列也被称测点(meter)、时间线(timeline)。实时数据库中常被称作标签(tag)、参数(parameter)。
例如,ln 电力集团、wf01 风电场的实体 wt01 有名为 status 的物理量,则它的时间序列可以表示为:
root.ln.wf01.wt01.status
- TsFile 既是 IoTDB 的核心组成部分,也可以独立使用,通过 TsFileSync 时序数据文件同步工具将文件同步至 HDFS 后即可在 Hadoop 或 Spark 等平台上进行数据处理。
| ORC | TsFile |
|---|---|
| schema预先定义 | 时间戳不对齐 |
| 以行式写入,列式存储 | 各序列独立写入 |
| 按属性组织 | 查询结果按时间戳排序 |
| 关系数据 | 时序数据 |
|---|---|
| 关系是一种集合,这种集合的元素称为元组。元组是对象个数有限的序列,例如(张三,李四)是一组元组,(一班,二班)是另一组元组。这种由行和列组成的表格就是二维表,也是关系数据库中的数据存在形式。 | 时序,即时间序列、时序数据,就是带着时间戳的一系列数据,通常表示被测量的主体在一段时间内的每个时间戳对应的数据变化。 |
1. 使用场景
是否所有的数据都适合用时序数据库来存储?
答案:是否定的,时序数据库提供了针对大量数据的插入操作,但同时数据的读取延迟也相对增加。而且时序数据库不支持 SQL 的数据查询。
传统数据库存储采用的都是 B+ tree,原因是查询和顺序插入时有利于减少寻道次数的。然而对于 90% 以上场景都是写入的时序数据库,使用了 LSM tree 更合适。
文件格式由于比较轻量级,适合在边缘端当做一个数据压缩包使用,这个边缘端可以是设备内部,也可以是工控机、工厂层级。设备上生成的数据可以随时持久化到文件中进行存储。这里说的设备可能一台风机,上边会有多个测点,比如风速传感器、温度传感器等。每个传感器采集的数据就是一个时间序列。
联想的IoT平台自2017年就开始使用TsFile存储时序数据。
因此,TsFile 的目标场景是管理一个或多个设备的时序数据。
- 设备-测点模型
设备(DeviceId):类似表的概念。
测点(MeasurementId):一个设备可以有多个测点,类似表中的列的概念。
时间序列路径(Path):可以通过设备和测点定义 Path(设备Id,测点Id)。
测点描述信息(MeasurementSchema):每个时间序列都对应一个描述信息,包括数据类型、编码方式、压缩方式。
每个时间序列都有两列:时间列、值列。
2. 基础知识
参数:
—数据类型:datatype—编码方式:encoding
—压缩方式:compression
数据类型:datatype
BOOLEAN(布尔值)/ INT32(整数)
INT64(长整数)
FLOAT(单精度浮点数)
DOUBLE(双精度浮点数)
TEXT(字符串)在创建浮点数的时候,可以通过 MAX_POINT_NUMBER 指定浮点数小数点后的位数。
如果未指定 MAX_POINT_NUMBER,则使用配置文件iotdb-engine.properties
编码方式:encoding
写入期间对数据进行编码,提高数据存储的效率,减少I / O操作中涉及的数据量以提高性能
PLAIN(PLAIN编码是默认的编码模式,即不编码,它支持多种数据类型。它具有较高的压缩和解压缩效率,同时空间存储效率低)
TS_2DIFF(二阶差分编码更适合于单调递增或递减的序列数据的编码,不建议用于波动较大的序列数据)
RLE(存储具有连续整数值的序列,而不建议用于大多数时间值不同的序列数据,也可用于对浮点数进行编码,浮点值连续出现、单调递增或递减,不适合存储小数点后精度要求高或波动较大的序列数据)
GORILLA(具有相似值的浮点序列,不建议将其用于具有较大波动的序列数据)
REGULAR(更适合于对规则序列递增的数据,在这种情况下它比TS_2DIFF要好)如果在创建时间序列时候,编码方式和数据类型没有对上,会报错
数据类型 支持编码 BOOLEAN PLAIN, RLE INT32 PLAIN, RLE, TS_2DIFF, REGULAR INT64 PLAIN, RLE, TS_2DIFF, REGULAR FLOAT PLAIN, RLE, TS_2DIFF, GORILLA DOUBLE PLAIN, RLE, TS_2DIFF, GORILLA TEXT PLAIN 压缩方式:compression
使用压缩技术压缩数据以进一步提高空间存储效率。但编码技术通常只适用于特定的数据类型,压缩不受数据类型的限制。
支持二种
UNCOMPRESSED (未压缩)
SNAPPY (默认)
创建时间序列:(时间序列就相当于表中的字段)
- 语法:
CREATE TIMESERIES root.abc.时间序列名称 WITH DATATYPE=数据类型, ENCODING=编码;- 创建时间序列时,参数 数据类型,编码方式 是必填的
别名:
即测点的别名,可以和测点名一样读写,不允许重复,可以不设置,;
在创建时间序列时直接在时序名之后,直接用括号,例如:
create timeseries root.xxx.name(别名) with datatype=xxx,ENCODING=xxx;# 创建时间序列 (包含别名,属性,标签) create timeseries root.turbine.d1.s1(temperature1) with datatype=FLOAT, encoding=GORILLA, compression=SNAPPY tags(unit=degree, owner=user1) attributes(description=mysensor1, location=BeiJing) # 插入更新 别名、标签、属性 ALTER timeseries root.turbine.d1.s1 UPSERT ALIAS=newAlias TAGS(unit=Degree, owner=me) ATTRIBUTES(description=ha, newAttr=v1) # 删除时间序列 delete timeseries root.turbine.d2.s1标签:tags
- key=value形式,多个标签可以用 , 进行分割;
- 可以通过标签反向查询时间序列元数据,比如,单位和拥有者,标签会常驻内存。目前只能给定一个 tag 查询条件,可精确查询和模糊查询。
属性:attributes
- key=value形式,多个标签可以用 , 进行分割;
- 只能根据时间序列路径展示出属性信息,如描述信息和位置。如果没有反向查询的需求,建议定义成属性。
0.10.0 引入的这两个概念,容易分不清这两个有啥区别。 虽然都是 key-value 类型的属性。但是 Tag 是可以反向查询时间序列的元数据的,假如有个 tag 的 key 是 owner,就可以用 show timeseries where owner=Thanos 查灭霸拥有的时间序列。Tag 常驻内存,有Tag到时间序列的索引。
Attribute 就是普通属性了,比如有个属性是 description=“this is my series”。这些属性只能是给定时间序列的路径顺带展示一下,辅助人查看的。
因此,要根据实际需求进行区分,那些需要做反向查询的属性,就建成 tag,其他的就搞成 attribute 就行了。
查看时间序列:(默认查看系统内所有的时间序列)
- show timeseries
- 查看指定存储组(指定路径下的)的时间序列: show timeseries root.com.test1
查看满足条件的时间序列:
- show timeseries where unic=元 (查看单位为‘元’的时间序列)
- show timeseries LIMIT 1 (查看1条时间序列)
- show timeseries LIMIT 1 OFFSET 3 (一般用于分页)
查看子路径
- show child paths root.com (查看root.com路径下的所有子路径)
查看时间序列数量(默认查看系统所有时间序列数量,后面可以跟上指定的路径查看指定路径下的数量)
- count timeseries root.xxx
插入更新时序#别名,标签,属性
例:将时间序列“name” 的别名设置为“新名字”,标签设置为xxx,属性设置为xxx
- alter timeseries root.com.test1.name upsert alias=新名字 tags(unit=个) attributes(description=ha, newAttr=v1)
3.使用步骤
1. 注册元数据
注册时间序列(Path+MeasurementSchema)
注册时间序列需要提供一个 Path 和一个 MeasurementSchema,可以通过这种方式注册每个时间序列
String path = "test.tsfile";在 0.10 以前,所有设备都共享一个点表,同名 Measurement 的 schema 也需要一样(这就是IoTDB里一个存储组下同名测点类型需要一样的限制的来源)。在 0.10 以后,每个时间序列做到了真正的独立,互不干扰。
按模板注册设备(设备模板+设备)
像上面一条一条注册比较麻烦,因此提供了一个设备模板的功能。每个模板定义了一组 MeasurementSchema,比如有10个测点,当一个设备关联到了这个模板上,就自动注册出了 10 个序列。
首先生成设备模板,然后注册模板。
Map<String, MeasurementSchema> template = new HashMap<>();接下来注册设备,按模板名关联到模板上:
tsFileWriter.registerDevice("device_1", "template_1");这样,我就注册了 2 个设备,每个设备都有 2 个测点。
注册一个模板,实时写入数据
- 这个是高级简化版。当我们只注册了一个设备模板时,可以不注册设备,直接写入数据。写入流程中如果发现这个设备写入的数据没有注册,会直接到模板里找同名的 MeasurementSchema 进行注册。这也是继承了 0.9 以前版本的优良传统(0.9以前的版本,TsFile 只能注册一个模板,然后就可以写数据了)。
2. 写数据
TsFile 的数据写入有一个限制,每列都需要按照时间递增写入,否则不保证正确性。
- 按设备写入一行数据:TSRecord
- 一个 TSRecord 是一个设备,一个时间戳,多个测点的值。类似一个表的一行数据。
- 按设备写入一批数据:Tablet
- 这个结构是贯穿 TsFile 和 IoTDB Session 的一个结构。表示一个设备,多个时间戳的多个测点的值,类似一个子表。这个子表不能有空值。
- 同样,这种写入接口速度快,可以达到每秒千万点写入速度。
3. 读数据
查询的接口接收一批路径,一个表达式(可以进行时间过滤和值过滤),其实就对应了 select 和 where 两个子句。
在查询时候,TsFile 的默认表结构是宽表,time, d1.m1, d1.m2, d2.m1, d2.m2。这个结构默认是把给定的查询 Path 按 Time 做对齐,并且进行条件过滤的。
3. 集群部署
1. 进入IoTDB对应文件夹
| 目录 | 说明 |
|---|---|
| conf | iotdb配置文件目录 |
| data | 默认数据文件目录,可通过修改配置文件修改位置 |
| ext | 默认udf目录,可通过修改配置文件修改位置 |
| lib | 库文件目录 |
| logs | 运行日志目录 |
| sbin | 可执行文件目录,启动停止命令等 |
| tools | 系统工具目录 |
2. 修改配置文件
| 文件名 | 配置项 | 配置项描述 |
|---|---|---|
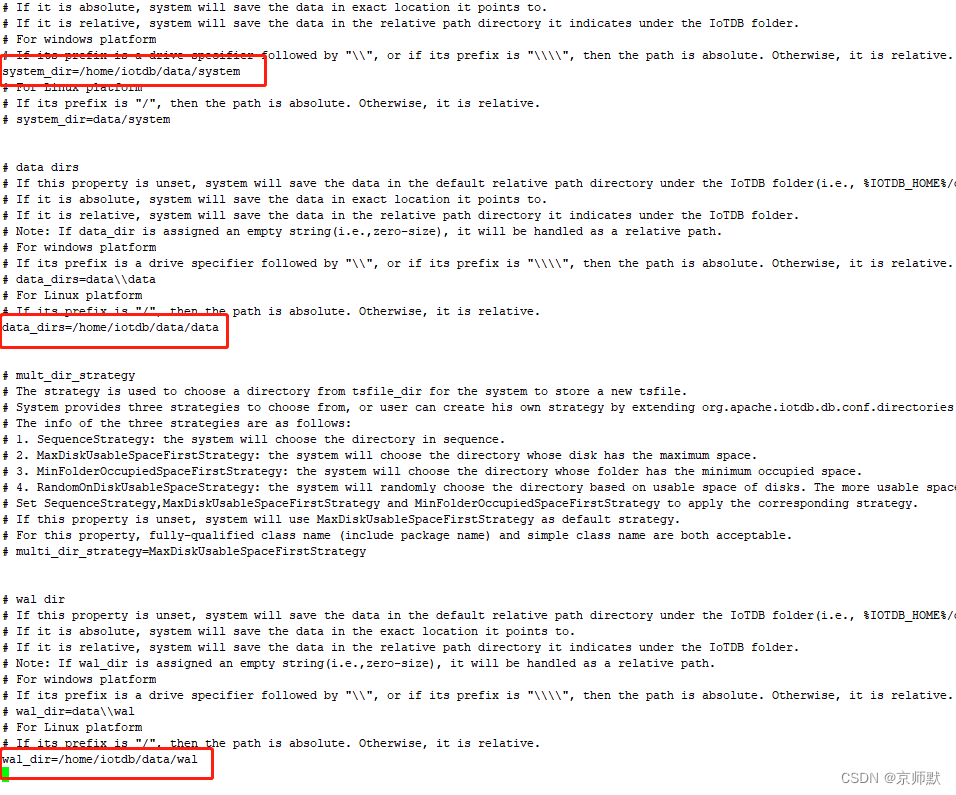
| iotdb-engine.properties | rpc_address | rpc的主机地址 |
| rpc_port | rpc的主机端口 | |
| base_dir | 基础文件目录 | |
| data_dirs | 数据存放目录 | |
| wal_dir | wal包存放目录 | |
| enable_auto_create_schema | 开启自动建表 | |
| iotdb-cluster.properties | internal_ip | IOTDB 集群各个节点之间内部通信的 IP 地址 |
| internal_meta_port | IoTDB meta 服务端口 | |
| internal_data_port | IoTDB data 服务端口 | |
| seed_nodes | 集群中节点的地址 | |
| default_replica_num | 集群副本数 |
- 只需要两个配置文件(iotdb-cluster.properties 和 iotdb-engine.properties)
1)修改配置文件iotdb-cluster.properties
vi iotdb-cluster.properties
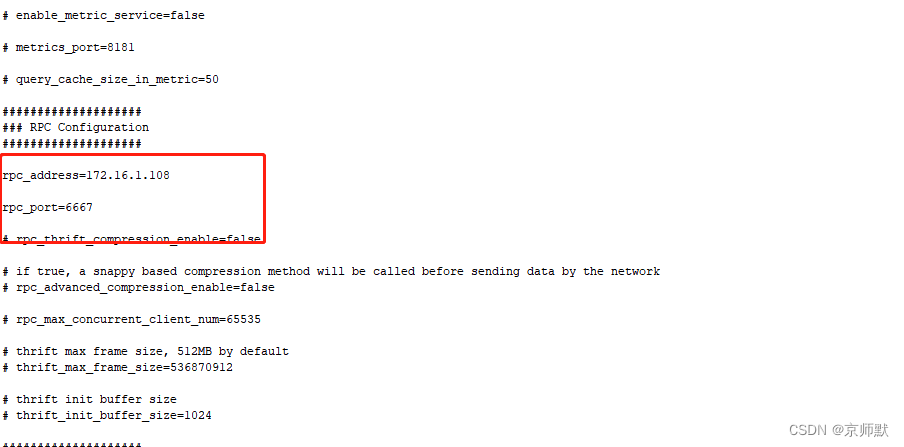
修改下图圈内参数配置,改为部署服务器的ip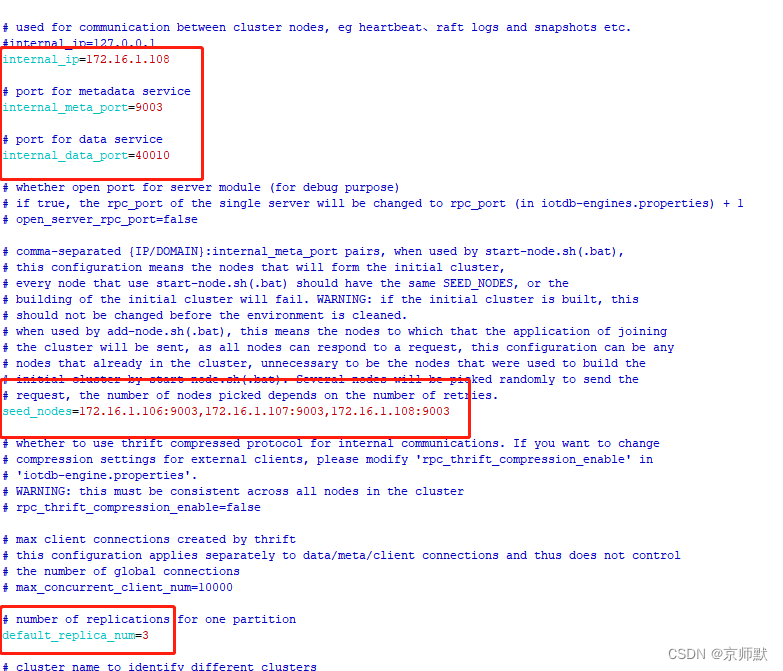
2)修改配置文件 iotdb-engine.properties
vi iotdb-engine.properties
清除历史日志和历史配置
cd data/system/``rm -fr *`删除system下的历史文件及文件夹
将改后的文件夹iotdb分发到另外二台服务器上
scp -r iotdb [email protected]:/home修改 iotdb-engine.properties 中rpc_address 和iotdb-cluster.properties 中internal_ip 的ip改为对应服务器的ip即可
启动
在这三台服务器上按顺序执行启动命令(后台运行,日志位置自己基于实际路径修改)nohup /home/iotdb/sbin/start-node.sh >/home/iotdb/logs/log 2>&1 &测试是否启动成功(ip请修改为服务器部署ip地址)
sbin/start-cli.sh -h 172.16.1.108
IoTDB的使用
1.基本命令
1.DDL
#创建 SET STORAGE GROUP TO root.ln #查询 SHOW STORAGE GROUP #删除 DELETE STORAGE GROUP root.ln#创建时间序列 CREATE TIMESERIES root.ln.wf01.wt01.status WITH DATATYPE=BOOLEAN, ENCODING=PLAIN CREATE TIMESERIES root.ln.wf01.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE #从 v0.13 起,可以使用简化版的 SQL 语句创建时间序列: create timeseries root.ln.wf01.wt01.status BOOLEAN encoding=PLAIN #创建(增加 测点别名、标签、属性 三个概念) #标签和属性总大小在配置文件中 tag_attribute_total_size 设置。 create timeseries root.turbine.d1.s1(temperature1) with datatype=FLOAT, encoding=GORILLA, compression=SNAPPY tags(unit=degree, owner=user1) attributes(description=mysensor1, location=BeiJing) create timeseries root.turbine.d1.s2(temperature2) with datatype=FLOAT, encoding=GORILLA, compression=SNAPPY tags(unit=degree, owner=user1) attributes(description=mysensor2, location=TianJin) create timeseries root.turbine.d2.s1(temperature1) with datatype=FLOAT, encoding=GORILLA, compression=SNAPPY tags(unit=degree, owner=user2) attributes(description=mysensor3, location=HeBei) # 创建对齐时间序列 CREATE ALIGNED TIMESERIES root.ln.wf01.GPS(latitude FLOAT encoding=PLAIN compressor=SNAPPY, longitude FLOAT encoding=PLAIN compressor=SNAPPY) # 插入更新 别名、标签、属性 ALTER timeseries root.turbine.d1.s1 UPSERT ALIAS=newAlias TAGS(unit=Degree, owner=me) ATTRIBUTES(description=ha, newAttr=v1) # 删除时间序列 delete timeseries root.turbine.d2.s1 # 查询(根据路径和标签查询序列元数据) # 查询所有时间序列 show timeseries # 查询 root.turbine.d1 前缀路径下的时间序列 show timeseries root.turbine.d1 # 根据 tag 精确查询 owner 为 user1 的序列 show timeseries root.turbine where owner=user1 # 查看某个路径的孩子节点 show child paths root.turbine SHOW CHILD NODES pathPattern # 统计所有时间序列 count timeseries # 分组统计(root为第0层) count timeseries group by level=2 # 查询所有设备 show devices
2. DML
写入数据
# IoTDB允许用户不预先定义表结构,直接写入数据,这个特性降低了用户使用负担,也更加适应物联网设备快速迭代升级的场景。 insert into root.turbine.d1(timestamp,s1,s2) values(1,1,2); insert into root.turbine.d1(timestamp,s1,s2) values(2,1,2); insert into root.turbine.d1(timestamp,s1,s2) values(3,1,2);删除数据
delete from root.turbine.d2.s1 where time <= 10查询(原始数据)
select * from root.turbine.d1查询(单点补空值)
#很多时间戳有偏差,时间戳精确查询容易查不到数据,可以用 previous 或者 linear 方式补空值 select s1 from root.turbine.d1 where time = 8 # 用前边最近的值填过来 select s1 from root.turbine.d1 where time = 8 fill(float[previous]) # 如果想限制补值的范围,超过这个范围就不补了,可以再加个参数,要带单位 select s1 from root.turbine.d1 where time = 8 fill(float[previous,1ms])查询(最新数据)
select last * from root聚合查询
select count(*) from root where time <= 10查询(按设备对齐)
# IoTDB 查询的默认表结构是【time,序列1,序列2,…,序列n】,所有序列会按照 time 对齐,如果存在某个序列在一个时间点不存在,会补空值,在做值过滤时候,这种表结构的过滤也会很严格。 select * from root # 为了使得各个设备查询时不互相影响,我们支持按 time 和设备对齐查询,表结构为【time,设备ID,测点1,测点2,…,测点n】,这种就和关系表结构比较像了,只需要在查询语句后加 align by device select * from root align by device
2. 基本概念
1. 数据模型
对齐时间序列(Aligned Timeseries)
在实际应用中,存在某些实体的多个物理量同时采样,形成在时间列上对齐的多条时间序列。
通过使用对齐的时间序列,在插入数据时,一组对齐序列的时间戳列在内存和磁盘中仅需存储一次,而不是每个时间序列存储一次。
对齐的一组时间序列最好同时创建。
不可以在对齐序列所属的实体下创建非对齐的序列,不可以在非对齐序列所属的实体下创建对齐序列。
查询数据时,可以对于每一条时间序列单独查询。
插入数据时,对齐的时间序列中某列的某些行允许有空值。
一组对齐序列中的序列可以有不同的数据类型、编码方式以及压缩方式。对齐的时间序列暂不支持设置别名、标签、属性
2. 存储组(Storage group)
# 以下两种方式都可以创建 set storage group to root.ln create storage group root.sgcc一组物理实体,用户可以将任意前缀路径设置成存储组。如有 4 条时间序列
root.ln.wf01.wt01.status,root.ln.wf01.wt01.temperature,root.ln.wf02.wt02.hardware,root.ln.wf02.wt02.status,路径root.ln下的两个实体wt01,wt02可能属于同一个业主,或者同一个制造商,这时候就可以将前缀路径root.ln指定为一个存储组。未来root.ln下增加了新的实体,也将属于该存储组。一个存储组中的所有实体的数据会存储在同一个文件夹下,不同存储组的实体数据会存储在磁盘的不同文件夹下,从而实现物理隔离。
注意 1:不允许将一个完整路径(如上例的
root.ln.wf01.wt01.status) 设置成存储组。注意 2:一个时间序列其前缀必须属于某个存储组。在创建时间序列之前,用户必须设定该序列属于哪个存储组(Storage Group)。只有设置了存储组的时间序列才可以被持久化在磁盘上。
一个前缀路径一旦被设定成存储组后就不可以再更改这个存储组的设定。
一个存储组设定后,其对应的前缀路径的祖先层级与孩子及后裔层级也不允许再设置存储组(如,
root.ln设置存储组后,root 层级与root.ln.wf01不允许被设置为存储组)。存储组节点名只支持中英文字符、数字、下划线和中划线的组合。例如
root. 存储组_1-组1
3. 元数据模板(Schema template)
对于大量的同类型的实体,每一个实体下的物理量都相同,为每个序列注册时间序列一方面时间序列的元数据将占用较多的内存资源,另一方面,大量序列的维护工作也会十分复杂。
为了实现同类型不同实体的物理量元数据共享,减少元数据内存占用,同时简化同类型实体的管理。
将元数据模版挂载在树形数据模式的任意节点上,表示该节点下的所有实体具有相同的物理量集合。目前每一条路径节点仅允许挂载一个元数据模板,即当一个节点被挂载元数据模板后,它的祖先节点和后代节点都不能再挂载元数据模板。实体将使用其自身或祖先的元数据模板作为有效模板。
特别需要说明的是,挂载模板与使用模板的概念不同。
一个节点挂载模板后,其所有后代节点都可以使用这个模板,因此可以通过向同类实体的祖先节点挂载模板来简化操作。当系统向挂载模板的节点(或其后代节点)插入模板中定义的物理量时,这个节点就被设置为“正在使用模板”。
使用元数据模板后,所有的物理量元数据仅在模板中保存一份,所有的实体共享模板中的元数据。
强烈建议您将模板设置在存储组或存储组下层的节点中,以更好地适配未来地更新及各模块的协作。
挂载元数据模板后,即可向挂载节点或该节点的子孙节点,按照模板的模式进行数据写入。
1. 创建元数据模板
# 创建元数据模板 # 包含两个非对齐序列 create schema template t1 (temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN compression=SNAPPY) # 包含一组对齐序列 lat和lon create schema template t2 aligned (lat FLOAT encoding=Gorilla, lon FLOAT encoding=Gorilla)在场景和模型的选择方面,非对齐序列更适合多物理量独立采集场景,对齐序列更适多物理量同时采集的场景。可以根据不同场景选择不同存储引擎。
2. 挂载元数据模板
# 挂载元数据模板
# 建议将模板设置在存储组及存储组下层的节点中
set schema template t1 to root.sg1.d1
# 在插入数据之前,模板定义的时间序列不会被创建。可以使用如下SQL语句在插入数据前创建时间序列
create timeseries of schema template on root.sg1.d1
# 查看此时时间序列
show timeseries root.sg1.**
# 查看此时设备
show devices root.sg1.**
# 查看所有原始数据模板
show schema templates
# 查看某个元数据模板下的物理量
show nodes in schema template t1
# 查看挂载了某个元数据模板的路径前缀
show paths set schema template t1
# 查看使用了某个元数据模板(即序列已创建)的路径前缀
show paths using schema template t1
3. 解除/卸载/删除 元数据模板
# 解除 (注意:这一操作会删除对应节点下按照模板中的序列写入的数据)
deactivate schema template t1 from root.sg1.d1
# 卸载
unset schema template t1 from root.sg1.d1
# 删除 (注意:不能删除尚未卸载的模板)
drop schema template t1
4. 数据存活时间(TTL)
给存储组设置ttl,使 IoTDB 可以定期、自动地删除一定时间之前的数据。合理使用 TTL 可以帮助您控制 IoTDB 占用的总磁盘空间以避免出现磁盘写满等异常。及时地删除一些较老的文件有助于使查询性能维持在一个较高的水平和减少内存资源的占用。
设置TTL
# 表示在root.ln存储组中,只有最近一个小时的数据将会保存,旧数据会被移除或不可见。 set ttl to root.ln 3600000取消TTL
# 取消设置 TTL 后,存储组root.ln中所有的数据都会被保存 unset ttl to root.ln显示TTL
# 给出所有存储组的 TTL SHOW ALL TTL # 显示指定的存储组的 TTL : `SHOW TTL ON StorageGroupNames` # 注意:没有设置 TTL 的存储组的 TTL 将显示为 null。 SHOW TTL ON root.group1,root.group2,root.group3