Spark Structured Streaming 结构化流
Structured Streaming是一个构建在Spark SQL基础上可靠具备容错处理的流处理引擎。Structured Streaming提供快速,可扩展,容错,端到端的精确一次流处理,而无需用户推理流式传输。
流数据处理的三种语义:
- 最少一次(at least once): 流数据中的记录最少会被处理一次(1-n)
- 最多一次(at most once): 流数据中的记录最多会被处理一次(0-1)
- 精确一次(at exactly once):流数据中的记录只能被处理一次(1)
在内部,默认情况下,Structured Streaming查询和处理使用micro-batch(微批)处理引擎。它将数据流作为一系列小批量作业进行处理,从而实现低至100毫秒的端到端延迟和完全一次的容错保证。在Spark 2.3版本后,又提供了一个低延迟的处理模式称为Continuous Processing(持续处理),可以实现端对端低至1毫秒和最少一次的容错保证。
一、Quick Example
流数据单词计数
package example8
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
object StructuredStreamingQuickStart {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[4]").setAppName("StructuredNetworkWordCount")
val sc = new SparkContext(conf)
sc.setLogLevel("FATAL")
val spark = SparkSession.builder().getOrCreate()
import spark.implicits._
// 构建DataFrame
val df = spark.readStream.format("socket").option("host","gaozhy").option("port","9999").load()
// 转换为Dataset 进行算子操作
val words = df.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
val query = wordCounts.writeStream.outputMode("complete").format("console").start()
query.awaitTermination()
}
}
运行结果:
-------------------------------------------
Batch: 0
-------------------------------------------
+-----+-----+
|value|count|
+-----+-----+
+-----+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+-----+-----+
|value|count|
+-----+-----+
| AA| 3|
| CC| 1|
| BB| 2|
+-----+-----+
-------------------------------------------
Batch: 2
-------------------------------------------
+-----+-----+
|value|count|
+-----+-----+
| AA| 5|
| CC| 1|
| BB| 2|
+-----+-----+
...
spark streaming结构化流的编程步骤:
- 构建Spark Session对象【不光是SQL的入口,也是Structured Streaming应用入口】
- spark#readStream方法构建数据流的DF
- 数据流的DF应用SQL计算或者将DF转为DS应用计算操作
- 数据流的计算结果需要 DF.writeStream.format(输出格式).outputMode(输出模型)
- 启动 query#start & awaittermnation
Structured Streaming程序模型
Structured Streaming的核心是将流式的数据看成一张不断增加的数据库表,这种流式的数据处理模型类似于数据块处理模型,你可以把静态数据库表的一些查询操作应用在流式计算中,Spark运行这些标准的SQL查询,从不断增加的无边界表中获取数据。
基本概念
输入数据流视为"Input Table"(输入表)

在输入表上的每一次查询都会产生"Result Table"(输出表)
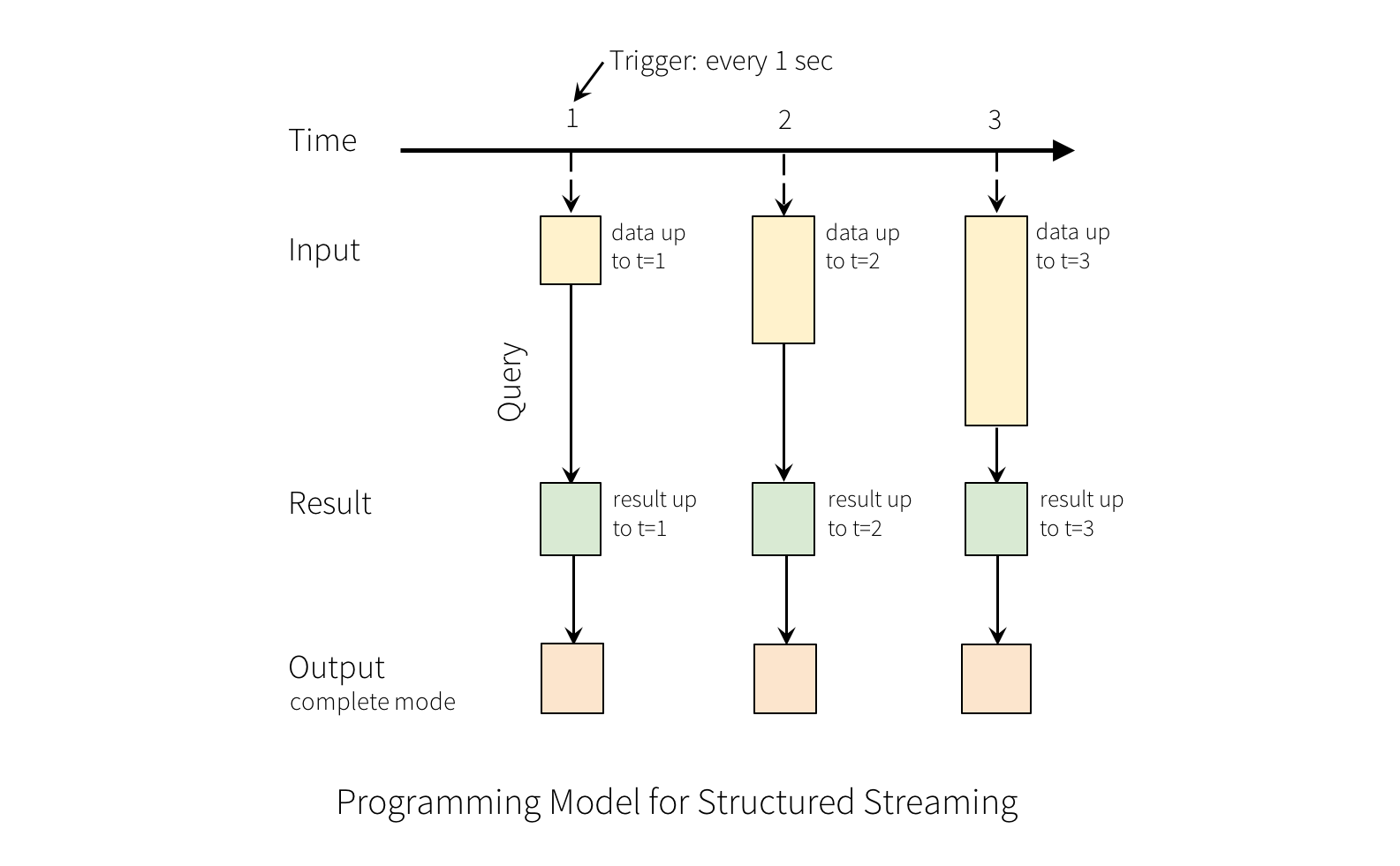
“Output”(输出)定义了如何将结果写出到外部的存储系统,有三种不同的写出模式:
- Complete Mode: 整个更新的结果集都会写入外部存储。整张表的写入操作将由外部存储系统的连接器Connector。
- Append Mode:当时间间隔触发时,只有在Result Table中新增加的数据行会被写入外部存储。这种方式只适用于结果集中已经存在的内容不希望发生改变的情况下,如果已经存在的数据会被更新,不适合适用此种方式。
- Update Mode: 当时间间隔触发时,只有在Result Table中被更新的数据才会被写入外部存储系统。注意,和Complete Mode方式的不同之处是不更新的结果集不会写入外部存储。如果查询不包含aggregations, 将会和append模式相同
第一个lines DataFrame对象是一张数据输入的Input Table,最后的WordCounts DataFrame是一个结果集Result Table。在lines DataFrame数据流之上的查询产生了wordCounts的表示方式和在静态的Static DataFrame上的使用方式相同。然而,Spark会监控socket连接,获取新的持续不断产生的数据。当新的数据产生时,Spark将会在新数据上运行一个增量的counts查询,并且整合新的counts和之前已经计算出来的counts,获取更新后的counts,如下所示:

这个模型和其他的流式数据处理引擎是非常不一样的,许多系统要求用户自己维护运行的聚合等,从而需要熟悉容错机制和数据保障机制(at-least-once, or at-most-once, or exactly-once)。在本模型中,Spark负责更新结果集ResultTable,从而解放了用户。
Fault Tolerance Semantics【容错语义】
Structure Streaming通过checkpoint和write ahead log去记录每一次批处理的数据源的偏移量(区间),可以保证在失败的时候可以重复的读取数据源。其次Structure Streaming也提供了Sink的幂等写的特性(在编程中一个操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同), 因此Structure Streaming实现end-to-end exactly-once 语义的故障恢复。
API using Datasets and DataFrames
从Spark2.0以来,DataFrames 和 Datasets可以表示静态的,有界的数据,也可以表示流式的,无界的数据。和静态的相似,您可以使用通用入口点SparkSession(Scala / Java / Python / R docs)从流式source创建流式DataFrames/Datasets,并且可以应用和静态数据相同的操作。
二、创建流式DataFrame和流式Datasets
Streaming DataFrames可以通过SparkSession.readStream()返回的DataStreamReader接口(Scala / Java / Python文档)创建。
Input Sources
常见的内置Sources
- File source : 读取指定目录下的文件作为流数据,支持的文件格式有:text、csv、json、parquet、orc等
- Kafka source(常用): 从kafka读取数据
- Socket source (测试使用):从套接字连接读取UTF-8编码的文本数据
| Source | Options | Fault-tolerant | Notes |
|---|---|---|---|
| File source | 1. **path:**路径到输入目录,并且与所有文件格式通用。2. **maxFilesPerTrigger:**每个时间间隔触发器中要考虑的最大新文件数(默认值:无最大值)3. **latestFirst:**是否首先处理最新的新文件,当有大量的文件积压(default:false)时很有用。4. **fileNameOnly:**是否仅根据文件名而不是完整路径检查新文件(默认值:false)。将此设置为“true”,以下文件将被视为相同的文件,因为它们的文件名“dataset.txt”是相同的:· “file:///dataset.txt” · “s3://a/dataset.txt” | Yes | 支持glob路径,但不支持多个逗号分隔的poths/ globs。 |
| Socket Source | **host:**主机连接,必须指定 **port:**要连接的端口,必须指定 | No | |
| Kafka Source | 详细查看kafka整合教程 | Yes |
Some examples:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>2.4.4</version>
package example8
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.StructType
object StructuredStreamingSource {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[4]").setAppName("StructuredNetworkWordCount")
val sc = new SparkContext(conf)
sc.setLogLevel("FATAL")
val spark = SparkSession.builder().getOrCreate()
import spark.implicits._
// =====================================CSV===========================================
/*
val df = spark.readStream
.format("csv")
//.option("sep",";")
.schema(new StructType().add("id", "integer").add("name", "string").add("salary", "double"))
.csv("/Users/gaozhy/data/csv")
*/
// =====================================CSV===========================================
// =====================================json===========================================
/*
val df = spark.readStream
.format("json")
.schema(new StructType().add("id","integer").add("name","string").add("salary","float"))
.json("/Users/gaozhy/data/json")
*/
// =====================================json===========================================
//df.createOrReplaceTempView("t_user")
/*
spark.sql("select * from t_user")
.writeStream
.outputMode("append")
.format("console")
.start()
.awaitTermination()
*/
// =====================================kafka===========================================
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "gaozhy:9092")
.option("startingOffsets", """{"baizhi":{"0":-2}}""") // 指定偏移量消费
.option("subscribe", "baizhi")
.load()
val kafka = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)", "topic", "partition")
.as[(String, String, String, Int)]
kafka.createOrReplaceTempView("t_kafka")
// spark.sql("select * from t_kafka")
// .writeStream
// .format("console")
// .outputMode("append")
// .start()
// .awaitTermination()
spark.sql("select count(*) from t_kafka group by partition")
.writeStream
.format("console")
.outputMode("complete")
.start()
.awaitTermination()
}
}
Output Modes
下面是几种输出模式:
- Append mode (default) - 这是默认模式,其中只有从上次触发后添加到结果表的新行将被输出到sink。 只有那些添加到“结果表”中并且从不会更改的行的查询才支持这一点。 因此,该模式保证每行只能输出一次(假定容错sink)。 例如,只有select,where,map,flatMap,filter,join等的查询将支持Append模式。
- Complete mode -每个触发后,整个结果表将被输出到sink。 聚合查询支持这一点。
- Update mode - (自Spark 2.1.1以来可用)只有结果表中自上次触发后更新的行才会被输出到sink。
不同类型的流式查询支持不同的输出模式。 以下是兼容性信息。
| Query Type | Supported Output Modes | 备注 |
|---|---|---|
| 没有聚合的查询 | Append, Update | 不支持完整模式,因为将所有数据保存在结果表中是不可行的。 |
| 有聚合的查询:使用watermark对event-time进行聚合 | Append, Update, Complete | 附加模式使用watermark 来降低旧聚合状态。 但是,窗口化聚合的输出会延迟“withWatermark()”中指定的晚期阈值,因为模式语义可以在结果表中定义后才能将结果表添加到结果表中(即在watermark 被交叉之后)。 有关详细信息,请参阅后期数据部分。更新模式使用水印去掉旧的聚合状态。完全模式不会丢弃旧的聚合状态,因为根据定义,此模式保留结果表中的所有数据。 |
| 有聚合的查询:其他聚合 | Complete, Update | 由于没有定义watermark (仅在其他类别中定义),旧的聚合状态不会被丢弃。不支持附加模式,因为聚合可以更新,从而违反了此模式的语义。 |
Output Sinks
有几种类型的内置输出sinks
- File sink - Stores the output to a directory
- Kafka sink - Stores the output to one or more topics in Kafka.
- Foreach sink - Runs arbitrary(任意) computation on the records in the output.
- Console sink (for debugging) - Prints the output to the console/stdout every time there is a trigger
| sink | Supported Output Modes | Options | Fault-tolerant | Notes |
|---|---|---|---|---|
| File Sink | Append | path:输出目录的路径,必须指定。 maxFilesPerTrigger:每个触发器中要考虑的最大新文件数(默认值:无最大值) latestFirst:是否首先处理最新的新文件,当有大量的文件积压(default:false)时很有用 有关特定于文件格式的选项,请参阅DataFrameWriter(Scala / Java / Python)中的相关方法。 例如。 对于“parquet”格式选项请参阅DataFrameWriter.parquet() | yes | 支持对分区表的写入。 按时间划分可能有用。 |
| Foreach Sink | Append, Update, Compelete | None | 取决于ForeachWriter的实现 | 更多细节在下一节 |
| Console Sink | Append, Update, Complete | numRows:每次触发打印的行数(默认值:20)truncate:输出太长是否截断(默认值:true) | no | |
| Memory Sink | Append, Complete | None | 否。但在Complete模式下,重新启动的查询将重新创建整个表。 | 查询名就是表名 |
package com.baizhi
import org.apache.spark.sql.{ForeachWriter, Row, SparkSession}
import org.apache.spark.sql.streaming.OutputMode
import redis.clients.jedis.Jedis
/**
* 如何通过不同的sink构建结构化流计算结构的输出
*/
object SparkStructuredStreamingForOutputSink {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("input source")
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
import spark.implicits._
//--------------------------------kafka【重点】-----------------------------------
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092")
.option("startingOffsets", """{"baizhi":{"0":-2}}""") // 指定消费baizhi topic的0号分区的earliest消费方式
// 指定偏移量消费 In the json, -2 as an offset can be used to refer to earliest, -1 to latest.
.option("subscribe", "baizhi")
.load
// kafka record 转换为要求的类型
// val ds = df
// .selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)", "CAST(topic AS STRING)", "CAST(partition AS INT)", "CAST(timestamp AS LONG)")
// .as[(String, String, String, Int, Long)] // key value topic partition Long
//
// ds.createOrReplaceTempView("t_kafka")
//
// val text = spark.sql("select key as k,value as v,topic as t,partition as p, timestamp as ts from t_kafka")
//--------------------------------kafka【重点】-----------------------------------
// text
// .writeStream
// .format("console")
// .outputMode(OutputMode.Append())
// .start()
// .awaitTermination()
//===================================文件【输出模式:只支持Append】===========================================
// text
// .writeStream
// .format("json") // 文件格式 CSV JSON parquet ORC等
// .outputMode(OutputMode.Append())
// .option("checkpointLocation","hdfs://Spark:9000/checkpoint1") // 检查点path 用以故障恢复
// .option("path","file:///D://result") // path支持本地和HDFS文件系统路径
// .start()
// .awaitTermination()
// text
// .writeStream
// .format("csv") // 文件格式 CSV JSON parquet ORC等
// .outputMode(OutputMode.Append())
// .option("checkpointLocation", "hdfs://Spark:9000/checkpoint2") // 检查点path 用以故障恢复
// .option("path", "file:///D://result2") // path支持本地和HDFS文件系统路径
// .start()
// .awaitTermination()
//===================================Kafka【输出模式:Append | Updated | Completed】=========================
// val ds = df
// .selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)", "CAST(topic AS STRING)", "CAST(partition AS INT)", "CAST(timestamp AS LONG)")
// .as[(String, String, String, Int, Long)].flatMap(_._2.split(" ")).map((_, 1)) // key value topic partition Long
//
// ds.createOrReplaceTempView("t_kafka")
//
// val text = spark.sql("select _1 as word,count(_2) as num from t_kafka group by _1")
//
// text
// // .selectExpr("CAST(k AS STRING) as key", "CAST(v AS STRING) as value") // 对输出到kafka的数据定义key 和 value信息
// .selectExpr("CAST(word AS STRING) as key", "CAST(num AS STRING) as value") // 对输出到kafka的数据定义key 和 value信息
// .writeStream
// .format("kafka") // 文件格式 CSV JSON parquet ORC等
// // .outputMode(OutputMode.Append())
// .outputMode(OutputMode.Update())
// .option("checkpointLocation", "hdfs://Spark:9000/checkpoint4") // 检查点path 用以故障恢复
// .option("kafka.bootstrap.servers", "HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092") // kafka集群信息
// .option("topic", "result") // 指定计算结果的保存topic
// .start()
// .awaitTermination()
/*
[root@HadoopNode02 kafka_2.11-2.2.0]# bin/kafka-console-consumer.sh --topic result --bootstrap-server HadoopNode01:9092,HadoopNode02:9092,HadoopNode03:9092 --property print.key=true
*/
//===================================Foreach【输出模式:Append | Updated | Completed】==================================
// 将计算结果输出到redis中
//kafka record 转换为要求的类型
val ds = df
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)", "CAST(topic AS STRING)", "CAST(partition AS INT)", "CAST(timestamp AS LONG)")
.as[(String, String, String, Int, Long)].flatMap(_._2.split(" ")).map((_, 1)) // key value topic partition Long
ds.createOrReplaceTempView("t_kafka")
val text = spark.sql("select _1 as word,count(_2) as num from t_kafka group by _1")
text
.writeStream
.outputMode(OutputMode.Update())
.foreach(new ForeachWriter[Row] {
/**
* 打开方法
*
* @param partitionId 分区序号
* @param epochId
* @return Boolean true 创建一个连接 对这一行数据进行处理操作
* false 不会创建连接 跳过这一行数据
*/
override def open(partitionId: Long, epochId: Long): Boolean = true
/**
* 处理方法
*
* @param value resultTable 行对象
*/
override def process(value: Row): Unit = {
val word = value.getString(0)
val count = value.getLong(1).toString
val jedis = new Jedis("Spark", 6379)
jedis.set(word, count)
jedis.close()
}
override def close(errorOrNull: Throwable): Unit = if (errorOrNull != null) errorOrNull.printStackTrace()
}) // 对resultTable中的每一行记录应用写出规则
.option("checkpointLocation", "hdfs://Spark:9000/checkpoint4") // 检查点path 用以故障恢复
.start()
.awaitTermination()
}
}
三、Operations on streaming DataFrames/Dataset
您可以对流式DataFrames/Datasets应用各种操作 - 从无类型,类似SQL的操作(例如select,where,groupBy)到类型化RDD类操作(例如map,filter,flatMap)
基础操作(选择、投影、聚合)
略
四、Window Operations on Event Time
基于事件时间的窗口操作
滑动event-time时间窗口的聚合在StructuredStreaming上很简单,并且和分组聚合非常相似。在分组聚合中,为用户指定的分组列中的每个唯一值维护聚合值(例如计数)。在基于窗口的聚合的情况下,为每一个event-time窗口维护聚合值。
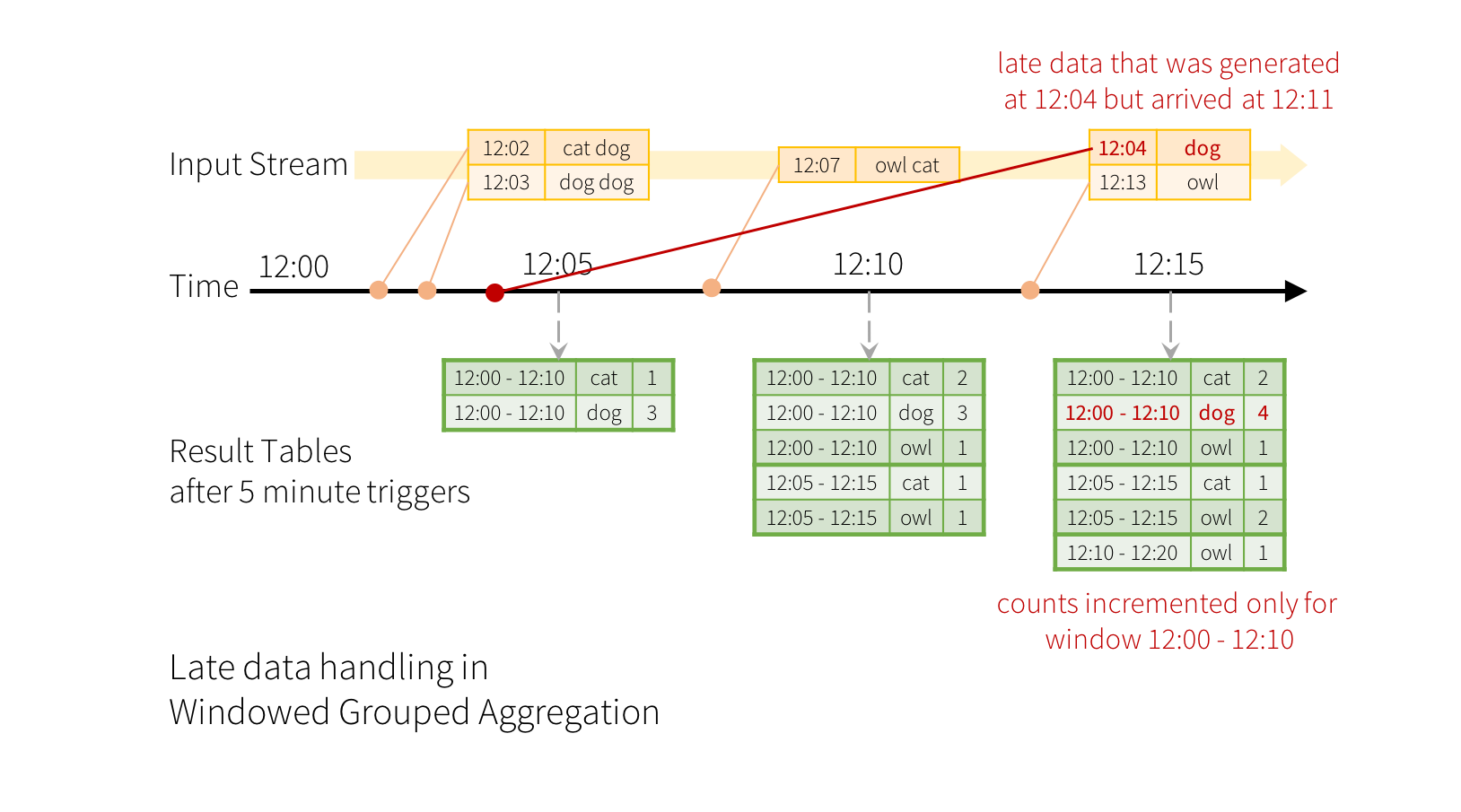
想象一下,quickexample中的示例被修改,现在stream中的每行包含了生成的时间。我们不想运行word count,而是要在10分钟的窗口内计数单词,每5分钟更新一次。也就是说,在10分钟窗口12:00 - 12:10,12:05 - 12:15,12:10 - 12:20等之间收到的单词中的字数。请注意,12:00 - 12:10是指在12:00之后但在12:10之前到达的数据。现在,考虑在12:07收到的一个word。这个词应该增加对应于两个窗口的计数,分别为12:00 - 12:10和12:05 - 12:15。所以计数counts将会被group key(ie:the word)和window(根据event-time计算)索引。将会如下所示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yGhAcD56-1573651808180)(assets/1573528619688.png)]
由于此窗口类似于分组,因此在代码中,可以使用groupBy()和window()操作来表示窗口聚合。如:
Handling Late Data and Watermarking
处理延迟数据和水位线
默认: 延迟数据累加到窗口计算中,并且Spark在内存保存所有窗口计算的中间结果
现在考虑如果一个事件迟到应用程序会发生什么。例如,假设12:04(即event-time)生成的一个word可以在12:11被应用程序接收。应用程序应该使用时间12:04而不是12:11更新窗口的较旧计数,即12:00 - 12:10。这在我们基于窗口的分组中很自然有可能发生- Structured Streaming可以长时间维持部分聚合的中间状态,以便延迟的数据可以正确地更新旧窗口的聚合,如下所示:
wm(水位线) = 最大的事件时间-数据的延迟时间
作用: 界定过期数据和有效数据的一种规则
- 水位线以内的延迟数据为有效数据,参与窗口的计算
- 水位线以外的数据为无效数据,直接丢弃,水位线以外的窗口会自动drop
import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word")
.count()
本例中,watermark的指定列为“timestamp”,并且指定了“10minute”作为阀值。如果这个查询运行在update的输出模式,引擎engine会持续更新window的counts到结果集中,直到窗口超过watermark的阀值,本例中,则是如果timestamp列的时间晚于当前时间10minute。
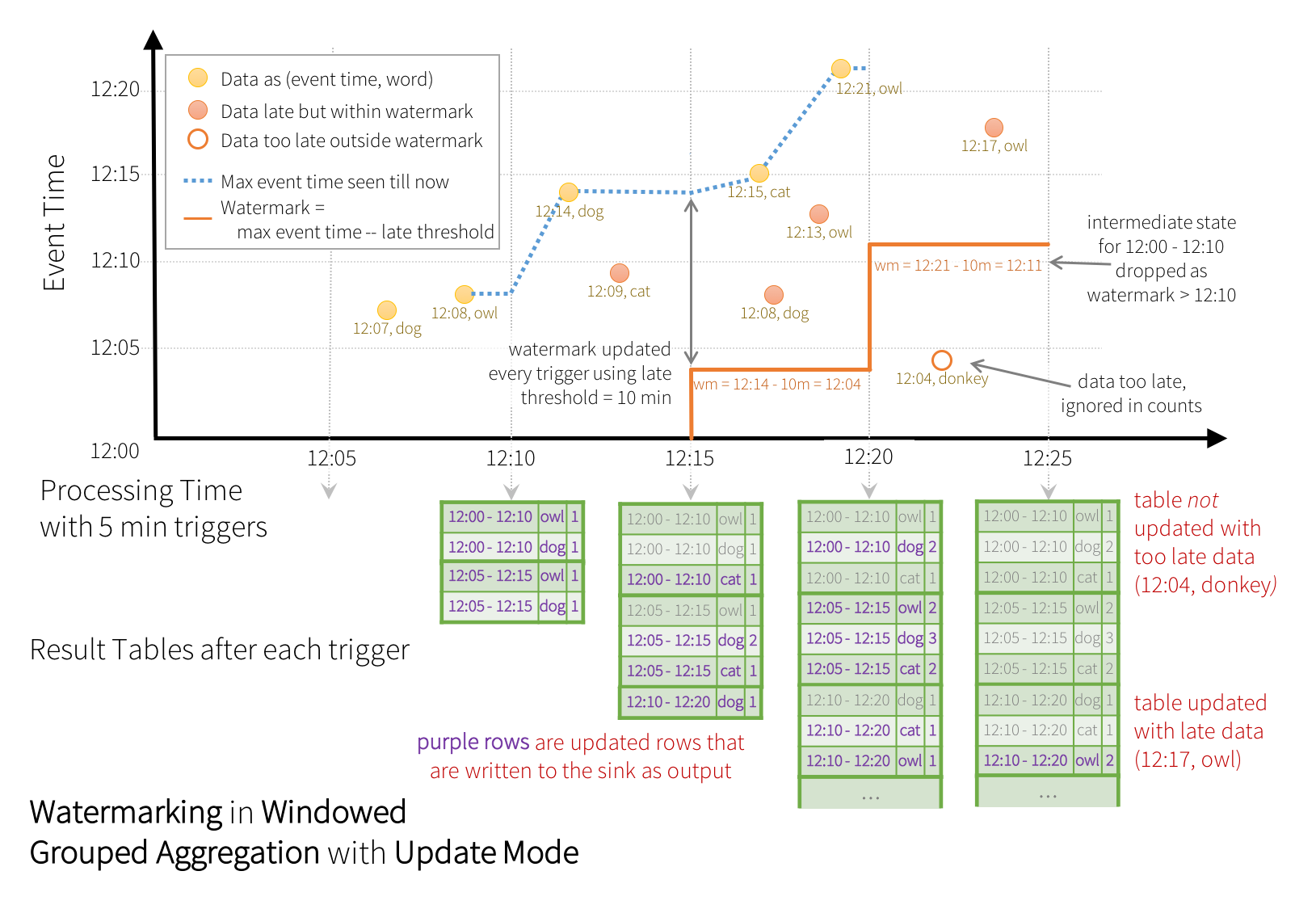
如上所示,蓝色虚线表示最大event-time,每次数据间隔触发开始时,watermark被设置为max eventtime - ‘10 mins’,如图红色实线所示。例如,当引擎engine观测到到数据(12:14,dog),对于下个触发器,watermark被设置为12:04。这个watermark允许引擎保持十分钟内的中间状态并且允许延迟数据更新聚合集。例如(12:09,cat)的数据未按照顺序延迟到达,它将落在12:05 – 12:15 和 12:10 – 12:20 。因为它依然大于12:04 ,所以引擎依然保持着中间结果集,能够正确的更新对应窗口的结果集。但是当watermark更新到12:11,中间结果集12:00-12:10的数据将会被清理掉,此时所有的数据(如(12:04,donkey))都会被认为“too late”从而被忽略。注意,每次触发器之后,更新的counts(如 purple rows)都会被写入sink作为输出的触发器,由更新模式控制。
某些接收器(例如文件)可能不支持更新模式所需的细粒度更新。要与他们一起工作,我们还支持append模式,只有最后的计数被写入sink。这如下所示。
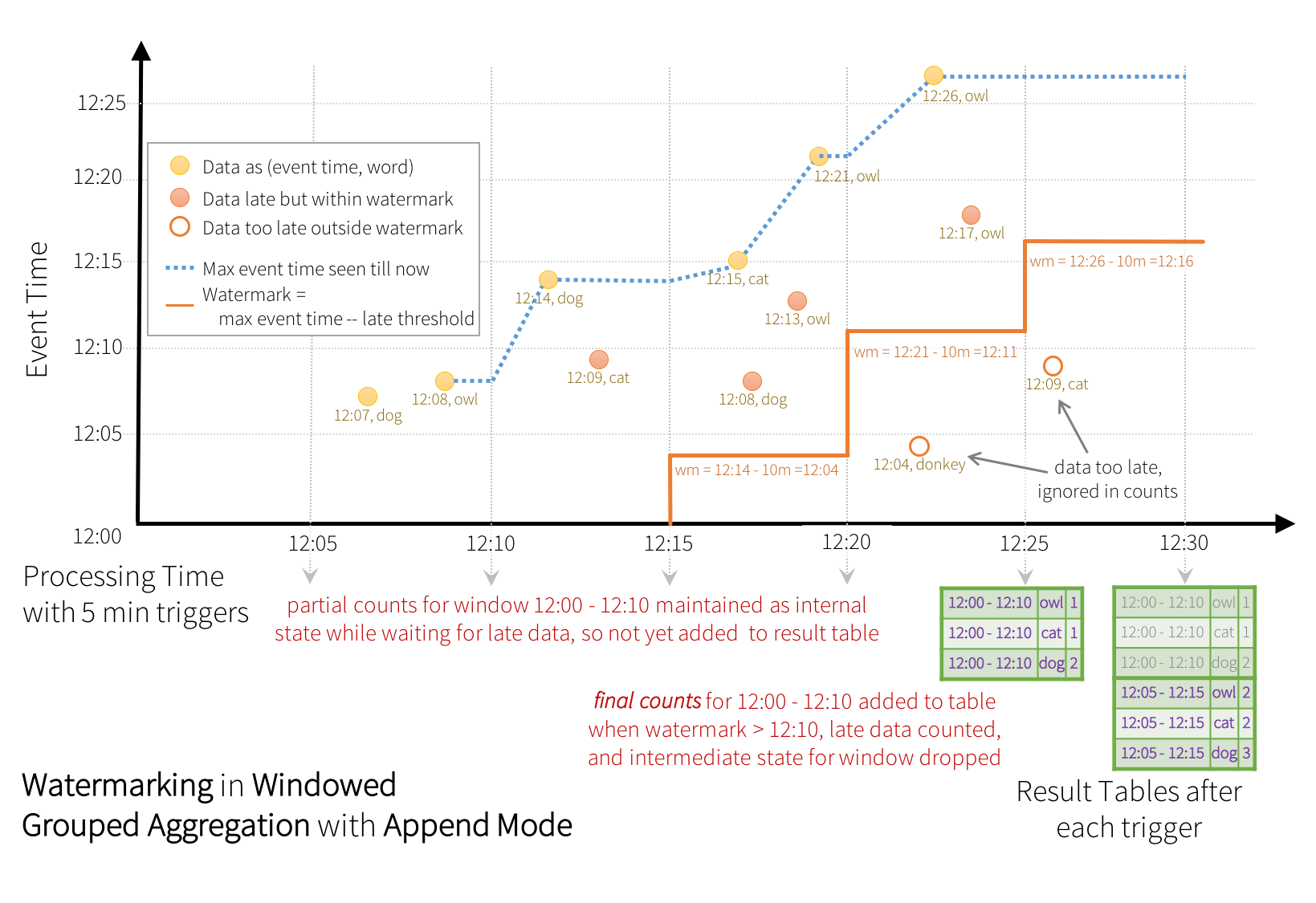
请注意,在非流数据集上使用watermark是无效的。由于watermark不应以任何方式影响任何批次查询,我们将直接忽略它。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IDq8tzPF-1573651808183)(assets/1573547867613.png)]
package com.baizhi.window
import java.sql.Timestamp
import java.text.SimpleDateFormat
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.OutputMode
/**
* 基于事件事件窗口操作
*
*/
object SparkStructuredStreamingForLateDataHandling {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("window on event time").master("local[*]").getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
import spark.implicits._
val df = spark
.readStream
.format("socket")
.option("host", "Spark")
.option("port", "4444")
.load()
// 发送数据时:word,timestamp
// Hello,1573525440000 --> 10:24:00
// 导入隐式转换的函数
import org.apache.spark.sql.functions._
val sdf = new SimpleDateFormat("HH:mm:ss") // 时:分:秒
df
.as[String]
.map(_.split(",")) // Hello,1573525440000 --> Array("Hello","1573525440000")
.map(arr => (arr(0), new Timestamp(arr(1).toLong))) //("Hello",new Timestamp(1573525440000))
.toDF("word", "timestamp")
//-------------------------------------------------------------
// 水位线操作
.withWatermark("timestamp", "10 seconds") // vm = maxEventTime-2
//-------------------------------------------------------------
// 先根据事件时间划分窗口,再对窗口内的单词进一步分组
.groupBy(window($"timestamp", "10 seconds", "5 seconds"), $"word") // 滑动窗口 长度5s 滑动3s
// 统计窗口内单词出现的次数
.count()
/**
* root
* |-- window: struct (nullable = true)
* | |-- start: timestamp (nullable = true)
* | |-- end: timestamp (nullable = true)
* |-- word: string (nullable = true)
* |-- count: long (nullable = false)
*/
//.printSchema()
.map(row => (sdf.format(row.getStruct(0).getTimestamp(0)), sdf.format(row.getStruct(0).getTimestamp(1)), row.getString(1), row.getLong(2)))
.toDF("startTime", "endTime", "word", "num")
.writeStream
.format("console")
// .outputMode(OutputMode.Append()) // 注意:输出模式只能是 append和 update
.outputMode(OutputMode.Update()) // 注意:输出模式只能是 append和 update
.start()
.awaitTermination()
}
}
五、Join Operations
Streaming DataFrames可以与静态 DataFrames连接,以创建新的Streaming DataFrames。 例如下面的例子:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.{BooleanType, StructType}
object SparkStructuredStreamingForJoinOpt {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("join opt").master("local[*]").getOrCreate()
val df1 = spark // 基于静态文件创建DF
.read
.format("json")
.load("file:///G:\\IDEA_WorkSpace\\scala-workspace\\spark-day11\\src\\main\\resources") // id name sex
val df2 = spark // 基于流数据创建DF
.readStream
.format("csv")
.schema(
new StructType()
.add("id", "integer")
.add("name", "string")
.add("sex", BooleanType)
.add("salary", "double")
)
.csv("file:///d://csv")
// 批和流不允许Join【流数据不能join给批数据】
// 正常: 【批数据join给流数据】
df2.join(df1,Seq("id","id"),"leftOuter") // 流DF join 批DF
.writeStream
.format("console")
.outputMode("append")
.start()
.awaitTermination()
}
}
//----------------------------------------------------------------------
Batch: 0
-------------------------------------------
+---+---+----+------+----+------+
| id| id|name|salary|name|salary|
+---+---+----+------+----+------+
| 1| 1| zs|1000.0| zs|3000.0|
| 2| 2| ls|2000.0| ls|3000.0|
| 3| 3| ww|3000.0| ww|3000.0|
| 4| 4| zs|1000.0| zs2|3000.0|
| 5| 5| ls|2000.0| ls2|3000.0|
| 6| 6| ww|3000.0| ww2|3000.0|
| 4| 4| zs|3000.0| zs2|3000.0|
| 7| 7| ls|2000.0|null| null|
| 8| 8| ww|3000.0|null| null|
+---+---+----+------+----+------+