大模型,多模态大模型面试问题记录24/10/27
问题一:视频生成例如Sora或者视频理解internvl2模型怎么提取时序上的特征。
- 稀疏采样与空间下采样:
将输入视频稀疏采样 8 帧,并进行 14x14 的空间下采样。
这使得模型能够从少量帧中提取信息,并降低计算复杂度。 - 3D正余弦可学习的位置编码,将每个时序 token 与一个类别 token 和 3D 位置编码结合。
3D 位置编码包含了时间信息,帮助模型理解视频中的时间顺序。 - 多头自注意力机制:
ViT 中的多头自注意力机制能够捕捉视频帧之间的长距离依赖关系。
通过注意力机制,模型能够关注重要的帧并忽略无关的帧,从而更好地理解视频内容。 - 位置池化:
在 ViT 的每个阶段后添加位置池化层。
位置池化层将每个阶段的特征映射到一个固定大小的向量,从而降低计算复杂度,并保持时间信息。 - 逐步增强的架构:
InternVideo2 的视频编码器包含多个阶段,每个阶段的参数量和模型规模都逐步增强。
这种设计使得模型能够学习越来越复杂的时序特征。 - 与其他模态的对比学习:
InternVideo2 将视频特征与其他模态(如文本、音频、语音)进行对比学习。
这使得模型能够更好地理解视频内容,并学习更丰富的时序特征。
问题二:Qformer介绍
参考BLIP2中Q-former详解
总结关键点是:
- Q-Former是一个轻量级的transformer,它使用一个可学习的query向量集,从冻结的视觉模型提取视觉特征。
- 采取两阶段预训练策略
- 阶段一:vision-language表示学习(representation learning),迫使Q-Former学习和文本最相关的视觉表示。
- 阶段二:vision-to-language生成式学习(generative learning),将Q-Former的输出连接到冻结的大语言模型,迫使Q-Former学习到的视觉表示能够为大语言模型所解释。
Q-former结构:
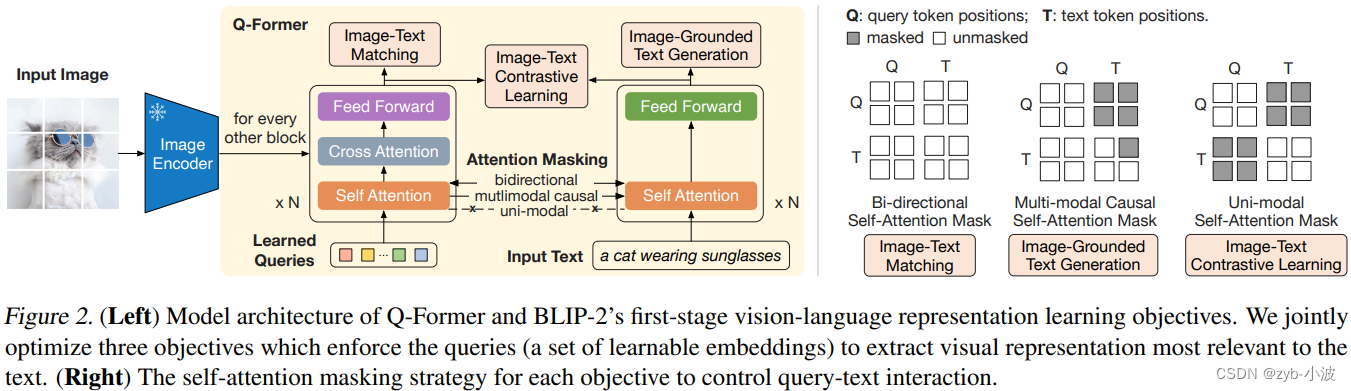
Q-Former由两个transfomer子模块组成,左边为**(learnable) query encoder**,右边为text encoder & decoder。记视觉模型的image encoder的输出为I。左边网络的(learnable) query为Q,右边网络的输入text为T。注意Q是一个向量集,非单个向量。它可以视为Q-Former的参数。
-
左边的transformer和视觉模型image encoder交互,提取视觉表征,右边的transformer同时作为text encoder和decoder。
-
左边的query encoder和右边的text encoder共享self-attention layer。
-
通过self attention layer,实现Q向量之间的交互。
-
通过cross attention layer,实现Q向量和I的交互。
-
Q和T之间的交互,也是通过共享的self attention layer实现的,不过根据训练目标的不同,通过不同的attention mask来实现不同的交互。
不同的交互任务如下:图文对比学习ITC,图文匹配ITM,基于图的文本生成ITG
-
ITC,使用单模态视觉和大语言模型各自的注意力掩码,Q向量和T之间没有交互。
-
ITM,使用双向注意力机制掩码(MLM),实现Q向量和T之间的任意交互。Q向量可以attention T,T也可以attention Q向量。
-
ITG,使用单向注意力机制掩码(CLM),实现Q向量和T之间的部分交互。Q向量不能attention T,T中的text token可以attention Q向量和前面的text tokens。
图文匹配任务与图文对比学习的主要区别是,引入了图文之间的cross attention,进行细粒度的图像和文本匹配用来预测,可以理解为单塔模型和双塔模型的区别
训练阶段一
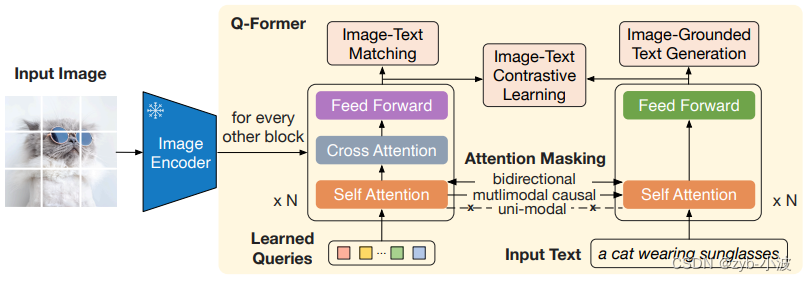
text对进行多目标训练(ITC+ITM+ITG)。
这三个目标都是将视觉表示和文本表示T进行对齐,学习到最匹配文本的视觉表示。
这个多目标训练是在BLIP论文中提出的。在BLIP论文中提到,之所以同时训练三个目标,是为了让学习到的视觉表示可以同时做理解和生成下游任务。
ITC和ITM主要是为了适应图片分类、图片检索、VQA等理解类任务。ITG主要是为了适应Captioning等生成类任务。
ITC是对比学习,通过最大化positive image-text pair,最小化negative image-text pair。而ITM是二分类模型,加入一个linear layer,直接给image-text pair打分。
由于训练ITC目标时,为了防止信息泄露,image和text不能attention彼此,捕捉到的image-text交互信息有限。训练ITM允许image和text互相attention,而且是双向的,来捕捉到更细粒度的image-text交互信息。同时训练ITC、ITM这两个目标,互补一下,以更好地进行image-text对齐。
ITG目标的作用是训练Q-Former,让它具有在给定图片的情况下,生成文本的能力。
右边transformer,在ITC和ITM目标训练中,作为encoder,在ITG目标训练中,作为decoder。
训练阶段二
分别展示了对于decoder-only和encoder-decoder架构的大语言模型,预训练阶段二的示意图。
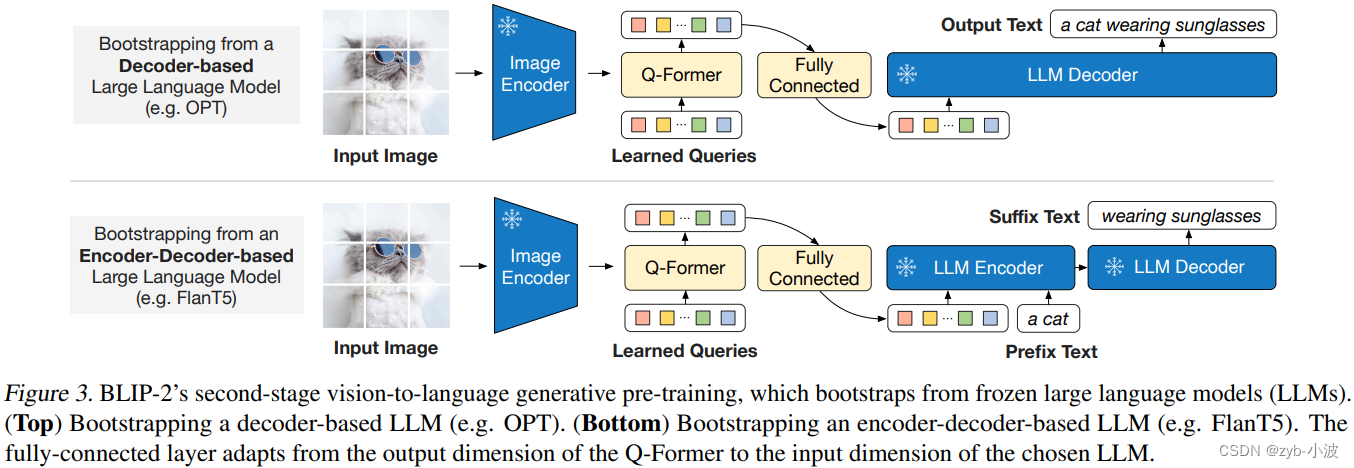
这个阶段是比较简单的,通过一个linear layer将Q-Former输出投射(project)成一个向量(和大语言模型的embedding一样维度),将它拼接到大语言模型的输入text的embedding前面,相当于一个soft prompt。
将Q-Former学习的文本和图像向量,加上一个全连接层(一个Linear,从768维到2560维),然后输入到大预言模型,预测文本输出。
Decoder only:将Q-former学到token直接输入,得到文本输出,论文中采用facebook的opt模型进行训练。
encoder-decoder:将Q-former学到token加上前缀词(如图中的a cat)一起输入,得到后续的文本输出,论文中采用FlanT5添加指令进行训练。
问题三:卷积维度计算公式,感受野
在卷积层和池化层中,输入和输出的维度变化受卷积核大小、步长、填充(padding)等参数的影响。以下是详细说明:
1. 卷积层
对于输入张量的维度 H i n × W i n × C i n H_{in} \times W_{in} \times C_{in} Hin×Win×Cin(高度、宽度、通道数),卷积层的输出维度可以通过以下公式计算:
输出高度和宽度
-
输出高度 H o u t H_{out} Hout:
H o u t = ⌊ H i n + 2 × padding h − kernel_size h stride h ⌋ + 1 H_{out} = \left\lfloor \frac{H_{in} + 2 \times \text{padding}_h - \text{kernel\_size}_h}{\text{stride}_h} \right\rfloor + 1 Hout=⌊stridehHin+2×paddingh−kernel_sizeh⌋+1 -
输出宽度 W o u t W_{out} Wout:
W o u t = ⌊ W i n + 2 × padding w − kernel_size w stride w ⌋ + 1 W_{out} = \left\lfloor \frac{W_{in} + 2 \times \text{padding}_w - \text{kernel\_size}_w}{\text{stride}_w} \right\rfloor + 1 Wout=⌊stridewWin+2×paddingw−kernel_sizew⌋+1
输出通道数
- 输出通道数通常由卷积层的滤波器数量决定,设为 C o u t C_{out} Cout。
总结
- 输出维度: H o u t × W o u t × C o u t H_{out} \times W_{out} \times C_{out} Hout×Wout×Cout
2. 池化层
对于池化层,输出维度的计算方式与卷积层类似,通常以最大池化或平均池化为主。
输出高度和宽度
-
输出高度 H o u t H_{out} Hout:
H o u t = ⌊ H i n − kernel_size h stride h ⌋ + 1 H_{out} = \left\lfloor \frac{H_{in} - \text{kernel\_size}_h}{\text{stride}_h} \right\rfloor + 1 Hout=⌊stridehHin−kernel_sizeh⌋+1 -
输出宽度 W o u t W_{out} Wout:
W o u t = ⌊ W i n − kernel_size w stride w ⌋ + 1 W_{out} = \left\lfloor \frac{W_{in} - \text{kernel\_size}_w}{\text{stride}_w} \right\rfloor + 1 Wout=⌊stridewWin−kernel_sizew⌋+1
输出通道数
- 池化层通常保持通道数不变,即 C o u t = C i n C_{out} = C_{in} Cout=Cin。
总结
- 输出维度: H o u t × W o u t × C i n H_{out} \times W_{out} \times C_{in} Hout×Wout×Cin
示例
假设输入为 32 × 32 × 3 32 \times 32 \times 3 32×32×3 的图像,使用 3 × 3 3 \times 3 3×3 的卷积核,步长为 1,padding 为 1:
- 输出维度为 32 × 32 × C o u t 32 \times 32 \times C_{out} 32×32×Cout(C_out 根据滤波器数量而定)。
如果使用 2 × 2 2 \times 2 2×2 的最大池化,步长为 2:
- 输出维度为 16 × 16 × 3 16 \times 16 \times 3 16×16×3。
通过这些公式,你可以灵活地调整卷积层和池化层的参数,以满足不同模型的需求。
感受野
综合考虑卷积层和池化层的所有参数(卷积核大小、步长、填充等),感受野的计算可以通过递推公式来进行。以下是完整的感受野计算公式:
感受野计算公式
-
卷积层:
对于第 l l l 层卷积层,假设其参数为:- 卷积核大小 k l k_l kl
- 步长 P l P_l Pl
- 填充(padding) padding l \text{padding}_l paddingl
则第 l l l 层的感受野 R l R_l Rl 由以下公式给出:
R l = R l − 1 + ( k l − 1 ) ⋅ P l R_l = R_{l-1} + (k_l - 1) \cdot P_l Rl=Rl−1+(kl−1)⋅Pl -
池化层:
对于第 m m m 层池化层,假设其参数为:- 池化核大小 k p k_p kp
- 步长 P p P_p Pp
则第 m m m 层的感受野 R m R_m Rm 由以下公式给出:
R m = R m − 1 + ( k p − 1 ) ⋅ P p R_m = R_{m-1} + (k_p - 1) \cdot P_p Rm=Rm−1+(kp−1)⋅Pp
综合计算
如果将卷积层和池化层结合起来,假设网络中有多个卷积层和池化层的交替,感受野的综合计算可以如下进行:
-
初始化:
- 输入层的感受野设为 R 0 = 1 R_0 = 1 R0=1。
-
递推计算:
- 对于每一层(无论是卷积层还是池化层),按照顺序进行递推计算:
- 如果是卷积层:
R l = R l − 1 + ( k l − 1 ) ⋅ P l R_l = R_{l-1} + (k_l - 1) \cdot P_l Rl=Rl−1+(kl−1)⋅Pl - 如果是池化层:
R m = R m − 1 + ( k p − 1 ) ⋅ P p R_m = R_{m-1} + (k_p - 1) \cdot P_p Rm=Rm−1+(kp−1)⋅Pp
- 如果是卷积层:
- 对于每一层(无论是卷积层还是池化层),按照顺序进行递推计算:
示例
假设你有以下层的组合:
- 第 1 层(卷积层): k 1 = 3 k_1 = 3 k1=3, P 1 = 1 P_1 = 1 P1=1,padding = 1 = 1 =1
- 第 2 层(池化层): k p = 2 k_p = 2 kp=2, P p = 2 P_p = 2 Pp=2
- 第 3 层(卷积层): k 2 = 3 k_2 = 3 k2=3, P 2 = 1 P_2 = 1 P2=1,padding = 1 = 1 =1
计算步骤
-
第一层(卷积层):
R 1 = R 0 + ( k 1 − 1 ) ⋅ P 1 = 1 + ( 3 − 1 ) ⋅ 1 = 3 R_1 = R_0 + (k_1 - 1) \cdot P_1 = 1 + (3 - 1) \cdot 1 = 3 R1=R0+(k1−1)⋅P1=1+(3−1)⋅1=3 -
第二层(池化层):
R 2 = R 1 + ( k p − 1 ) ⋅ P p = 3 + ( 2 − 1 ) ⋅ 2 = 4 R_2 = R_1 + (k_p - 1) \cdot P_p = 3 + (2 - 1) \cdot 2 = 4 R2=R1+(kp−1)⋅Pp=3+(2−1)⋅2=4 -
第三层(卷积层):
R 3 = R 2 + ( k 2 − 1 ) ⋅ P 2 = 4 + ( 3 − 1 ) ⋅ 1 = 6 R_3 = R_2 + (k_2 - 1) \cdot P_2 = 4 + (3 - 1) \cdot 1 = 6 R3=R2+(k2−1)⋅P2=4+(3−1)⋅1=6
总结
最终,经过这几层后,第三层神经元的感受野为 6。这意味着该层的每个输出值与输入图像中 6x6 的区域相关联。通过这种方式,你可以计算整个网络中每一层的感受野,以便更好地理解模型的特征提取能力。
问题四:ControlNet超详细解
参考Stable Diffusion — ControlNet 超详细讲解
-
使用Stable Diffusion并冻结其参数,同时copy一份SDEncoder的副本,这个副本的参数是可训练的。这样做的好处有两个:
- 制作这样的副本而不是直接训练原始权重的目的是为了避免在数据集很小时的过拟合,同时保持了从数十亿张图像中学习到的大模型质量。
- 由于原始的权值被锁定了,所以不需要对原始的编码器进行梯度计算来进行训练。这可以加快训练速度;因为不用计算原始模型上参数的梯度,所以节省了GPU内存。
-
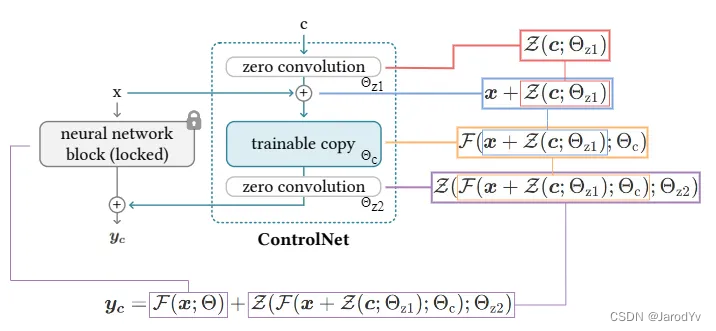
零卷积 :即初始权重和bias都是零的卷积。在副本中每层增加一个零卷积与原始网络的对应层相连。在第一步训练中,神经网络块的可训练副本和锁定副本的所有输入和输出都是一致的,就好像ControlNet不存在一样。换句话说,在任何优化之前,ControlNet都不会对深度神经特征造成任何影响,任何进一步的优化都会使模型性能提升,并且训练速度很快。
内部架构:
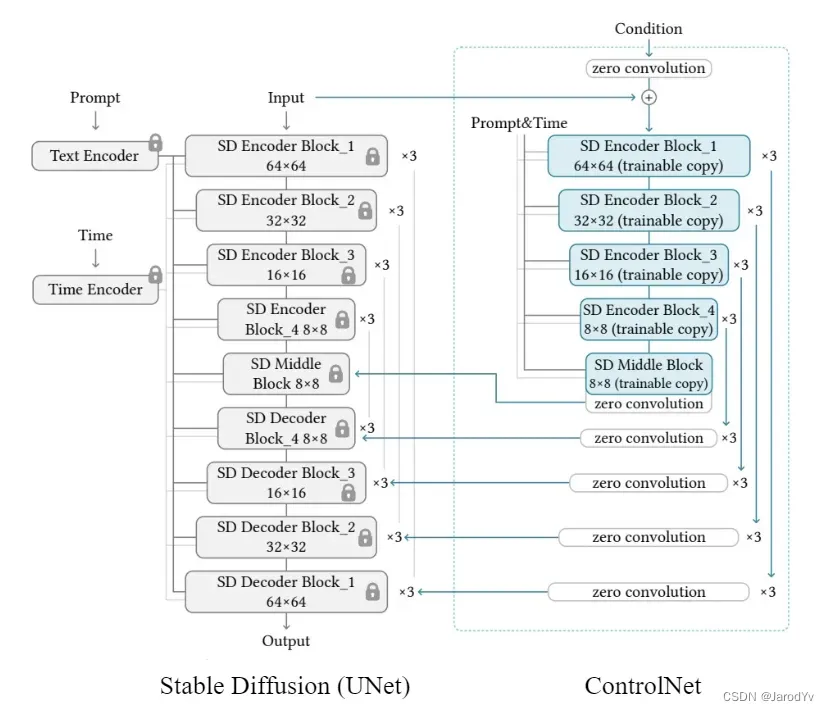
Stable Diffusion (UNet) 中的所有参数都被锁定并克隆到 ControlNet 端的可训练副本中。然后使用外部条件向量训练该副本。
创建原始权重的副本而不是直接训练原始权重是为了防止数据集较小时出现过拟合,并保持已经训练好的大模型的高质量,这些大模型在数十亿图像上训练得到,并可以直接部署到生产环境使用。
前馈

问题五:IP-adapter超详细解
参考https://blog.csdn.net/weixin_44966641/article/details/136692647
IP-Adapter:用于文本到图像扩散模型的文本兼容图像提示适配器
IP-Adapter的网络架构
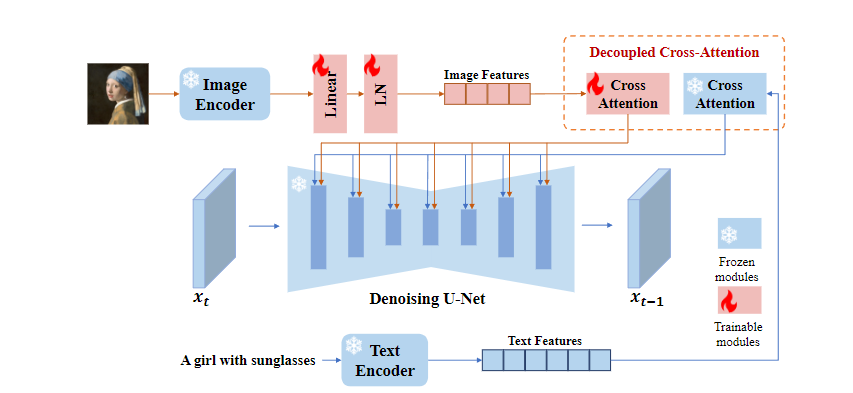
- 当前adapter很难达到微调图像提示模型或从头训练的模型性能,主要原因是图像特征无法有效的嵌入预训练模型中。大多数方法只是将拼接的特征输入到冻结的cross-attention中,阻止了扩散模型捕捉图像图像提示的细粒度特征。
- 为了解决这个问题,我们提出了一种解耦交叉注意力策略,即通过新添加的交叉注意力层嵌入图像特征。提议的IP-adapter包含两个部分:
- 图像编码器用于从图像提示中提取图像特征;
- 具有解耦的cross-attention的适配模块,用于将图像特征嵌入预训练的文本到图像扩散模型中。
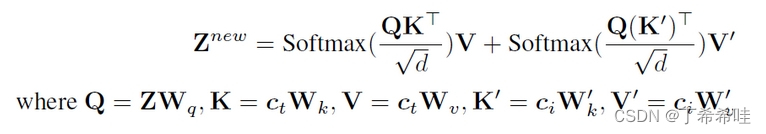



♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠
