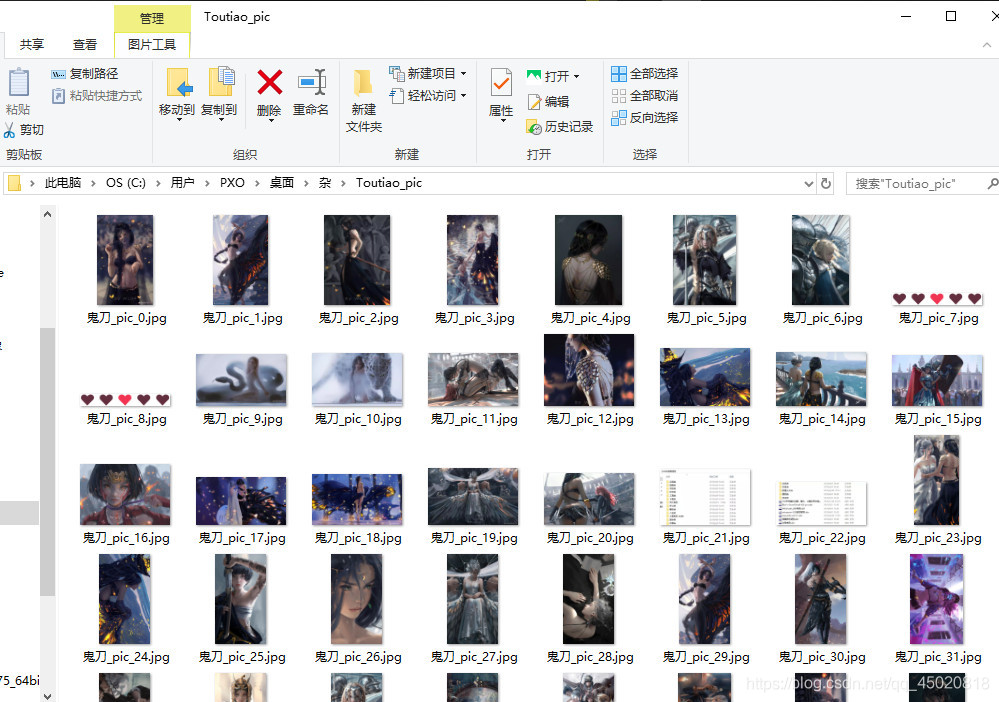
码前冷静分析
首先需要准备好selenium、requests库以及Chromedriver
- 这个就不细说了,有很多博客可以参考
然后讲一下大体思路
| 首先搜索想要爬取图片的关键词 |
| - 接着是“搜集”搜索结果 |
| - 然后想办法逐一进入搜索结果,进而获取内容 |
| - 最后就是下载了 |
框架大体如下
框架是个大体思路(草稿),写代码的时候可以灵活来
def get_list(url): #目的是根据关键词搜索,抓取每一条结果的图片链接
lst = []
browser = webdriver.Chrome()
wait = ww(browser, 10)
#……等等等等
return lst
#胡乱摸索了线程简单的应用,就copy了另一个一样的下载函数
def download_pic1(lst): #逐一遍历列表中的图片链接,下载美图
return ''
def download_pic2(lst): #逐一遍历列表中的图片链接,下载美图
return ''
def main():
global keyword
keyword = '鬼刀'
basic_url = 'https://www.toutiao.com/'
lst = get_list(basic_url) #访问主页,搜索,收集结果的图片链接,返回列表
download_pic(lst) #根据链接下载图片
#就是这么小白式的简单粗暴,水平还不够,暂时就只弄两个函数吧
#虽然是有点臃肿了,嘤嘤嘤
开 码
首先把要用的库给喊粗来
库,函数的使用介绍有很多超棒的博客,本文会给出部分链接
- 好的,上代码
import requests
from time import sleep
import os
import os.path as op
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait as ww
import threading
1.1 访问今日头条首页,关键词传送及点击搜索
def get_list(basic_url):
lst = []
browser = webdriver.Chrome()
wait = ww(browser, 10)
try:
browser.get(basic_url)
#找到搜索框节点
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#rightModule > div.search-wrapper > div > div > div > input')))
#找到搜索按钮节点
click = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#rightModule > div.search-wrapper > div > div > div > div > button')))
input.send_keys(keyword) #模拟传入搜索词
sleep(2) #输入后停一下,要不然立马让你验证,来自小白的喵喵喵
click.click() #模拟点击搜索按钮
except Exception as er:
print(er)
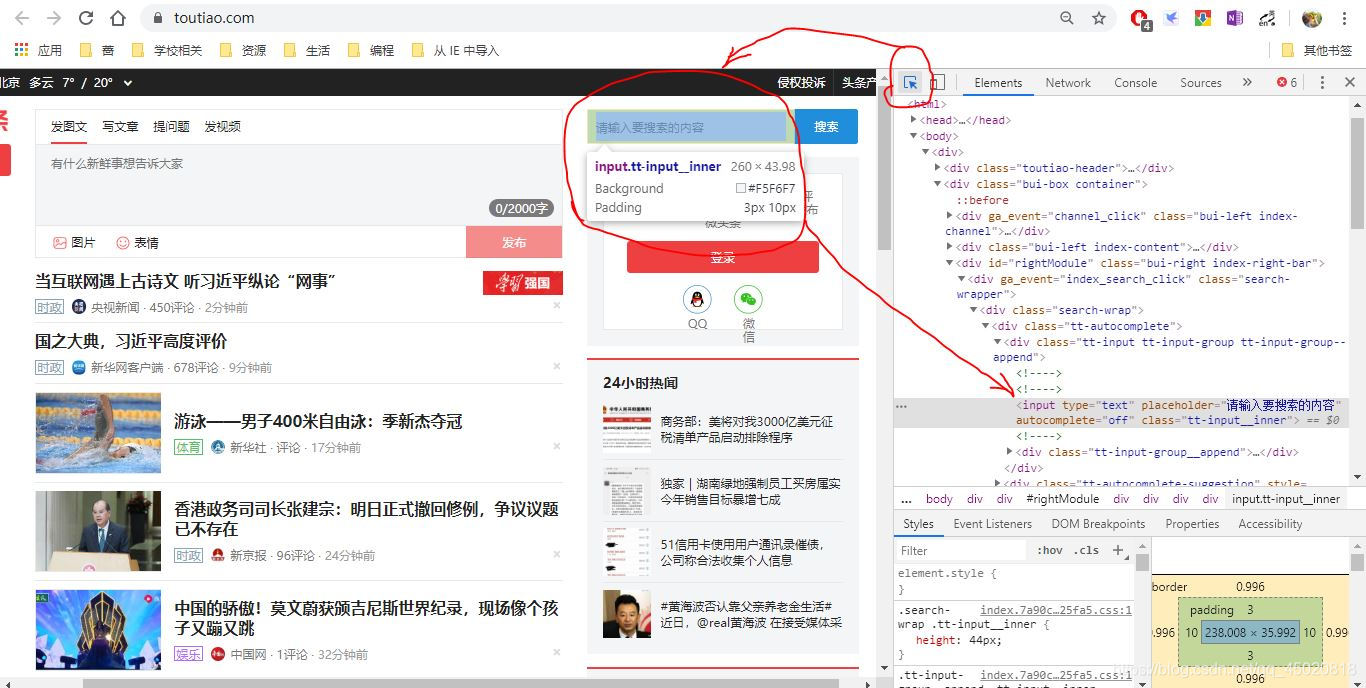
# 两个节点的查找看下图
节点查找~超详细解答如下博文
博主 Eastmount 原创
【[python爬虫] Selenium常见元素定位方法和操作的学习介绍】wait用法详解~如下链接
博主 不码不成才 原创
【python+selenium中的wait事件】CSS选择器用法介绍~博文链接如下
到主页后右键—>检查—>开找
- 首先是输入框查找(按照图示顺序很快就找到啦)
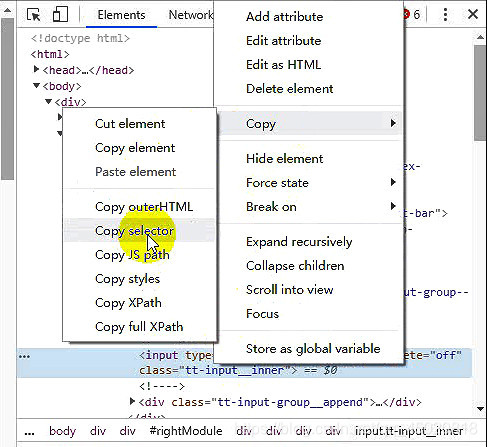
- 然后右键点击节点,copy—>copy selector
啦啦啦~
|
节点查找~超详细解答如下博文
博主 Eastmount 原创
【[python爬虫] Selenium常见元素定位方法和操作的学习介绍】wait用法详解~如下链接
博主 不码不成才 原创
【python+selenium中的wait事件】CSS选择器用法介绍~博文链接如下
这样就进入到了搜索结果界面,接下来就是让它加载出更多结果,通过模拟滑动来实现
1.2 接下来便是模拟滑动页面,出加载更多结果,上码
# 首先把browser切换到当前搜索结果的页面
browser.switch_to.window(browser.window_handles[1])
#滑动多少自己可以任意发挥
for i in range(0, 2001, 250):
#下边这个方法来模拟滚动屏幕(详解可以参考其它博客)
browser.execute_script(f'window.scrollBy(0, {i})')
sleep(2)
#滑的差不多了,您是不是该寻思着收集进入结果的''门''了?
clicks = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.link.title')))
模拟滑动所用的方法【execute_script()】相关博客链接如下。
【博主 吾爱乐享 原创-----python学习之滚动页面函数execute_script】
+
【博主 qq_16069927 原创 ----selenium 如何控制滚动条逐步滚动】
- 来一起找这’'门’‘吧!
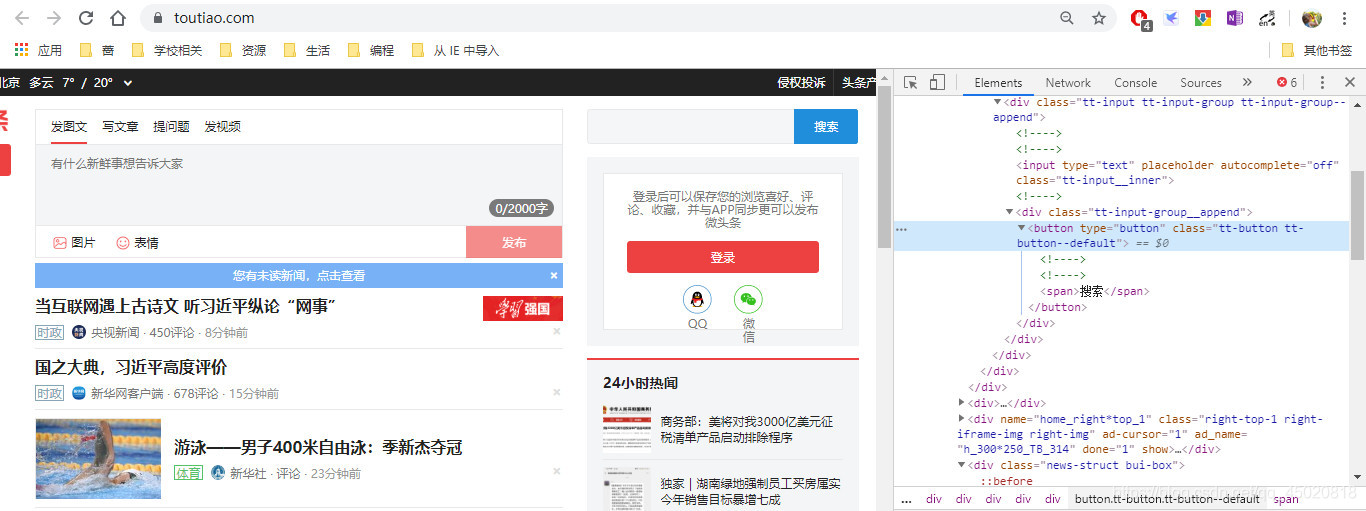
经过观察以及实践,点击标题链接可以进子入页面,就是你了皮卡丘!(就是蓝色阴影那个节点)- 首先观察,class有两个属性,所以CSS选择器因该是 ‘.link.title’,既然找到了,就都收集起来吧,哈哈
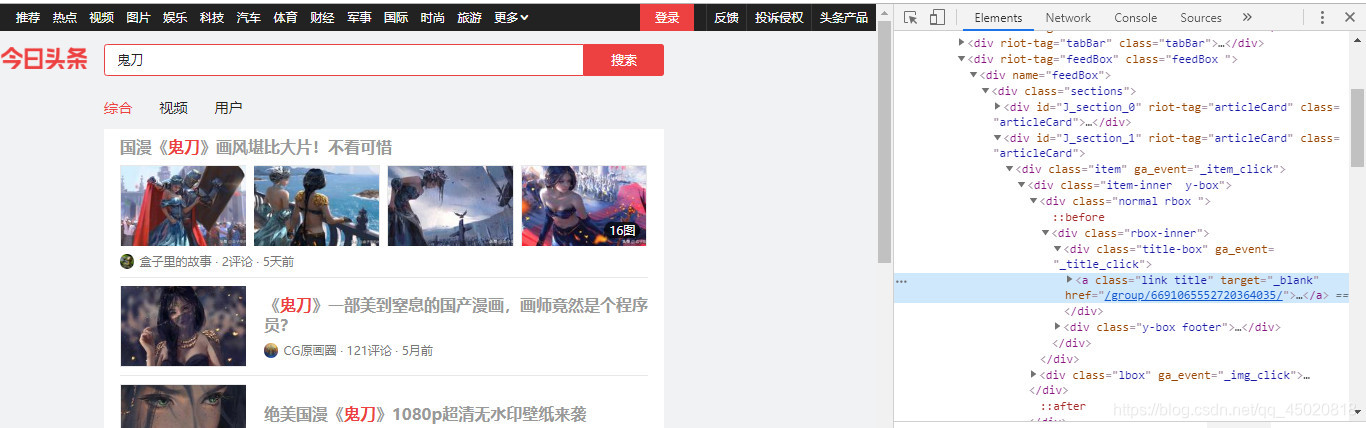
1.3 接下来,就开始邪恶的循环,打开子页面->回到搜索结果页->打开子页面->回到搜索结果页……
- 别问为什么,问就是网速慢,先打开页面,让成熟的它自己加载着,然后挨个收割美图链接
- 不要问为什么不找到链接当时就给图片给下了,问就是缺少仪式感。
上码!
for clc in clicks[1:10]: # 搜索结果打开数自己定,我是因为穷,惨,所以就10个吧(嘤嘤嘤)
clc.click()
#进入子页面后,趁它不注意,赶快回到结果页
browser.switch_to.window(browser.window_handles[1])
sleep(4)
1.4 然后开始收割美图链接吧,哈哈!
上码!
for num in range(len(browser.window_handles) - 2):
#逐个进入子页面
browser.switch_to.window(browser.window_handles[num + 2])
#等待所有图片节点加载粗来,收集它
try: #可能会遇到视频界面,到时候这里判断错误就不管,进入下一个
img = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'img[src]')))
except:
pass
#提取链接到列表
for mg in img:
url = mg.get_attribute('src')
if url.startswith('http://p') and 'thumb' not in url:
lst.append(url)
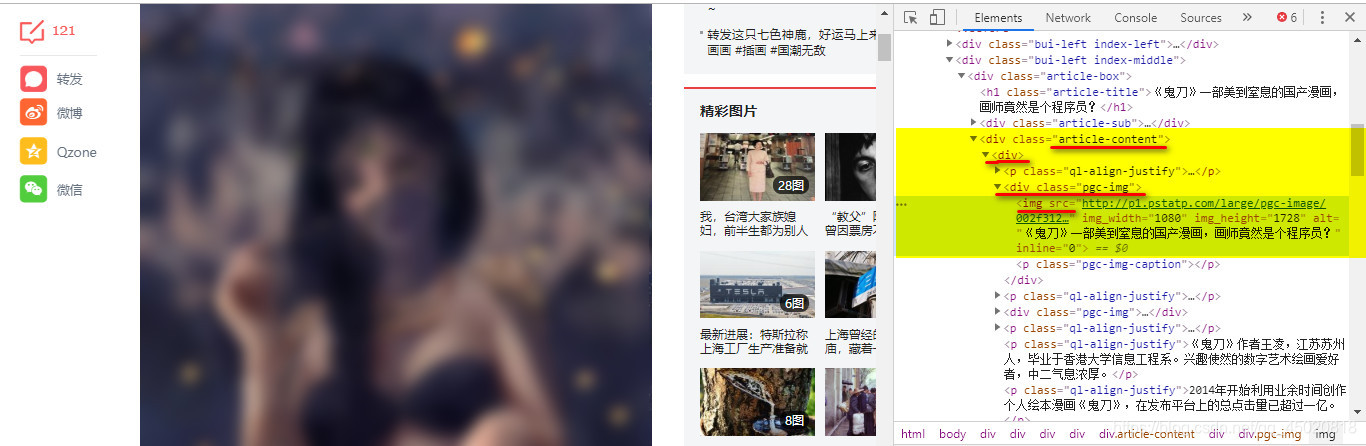
老问题,找节点,上图!!!
通过分析,可以看出,文章中图片链接都在图中红线标注的 ‘路径’内,所以……
可以构造一个CSS选择器,筛选出所有含图链接节点 ,通过实战,发现有两种页面:
常见的一种是一页到底那种,图片在-> ‘.article-content div .pgc-img img[src]’,
另一种是跟ins一样左右切换那种
两种页面图片节点路径就不一样了,但是标签名都是<img>属性都是’src’,所以选择器就粗糙一点"img[src]"
这样就需要筛选一下了,粗糙的选择器就会获取到一些广告图,实战发现,广告图链接几乎都是’https://……”而图片链接是“http://……”这就很妙了,如代码
【这里很粗糙,还是可能会爬到不相关的,flag:以后有时间再改进改进】
2.接下来就是下载了!
这里我后来翻了一些优秀博客,胡乱摸索,写了个very简单(因为菜)的双线程下载
说白了就是同时运行两个下载函数,男人嘛,不能叫快要叫效率
上码
def download_pic1():
#单独搞个文件夹存一下
path = r'C:\Users\PXO\Desktop\杂\Toutiao_pic\\' + keyword
if not op.exists(path):
os.mkdir(path)
ln = len(lst)
id = [i for i in range(ln)]
cnt = 1
for url in lst[:ln//2]:#负责前半部分列表下载
#开始搞事情,遍历图片链接,get get get!
r = requests.get(url)
#这里设置文件保存路径(含文件名)
pic_path = path + '\\' + f'{keyword}_pic_{id.pop(0)}.jpg'
#以二进制写入方式打开命名好的文件
with open(pic_path, 'wb+') as ff:
#写入获取到的图片(二进制)//养成好习惯,随手关闭
ff.write(r.content)
ff.close()
#下边是一个小优化,刷新显示当前下载状态
op1 = cnt*120//ln
en = 60 - op1
opp, enn = '-'*op1, '*'*en
print(f'\r[1]下载ing:已下{cnt}/{ln//2}张,[{opp}>{enn}] {(2 * cnt) / len(lst):.1%}', end='')
cnt += 1
#下边copy一下就是另一个啦
def download_pic2():
path = r'C:\Users\PXO\Desktop\杂\Toutiao_pic\\' + keyword
if not op.exists(path):
os.mkdir(path)
ln = len(lst)
id = [i for i in range(ln)]
id.reverse()
cnt = 1
for url in lst[ln//2:]:#负责下载后半部分
r = requests.get(url)
pic_path = path + '\\' + f'{keyword}_pic_{id.pop(0)}.jpg'
with open(pic_path, 'wb+') as ff:
ff.write(r.content)
ff.close()
op1 = cnt*120//ln
en = 60 - op1
opp, enn = '-'*op1, '*'*en
print(f'\r[2]下载ing:已下{cnt}/{ln//2}张,[{opp}>{enn}] {(2 * cnt) / len(lst):.1%}', end='')
cnt += 1
小说明:这里就不传参数了,直接把列表定义为全局变量
线程的代码,还有博客参考如下
#大家可以参考下面给出的优秀博客
threads = []
th1 = threading.Thread(target=download_pic1)
threads.append(th1)
th2 = threading.Thread(target=download_pic2)
threads.append(th2)
for th in threads:
th.setDaemon(True)
th.start()
th.join()
参考博客链接
[博主 n_laomomo 原创]----Python多线程threading用法
较详细介绍
【博主 DrStream 原创】----python:threading.Thread类的使用详解
奉上完整代码
- 注意:爬取的时候会出现超时,然后就over了,除了使用try来’试错‘,还可以适当用一下time库的sleep()
import requests
from time import sleep
import os
import os.path as op
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait as ww
import threading
def get_list(basic_url):
'''
#这里是无界面浏览器相关操作,不想要弹出界面的话,
#把下边那行换成这些就ok
browser_options = webdriver.ChromeOptions()
browser_options.add_argument('--headless')
browser = webdriver.Chrome(options=browser_options)
'''
browser = webdriver.Chrome() #这行就是那行(手动滑稽)
wait = ww(browser, 20)
try:
browser.get(basic_url)
print('访问成功!!')
sleep(1)
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#rightModule > div.search-wrapper > div > div > div > input')))
click = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#rightModule > div.search-wrapper > div > div > div > div > button')))
input.send_keys(keyword)
sleep(2)
click.click()
sleep(1)
print('搜索成功!')
browser.switch_to.window(browser.window_handles[1])
for i in range(0, 2001, 250):
browser.execute_script(f'window.scrollBy(0, {i})')
print(f'\r加载中。。。{i/2000:.1%}', end='')
sleep(3)
print('')
clicks = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.link.title')))
cnt = 0
want = 10 ## 爬取页面数
for clc in clicks[: want]:
clc.click()
sleep(2)
cnt += 1
browser.switch_to.window(browser.window_handles[1])
print(f'\r已打开{cnt}个界面,比例{cnt/want:.2%}', end='')
print()
for num in range(want):
browser.switch_to.window(browser.window_handles[num + 2])
try:
img = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'img[src]'))) #.article-content div .pgc-img img[src]
except:
pass
for mg in img:
url = mg.get_attribute('src')
if url.startswith('http://p'):
lst.append(url)
except Exception as t:
print(t)
def download_pic1():
path = r'C:\Users\PXO\Desktop\杂\Toutiao_pic\\' + keyword
if not op.exists(path):
os.mkdir(path)
ln = len(lst)
id = [i for i in range(ln)]
cnt = 1
for url in lst[:ln//2]:
r = requests.get(url)
pic_path = path + '\\' + f'{keyword}_pic_{id.pop(0)}.jpg'
with open(pic_path, 'wb+') as ff:
ff.write(r.content)
ff.close()
op1 = cnt*120//ln
en = 60 - op1
opp, enn = '-'*op1, '*'*en
print(f'\r[1]下载ing:已下{cnt}/{ln//2}张,[{opp}>{enn}] {(2 * cnt) / len(lst):.1%}', end='')
cnt += 1
def download_pic2():
path = r'C:\Users\PXO\Desktop\杂\Toutiao_pic\\' + keyword
if not op.exists(path):
os.mkdir(path)
ln = len(lst)
id = [i for i in range(ln)]
id.reverse()
cnt = 1
for url in lst[ln//2:]:
r = requests.get(url)
pic_path=path+'\\'+f'{keyword}_pic_{id.pop(0)}.jpg'
with open(pic_path, 'wb+') as ff:
ff.write(r.content)
ff.close()
op1 = cnt*120//ln
en = 60 - op1
opp, enn = '-'*op1, '*'*en
print(f'\r[2]下载ing:已下{cnt}/{ln//2}张,[{opp}>{enn}] {(2 * cnt) / len(lst):.1%}', end='')
cnt += 1
def main():
global keyword, lst
lst = []
keyword = '鬼刀'
basic_url = 'https://www.toutiao.com/'
get_list(basic_url)
threads = []
th1=threading.Thread(target=download_pic1)
threads.append(th1)
th2=threading.Thread(target=download_pic2)
threads.append(th2)
for th in threads:
th.setDaemon(True)
th.start()
th.join()
main()