- List item
本篇介绍vi/vim编辑器和Linux文件处理“三剑客”(sed/grep/awk),这5个工具命令可能是Linux最最常用的,而且功能超级强大。
vi/vim
vi和vim的基本介绍
所有的 Linux 系统都会内建 vi 文本编辑器。Vim 具有程序编辑的能力,可以看做是Vi的增强版本,可以主动的以字体颜色辨别语法的正确性,方便程序设计。代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。
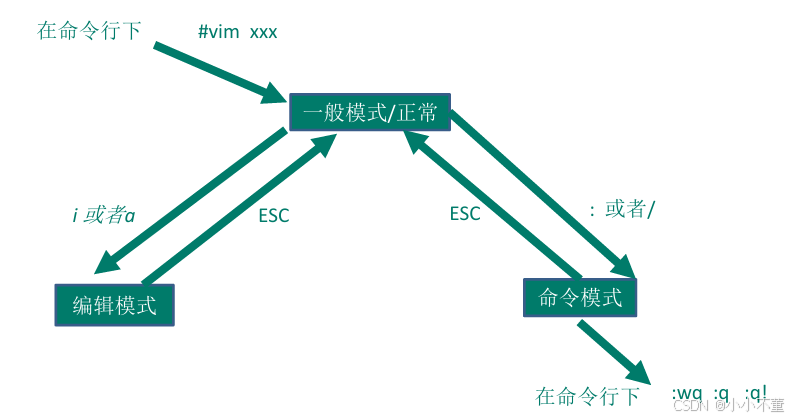
vi和vim常用的三种模式
正常模式:
以 vim 打开一个档案就直接进入一般模式了(这是默认的模式)。在这个模式中, 你可以使用『上下左右』按键来移动光标,你可以使用『删除字符』或『删除整行』来处理档案内容,也可以使用『复制、贴上』来处理你的文件数据。
插入模式:
按下i, I, o, O, a, A, r, R等任何一个字母之后才会进入编辑模式, 一般来说按i即可.
命令行模式:
在这个模式当中, 可以提供你相关指令,完成读取、存盘、替换、离开 vim 、显示行号等的动作则是在此模式中达成的!
Linux文件处理“三剑客”(sed/grep/awk)
sed的用法
sed(Stream Editor)是一个流编辑器,在 Linux 和 Unix 系统中被广泛用于文本处理。
1、基本替换
替换文件中的特定字符串:
sed 's/old_string/new_string/' filename
这将在文件中把第一次出现的 “old_string” 替换为 “new_string”。例如,sed ‘s/apple/orange/’ fruits.txt会在fruits.txt文件中将 “apple” 替换为 “orange”。
全局替换:
sed 's/old_string/new_string/g' filename
“g” 表示全局替换,即文件中所有的 “old_string” 都将被替换为 “new_string”。
2、行号定位
只处理特定行:
sed -n '3p' filename
这将只打印文件的第三行。
处理一定范围的行:
sed -n '2,5p' filename
打印文件的第 2 行到第 5 行。
3、删除行
删除特定行:
sed '3d' filename
删除文件的第三行。
删除符合特定条件的行:
sed '/pattern/d' filename
删除包含 “pattern” 的行。
4、插入和追加
在特定行前插入文本:
sed '3i\Inserted text' filename
在文件的第三行前插入 “Inserted text”。
在特定行后追加文本:
sed '3a\Appended text' filename
在文件的第三行后追加 “Appended text”。
5、使用正则表达式
基于正则表达式进行替换:
sed 's/[0-9]\+/replacement/' filename
这将把文件中的所有数字替换为 “replacement”。
删除符合正则表达式的行:
sed '/^[A-Z].*$/d' filename
删除以大写字母开头的行。
6、从文件读取命令
可以将sed命令存储在一个文件中,然后使用-f选项执行这些命令:
创建一个包含sed命令的文件,例如commands.sed:
s/old/new/g
/pattern/d
执行命令文件:
sed -f commands.sed filename
7、直接在命令行中传递多个命令
可以在单个命令中使用分号分隔多个sed命令:
sed ‘s/first/1st/; s/second/2nd/’ filename
这将先把文件中的 “first” 替换为 “1st”,然后把 “second” 替换为 “2nd”。
sed是一个非常强大的工具,通过不同的选项和命令组合,可以实现各种复杂的文本处理任务。在使用时,要注意正则表达式的正确使用以及命令的顺序和效果。sed的功能远不止以上所列的,但掌握以上的用法,作为DBA或者开发就足够了。
grep的用法
grep是一个强大的文本搜索工具。
1、基本搜索
在文件中搜索特定字符串:
grep "search_string" filename
例如,grep “hello” file.txt会在file.txt文件中搜索包含 “hello” 的行。
搜索多个文件:
grep "search_string" file1.txt file2.txt file3.txt
这将在多个文件中搜索指定的字符串。
二、选项用法
-i:忽略大小写进行搜索。
grep -i "Hello" file.txt
这将在文件中搜索 “Hello”、“hello”、“HELLO” 等各种大小写组合。
-v:反转搜索结果,显示不包含搜索字符串的行。
grep -v "search_string" filename
-n:显示匹配行的行号。
grep -n "hello" file.txt
-c:只显示匹配的行数,而不是匹配的行内容。
grep -c "search_string" filename
-l:只列出包含匹配字符串的文件名,而不是显示具体的行内容。
grep -l "search_string" *
这将在当前目录下的所有文件中搜索,并列出包含指定字符串的文件名。
-r或–recursive:递归地在目录及其子目录下的所有文件中进行搜索。
grep -r "search_string" directory/
3、正则表达式搜索
grep支持基本的正则表达式搜索。例如:
.表示任意一个字符:
grep "h..o" file.txt
这将搜索包含 “h 任意两个字符 o” 的行,如 “hello”、“hero” 等。
*表示零个或多个前面的字符:
grep "he*llo" file.txt
可以匹配 “hello”、“heello”、“heeello” 等。
^表示行的开头:
grep “^hello” file.txt
只匹配以 “hello” 开头的行。
$表示行的结尾:
grep "world$" file.txt
只匹配以 “world” 结尾的行。
4、结合其他命令使用
与管道结合使用:
cat file.txt | grep "search_string"
先使用cat命令显示文件内容,然后通过管道将输出传递给grep进行搜索。
与其他命令的输出进行搜索:
ps aux | grep "process_name"
这将列出正在运行的进程中包含特定进程名称的行。
awk的用法
awk是一种强大的文本处理工具。
1、基本语法
awk ‘{action}’ input-file
其中,action是要执行的操作,input-file是输入文件。
例如,打印文件中每一行的内容:
awk ‘{print}’ filename
2、打印特定字段
假设一个文件中有以逗号分隔的字段,可以使用$符号加上字段编号来打印特定字段。
例如,打印文件中每行的第二个字段:
awk ‘{print $2}’ filename
3、使用变量
可以在awk中定义和使用变量。
例如,计算文件中某一列的总和:
awk ‘{sum+=$1} END{print sum}’ filename
这里,$1表示每行的第一个字段,sum是定义的变量,在END块中打印总和。
4、条件判断
可以使用条件语句来筛选和处理特定的行。
例如,打印文件中第一个字段大于 10 的行:
awk ‘$1>10 {print}’ filename
5、内置函数
awk提供了一些内置函数,如length()用于计算字符串长度,sqrt()用于计算平方根等。
例如,打印文件中每行第一个字段的平方根:
awk ‘{print sqrt($1)}’ filename
6、格式化输出
可以使用printf语句进行格式化输出。
例如,以特定格式打印每行的两个字段:
awk ‘{printf “Field1: %d, Field2: %s\n”, $1, $2}’ filename
7、处理多个文件
可以同时处理多个文件。
例如,打印两个文件中每行第一个字段的总和:
awk ‘{sum+=$1} END{print sum}’ file1 file2
8、模式匹配
可以使用模式来匹配特定的行进行处理。
例如,打印文件中包含特定字符串的行:
awk ‘/pattern/ {print}’ filename
9、数组的使用
可以在awk中使用数组来存储和处理数据。
例如,统计文件中每个单词出现的次数:
awk '{for(i=1;i<=NF;i++){words[$i]++}} END{for(word in words){print word, words[word]}}' filename
这里,NF表示当前行的字段数量,words是一个数组,用于存储单词及其出现次数。
sed/grep/awk的功能远不止以上所列的,但掌握以上的用法,作为DBA或者开发就足够了。
本篇结束。
码字不易,宝贵经验分享不易,请各位支持原创,转载注明出处,多多关注作者。