文章目录
- 1. Wonderworld:拓展图片边界,生成3D场景
- 2. 3DTopia-XL:扩散模型辅助生成
- 3. 3DGS-Enhancer: 通过视图一致2D Diffusion,提升无界3D Gaussian Splatting (NlPs2024 Spotlight)
- 4. L3DG:Latent 3D Gaussian Diffusion
- 5. MonST3R:运动中的几何估计(已讲)
- 6. PhotoReg :GS点云3D配准
- 7.VR-Splatting
- 8.GaussianCut:通过Graph cut的交互式GS分割
- 9.DiffGS:基于LDM的GS生成式模型,通过三个函数解耦建模高斯概率、颜色和变换
- 10.MVSplat360:稀疏场景的360视角合成(NeurIPS 2024 √)
- 11. LVSM:具有最小归纳偏差的大场景合成模型(×)
- 12. DiffusionGS:基于GS的可扩展单阶段图像生成GS模型(x)
- 13.InFusion:扩散模型助力,替换补全场景
- 14.Bootstrap 3D:从扩散模型引导三维重建
- 15.Flash3D:单张图像重建场景的GaussianSplatting
- 16.Edify 3D:可扩展的高质量的3D资产生成(英伟达)
- 17. ExtraNeRF:基于扩散模型的NeRF可见性视角外延(稀疏重建)
- 18.扩散模型LDM辅助3D Gaussian重建三维场景(生成任务)
- 19.SmileSplat:无约束稀疏图像的可推广高斯溅射
- 20.SplatFormer Point Transformer
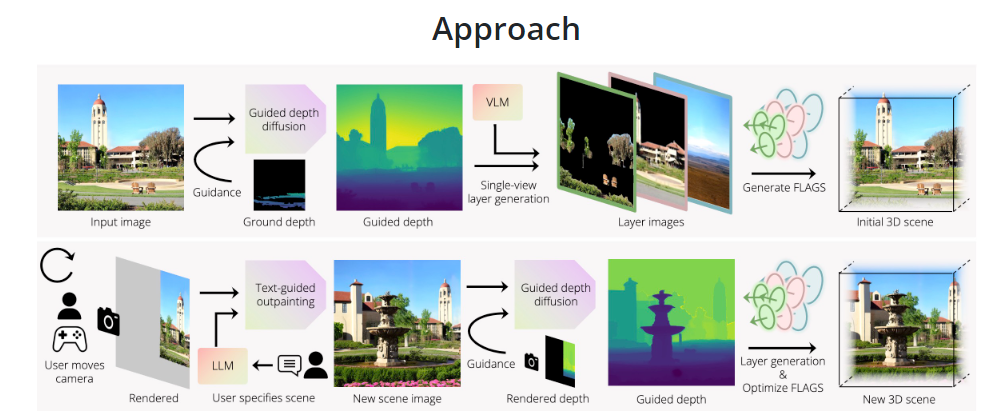
1. Wonderworld:拓展图片边界,生成3D场景
项目:https://kovenyu.com/wonderworld/(未开源)
论文:https://arxiv.org/pdf/2406.09394
《wonderworld Interactive 3D Scene Generation from a Single Image》
交互式3D 世界生成,根据用户的移动和内容请求以交互方式在10秒内生成 3D 场景


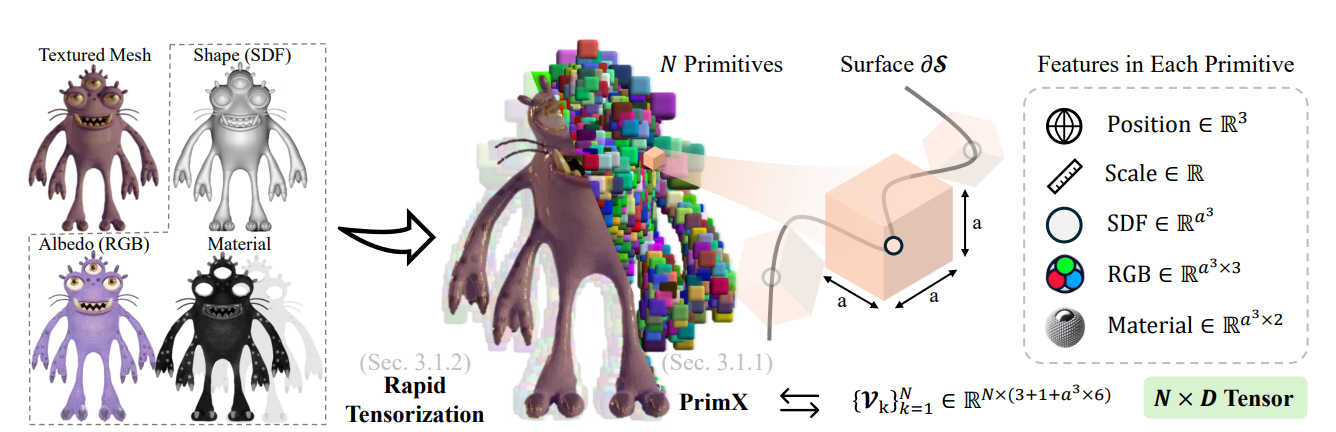
2. 3DTopia-XL:扩散模型辅助生成
项目:https://3dtopia.github.io/3DTopia-XL/
代码:https://github.com/3DTopia/3DTopia-XL
标题:3DTopia-XL: Scaling High-quality 3D Asset Generation via Primitive Diffusion
基于DiT与一种新式基元3D表示(PrimeX)的高质量 3D 资产生成方法,5秒生成PBR资产。该方法提出的PrimX 3D表示显式的将目标的3D形状和纹理、材质编码为一个紧致的N*D维张量,每个基元与其对应的形状曲面锚定,通过DiT生成。

3. 3DGS-Enhancer: 通过视图一致2D Diffusion,提升无界3D Gaussian Splatting (NlPs2024 Spotlight)
3DGS-Enhancer: Enhancing Unbounded 3D Gaussian Splatting with View-consistent 2D Diffusion Priors (NlPs2024 Spotlight)
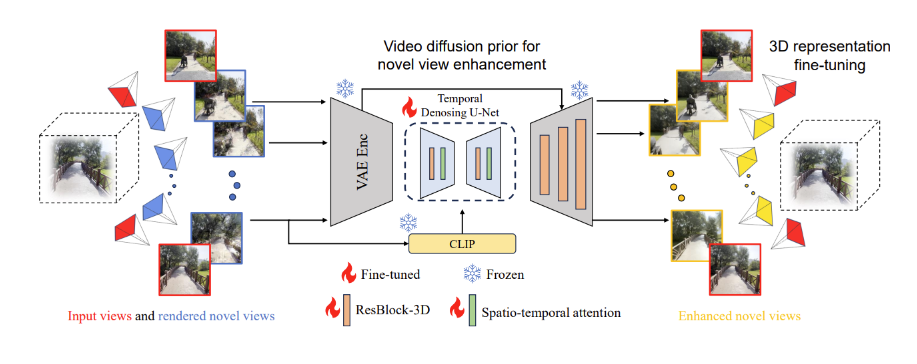
链接:https://xiliu8006.github.io/3DGS-Enhancer-project/(未开源)
标题:3DGS-Enhancer: Enhancing Unbounded 3D Gaussian Splatting with View-consistent 2D Diffusion Priors (NIPS 2024 Spotlight)
通过视频生成扩散先验改进低质量3DGS建模的效果
4. L3DG:Latent 3D Gaussian Diffusion
https://arxiv.org/pdf/2410.13530
L3DG: Latent 3D Gaussian Diffusion
LDM的3DGS版本

5. MonST3R:运动中的几何估计(已讲)
https://monst3r-project.github.io/
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion


Must3R的4D版本,单目视频估计动态点云与内外参,效果、速度看着都很不错,
动态版本、以及建筑行业的动态过程管理等方面。应该也是目前速度最快的4D Recon方案之一。
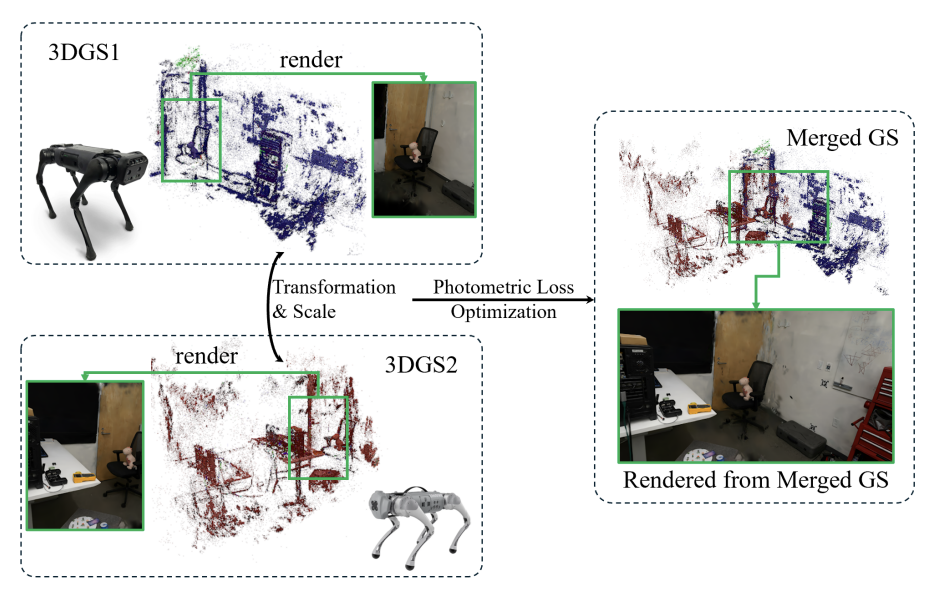
6. PhotoReg :GS点云3D配准
PhotoReg: Photometrically Registering 3D
https://github.com/ziweny11/PhotoRegCodes
PhotoReg takes two input 3D Gaussian Splatting models and
aligns them into a merged Gaussian Splatting model. Transformation and Scale information between two inputs is obtained through
3D visual foundation models and further refined photometrically.
8.6DGS:GS + 体渲染
6DGS:Enhanced Direction-AwareGaussian Splatting for VolumetricRendering
https://arxiv.org/pdf/2410.04974
在这里插入图片描述
7.VR-Splatting
链接:https://lfranke.github.io/vr_splatting/(未开源)
VR-Splatting: Foveated Radiance Field Rendering via 3D Gaussian Splatting and Neural Points
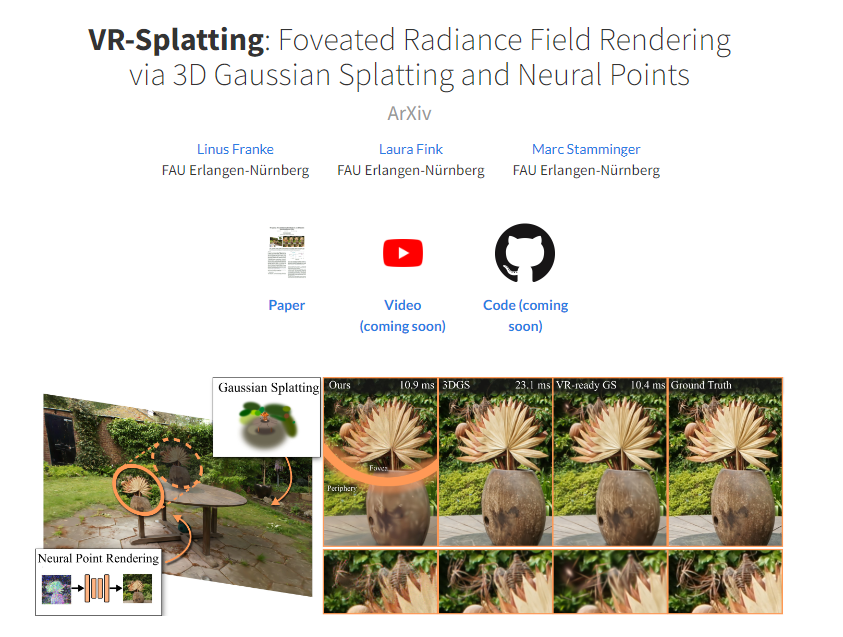

VR-Splatting 将神经点渲染和3DGS的优势结合到 VR 混合注视点辐射场渲染系统中。方法在注视点区域提供了高保真度,并满足 90 Hz VR 帧速率要求。
8.GaussianCut:通过Graph cut的交互式GS分割
https://arxiv.org/pdf/2411.07555
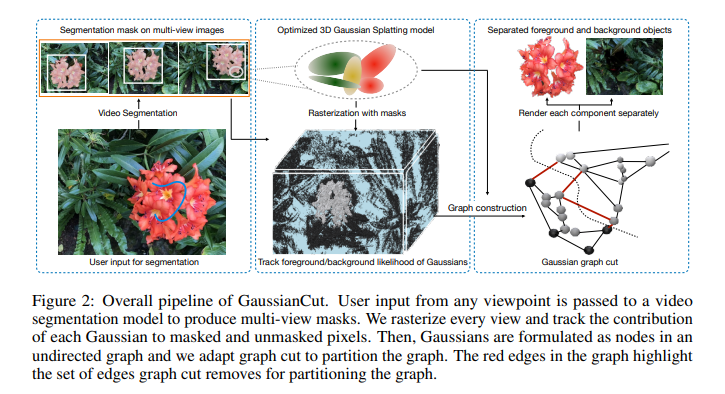
GaussianCut: Interactive Segmentation via Graph Cut for 3D Gaussian Splatting
3D图割结合SAM做GS分割,细节较好;

9.DiffGS:基于LDM的GS生成式模型,通过三个函数解耦建模高斯概率、颜色和变换
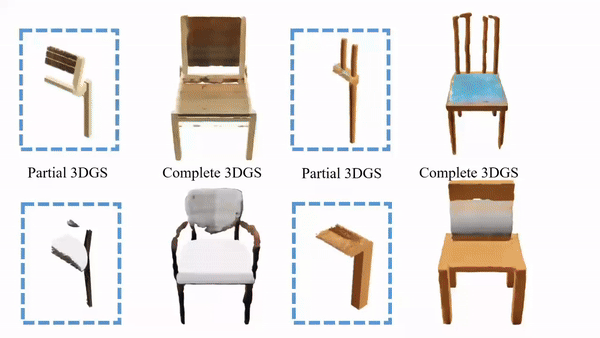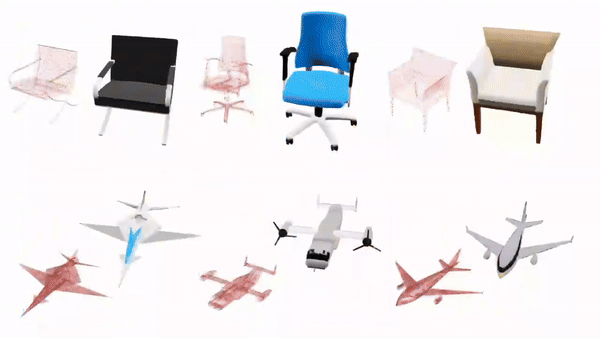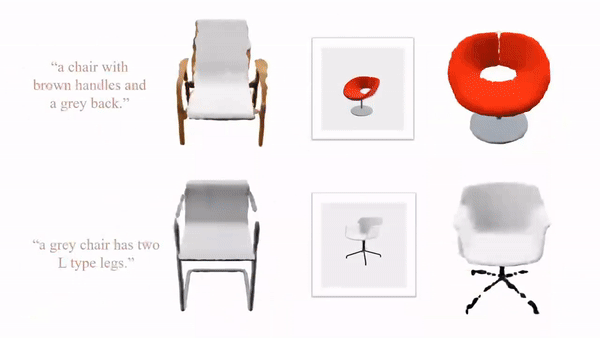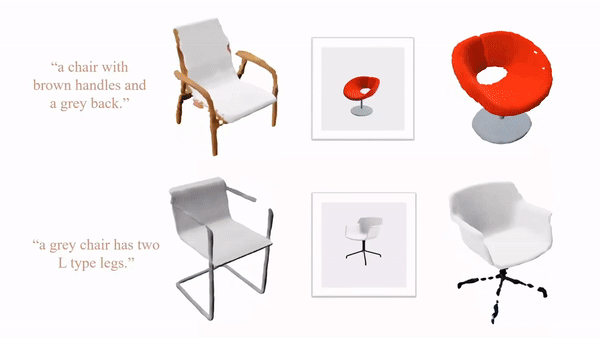
https://junshengzhou.github.io/DiffGS/
DiffGS: Functional Gaussian Splatting Diffusion
DiffGS是一种基于潜在扩散模型的三维生成模型,它能够以任意数生成高斯原语,用于使用栅格化的高保真渲染。关键的见解是通过三个新的函数来表示高斯溅来模拟高斯的 probabilities, colors and transforms。通过新的3DGS的解耦,我们表示了具有连续高斯溅射函数的离散和非结构化的3DGS,然后我们训练了一个无条件和有条件地生成这些高斯溅射函数的潜在扩散模型。同时,我们引入了一种离散化算法,通过八叉树引导的采样和优化,从生成的函数中提取任意数的高斯函数。
本文探索了DiffGS的各种任务,包括无条件生成、从文本、图像中获得的条件生成和部分3DGS,以及点云高斯生成 。
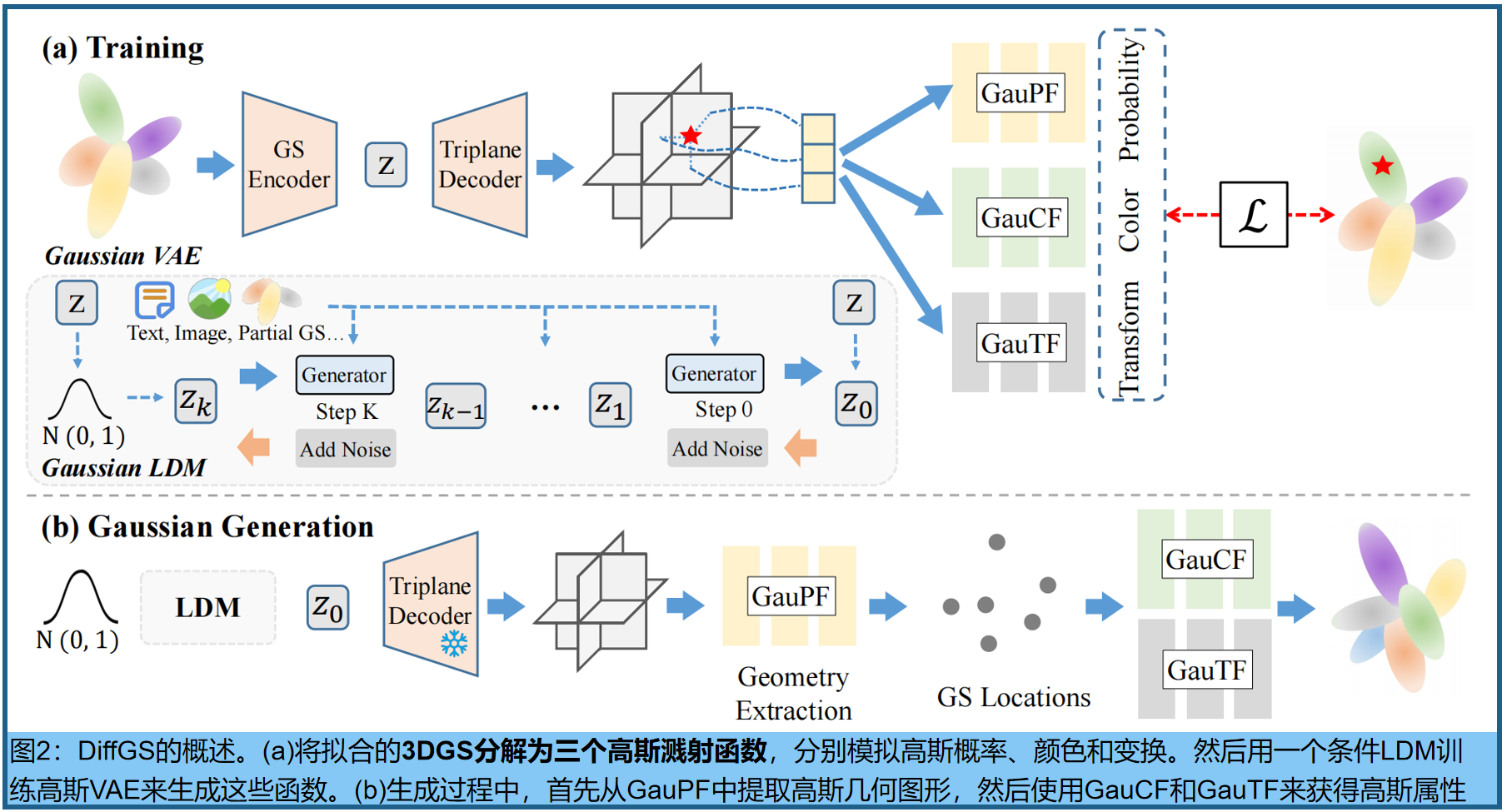
Functional Gaussian Splatting Representation(3DGS的解耦)
我们通过三个新的函数以解耦的方式表示高斯喷溅:高斯概率函数(GauPF)、高斯颜色函数(GauCF)和高斯变换函数(GauTF)来解决这个问题。通过对3DGS的新型解纠缠,我们表示了具有三个连续高斯溅射函数的离散和非结构化的3DGS
Gaussian Probability Function。高斯概率函数(GauPF)通过将每个采样的三维位置建模为一个高斯位置的概率来表示3DGS的几何形状。给定一组3D查询位置 Q Q Q = { q j ∈ R 3 q_j∈R^3 qj∈R3} i = 1 M ^M_{i=1} i=1M(从拟合的3DGS G G G={ g i ∈ R 3 g_i∈R^3 gi∈R3} j = 1 N ^N_{j=1} j=1N空间中采样),GauPF预测查询 { q j q_j qj} i = 1 M ^M_{i=1} i=1M是G中高斯位置的概率 p p p:
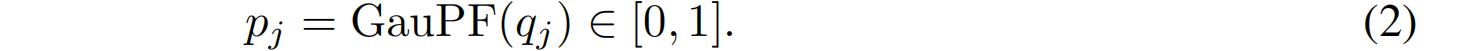
高斯概率建模的思想为:观察到的三维位置 q j q_j qj 与所有高斯分布的距离越远,任何高斯分布占据 q j q_j qj空间的概率就越低。因此, q j q_j qj的ground truth 高斯概率为:
m
i
n
∣
∣
q
j
−
σ
i
∣
∣
2
min||q_j−σ_i ||_2
min∣∣qj−σi∣∣2 表示
q
j
q_j
qj 到最近的高斯中心 {
σ
i
σ_i
σi}
i
=
1
N
^N_{i=1}
i=1N 的距离,λ是一个截断函数,过滤 large value;
τ
τ
τ 是一个连续函数,用于将 query-to-Gaussian映射到[0,1]的概率范围。

一个可学习的GauPF,隐式地模拟了三维高斯中心的位置,这是生成高质量的3DGS的关键因素。
Gaussian Color and Transform Modeling。高斯颜色函数(GauCF)和高斯变换函数(GauTF)从高斯几何预测高斯外观和变换的高斯属性。具体来说,给定G中一个高斯 g i g_i gi的中心 σ i σ_i σi 作为输入,GauCF预测颜色 c i c_i ci,GauTF预测旋转 r i r_i ri、尺度 s i s_i si和不透明度 o i o_i oi
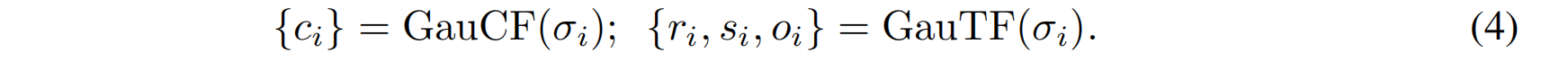
Gaussian Extraction Algorithm
DiffGS生成过程的最后一步是从生成的高斯函数中,提取3DGS,类似于从SDF中提取mesh的行Marching Cube[34]的效果。关键因素是提取3DGS的几何形状,即高斯位置和3DGS的外观,即颜色和变换。整体如图2(b).所示
Octree-Guided Geometry Sampling。三维高斯中心的位置表示了所表示的3DGS的几何形状。我们的目标是设计一种离散化算法,从学习到的由神经网络ψpf参数化的连续高斯概率函数中获得离散的三维位置,该算法将每个三维空间中采样的查询概率,建模为一个三维高斯位置。为此,我们设计了一种基于八叉树的采样和优化算法,该算法可以在任意数下生成精确的三维高斯分布的中心位置。
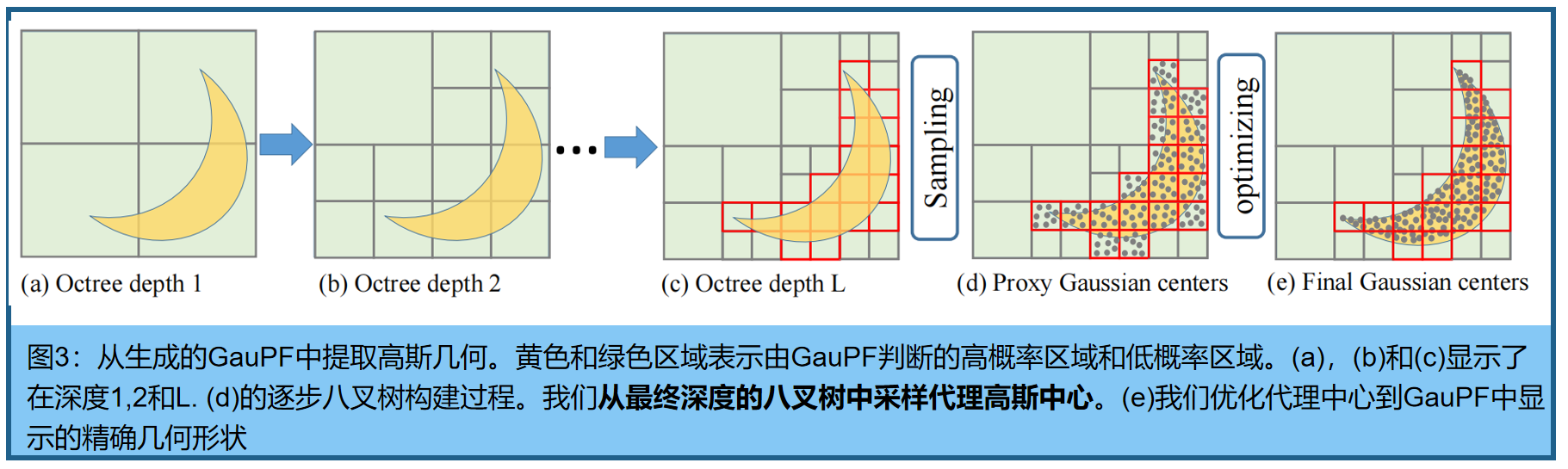
图3中展示了该算法的二维说明。假设通过生成的GauPF将三维空间划分为高概率区域(黄色区域)和低概率区域(绿色区域)。我们的目标是提取几何图形作为具有高概率的位置。一个简单的实现是在三维空间中密集地采样查询,并保留具有大概率的查询作为输出。然而,它将导致推断的高计算成本,而离散采样也难以准确地达到连续GauPF中概率最大的位置。我们从八叉树[38,67]中获得灵感,设计了一种渐进式策略,即只探索当前八叉树深度中概率较大的三维区域,以便在下一个八叉树深度中进一步细分。经过L层八叉树细分后,我们到达概率最大的局部区域,从那里我们均匀地采样N个3D点作为代理点{ ρ i ρ_i ρi} i = 1 N ^N _{i=1} i=1N,代表高斯中心的粗位置。
Optimizing Geometry with GauPF . 为了进一步细化代理点到GauPF中概率最大的高斯中心的精确位置,我们在学习到的GauPF ψ p f ψ_{pf} ψpf 的监督下进一步优化代理点。具体来说,我们设置代理点{ ρ i ρ_i ρi = { ρ x i , ρ y i , ρ z i ρ_{xi},ρ_{yi},ρ_{zi} ρxi,ρyi,ρzi} i = 1 N ^N_{i=1} i=1N的位置为可学习,并对其进行优化,使其达到 ψ p f ψ_{pf} ψpf概率最大的位置{ σ ^ i \hat{σ}_i σ^i} i = 1 N ^N_{i=1} i=1N。优化目标制定如下(可以将N设置为任意数字,对密度和分辨率没有限制):

Extracting Gaussian Attributes。从生成的三平面 t t t、高斯色函数 ψ c f ψ_{cf} ψcf和高斯变换函数 ψ t f ψ_{tf} ψtf中提取外观和变换:
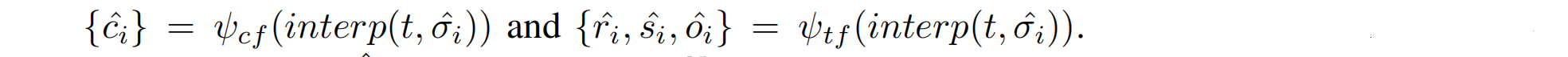
10.MVSplat360:稀疏场景的360视角合成(NeurIPS 2024 √)
项目:https://donydchen.github.io/mvsplat360/
标题:MVSplat360: Feed-Forward 360 Scene Synthesis from Sparse Views
来源:莫纳什大学;牛津大学
代价体 + 视频扩散先验模型,实现稀疏输入条件下的360度NVS
摘要:仅使用稀疏观察(5张左右),MVSplat360通过结合几何感知的三维重建和时间一致的视频生成来解决这个问题。具体来说,它重构了前馈 3DGS,将特征直接渲染到预先训练的稳定视频扩散(SVD)模型的潜在空间中,然后这些特征作为姿态和视觉线索,指导去噪过程,并产生逼真的3D一致视图。模型是端到端可训练的,并支持仅用5个稀疏输入视图呈现任意视图。实验数据选择了 DL3DV-10K数据集。
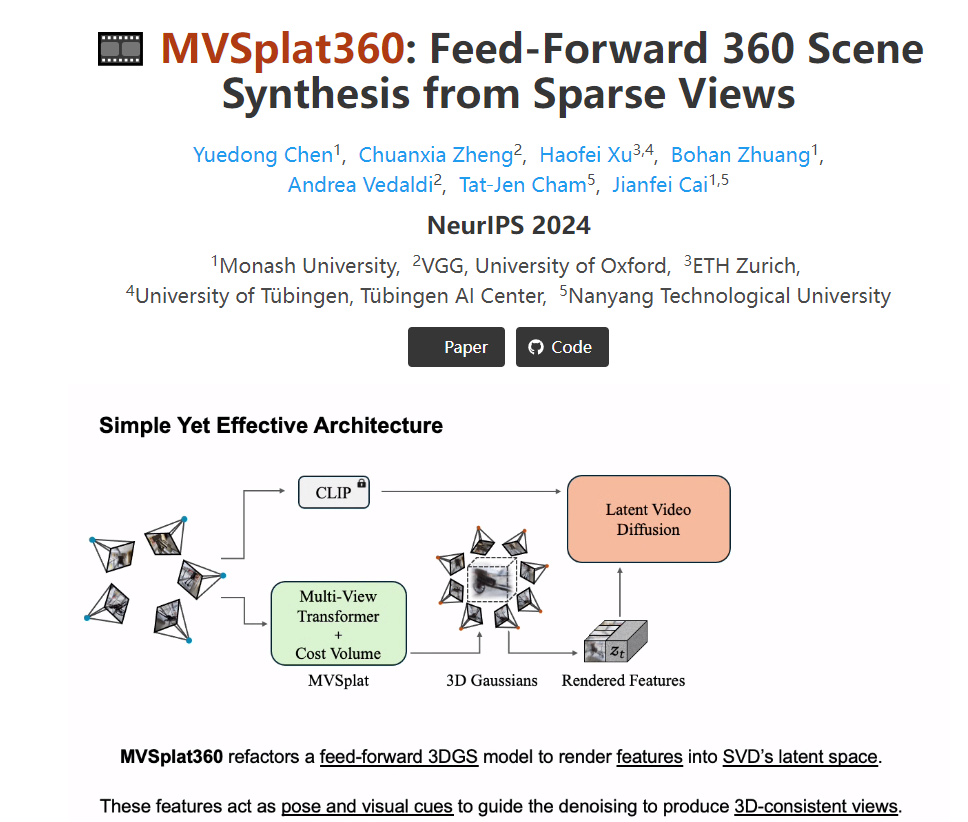
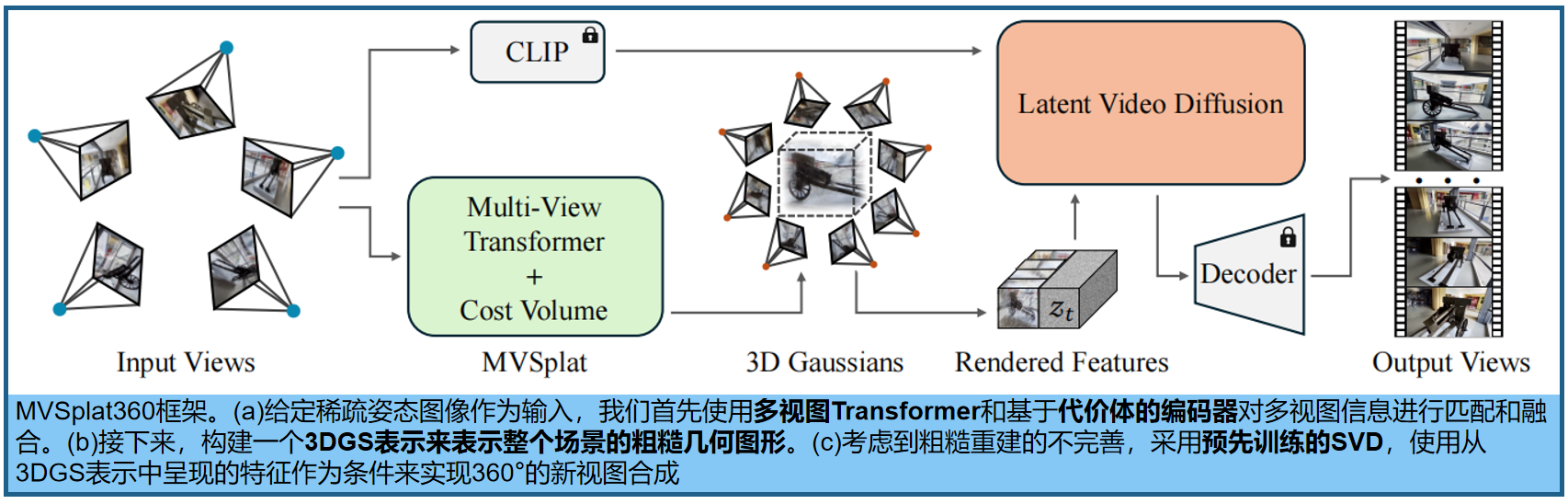
代价体的构建:通过交叉视图来扩展更多视图:



8块A100 GPU训练效果:

11. LVSM:具有最小归纳偏差的大场景合成模型(×)
来源:康奈尔大学;德克萨斯大学奥斯汀分校;adobe research
项目地址:https://haian-jin.github.io/projects/LVSM/

摘要:大视图合成模型(LVSM)基于Transformer,从稀疏视图中合成新视图。我们介绍了两种架构: (1)Encoder-decoder LVSM,,它将输入图像标记编码为固定数量的一维潜在标记,作为完全学习的场景表示,并解码新视图图像;(2)Decoder-only LVSM,它直接将输入图像映射到新视图输出,完全消除了中间场景表示。用完全数据驱动的方法来解决新的视图合成(仅解码器的LVSM实现了优越的质量、可伸缩性和零样本泛)。
用Plücker ray(由内参和外参计算而来)代替位置信息:
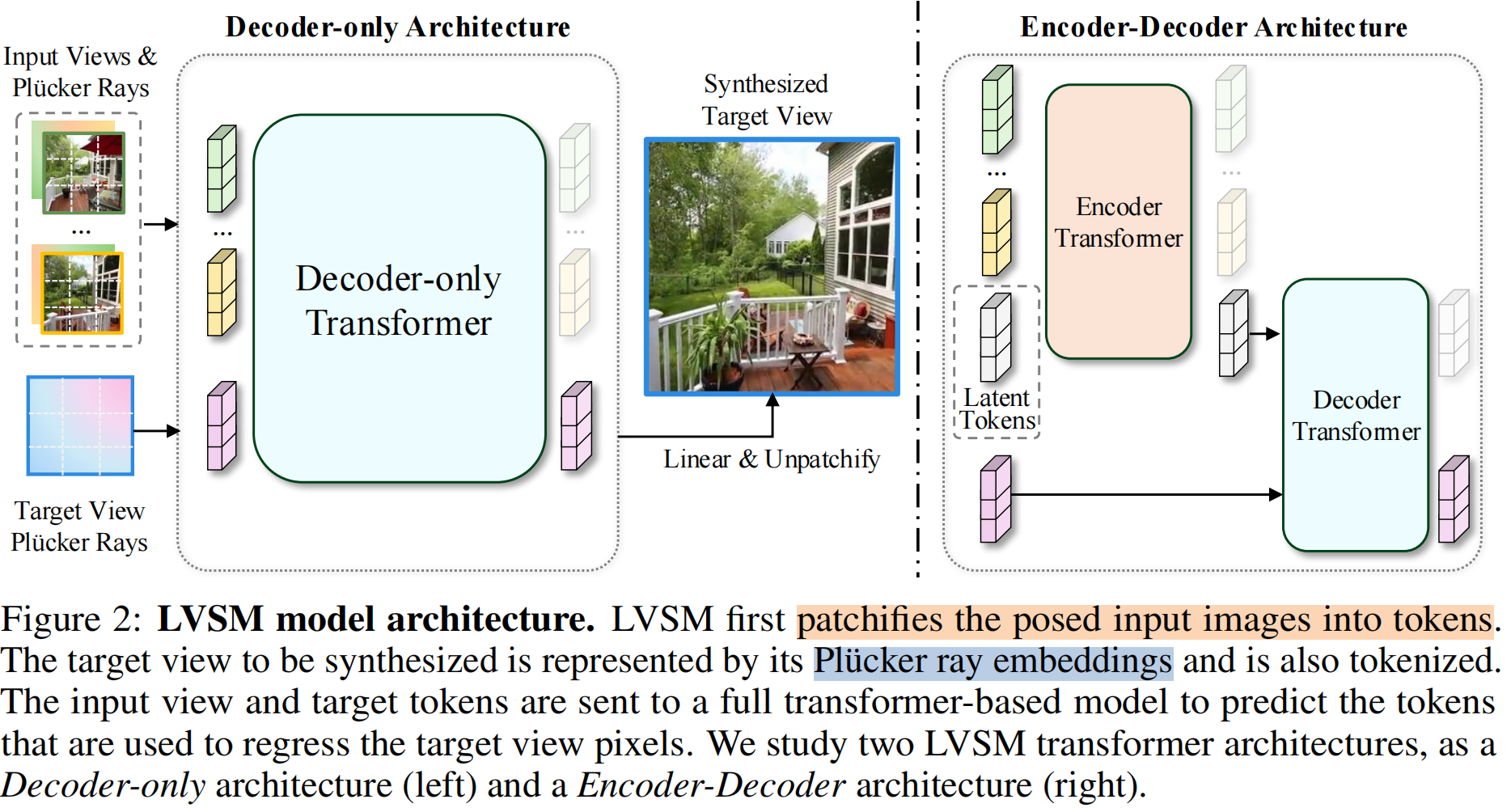
细节:

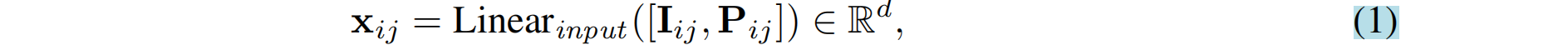

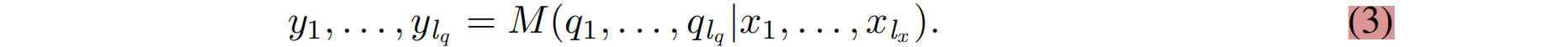
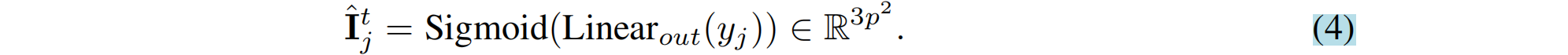
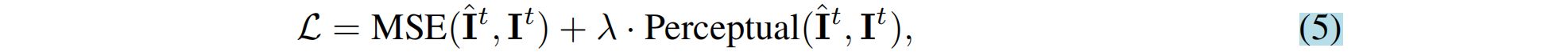
实验数据:

训练细节:实验用64个A100 GPU训练batchsize为8,训练100k。patchsize = 8和
d
t
o
k
e
n
d_{token}
dtoken = 768。Transformer层的遵循GS-LRM:所有模型有24个Transformer层;编-解码器LVSM具有12个Encoder层和12个Decoder层。
对象级实验,每个训练物体使用4个输入视图和8个目标视图。首先以256的分辨率进行训练,编码器-解码器模型需要4天,仅解码器模型需要7天。然后,我们以512,学习率为4e-5,较小的批处理规模为128,需要2.5天。对于场景级的实验,我们为每个训练示例使用2个输入视图和6个目标视图。我们首先以256的分辨率进行训练,对于编码器-解码器和仅解码器的模型,这大约需要3天。然后,我们对20k迭代的模型微调分辨率为512,学习率更小,为1e-4,总batch为128,持续3天。
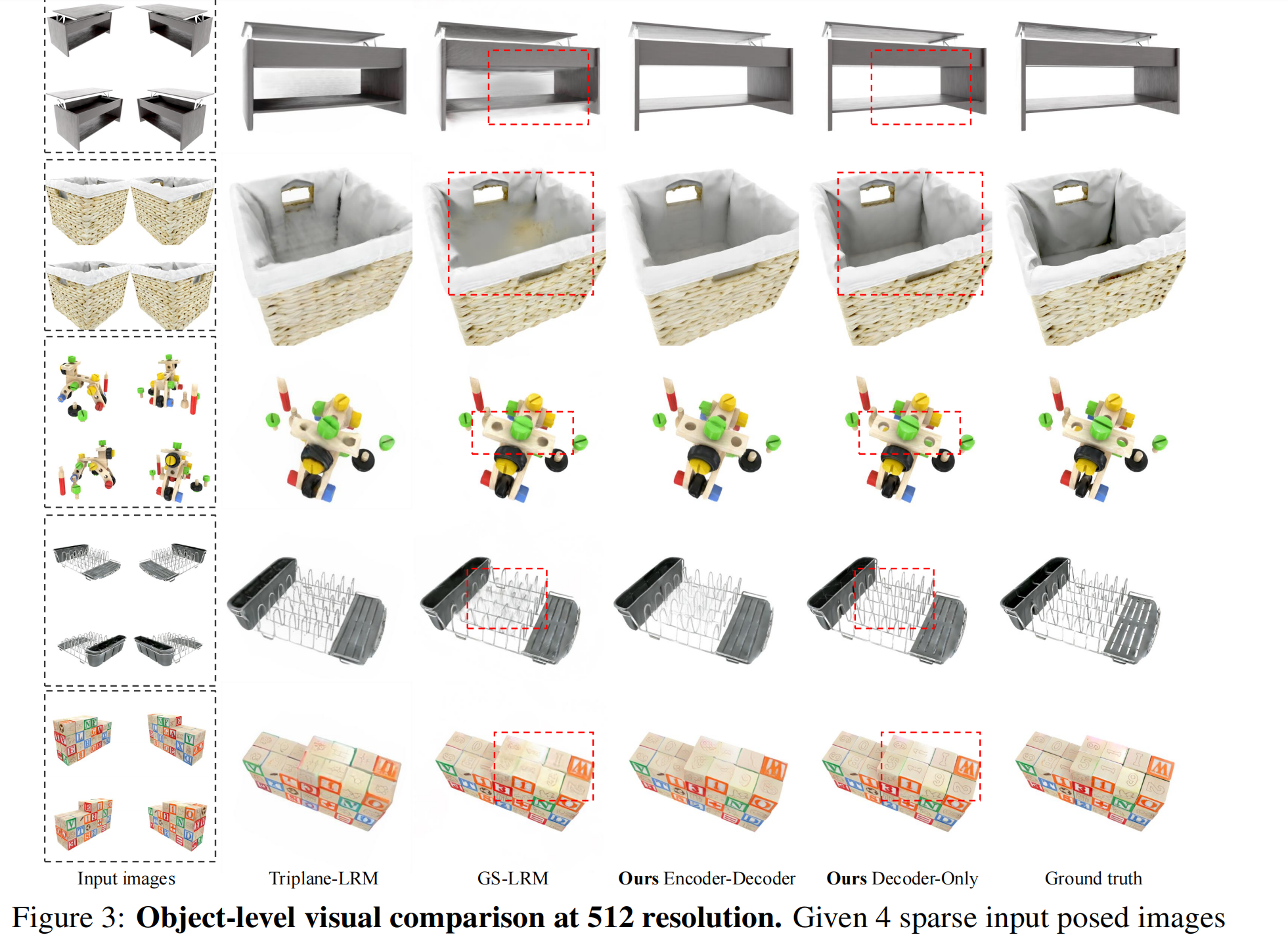
物体级结果:
场景级结果:

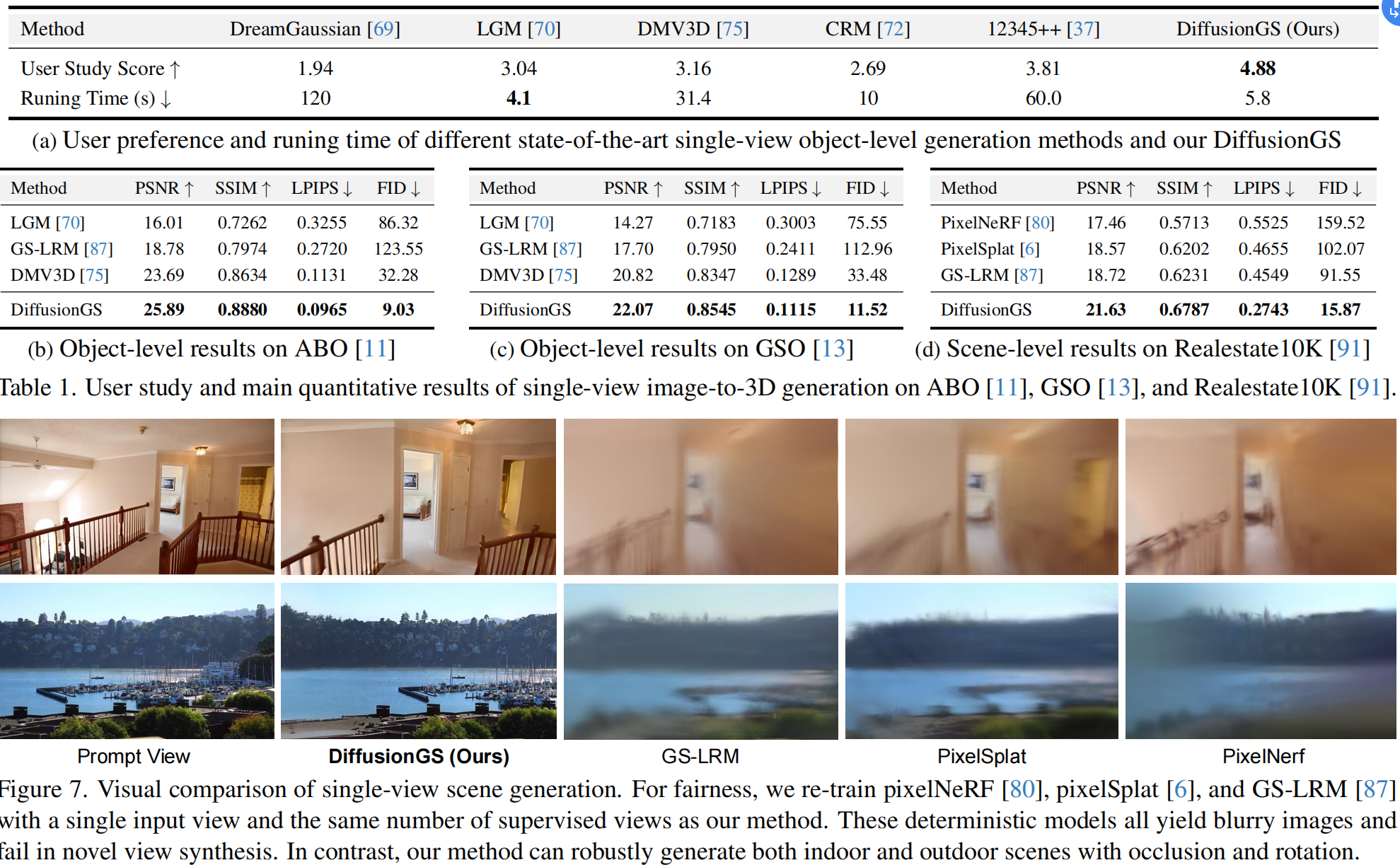
12. DiffusionGS:基于GS的可扩展单阶段图像生成GS模型(x)

标题:Baking Gaussian Splatting into Diffusion Denoiser for Fast and Scalable Single-stage Image-to-3D Generation
来源:Johns Hopkins University, Adobe Research
链接:https://caiyuanhao1998.github.io/project/DiffusionGS/
图4为DiffusionGS的框架。4 (a)为场景-对象混合训练。对于每个场景或对象,选取一个视图作为条件,N个视图作为要去噪的噪声视图,以及M个新视图作为监督。然后在图4 (b)中,将干净的和有噪声的视图输入到DiffusionGS中,以预测每像素的三维高斯原语。
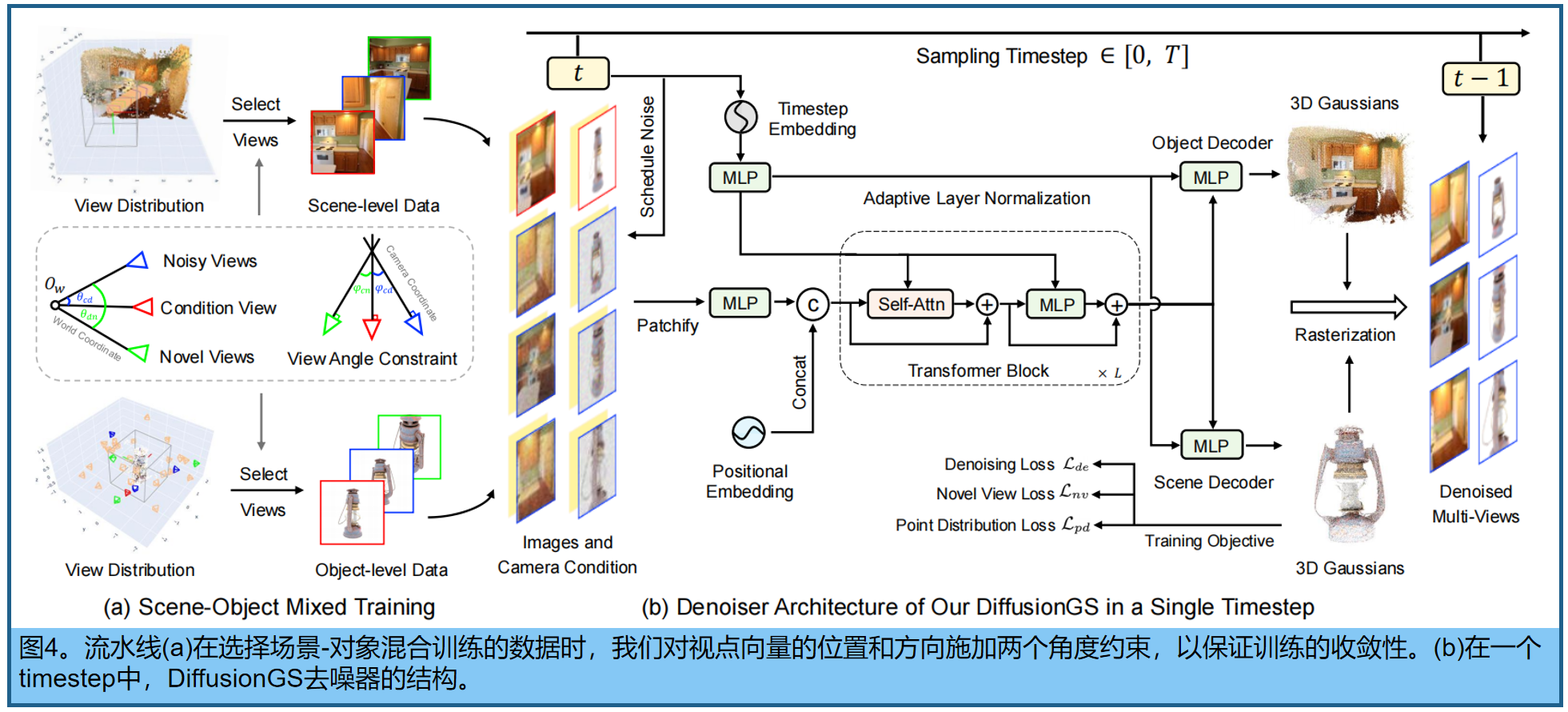
图像扩散模型的训练、测试原理如下:

目标是恢复干净的三维高斯点云。因此,去噪器直接预测像素对齐的三维高斯,并在干净的二维多视图渲染中进行监督。
如图4(b),DiffusionGS在训练阶段的输入:一个条件视图
x
c
o
n
∈
R
H
×
W
×
3
x_{con}∈R^{H×W×3}
xcon∈RH×W×3 和
N
N
N个噪声视图
X
t
X_t
Xt={
x
t
(
1
)
,
x
t
(
2
)
,
⋅
⋅
⋅
,
x
t
(
N
)
x_t^{(1)},x_t^{(2)},···,x_t^{(N)}
xt(1),xt(2),⋅⋅⋅,xt(N)),与视点条件
v
c
o
n
∈
R
H
×
W
×
6
v_{con}∈R^{H×W×6}
vcon∈RH×W×6和
V
V
V={(
v
(
1
)
,
v
(
2
)
,
⋅
⋅
⋅
,
v
(
N
)
v^{(1)},v^{(2)},···,v^{ (N)}
v(1),v(2),⋅⋅⋅,v(N)}拼接在一起。噪声视图的干净对应项为
X
0
X_0
X0={
x
0
(
1
)
,
x
0
(
2
)
,
⋅
⋅
⋅
,
x
0
(
N
)
x_0^{(1)},x_0^{(2)},···,x_0^{(N)}
x0(1),x0(2),⋅⋅⋅,x0(N))。前向扩散过程为每个视图添加噪声:
本文采用像素对齐的三维高斯函数作为输出,其数量是固定的。预测的三维高斯
G
θ
G_θ
Gθ表示为:
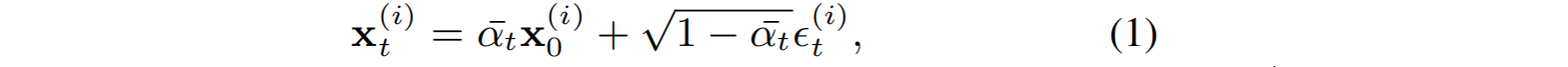
其中,
1
≤
k
≤
N
g
1≤k≤N_g
1≤k≤Ng,
N
g
=
(
N
+
1
)
H
W
N_g =(N +1)HW
Ng=(N+1)HW为逐像素高斯
G
t
(
k
)
G_t^{(k)}
Gt(k)的数量。
具体来说, µ t ( k ) µ_t^{(k)} µt(k)= o ( k ) o^{(k)} o(k)+ u t ( k ) d ( k ) u_t^{(k)}d^{(k)} ut(k)d(k)。 o ( k ) o^{(k)} o(k)和 d ( k ) d^{(k)} d(k)是第k个像素对齐射线的原点和方向。距离 µ t ( k ) µ_t^{(k)} µt(k)的参数化方法为:
u
f
a
r
u_{far}
ufar是最近和最远的距离。
w
t
(
k
)
w_t^{(k)}
wt(k)∈R是控制
u
t
(
k
)
u_t^{(k)}
ut(k)的权重。Σ由一个旋转矩阵
R
t
(
k
)
R_t^{(k)}
Rt(k)和一个缩放矩阵
S
t
(
k
)
S _t^{(k)}
St(k)参数化。
w
t
(
k
)
w_t^{(k)}
wt(k),
R
t
(
k
)
R_t^{(k)}
Rt(k),
S
t
(
k
)
S _t^{(k)}
St(k),
α
t
(
k
)
α_t^{(k)}
αt(k),
c
t
(
k
)
c_t^{(k)}
ct(k)来自不同的通道,直接从合并的逐像素高斯映射中提取。

Denoiser框架。如图4 (b),将与视点条件连接的输入图像进行patch化、线性投影,然后与位置嵌入拼接,得到Transformer(由L个block组成)的输入token。每个block包含一个多头自注意(MSA)、一个MLP和两层归一化(LN)。
DiffusionGS是预测 x 0 x_0 x0而不是预测ϵ。去噪后的多视点图像 X ^ ( 0 , t ) \hat{X}_{(0,t)} X^(0,t)= x ^ ( 0 , t ) ( 1 ) \hat{x}_{(0,t)}^{(1)} x^(0,t)(1), x ^ ( 0 , t ) ( 2 ) \hat{x}_{(0,t)}^{(2)} x^(0,t)(2),···, x ^ ( 0 , t ) ( N ) \hat{x}_{(0,t)}^{(N)} x^(0,t)(N))}由可微栅格化函数 F r F_r Fr渲染:
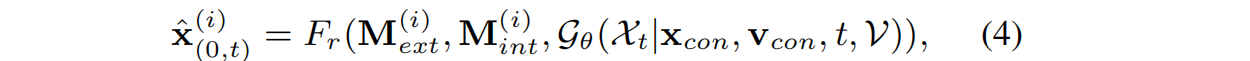
然后使用由λ控制的多视点预测图像和标签 X 0 X_0 X0之间的L2损失和VGG-19感知损失加权去噪损失,来监督三维高斯 G θ G_θ Gθ:
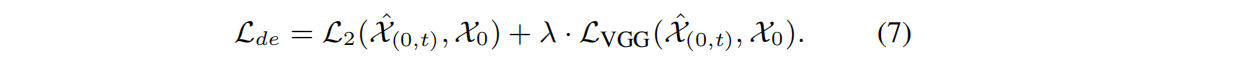
Scene-Object 混合训练策略:控制选定视图的分布、摄像机条件、高斯点云和成像深度。
视点选择 。第一步是选择观点。为了更好地收敛训练过程,我们对摄像机的位置和方向施加了两个角度约束,以确保噪声视图和新视图与条件视图有一定的重叠。 第一个约束是关于视点位置之间的角度 。经过归一化后,这个角度测量视点的距离。由于噪声视图只能提供部分信息,我们控制了第i个噪声视图位置与条件视图位置之间的角度 θ c d ( i ) θ_{cd}^{(i)} θcd(i),以及第i个噪声视图位置与第j个新视图位置之间的角度 θ d n ( i , j ) θ_{dn}^{(i,j)} θdn(i,j)。约束条件是:
其中θ1和θ2为超参数,1≤i≤N,1≤j≤m。位置向量可以从摄像机到世界(c2w)的视点矩阵中读取
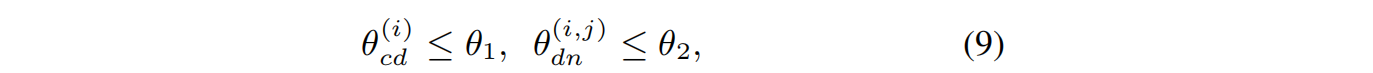
第二个约束条件是关于视点方向之间的角度。这个角度还控制着不同视点的重叠。将条件视图、第i个噪声视图和第j个新视图的forward direction vectors表示为 z c o n z_{con} zcon, z n o i s e ( i ) z_{noise} ^{(i)} znoise(i)和 z n v ( j ) z_{nv}^{(j)} znv(j)。约束条件是:
φ1和φ2都是超参数。
z
ˉ
\bar{z}
zˉ是从c2w中读取的。
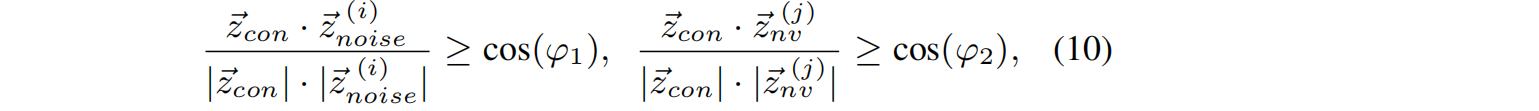
数据集。对象级:使用Objaverse 和 MVImgNet 数据,将对象集中并缩放成 [ − 1 , 1 ] 3 [−1,1]^3 [−1,1]3,用 5 0 ◦ 50^◦ 50◦FOV以随机视点渲染32张图像。评估使用ABO 和GSO 数据集。每个评估实例都有1个输入视图和10个测试视图。场景级:采用RealEstate10K [来自YouTube的80K室内外真实场景]和DL3DV10K [10510个真实场景的视频,涵盖96个类别]。
实施细节。为了节省GPU内存,使用BF16的混合精度训练。混合训练使用32个A100gpu在Objaverse 、MVImgNet、RealEstate10K和DL3DV10K上对模型进行训练,在每个gpubatch为16,进行40K迭代。然后在64个A100gpu的对象和场景级数据集上微调模型,在8和16次时进行80K和54K迭代。最后将训练分辨率从256×256扩展到512×512,并对模型进行了20K迭代的微调。
13.InFusion:扩散模型助力,替换补全场景
项目主页: https://johanan528.github.io/Infusion/
代码仓库: https://github.com/ali-vilab/infusion
机构单位: 中科大,港科大,蚂蚁,阿里巴巴
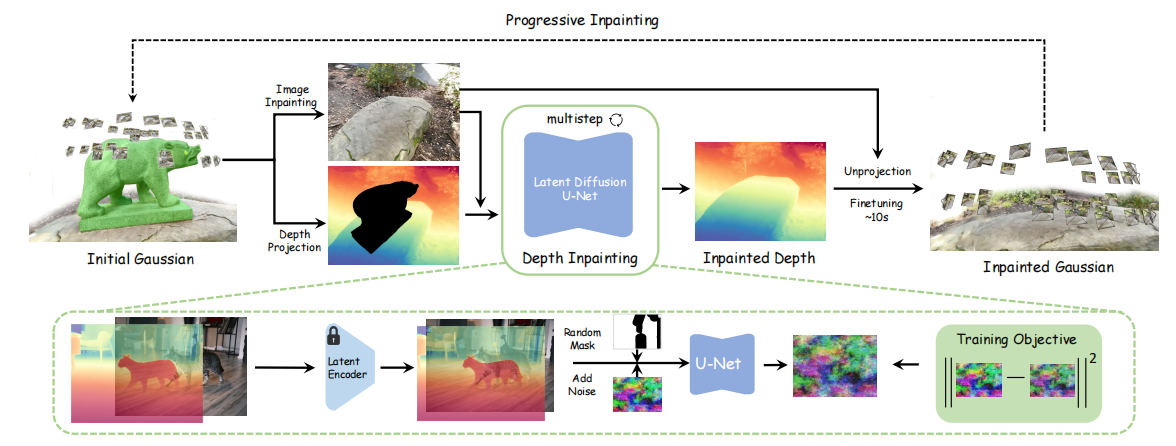
整体流程如下:
1)场景编辑初始化:首先,根据编辑需求和提供的mask,构造残缺的高斯场景。
2)深度补全:选择一个视角,渲染得到的利用图像修复模型如(Stable Diffusion XL Inpainting )进行,修复单张RGB图像。再利用深度补全模型(基于观测图像)预测出缺失区域的深度信息,生成补全的深度图。具体来说,深度补全模型接受三个输入:从3D高斯渲染得到的深度图、相应的修复后彩色图像和一个掩码,其中掩码定义了需要补全的区域。先使用变分自编码器(VAE)将深度图和彩色图像编码到潜在空间中。其中通过将深度图重复使其适合VAE的输入要求,并应用线性归一化,使得深度值主要位于[-1, 1]区间内。后将编码后的深度图加噪得到的近高斯噪声,将掩码区域设置为0的编码后的深度图,编码后的RGB指导图像,以及掩码图像,在channel维度进行连接,输入到U-Net网络进行去噪,逐步从噪声中恢复出干净的深度潜在表示。再次通过VAE解码得到补全后的深度图。
3)3D点云构建:使用补全的深度图和对应的彩色图,通过3D空间中的反投影操作,将2D图像点转换为3D点云,这些点云随后与原始的3D高斯体集合合并。
4)Gaussian模型优化:合并后的3D点云通过进一步迭代优化和调整,以确保新补全的高斯体与原始场景在视觉上的一致性和平滑过渡。
14.Bootstrap 3D:从扩散模型引导三维重建

标题:Bootstrap 3D Reconstructed Scenes from 3D Gaussian Splatting
来源:电子科技大学;深圳先进技术研究院;中科院

训练数据集之外,存在一些看不见的部分,训练过的3DGS合成的新视图 I I I,可能不能准确地反映GT图像。我们将 I I I 视为 I ′ I' I′ 的“部分退化版本”。可以利用扩散模型,实现对 I I I 的 image-to-image integration,得到image density I ′ I' I′ 。
实践中实现这种理想的情况是非常困难的。这不仅是因为 1.目前可用的开源扩散模型不能很好地生成所有场景中的部分图像 ,而且还因为 2.许多场景本身都是复杂和独特的 。此外, 3.引导(bootstrap)的过程也引入了一定程度的不确定性 。理想情况下,构建的3D场景在所有角度都保持一致。然而,扩散模型引入的可变性使得保证扩散模型从一个新视角重新生成的场景与来自另一个新视角的场景无缝对齐具有挑战性。另外, 4.并不是合成的新视图图像的所有部分都应该被再生 ,如果我们将扩散过程应用到整个图像中,一些已经训练良好的部分会在一定程度上被扭曲。本文探索了一种更通用、更稳定的方法。
为了从训练图像 I t I_t It 中获得新图像 I n t I_n^t Int,稍微改变训练相机的 q v e c qvec qvec 和 t v e c tvec tvec,以获得新的视图相机。然后通过扩散模型D,重新生成 I d t I_d^t Idt=D( I n t I_n^t Int)。实践中,从每个训练像机中生成多个新视图。
可控的扩散方向。 重新生成的内容分为两个部分: 一个包含了对场景的忠实表示,但随着改变而改变,另一个显示了被扩散模型修改的场景的新的表示 。通过管理原始训练部分和bootstrap部分相关的损失比值,我们可以实现3D-GS模型的全局稳定训练过程。
bootstrap损失: L b L_b Lb= || I d t I_d^t Idt - I n t I_n^t Int||;对每个训练像机,使用混合损失( L o L_o Lo是GT图像的原始3D-GS损失):
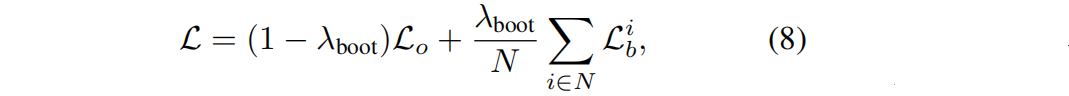
补偿过程往往是不稳定的,因为渲染甚至在同一场景部分也发生变化。 然而,本文利用多个重新生成的新视图,来训练单个视图 。对于这些渲染,如果其中的细节不冲突,那么它们能表示看不见的细节,或可以自由修改的粗糙建模;如果它们之间存在冲突,则选择最普遍适用的方法来对齐。给定一个受到不同梯度方向更新的点,称为 ∑ i ∈ m ∂ g m \sum_{i∈m}∂g_m ∑i∈m∂gm。 m m m 为不同梯度方向的总数, ∂ g m ∂g_m ∂gm为对应的梯度。如果我们将这些高维梯度方向抽象成简单的二维方向,我们就可以进一步简化这个问题。
假设二维xy平面上的每个梯度只包含两个方向,正y指向GT,x表示偏差,为了简单起见,我们将每个方向分离成一个累积形式。我们假设扩散模型通常产生的图像与背景一致,但细节有所不同。然后通过建立一个适当的梯度积累幅度阈值,并将其与我们在等式8中概述的优化策略相结合,可以达到所期望的优化结果,如图3所示。
经过几轮分裂后,点将足够小,在这些点上只会出现少量的梯度(即使没有,λboot也足够小)。为了进一步克隆,只有这些恰好指向一个方向的梯度和较小的偏差才有可能超过这个阈值,然后我们得到一个相对可靠的bootstrap克隆点,构成了该场景中的细节。

实验
数据集。数据集包括Mip-NeRF360 [83]的7个场景,两个来自 Tanks&Temples[84]的场景,两个场景来自 DeepBlending[85]的场景。
Baseline。原始3D-GS [1], Mip-NeRF360 [83],
iNGP [10] 和 Plenoxels [9],以及最近的 Scaffold-GS。
设置。对于bootstrap部分,使用 Stable Diffusion (SD) 2v.1模型 [30]及其精调模型作为初始扩散模型。共进行了4个阶段的实验,其中何时和如何应用bootstrap是不同的。实验初始阶段,以特定的时间间隔执行bootstrap,为每个引导跨度提供1000次迭代。在这1000次迭代间隔中,我们在前500次迭代中将 λ b o o t λ_{boot} λboot设置为 0.15,在剩下的500次迭代中将其降低为 0.05。在配置扩散模型时,我们采用了一个逐步降低的图像破损强度 s r s_r sr,范围从0.05到0.01,跨越100个DDIM [28]采样的时间步长。不同的数据集,有不同的策略来创建新的视图像机(随机或连续)。引导重新生成的图像将使用原始的SD2.1v模型来执行。在第二阶段的实验中,SD2.1v模型分别对每个训练数据集进行细化,同时保持其他配置不变。调整SD2.1v模型,结果有显著的波动:一些场景在指标上显示了明显的进展,而另一些场景表现出明显的退化,4.2节会讨论到。
在对每个场景的模型进行微调之后,为进一步解锁bootstrap的潜力,在第三阶段实验中,将扩散破损强度 s r s_r sr从0.15调整到0.01,每个场景的所有bootstrap图像都设置为随机。虽然最初三个阶段的实验已经证明了比最初的3D-GS有相当大的改进,但在渲染特定视图方面仍然存在挑战。因此,在第四阶段实验中,使用了一个upscale的扩散模型来进行bootstrap再生。

15.Flash3D:单张图像重建场景的GaussianSplatting
设
I
I
I∈
R
3
×
H
×
W
R^{3×H×W}
R3×H×W 是一个场景的RGB图像。我们的目标是学习一个神经网络Φ,它以
I
I
I作为输入,并预测场景的3D内容的表示
G
G
G =
Φ
(
I
)
Φ(I)
Φ(I),包含了三维几何和光学。

为了泛化,在大量数据训练的高质量的预训练模型上构建Flash3D。考虑到单目场景重建和单目深度估计之间的相似性,使用一个现成的单目深度预测器 Ψ Ψ Ψ:返回一个深度映射 D = Ψ ( I ) D = Ψ(I) D=Ψ(I),其中 D ∈ R + H × W D∈R^{H×W}_+ D∈R+H×W.
基础框架。基线网络 Φ ( I , D ) Φ(I,D) Φ(I,D) 输入图像 I I I和估计的深度图 D D D,,返回所需的每像素的高斯参数。具体地,对于每个像素u, 条目 [ Φ ( I , D ) ] u [Φ(I,D)]_u [Φ(I,D)]u = ( σ , ∆ , s , θ , c ) (σ,∆,s,θ,c) (σ,∆,s,θ,c)包括不透明度 σ ∈ R + σ∈R_+ σ∈R+,位移 ∆ ∈ R 3 ∆∈R^3 ∆∈R3,尺度 s ∈ R 3 s∈R^3 s∈R3,参数化旋转R(θ)的四元数 θ ∈ R 4 θ∈R^4 θ∈R4,和颜色参数c 。每个高斯的协方差由 Σ = R ( θ ) T d i a g ( s ) R ( θ ) Σ=R(θ)^Tdiag(s)R(θ) Σ=R(θ)Tdiag(s)R(θ),均值由 µ = ( u x d / f , u y d / f , d ) + ∆ µ=(u_xd/f,u_yd/f,d)+∆ µ=(uxd/f,uyd/f,d)+∆,其中f是相机的焦距(已知或来自估计Ψ)和来自深度图的 d = D ( u ) d=D(u) d=D(u)。网络Φ是一个U-Net ,利用ResNetBlock进行编码和解码。解码器网络输出一个张量 Φ d e c ( Φ e n c ( I , D ) ) ∈ R ( C − 1 ) × H × W Φ_{dec}(Φ_{enc}(I,D))∈R^{(C−1)×H×W} Φdec(Φenc(I,D))∈R(C−1)×H×W。请注意,网络输出只有C−1通道,因为深度是直接从Ψ获取的。
额外添加一个背景高斯。虽然上述模型中的高斯值能够从相应的像素的射线上得到偏移,但每个高斯值都很自然地倾向于对投射到该像素上的物体部分进行建模。斯曼诺维茨等人[68]指出,对于单个对象,大量的背景像素与任何对象表面都没有关联,这些背景像素可以被模型重新利用,以捕捉3D对象中未观察到的部分。然而,场景却不是这样,场景的目标是重建每个输入像素,甚至更远。
由于没有“空闲”像素,模型很难重新利用一些高斯模型来建模遮挡周围和图像视场之外的3D场景。因此,我们建议对每个像素预测K > 1个不同的高斯分布。从概念上讲,给定一个图像I和一个估计的深度图D,我们的网络预测每个像素u的一组:形状、位置和外观参数 P = ( σ i , δ i , ∆ i , Σ i , c i ) i = 1 K P={(σ_i,δ_i,∆_i,Σ_i,c_i)}^K_{i=1} P=(σi,δi,∆i,Σi,ci)i=1K,其中第i个高斯分布的深度来自:

其中 d = D ( u ) d = D(u) d=D(u) 为深度图D中像素u处的预测深度, δ 1 δ_1 δ1 = 0为常数。由于深度偏移量 δ i δ_i δi不能是负的,这确保了后续的高斯层“落后于”之前的层,并鼓励网络建模封闭的表面。第i个高斯分布的均值由 µ i = ( u x d i / f , u y d i / f , d i ) + ∆ i µ_i=(u_xd_i/f,u_yd_i/f,d_i)+∆_i µi=(uxdi/f,uydi/f,di)+∆i给出。在实践中,我们发现K = 2是一个足够表达性的表示。
通过padding 越过边界进行重建。网络能够在视场之外建模3D内容是很重要的。虽然多高斯层在这方面有帮助,但通过填充物越过边界进行重建。正如我们的经验所表明的那样,对于网络能够在其视场之外建模3D内容是很重要的。虽然多高斯层在这方面有帮助,但在图像边界附近,特别需要额外的高斯层(例如,当缩放图像时,能够进行良好的新视图合成)。为了便于获得这样的高斯分布,编码器 Φ e n c Φ_{enc} Φenc首先将输入图像和深度 ( I , D ) (I,D) (I,D) 的每个边上填充P > 0个像素,以便输出 Φ k ( I , D ) ∈ R ( C − 1 ) × ( H + 2 P ) × ( W + 2 P ) Φ_k(I,D)∈R^{(C−1)×(H+2P)×(W+2P)} Φk(I,D)∈R(C−1)×(H+2P)×(W+2P) 大于输入。
实验
分为四个关键的发现:1.跨数据集泛化——利用单目深度预测网络和对单个数据集进行训练,可以在其他数据集上获得良好的重建质量(4.2节)。2.通过与专门为该任务设计的方法进行比较,我们确定了Flash3D可以作为单视图三维重建的有效表示。3.单视图Flash3D学习到的先验与通过双视图方法对比(效果相同)。最后是烧蚀研究。
数据集。Flash3D只在大规模的RealEstate10k[72]数据集上进行训练,其中包含了来自YouTube的房产视频。我们遵循默认的训练/测试分割,使用67,477个场景进行训练,使用7,289个场景进行测试。
指标。pixel-level PSNR, patch-level SSIM,以及 feature-level LPIPS.
对比方法。几种单视图场景重建方法,包括LDI [76]、 Single-View MPI [74]、SynSin [84]、BTS [85]和MINE [36]。也比较了最先进的双视图新视图合成方法,包括[14],pixelSplatSplat[9],MVSplat[11],和latentSplat[83]。
实施细节。Flash3D包括一个预先训练的单深度[47]模型,一个ResNet50 [24]编码器,以及多个深度偏移解码器和高斯解码器。整个模型在一个A6000 GPU上进行40,000次迭代,batchsize为16。Unidepth在训练过程中保持冻结,通过预提取整个数据集的深度图来加快训练。
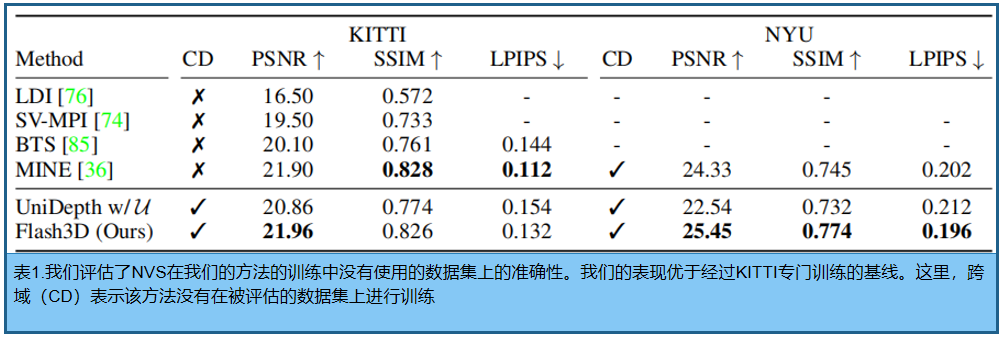
跨域新视角合成
为了评估跨域泛化能力,在不可见的室外(KITTI [17])和室内(NYU [61])数据集上的性能。对于KITTI,使用一个完善的评估方案,使用1079张图像进行测试。
域内新视图合成
RealEstate10k评估source和target之间不同距离下的重建质量,因为较小的距离会使任务更容易。


16.Edify 3D:可扩展的高质量的3D资产生成(英伟达)
标题:Edify 3D: Scalable High-Quality 3D Asset Generation
项目:https://research.nvidia.com/labs/dir/edify-3d
demo:https://build.nvidia.com/Shutterstock/edify-3d
Edify 3D,一种为高质量的3D资产生成而设计的高级解决方案。我们的方法首先使用扩散模型在多个视点上合成所描述对象的RGB和表面法线图像。然后使用多视图观测来重建物体的形状、纹理和PBR材料。我们的方法可以在2分钟内生成具有详细的几何图形、干净的形状拓扑、高分辨率拓扑的高质量纹理和材料
核心功能:
- 文本到3D的生成。给定输入文本描述,Edify 3D生成具有上述属性的数字3D资产。
- 图像到三维图像的生成。Edify 3D还可以从对象的参考图像中创建一个3D资产,自动识别图像中的前景对象。
模型设计:
Edify 3D的核心技术依赖于两种类型的神经网络:扩散模型 和Transformer。随着更多的培训数据可用,这两种架构都显示出了巨大的可伸缩性(scalability)和在提高生成质量方面的成功。 按照Sugar(2024) ,我们训练了以下模型:
- 多视图扩散模型。训练多个扩散模型,从多个角度合成一个物体的RGB外观和表面法线( Flexible isosurface extraction for gradient-based mesh optimization,2023 )。输入可以是文本提示符、参考图像,或者两者都有。
- 重建模型。利用合成的多视图RGB和表面法线图像,一个重建模型预测了三维形状的几何形状、纹理和材料。**基于Transformer(LRM 2023)**来预测三维对象作为潜在标记的神经表征,然后进行等面提取和网格处理
Edify 3D的最终输出是一个3D资产,其中包括网格几何、纹理贴图和材质贴图。图2为Edify 3D的整体管道。
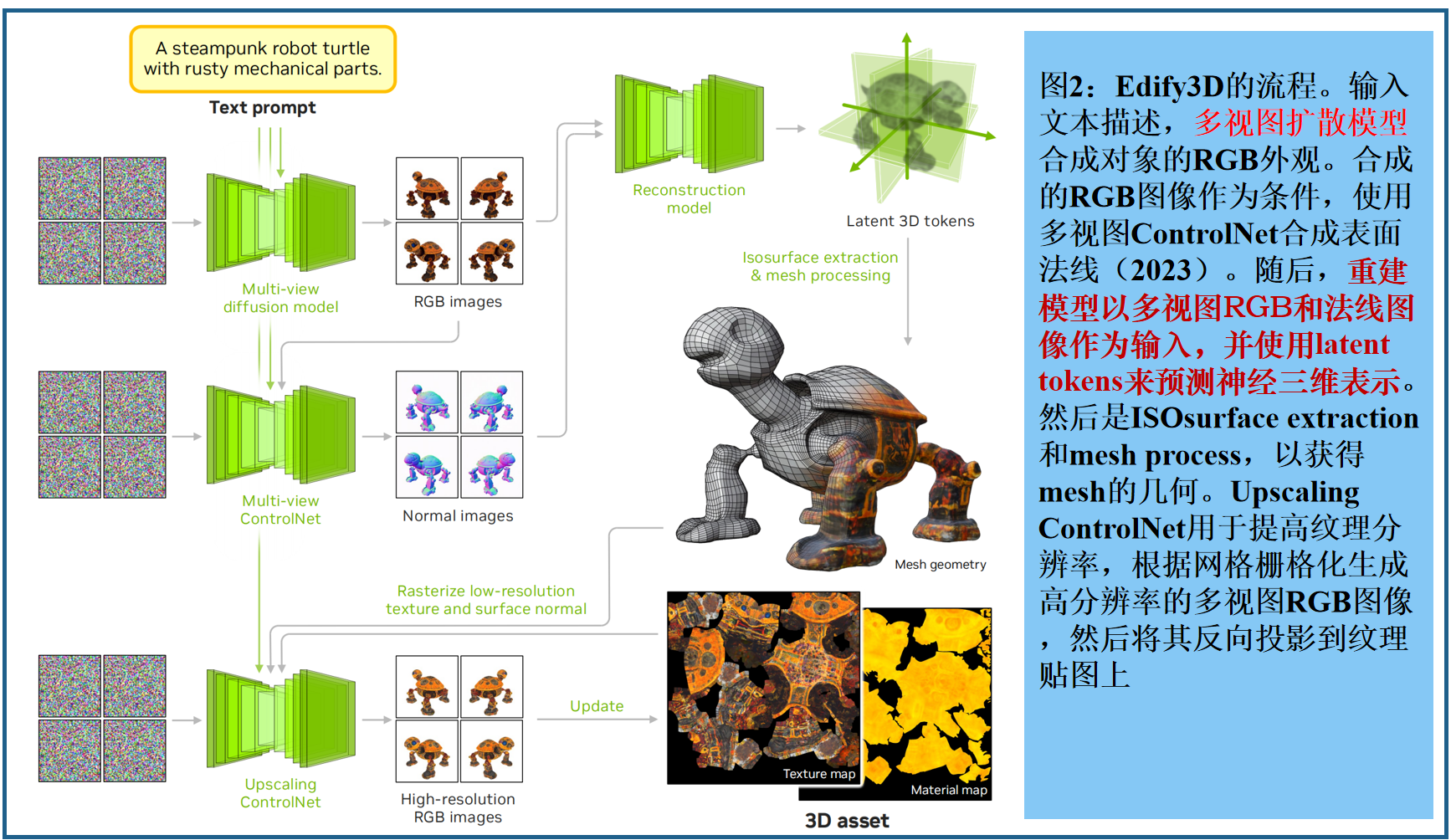
多视图扩散模型
创建多视图图像的过程类似于视频生成。我们将Text-2-Img模型微调为姿态感知的多视图扩散模型。模型以文本提示和相机姿态作为输入,从不同的角度合成物体的外观。训练出以下模型:
- 1.一个基本的多视图扩散模型,基于输入文本提示和相机姿态合成RGB外观。
- 2.一个多视图 ControlNet,合成对象的表面法线,以多视图RGB合成和文本提示为条件。
- 3.一种多视图的 upscaling ControlNet,它将多视图RGB图像超解析为更高的分辨率,条件是给定3D网格的栅格化纹理和表面法线
使用 Edify Image模型(NVIDIA 2024) 作为基础扩散模型架构(具有27亿个参数的U-Net),在像素空间中操作扩散。ControlNet 编码器使用来自U-Net的权重进行初始化,并扩展了原始文本到图像的扩散模型中的自注意层, 用一种新的机制来关注不同的视图(图3) ,作为一个具有相同权重的视频扩散模型。摄像机的pose(旋转和平移)通过一个轻量级的MLP进行编码,该MLP随后被作为时间嵌入添加到视频扩散模型架构中。
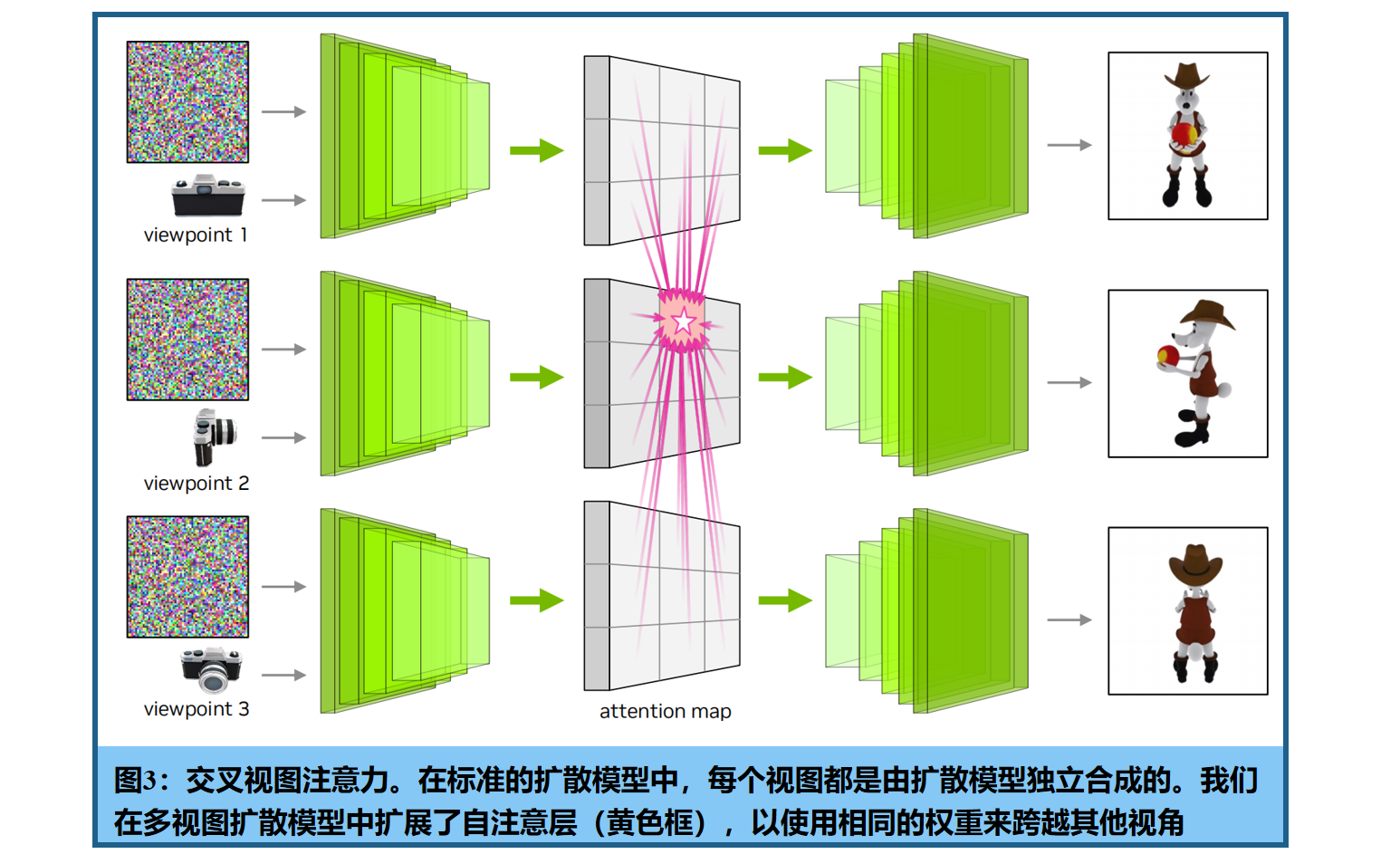
训练。在渲染图上微调 text-to-Img 模型。联合训练使用随机选择的视图数量(1、4和8)。多视图ControlNet 首先用多视图曲面法线图像来训练base模型。随后添加了一个以RGB图像为输入的ControlNet encoder,冻结base模型来训练。
消融研究
根据视角数量进行缩放。推理过程中,可以采样任意数量的视图,同时保持良好的多视图一致性,如图4所示。生成更多的视图,可以在多视图图像中更广泛地覆盖对象的区域,得到的三维重建的质量更好。
跨不同数量的观点进行训练。训练时,为每个训练对象采样1、4或8个视图,为每个视图数量分配不同的采样比,这样可以在推理过程中采样任意数量的视图,但最好将训练视图与推理过程中预期的视图相匹配。这有助于尽量减少训练和推理性能之间的差距。我们比较了两种模型——一种主要在4个视图图像上训练,另一种主要在8个视图图像上训练——并在相同的视点下采样10个视图图像。
重建模型
从图像观测中提取三维结构通常被称为摄影测量法,它已被广泛应用于许多三维重建任务。我们 使用基于Transformer 的重建模型(LRM,Adobe 2023)从多视图图像中生成三维网格几何图形、纹理贴图和材料贴图。基于Transformer 的模型对看不见的物体图像具有很强的泛化能力 ,包括从二维多视图扩散模型的合成输出。
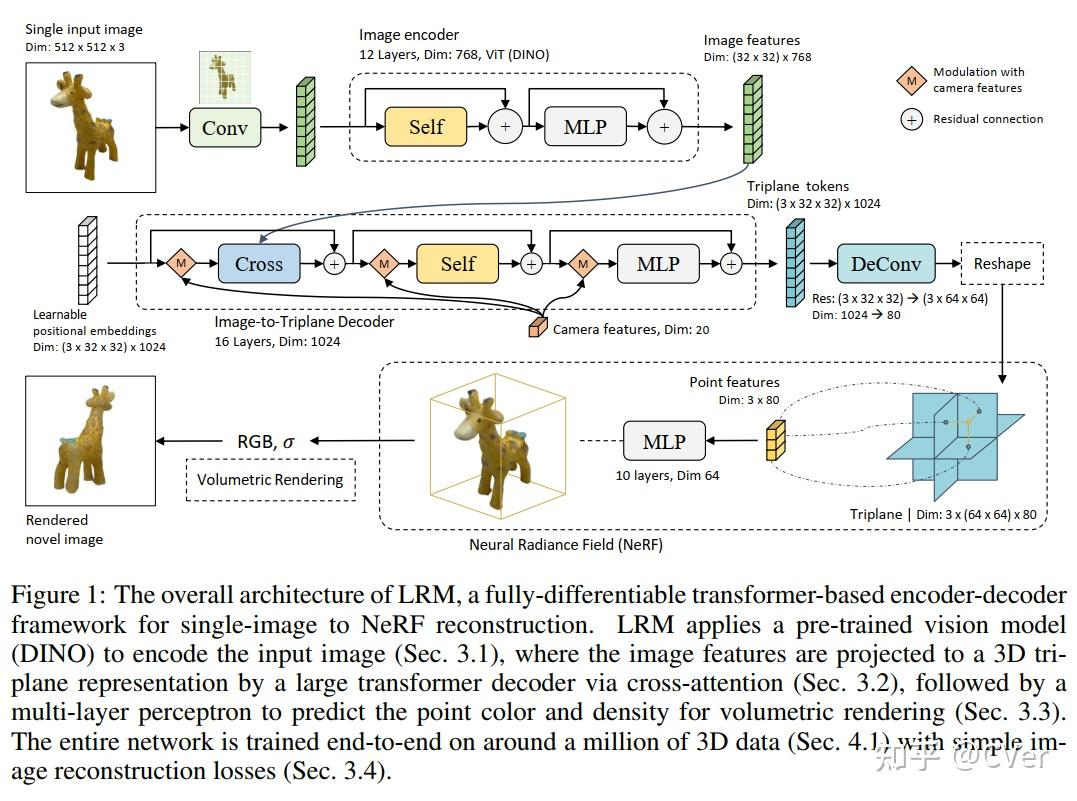
具体使用一个仅解码器的Transformer 模型,将潜在的三维表示为三平面。输入的RGB图像和法线图像作为重建模型的条件,在三平token和输入条件之间应用交叉注意力。通过MLPs对三平面标记进行处理,以预测有符号距离函数(SDF)和PBR属性的神经场(Karis,2013),这些属性用于基于SDF的体积绘制(Yariv et al.,2021)。通过isosurface extraction将神经SDF转换为三维网格(Lorensen和Cline,1998;Shen等人,2023年)。PBR属性通过UV映射被提取到纹理和材料贴图中,包括反照率颜色和材料属性,如粗糙度和金属通道。
训练 。使用大规模的图像和三维资产数据来训练我们的重建模型。通过基于sdf的体渲染,模型对深度、法线、掩码、反照率和材质通道进行监督,并从艺术家生成的网格渲染输出(model is supervised on depth, normal, mask, albedo, and material channels through SDF-based volume rendering,with outputs rendered from artist-generated meshes)。由于曲面法线计算相对昂贵,我们只在曲面上计算法线,并对地面真相进行监督。我们发现,将SDF的不确定性(Yariv et al.,2021)与相应的渲染分辨率对齐,可以提高最终输出的视觉质量。此外,我们在损失计算过程中掩蔽目标边缘,以避免混叠造成的噪声样本。为了平滑样本间的噪声梯度,我们应用指数移动平均(EMA)来聚合最终重建模型的权重。
mesh网格后处理 。从isosurface extraction 中获得稠密的三角形 3D mesh后,进行以下步骤的后处理:
- 1.Retopologize 成为具有简化几何和自适应拓扑的四边形(四)网格。
- 2.根据生成的四元网格拓扑结构生成UV映射。
- 3.将反照率和材料神经场分别烘焙成纹理图和材料图。
这些后处理步骤使生成的网格更适合于进一步的编辑,这对于面向艺术和面向设计的下游应用程序至关重要
17. ExtraNeRF:基于扩散模型的NeRF可见性视角外延(稀疏重建)
项目主页:https://shihmengli.github.io/extranerf-website/
来源:华盛顿大学,康奈尔大学,谷歌研究,加州大学伯克利分校
标题:ExtraNeRF: Visibility-Aware View Extrapolation of Neural Radiance Fields with Diffusion Models

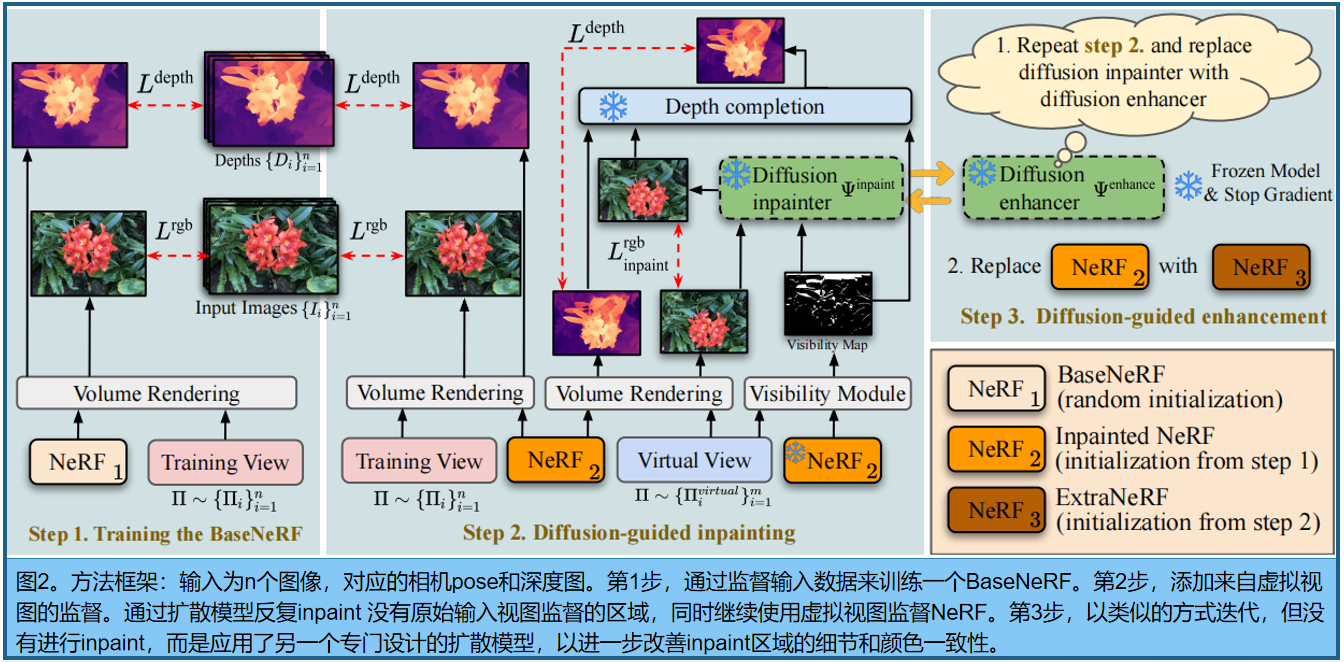
1.训练BaseNeRF :给定一组稀疏的 [ I i ] i = 1 n [{I_i}]_{i=1}^n [Ii]i=1n及其相关的相机pose和 Π i Π_i Πi,首先训练一个BaseNeRF。由于缺乏密集的多视图图像来有效地正则化底层三维空间,我们利用[Sparf:CVPR 2023]中提出的方法来计算每个输入图像的密集深度映射 [ D i ] i = 1 n [D_i]^n_{i=1} [Di]i=1n,以进行几何监督。为了进一步减少“floater”伪影,我们结合了 distortion loss[1]和hash decay loss[2],并应用 gradient scaling[34]来规范学习过程。
2.Diffusion-guided Inpainting :在超出原始查看域的原始视图和虚拟视图集上反复优化NeRF。对于每个虚拟视图,使用NeRF渲染它,然后使用扩散inpaint 模型 Ψ i n p a i n t Ψ^{inpaint} Ψinpaint 来预测未观察到的区域。我们采用了来自 [40:High-resolution image synthesis with latent diffusion models] 的潜在扩散的inpaint变体,在每个场景的基础上进一步微调(4.2节)。为了将inpaint 限制在未观察到的区域(例如NeRF缺乏监督的区域), Ψ i n p a i n t Ψ^{inpaint} Ψinpaint采用了三个输入:噪声图像、可见性mask和在绘制区域缺乏数据的屏蔽干净图像(见图3)。可见性mask是通过检查在训练图像中是否观察到每个像素处沿光线的三维样本点来计算的(见4.3节).
对于每个虚拟视图,我们还使用深度补全网络来绘制基于inpaint的彩色图像的深度(见4.3节).监督信号分别为 L i n p a i n t r g b L^{rgb}_{inpaint} Linpaintrgb and L d e p t h L^{depth} Ldepth:

类似于inpaint的迭代更新,每次训练中,1)渲染图像并从NeRF计算可见性mask,2)从渲染图像和可见性mask中创建一个三组输入数据,3)利用
Ψ
e
n
h
a
n
c
e
Ψ^{enhance}
Ψenhance 从这三组中生成一个增强的图像。与inpaint过程相比,我们没有mask out the pixels in the intact rendered image(见图3)。相反,我们希望
Ψ
e
n
h
a
n
c
e
Ψ^{enhance}
Ψenhance能够增强这些领域的细节。一旦增强的图像被生成,我们就会完成深度。最后,我们按照类似于喷漆阶段的步骤监督NeRF,但用
L
e
n
h
a
n
c
e
r
g
b
L^{rgb}_{enhance}
Lenhancergb替换
L
i
n
p
a
i
n
t
r
g
b
L^{rgb}_{inpaint}
Linpaintrgb
Visibility map。三维点如果在输入视图框之外或被更近的对象遮挡,它们可能会被隐藏。Visibility map 帮我们确定哪些区域在原始图像中没有被观察到,需要inpaint。来自NeRF的累积透光率编码了基本的可见性信息,使我们能够估计任何一个基于输入视图的三维点的可见性。 具体的 ,为了计算虚拟视图中单个像素的Visibility map,我们首先通过该像素构造一条射线。对于沿该射线的每个采样三维点,我们计算每个训练视图的透射率(如:另一条 ray march)。为了在输入视图中的透光率值,我们只需选择第二大的值。这是基于这样一个基本原理,即一个三维点的几何形状只有在被至少两个视图(三角测量的最小值)观察到时才可靠。如果一个三维点只被一个训练视图看到,它的估计深度可能是不可靠的。最后,通过体积渲染将这些聚集的透光率样本聚集到可见性图像素,类似于颜色值。
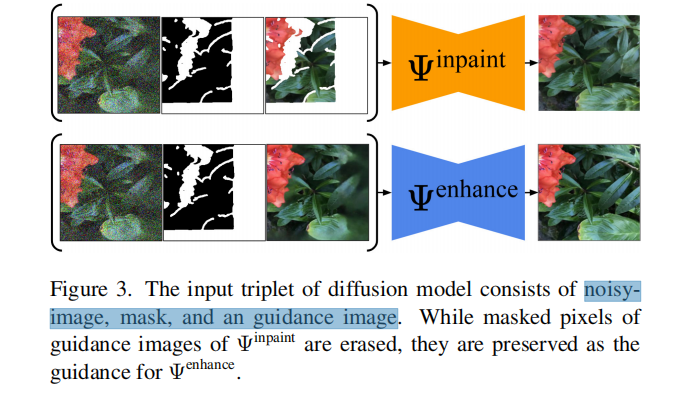
Depth completion module:深度补全模块,用来补全虚拟视图的深度图。其输入为inpaint的RGB图像、Visibility map和masked 深度图作为输入,并在mask区域内inpaint 深度图。该模型基于MiDaS-v3 [4]的预训练权重,并为输入mask和masked 深度图增加了两个输入通道。该模型在Places2数据集[71]上使用自监督的方法进行了微调。

图4:给定来自MVImgNet的单个输入图像(第一列),我们的模型以生成的方式执行三维重建,因此可以产生多个不同的后视图(列2到7)。与由确定性模型(第8列)生成的后视图相比,我们的模型的预测要清晰得多。
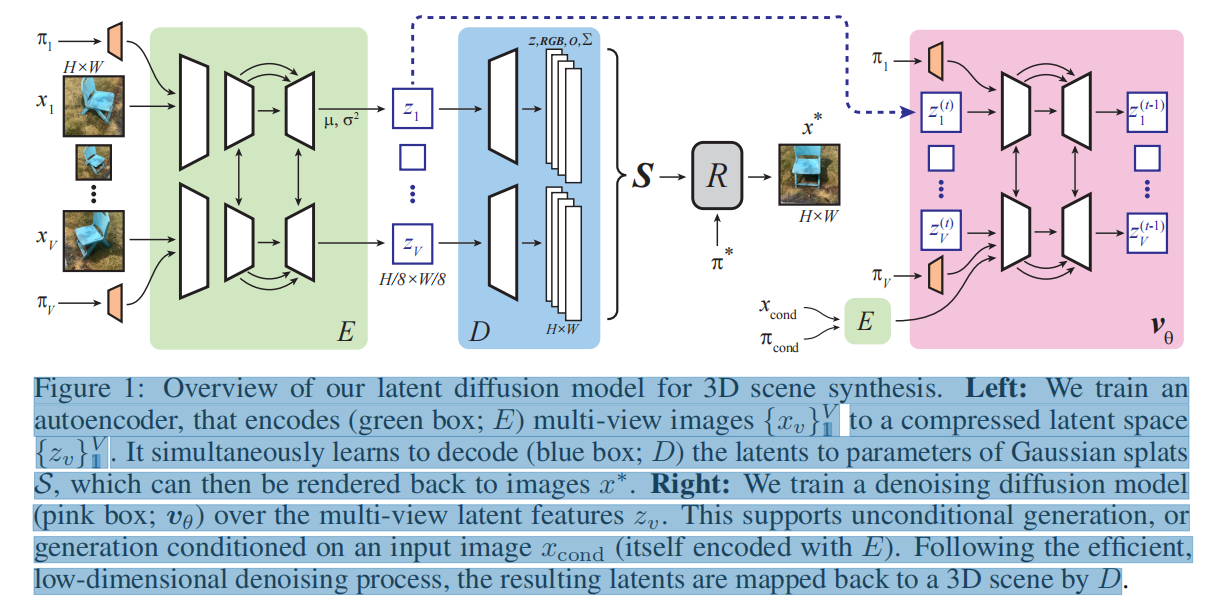
18.扩散模型LDM辅助3D Gaussian重建三维场景(生成任务)
标题:《Sampling 3D Gaussian Scenes in Seconds with Latent Diffusion Models》
来源:Glasgow大学;爱丁堡大学
连接:https://arxiv.org/abs/2406.13099
摘要:本文提出一个三维场景的潜在扩散模型,它仅使用2D图像数据训练。文章首先设计了一个 1.自动编码器,将多视图图像映射到三维GS ,同时构建这些splats的压缩潜在表示。然后,我们 2.在潜在空间上训练一个多视图扩散模型来学习一个有效的生成模型 。该管道不需要对象的mask 或深度,并且适用于具有任意摄像机位置的复杂场景。我们在两个复杂真实场景的大规模数据集上进行了仔细的实验-MVImgNet和RealEstate 10K。我们的方法能够在短短0.2秒内生成3D场景,或从头开始,从单个输入视图,或从稀疏输入视图。它产生多样化和高质量的结果,同时运行比非潜在扩散模型和早期的基于NeRF的生成模型快一个数量级。
Encoding multi-view images.
x
v
x_v
xv首先独立通过三个类似于[27,78]的降采样残差块,生成分辨率为
H
8
\frac {H}{8}
8H×
W
8
\frac {W}{8}
8W的特征图。这些特征由 多视图U-Net [80]处理,它使不同的视图能够有效地交换信息(是实现一致的三维重建所必需的)。这个U-Net是基本基于DDPM的。为了使它适应我们的多视图设置,我们从视频扩散模型 中获得灵感,特别是[Align your latents:
High-resolution video synthesis with latent diffusion models CVPR 2023] ,并在每个块后添加一个小的交叉视图ResNet,为每个像素独立地结合了来自所有视图的信息。我们还修改了所有的注意层,以共同attend 来自所有视角的cross 特征。除了这些部分,残差块处理的其余部分都是独立地处理视图。U-Net的最终卷积输出每个视图的大小为
H
8
\frac {H}{8}
8H×
W
8
\frac {W}{8}
8W的特征图的均值和对数方差(log-variances)。这将是压缩的潜在空间{
z
v
z_v
zv}
v
V
=
1
^V_v=1
vV=1,对其执行去噪(见第3.2节),所以我们限制它只有很少的通道。遵循VAEs [50,78],我们假设一个对角高斯后验分布(diagonal Gaussian posterior distribution),用E表示从
x
v
x_v
xv 到潜在样本
z
v
z_v
zv的整体编码器映射;如图1中的绿框所示。
Decoding to a 3D scene。上一步得到的
z
v
z_v
zv,通过三个上采样残差块传递特征,与E的初始层互为镜像关系,生成与原始图像具有相同大小的特征映射。与[97,13]类似,每个视图的特征通过卷积层被映射为splats(supported on the view frustum)的参数;对于每个像素,我们预测相应splats 的深度、不透明度、RGB颜色、旋转和尺度,共需要12个通道;通过预测的深度,沿相应的相机射线反投影,计算每个splats的三维位置。所有图像的V×H×W splats的联合,构成了我们的场景表示S。 这种表示(在[Splatter image]中称为飞溅图像)提供了一种结构化的方式来表示splats,允许使用标准卷积层对它们进行推理,而不是非结构化点云所需的排列不变层对它们进行推理 。我们用D表示从{
z
v
z_v
zv}
v
=
1
V
^V_{v=1}
v=1V到S的映射,如图1中的蓝框所示。然后可以使用任意的相机参数
π
∗
π^∗
π∗渲染到像素
x
∗
x^∗
x∗,即
x
∗
=
R
(
S
,
π
∗
)
x^∗=R(S,π^∗)
x∗=R(S,π∗)的渲染操作。在所有去噪视点的图像上都支持splats的一个关键好处是,我们可以在我们看到的任何地方表示3D内容。这与 SplatterImage [97]形成对比——当执行单图像重建时,它们只能参数化输入图像 view frustum的内部(或非常接近)的splats,而我们可以在任意远处产生连贯的内容。
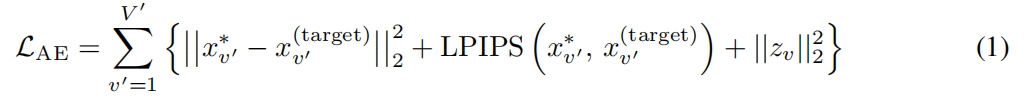
19.SmileSplat:无约束稀疏图像的可推广高斯溅射

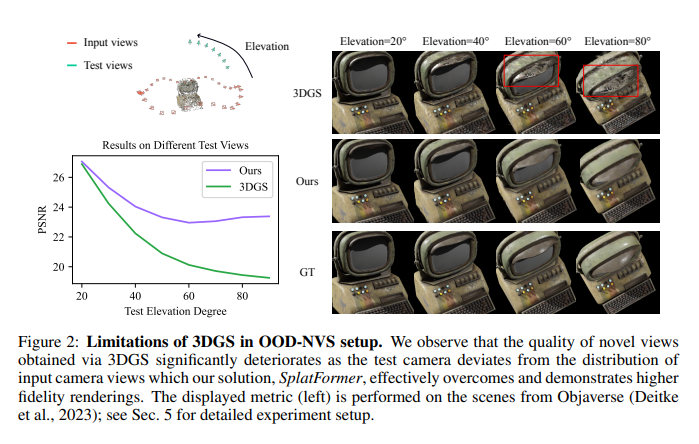
20.SplatFormer Point Transformer
https://sergeyprokudin.github.io/splatformer/
SplatFormer Point Transformer for Robust 3D Gaussian Splatting
数据驱动的用于优化远离训练视角的GS模型效果的方法,已开源

d
\sqrt{d}
d
1
8
\frac {1}{8}
81
x
ˉ
\bar{x}
xˉ
x
^
\hat{x}
x^
x
~
\tilde{x}
x~
ϵ
\epsilon
ϵ
ϕ
\phi
ϕ