1. 环境配置如下
- python3.7
- pip install torch
- pip install torchvision
2. 代码如下
原书的代码存在一点bug,现已被作者修复
Client端代码如下
import torch.utils.data
class Client(object):
def __init__(self,conf,model,train_dataset,id=1):
self.conf = conf # 配置文件
self.local_model = model # 客户端本地模型
self.client_id = id # 客户端ID
self.train_dataset = train_dataset #客户端本地数据集
all_range = list(range(len(self.train_dataset)))
data_len = int(len(self.train_dataset)/self.conf['no_models'])
indices = all_range[id*data_len:(id+1)*data_len]
self.train_loader = torch.utils.data.DataLoader(
self.train_dataset,
batch_size=conf["batch_size"],
sampler=torch.utils.data.sampler.SubsetRandomSampler(indices)
)
def local_train(self, model):
for name,param in model.state_dict().items():
# 客户端首先用服务器端下发的全局模型覆盖本地模型
self.local_model.state_dict()[name].copy_(param.clone())
# 定义最优化函数器,用于本地模型训练
optimizer = torch.optim.SGD(
self.local_model.parameters(),
lr=self.conf['lr'],
momentum=self.conf['momentum']
)
# 本地模型训练
self.local_model.train()
for e in range(self.conf['local_epochs']):
for batch_id,batch in enumerate(self.train_loader):
data, target = batch
if torch.cuda.is_available():
self.local_model.cuda()
data = data.cuda()
target = target.cuda()
optimizer.zero_grad()
output = self.local_model(data)
loss = torch.nn.functional.cross_entropy(output, target)
loss.backward()
optimizer.step()
print("Epoch %d done." % e)
diff = dict()
for name,data in self.local_model.state_dict().items():
diff[name] = (data - model.state_dict()[name])
return diff
Server端代码如下
import torch.utils.data
import torchvision.datasets as datasets
from torchvision import models
from torchvision.transforms import transforms
# 服务端
class Server(object):
def __init__(self, conf, eval_dataset):
self.conf = conf
# 服务器端的模型
self.global_model = models.get_model(self.conf["model_name"])
self.eval_loader = torch.utils.data.DataLoader(eval_dataset,batch_size=self.conf["batch_size"],shuffle=True)
self.accuracy_history = [] # 保存accuracy的数组
self.loss_history = [] # 保存loss的数组
# 聚合各个服务器上传的信息
def model_aggregate(self, weight_accumulator):
# weight_accumulator存储了每一个客户端的上传参数变化值
for name,data in self.global_model.state_dict().items():
update_per_layer = weight_accumulator[name] * self.conf['lambda']
if data.type() != update_per_layer.type():
data.add_(update_per_layer.to(torch.int64))
else:
data.add_(update_per_layer)
# 定义模型评估函数
def model_eval(self):
self.global_model.eval()
total_loss = 0.0
correct = 0
dataset_size = 0
for batch_id,batch in enumerate(self.eval_loader):
data,target = batch
dataset_size += data.size()[0]
if torch.cuda.is_available():
self.global_model.cuda()
data = data.cuda()
target = target.cuda()
output = self.global_model(data)
# 把损失值聚合起来
total_loss += torch.nn.functional.cross_entropy(output,target,reduction='sum').item()
# 获取最大的对数概率的索引值
pred = output.data.max(1)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
# 计算准确率
acc = 100.0 * (float(correct) / float(dataset_size))
# 计算损失值
total_l = total_loss / dataset_size
# 将accuracy和loss保存到数组中
self.accuracy_history.append(acc)
self.loss_history.append(total_l)
return acc,total_l
def save_results_to_file(self):
# 将accuracy和loss保存到文件中
with open("fed_accuracy_history.txt", "w") as f:
for acc in self.accuracy_history:
f.write("{:.2f}\n".format(acc))
with open("fed_loss_history.txt", "w") as f:
for loss in self.loss_history:
f.write("{:.4f}\n".format(loss))
聚合代码如下
import json
import random
import torch
from MyDataLoader import get_dataset
from chapter3.Client import Client
from chapter3.Server import Server
with open("conf.json",'r') as f:
conf = json.load(f)
# 接下来分别定义一个服务端对象和多个客户端对象,用来模拟横向联邦训练场景
train_datasets,eval_datasets = get_dataset("./data/",conf["type"])
server = Server(conf,eval_datasets)
clients = []
# 创建多个客户端
for c in range(conf["no_models"]):
clients.append(Client(conf,server.global_model,train_datasets,c))
# 每一轮迭代,服务端会从当前的客户端集合中随机挑选一部分参与本轮迭代训练,被选中的客户端调用本地训练接口local_train进行本地训练,
# 最后服务器调用模型聚合函数model——aggregate来更新全局模型,代码如下所示:
for e in range(conf["global_epochs"]):
# 采样k个客户端参与本轮联邦训练
candidates = random.sample(clients,conf['k'])
# 初始化weight_accumulator并在GPU上(如果可用)
weight_accumulator = {}
if torch.cuda.is_available():
device = torch.device("cuda:0")
else:
device = torch.device("cpu")
for name,params in server.global_model.state_dict().items():
# 在指定设备上创建并初始化weight_accumulator中的张量
weight_accumulator[name] = torch.zeros_like(params).to(device)
for c in candidates:
# 确保本地训练后的模型差异在正确设备上
diff = c.local_train(server.global_model)
for name,params in server.global_model.state_dict().items():
weight_accumulator[name].add_(diff[name])
server.model_aggregate(weight_accumulator)
acc,loss = server.model_eval()
print("Epoch %d ,acc:%f,loss: %f\n" % (e,acc,loss))
server.save_results_to_file()
数据集的加载
import torch.utils.data
import torchvision.datasets as datasets
from torchvision import models
from torchvision.transforms import transforms
def get_dataset(dir, name):
if name == 'mnist':
train_dataset = datasets.MINST(dir, train=True, download=True,transform=transforms.ToTensor())
eval_dataset = datasets.MINST(dir, train=False, transform=transforms.ToTensor())
elif name=='cifar':
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914,0.4822,0.4465),(0.2023,0.1994,0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
train_dataset = datasets.CIFAR10(dir, train=True, download=True, transform=transform_train)
eval_dataset = datasets.CIFAR10(dir, train=False, transform=transform_test)
return train_dataset, eval_dataset
配置文件如下
{
"model_name" : "resnet18",
"// comment1": "客户端的个数",
"no_models" : 10,
"type" : "cifar",
"global_epochs" : 10,
"local_epochs" : 3,
"// comment2": "每一轮中挑选的机器数",
"k" : 6,
"batch_size" : 32,
"lr" : 0.001,
"momentum" : 0.0001,
"lambda" : 0.1
}
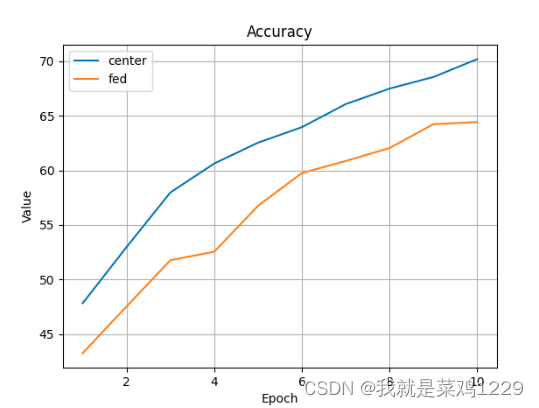
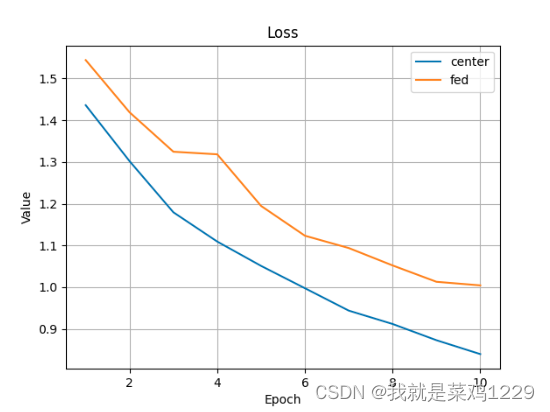
3.结果如下
可以看到联邦学习的效果还是不如集中式学习,也有可能是因为我迭代的轮次不够。