PyTorch 2.0 新特性
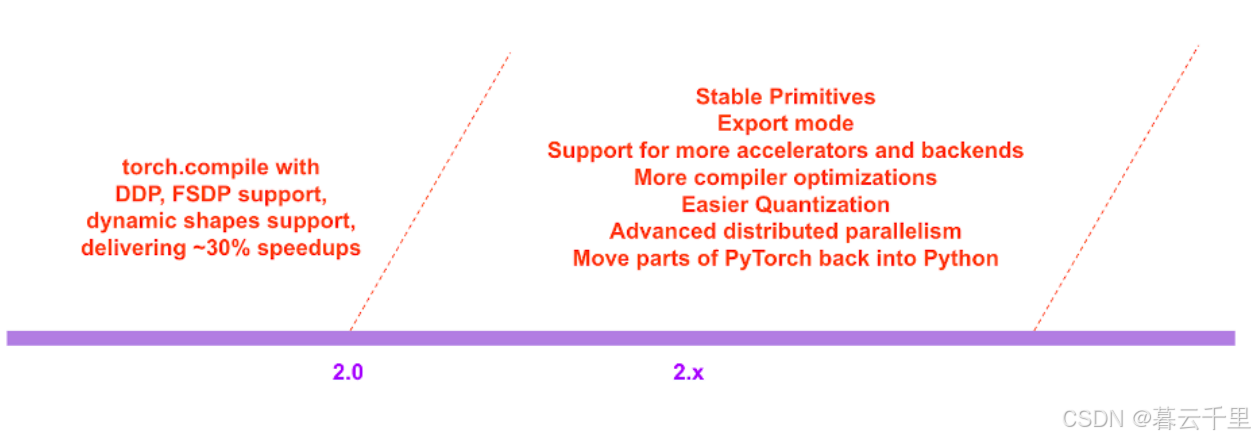
1. 未来版本
2. PyTorch编译过程

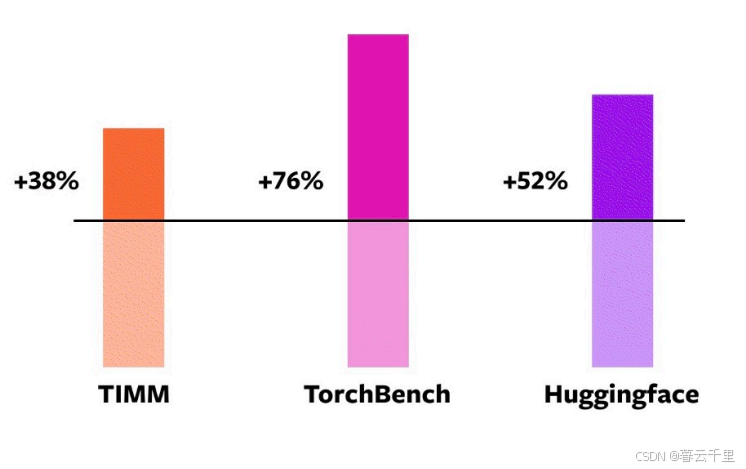
3. 模型泛化性测试
46 models from HuggingFace Transformers:
其最著名的特色是其为自然语言处理应用构建的Transformers库,以及它的平台,该平台允许用户分享机器学习模型和数据集。这个特性使得Hugging Face在人工智能社区中独树一帜,促进了研究者与开发者之间的知识共享与协作。通过Transformers库,用户可以轻松访问和使用最先进的自然语言处理技术,而开放的模型和数据集分享平台则进一步加速了AI领域的创新与发展。
61 models from TIMM:
这是由Ross Wightman收集的一系列前沿的PyTorch图像模型。这些模型代表了在计算机视觉领域使用PyTorch框架所能达到的最新技术水平。Ross Wightman是一位知名的深度学习专家,他在图像识别、分类和目标检测等任务上开发了许多高性能的模型,对推动PyTorch生态系统的丰富性和多样性做出了重要贡献。
56 models from TorchBench:
这是一套精心挑选的来自GitHub上广受欢迎的代码库集合。这套集合涵盖了各种热门项目和技术栈,旨在为开发者提供高质量的代码示例和资源,促进学习和项目开发。
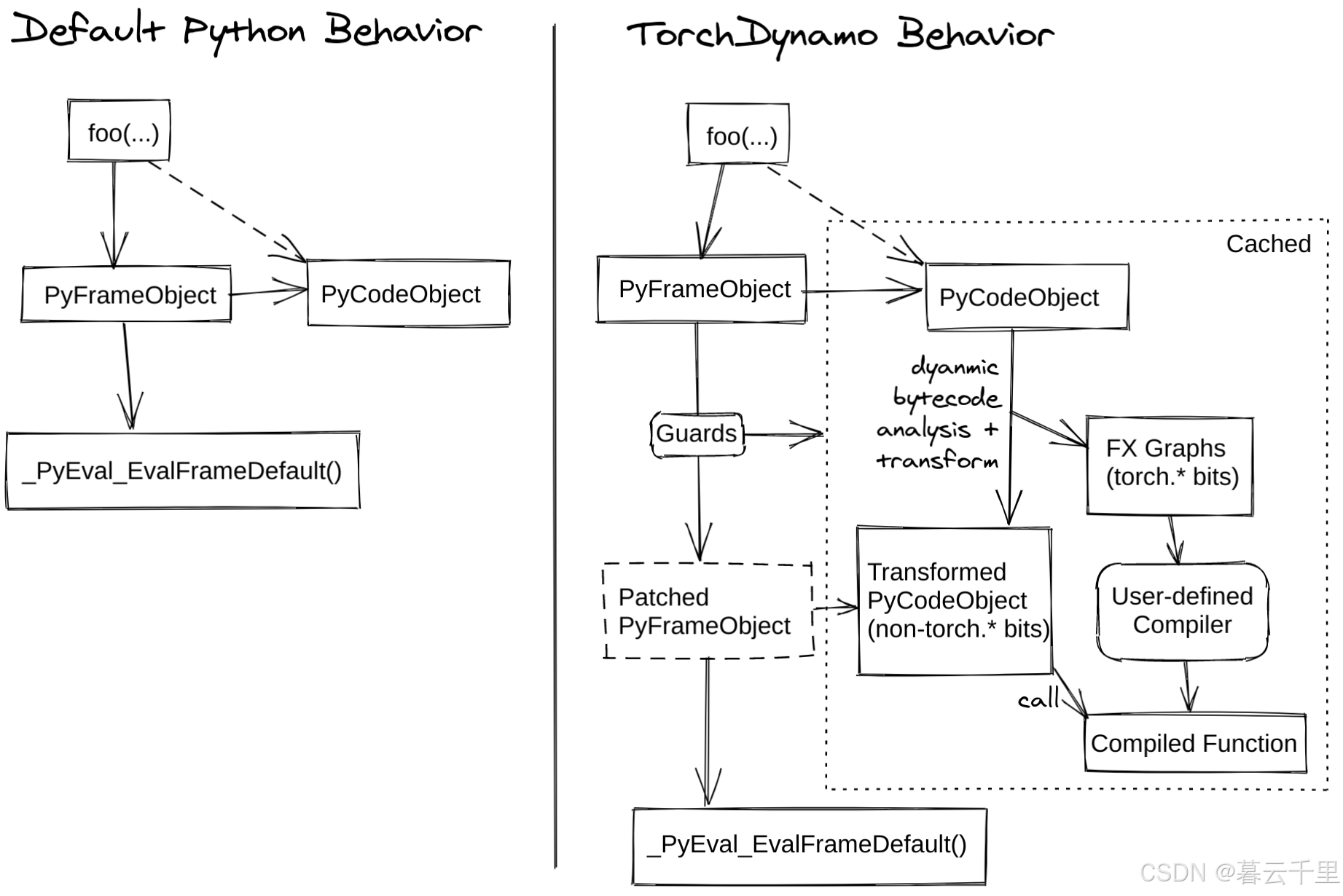
4. TorchDynamo:可靠且快速地获取图结构
TorchDynamo 是一项革新性的技术,专注于以高效率和高度可靠性捕获计算图(Graphs)。在深度学习领域,尤其是动态图执行环境中,TorchDynamo 的出现解决了长期以来存在的难题——如何在保证速度的同时确保图的准确捕捉。这项技术不仅大幅提升了图获取的速度,还显著增强了其稳定性,使得深度学习模型的训练和推理过程更加流畅和高效。
通过采用先进的算法和优化策略,TorchDynamo 能够在几乎不增加额外开销的情况下,实现对计算图的快速且准确捕获。这意味着开发者无需过多关注底层细节,即可享受到性能提升带来的好处。此外,TorchDynamo 还兼容多种深度学习框架和模型,为用户提供了一个灵活且强大的工具,极大地简化了模型部署和优化流程。
相比之下,TorchScript以及其他类似工具往往难以在一半以上的时间内成功捕获图形,而且通常伴随着较大的运行开销。然而,TorchDynamo却能够以高达99%的成功率正确、安全地捕获图形,而且几乎不增加任何额外开销,这一切都无需对原始代码进行任何修改。
参考: 什么是 TorchDynamo
5. AOTAutograd:利用自动微分机制提前生成计算图
AOTAutograd 是一项创新技术,它巧妙地重用了 PyTorch 中的 Autograd 自动微分系统,用于生成所谓的“提前计算图”(ahead-of-time graphs)。在传统的自动微分框架中,计算图是在运行时动态构建的,这种方式虽然灵活,但在某些场景下可能会导致性能上的瓶颈。
通过 AOTAutograd,开发者能够在编译阶段就预先构建好计算图,这种做法尤其适用于那些计算密集型且模式固定的任务。由于计算图在执行前已经确定,因此可以进行更深层次的优化,如常量折叠、算子融合等,从而显著提高执行效率。此外,提前生成的计算图还能更好地支持静态分析和编译器优化,有助于减少运行时的开销。
对于 PyTorch 2.0
对于 PyTorch 2.0,我们深知加速训练过程的重要性。因此,仅仅捕获用户级别的代码是不够的,我们还需要捕获反向传播过程。同时,我们知道要充分利用经过实战考验的 PyTorch 自动梯度系统。AOTAutograd 通过 PyTorch 的 torch_dispatch 扩展机制,追踪我们的自动梯度引擎,使得我们可以提前捕捉到反向传播过程。这使我们能够使用 TorchInductor 对前向和反向传播过程都进行加速。
具体来说,在 PyTorch 2.0 中,为了提升训练速度,我们认识到不仅要能够记录用户编写的代码逻辑,而且还要能够记录并处理反向传播的计算流程,这是深度学习训练过程中至关重要的部分。为了达到这个目标,我们决定继续沿用 PyTorch 原有的、经过大量实际应用验证的自动梯度(autograd)系统,确保其稳定性和正确性。
AOTAutograd 采用了 PyTorch 提供的 torch_dispatch 机制,这是一种允许用户自定义运算符实现的扩展点。通过这一机制,AOTAutograd 能够深入到自动梯度引擎内部,追踪和记录所有参与反向传播的运算细节。这样一来,原本在运行时动态构建的反向传播图,现在可以在训练开始之前就完成构建和优化,即所谓的“提前时间”(Ahead-Of-Time, AOT)方式。
借助 TorchInductor,一种专门针对 PyTorch 的高性能 JIT 编译器,我们对捕获到的前向和反向传播过程进行了深度优化。TorchInductor 不仅能识别并消除冗余计算,还能进行算子融合、循环展开等高级优化策略,显著提高了计算效率。因此,无论是前向传播还是反向传播,我们都能享受到更快的执行速度和更低的内存消耗,大大提升了整个训练流程的性能表现。
6. TorchInductor:利用定义即运行(Define-by-Run)的中间表示(IR)实现快速代码生成
TorchInductor 是一项旨在显著提升代码生成速度的技术,它巧妙地利用了定义即运行(Define-by-Run)的中间表示(Intermediate Representation, IR)。在深度学习框架中,中间表示是一种将用户代码转换为更底层、更易于优化形式的抽象表示。传统上,这种转换和优化工作通常在每次运行时动态完成,虽然提供了灵活性,但可能会影响性能。
TorchInductor 通过采用定义即运行的 IR,能够在编译阶段就对用户的 PyTorch 代码进行分析和优化,生成更为高效的目标代码。这种方法的好处在于,它能在保持动态执行灵活性的同时,预先进行代码优化,避免了运行时不必要的计算和内存开销,从而显著提高了执行效率。
当用户使用 PyTorch 编写神经网络模型时,TorchInductor 会记录下模型的运行轨迹,包括所有的操作和数据流。然后,它利用这些信息构建一个中间表示,这个中间表示不仅包含了模型的结构信息,还反映了实际运行过程中的数据依赖关系。接下来,TorchInductor 会对这个中间表示进行一系列优化,例如算子融合、常数折叠、并行化等,最终生成优化后的低级代码,可以直接在目标硬件上高效执行。
7. PrimTorch:稳定的基础算子
PrimTorch 是一个专注于提供稳定且基础的运算操作符(算子)的项目。在深度学习和机器学习领域,算子是构成各种复杂模型的基本构建块。它们可以是一些简单的数学运算,如加法、乘法,或者是更复杂的线性代数操作,如矩阵乘法、卷积等。
PrimTorch 的目标是确保这些基础算子的实现既稳定又高效,能够为更高级别的框架和库提供坚实的基础。稳定在这里意味着算子的行为在不同版本之间应该保持一致,不会因为更新而引入新的错误或者破坏现有的功能。此外,稳定性还包括算子在各种边界条件下的健壮性和准确性,确保即使在极端情况下也能得到正确的结果。
为了达到这一目标,PrimTorch 可能会采取一些策略,比如:
-
严格测试:对每一个算子进行详尽的测试,包括单元测试和集成测试,确保其正确性和鲁棒性。
-
代码审查:所有贡献的代码都经过同行评审,确保代码质量符合高标准。
-
文档完善:提供详细的文档说明每个算子的功能、参数以及使用方法,帮助用户正确使用。
-
性能优化:不断优化算子的实现,减少计算资源的消耗,提高执行效率。
-
兼容性保证:确保 PrimTorch 算子与主流的深度学习框架和库兼容,如 PyTorch、TensorFlow 等。
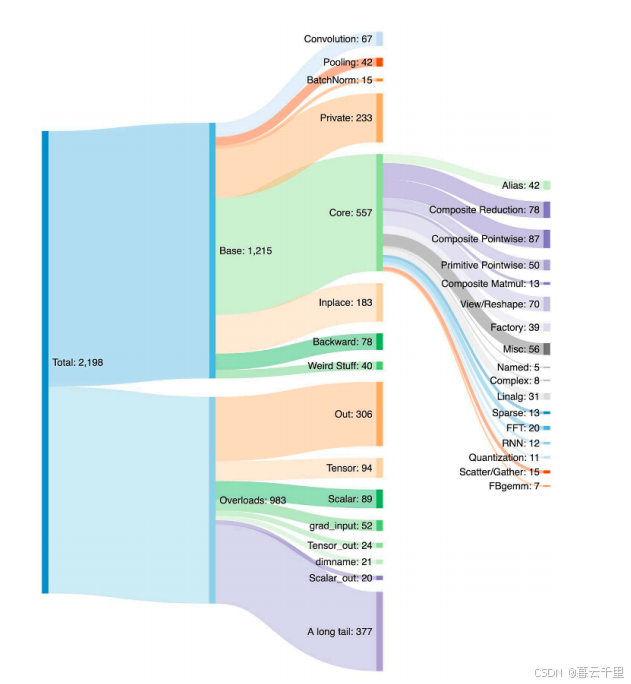
为 PyTorch 编写后端需要考虑到每个运算符的各种重载,PyTorch 涵盖了超过 1200 种运算符,如果将所有变体考虑在内,则数量超过 2000 种。
主要存在两类运算符:
- Prim 运算符:大约包含 250 种,这些运算符相对较低级。它们特别适合编译器使用,因为它们的级别足够低,需要将多个运算符融合在一起才能获得良好的性能。
- ATen 运算符:大约有 750 种标准运算符,非常适合直接导出。这类运算符适用于那些已经在 ATen 层级上集成的后端,或是那些不需要通过编译来从像 Prim 运算符这样的低级运算符集中恢复性能的后端。
编写 PyTorch 后端的难点在于需要支持大量的运算符,并确保与不同层级的运算符兼容。Prim 运算符因其低级特性,更适合编译优化,但需要额外的融合步骤以提升性能;而 ATen 运算符则更加标准化,可以直接在现有后端或不需要底层运算符融合的环境中使用,提供了更直接的集成路径。理解这两类运算符的区别和适用场景,对于开发高效且兼容的 PyTorch 后端至关重要。
参考:https://pytorch.org/get-started/pytorch-2.0/