TensorRT部署模型基本步骤(C++)
文章目录
前言
经典的一个TensorRT部署模型步骤为:onnx模型转engine、读取本地模型、创建推理引擎、创建推理上下文、创建GPU显存缓冲区、配置输入数据、模型推理以及处理推理结果(后处理)。
一、onnx模型转engine
目前多种模型框架都将onnx模型当作中间转换格式,是的该模型结构变得越来越通用,因此TensorRT目前主要在更新的就是针对该模型的转换。TensorRT是可以直接读取engine文件(缺点是:读取engine要求是相同TensorRT版本和相同的平台),对于onnx模型需要进行一些列转换配置,转为engine引擎才可以进行后续的推理,因此在进行模型推理前,需要先进行模型的转换。
1.基于C++代码生成engine
void onnx_to_engine(std::string onnx_file_path, std::string engine_file_path, int type) {
// 构建器,获取cuda内核目录以获取最快的实现
// 用于创建config、network、engine的其他对象的核心类
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
// 解析onnx网络文件
// tensorRT模型类
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
// onnx文件解析类
// 将onnx文件解析,并填充rensorRT网络结构
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, gLogger);
// 解析onnx文件
parser->parseFromFile(onnx_file_path.c_str(), 2);
for (int i = 0; i < parser->getNbErrors(); ++i) {
std::cout << "load error: " << parser->getError(i)->desc() << std::endl;
}
printf("tensorRT load mask onnx model successfully!!!...\n");
// 创建推理引擎
// 创建生成器配置对象。
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
// 设置最大工作空间大小。
config->setMaxWorkspaceSize(16 * (1 << 20));
// 设置模型输出精度
if (type == 1) {
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
if (type == 2) {
config->setFlag(nvinfer1::BuilderFlag::kINT8);
}
// 创建推理引擎
nvinfer1::ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
// 将推理银枪保存到本地
std::cout << "try to save engine file now~~~" << std::endl;
std::ofstream file_ptr(engine_file_path, std::ios::binary);
if (!file_ptr) {
std::cerr << "could not open plan output file" << std::endl;
return;
}
// 将模型转化为文件流数据
nvinfer1::IHostMemory* model_stream = engine->serialize();
// 将文件保存到本地
file_ptr.write(reinterpret_cast<const char*>(model_stream->data()), model_stream->size());
// 销毁创建的对象
model_stream->destroy();
engine->destroy();
network->destroy();
parser->destroy();
std::cout << "convert onnx model to TensorRT engine model successfully!" << std::endl;
}
2.基于trtexec.exe命令行生成
备注:
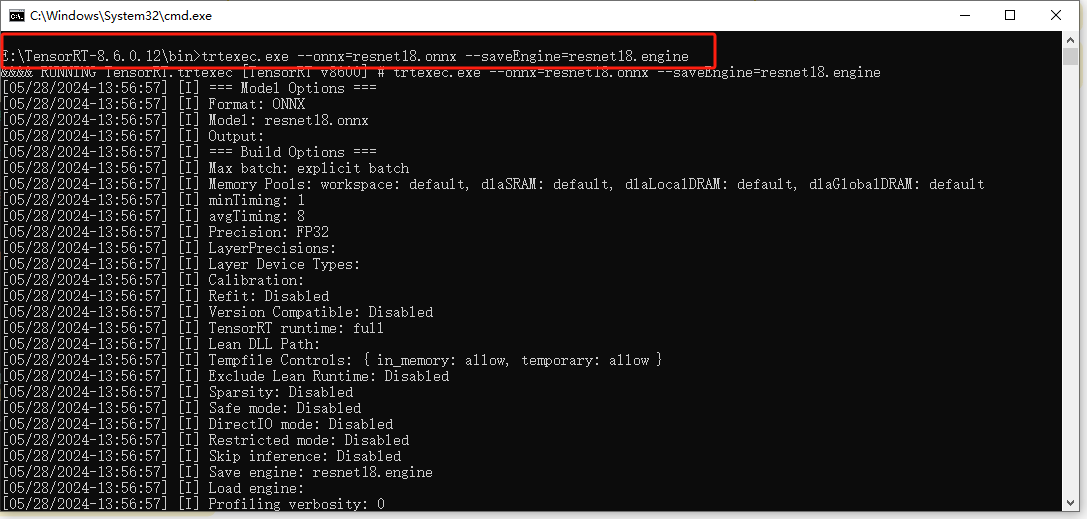
- –onnx=“filepath” filepath是onnx文件路径
- –saveEngine=“filepath” filepath是保存engine文件路径
二、读取本地模型
读取onnx转换的engine二进制文件,将模型文件信息读取到内存中。由于engine保存了模型的信息以及电脑的(TensorRT)配置环境信息,所以如果要将模型部署在其他电脑上,要保证电脑的配置环境以及平台(windows/linux/macos)是否相同。
std::string enginepath = "E:/TensorRT-8.6.0.12/bin/resnet18.engine"; //读取二进制文件engine的路径
std::ifstream file(enginepath, std::ios::binary); // 以二进制方式打开
char* trtModelStream = NULL; // 定义一个字符指针,用于读取engine文件数据
int size = 0; // 存储二进制文件字符的数量
if (file.good()) {
file.seekg(0, file.end); //将文件指针移动到文件末尾
size = file.tellg(); //获取当前文件指针的位置,即文件的大小
file.seekg(0, file.beg); //文件指针移回文件开始处
trtModelStream = new char[size]; //分配足够的内存储存文件内容
assert(trtModelStream); //检查内存是否分配成功
file.read(trtModelStream, size); //读取文件信息,并存储在trtModelStream
file.close(); //关闭文件
}
三、创建推理引擎
首先需要初始化日志记录接口类,该类用于创建后续反序列化引擎使用;然后创建反序列化引擎,其主要作用是允许对序列化的功能上不安全的引擎进行反序列化,接下调用反序列化引擎来创建推理引擎,这一步只需要输入上一步中读取的模型文件数据以及长度即可。
// 日志记录接口
Logger logger;
// 反序列化引擎
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);
assert(runtime != nullptr);
// 推理引擎
nvinfer1::ICudaEngine* engine = runtime->deserializeCudaEngine(model_stream, size);
assert(engine != nullptr);
四、创建推理上下文
创建可执行的IExecutionContent实例 - createExecutionContext,为后面进行模型推理的类。
nvinfer1::IExecutionContext* context = engine->createExecutionContext();
assert(context != nullptr);
delete[] trtModelStream ; // 释放内存
五、创建GPU显存缓冲区
TensorRT是利用英伟达显卡(GPU)进行模型推理的,但是我们的推理数据以及后续处理数据是在内存(CPU)中实现的,因此需要创建显存缓冲区,用于输入推理数据以及读取推理结果数据。
// 创建GPU显存缓冲区
void** data_buffer = new void* [num_ionode];
// 创建GPU显存输入缓冲区
// getBindingDimensions函数获取指定索引的绑定维度信息,然后从中提取高度和宽度的值
int input_node_index = engine->getBindingIndex(input_node_name);
cudaMalloc(&(data_buffer[input_node_index]), input_data_length * sizeof(float));
// 创建GPU显存输出缓冲区
int output_node_index = engine->getBindingIndex(output_node_name);
cudaMalloc(&(data_buffer[output_node_index]), output_data_length * sizeof(float));
六、 配置输入数据
配置输入数据时只需要调用cudaMemcpyAsync()方法,便可将cuda流数据加载到与i里模型上。但数据需要根据模型要求进行预处理,除此以外需要将数据结果加入到cuda流中。
// 创建输入cuda流
cudaStream_t stream;
cudaStreamCreate(&stream);
/*
*******输入图像预处理*******
*/
// HWC => CHW,转换成张量格式
cv::Mat tensor = ::dnn::blobFromImage(blob);
// 输入数据由内存到GPU显存
cudaMemcpyAsync(data_buffer[input_node_index], tensor.ptr<float>(), input_data_length * sizeof(float), cudaMemcpyHostToDevice, stream);
七、模型推理
context->enqueueV2(data_buffer, stream, nullptr);
八、获得输出数据
最后处理数据是在内存上实现的,首先需要将数据由显存读取到内存中。
std::vector<float> prob;
// 创建临时缓存输出
prob.resize(output_h * output_w);
// GPU显存到内存
cudaMemcpyAsync(prob.data(), data_buffer[output_node_index], output_data_length * sizeof(float), cudaMemcpyDeviceToHost, stream);
/*
*******输出图像后处理*******
*/
总结
本文主要介绍了TensorRT+C++部署的基本步骤,欢迎阅读交流。