AlexNet 是一种经典的卷积神经网络(CNN)架构,在 2012 年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)中表现优异,将 CNN 引入深度学习的新时代。AlexNet 的设计在多方面改进了卷积神经网络的架构,使其能够在大型数据集上有效训练。以下是 AlexNet 的详解:
1. AlexNet 架构概述
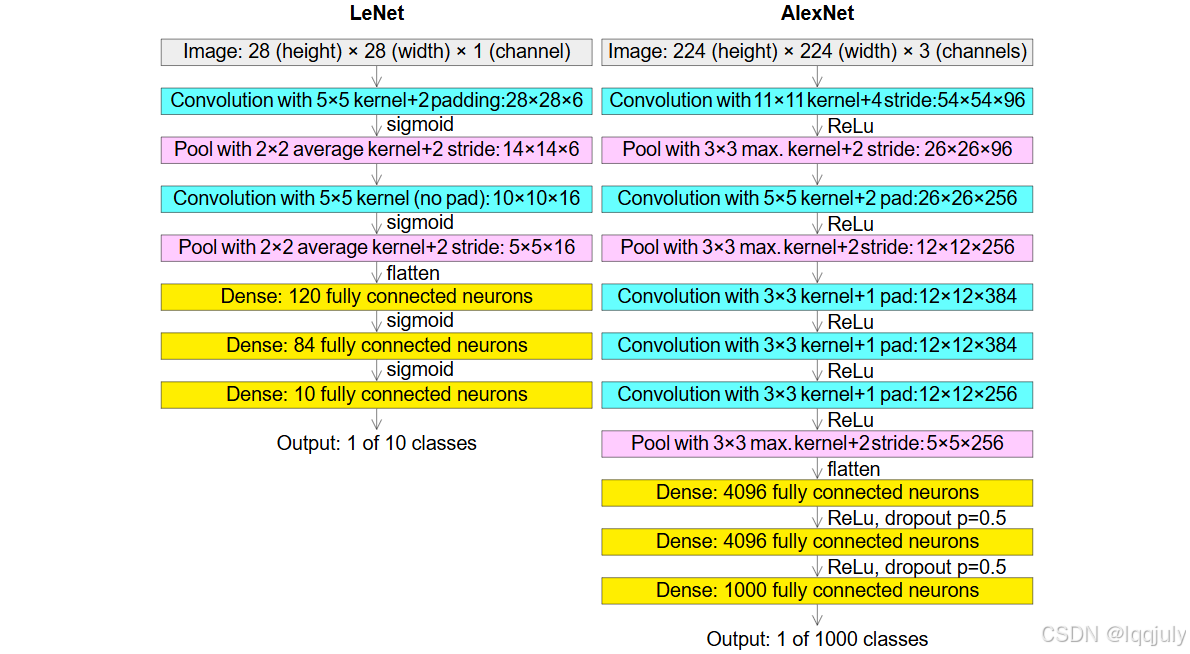
AlexNet 有 8 层权重层,包括 5 层卷积层和 3 层全连接层(FC 层),并引入了一些重要的创新,包括激活函数、Dropout 正则化和重叠池化。它通过增加网络的深度和宽度,结合 GPU 加速,极大提升了 CNN 的能力。
2. AlexNet 架构细节
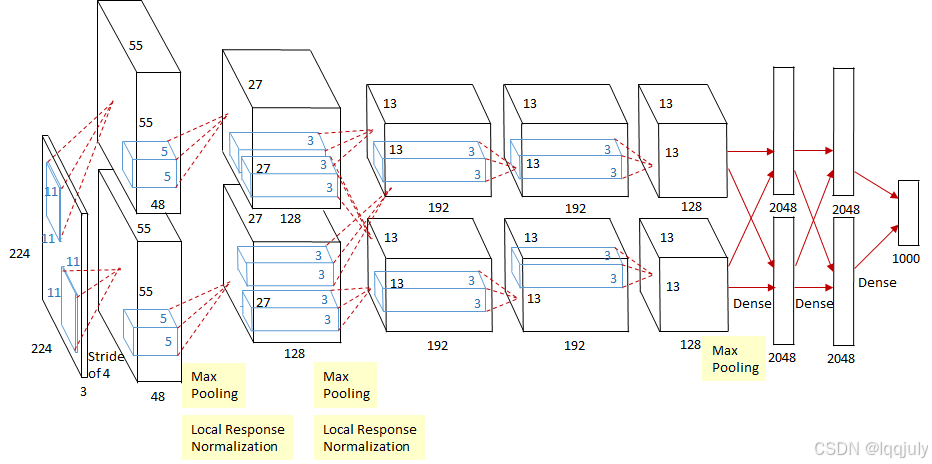
(1)输入层:
- 输入图像的尺寸为 227x227x3(RGB 3 通道图像)。
- AlexNet 采用的是 ImageNet 数据集,其图像分辨率较高,因此需要更大的卷积核和池化核。
(2)卷积层(Conv Layers):
- 第一层卷积层(Conv1):卷积核大小为 11x11,步长为 4,使用 96 个滤波器。输出的特征图尺寸为 55x55x96。经过 ReLU 激活函数处理。
- 第二层卷积层(Conv2):卷积核大小为 5x5,步长为 1,使用 256 个滤波器。由于输入图像较大,为减小计算量,每次滑动 1 像素,并采用了最大池化。输出的特征图尺寸为 27x27x256。
- 第三、四、五层卷积层(Conv3、Conv4、Conv5):分别采用 3x3 的卷积核,步长为 1,滤波器数分别为 384、384 和 256。
(3)激活函数(ReLU):
- AlexNet 是第一个在每一层卷积层之后使用 ReLU(Rectified Linear Unit)激活函数的网络。与 sigmoid 激活函数不同,ReLU 不会出现梯度消失问题,且能加快训练速度。
(4)池化层(Pooling Layers):
- 使用最大池化(Max Pooling),窗口大小为 3x3,步长为 2。
- AlexNet 引入了“重叠池化”,即池化窗口的步长小于窗口的大小(3x3 池化窗口和 2 步长),使得池化层能够更好地提取空间信息。
(5)全连接层(Fully Connected Layers):
- AlexNet 的最后 3 层是全连接层。
- FC6 层:输入是前一层展平后的特征图,输出为 4096 个节点。
- FC7 层:与 FC6 类似,输出也为 4096 个节点。
- FC8 层:为最终的输出层,节点数等于类别数(在 ImageNet 数据集中为 1000),通过 softmax 得到每个类别的概率。
(6)Dropout 正则化:
- 在全连接层中,AlexNet 引入了 Dropout 正则化,将随机的神经元设为 0,以减少过拟合。Dropout 率为 0.5,即每个神经元有 50% 的概率不参与计算。
(7)局部响应归一化(Local Response Normalization, LRN):
- LRN 是一种正则化技术,通过对某一层激活值进行归一化操作,增加了模型的泛化能力。虽然 LRN 不再是现代 CNN 的标准,但在 AlexNet 中有效防止了某些神经元的权值变得过大。
3. AlexNet 的创新点
AlexNet 的创新之处主要体现在以下几点:
-
ReLU 激活函数的应用:
通过使用 ReLU,AlexNet 成功避免了 sigmoid 和 tanh 激活函数可能导致的梯度消失问题,从而加速了训练过程。 -
重叠池化:
重叠池化减小了过拟合风险,使得网络能更好地进行特征提取和层次化表示。 -
Dropout 正则化:
Dropout 的引入在当时是一个非常重要的创新,它通过让神经元随机失活来防止过拟合。 -
多 GPU 训练:
AlexNet 在 GPU 上进行了分布式训练,将不同的卷积层分配到两个 GPU 上,从而加速了计算。 -
数据增强:
AlexNet 使用数据增强(如随机剪裁、镜像翻转和颜色扰动),进一步增加了训练数据的多样性,减少了过拟合风险。
模型特性
- 所有卷积层都使用ReLU作为非线性映射函数,使模型收敛速度更快
- 在多个GPU上进行模型的训练,不但可以提高模型的训练速度,还能提升数据的使用规模
- 使用LRN对局部的特征进行归一化,结果作为ReLU激活函数的输入能有效降低错误率
- 重叠最大池化(overlapping max pooling),即池化范围z与步长s存在关系z>s,避免平均池化(average pooling)的平均效应
- 使用随机丢弃技术(dropout)选择性地忽略训练中的单个神经元,避免模型的过拟合
4. AlexNet 的优势和局限性
- 优势:
- AlexNet 通过加深网络层数和增加神经元数量,提高了模型的表现力。
- 使用 GPU 进行加速计算,使得大规模数据集上的训练成为可能。
- Dropout、重叠池化和数据增强等技术有效地降低了过拟合风险。
- 局限性:
- AlexNet 参数数量较多,导致计算资源需求较大。
- 在深度增加的同时,过大的全连接层会导致大量参数和计算。
- LRN 归一化的效果有限,现代模型往往使用批归一化(Batch Normalization)来取代。
5. AlexNet 的影响
VGGNet、GoogLeNet 和 ResNet 等网络都在 AlexNet 的基础上进行了改进和扩展。
6.代码示例
PyTorch 中的 AlexNet 实现:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义 AlexNet 模型结构
class AlexNet(nn.Module):
def __init__(self, num_classes=1000): # 默认输出1000类,可根据任务调整
super(AlexNet, self).__init__()
# 特征提取部分,包括卷积和池化层
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2), # 第1个卷积层,输出96个特征图
nn.ReLU(inplace=True), # 激活函数,ReLU
nn.MaxPool2d(kernel_size=3, stride=2), # 第1个最大池化层
nn.Conv2d(96, 256, kernel_size=5, padding=2), # 第2个卷积层
nn.ReLU(inplace=True), # 激活函数
nn.MaxPool2d(kernel_size=3, stride=2), # 第2个最大池化层
nn.Conv2d(256, 384, kernel_size=3, padding=1), # 第3个卷积层
nn.ReLU(inplace=True), # 激活函数
nn.Conv2d(384, 384, kernel_size=3, padding=1), # 第4个卷积层
nn.ReLU(inplace=True), # 激活函数
nn.Conv2d(384, 256, kernel_size=3, padding=1), # 第5个卷积层
nn.ReLU(inplace=True), # 激活函数
nn.MaxPool2d(kernel_size=3, stride=2) # 第3个最大池化层
)
# 分类部分,包含全连接层和 Dropout 层
self.classifier = nn.Sequential(
nn.Dropout(0.5), # Dropout层,防止过拟合
nn.Linear(256 * 6 * 6, 4096), # 全连接层,输入尺寸为 256*6*6,输出4096
nn.ReLU(inplace=True), # 激活函数
nn.Dropout(0.5), # 第二个Dropout层
nn.Linear(4096, 4096), # 第二个全连接层
nn.ReLU(inplace=True), # 激活函数
nn.Linear(4096, num_classes) # 最后一个全连接层,输出类别数
)
# 定义前向传播过程
def forward(self, x):
x = self.features(x) # 经过特征提取层
x = x.view(x.size(0), 256 * 6 * 6) # 展平特征图用于输入全连接层
x = self.classifier(x) # 经过分类层
return x
# 数据预处理,定义图像转换操作
transform = transforms.Compose([
transforms.Resize(256), # 调整图像大小到256
transforms.CenterCrop(227), # 中心裁剪为227x227大小,符合AlexNet输入要求
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
# 加载 CIFAR10 数据集,训练集和测试集分别创建 DataLoader
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 设置批次大小和打乱数据
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 初始化模型、损失函数和优化器
model = AlexNet(num_classes=10) # CIFAR10 任务设置10个输出类别
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 检查是否有 GPU 加速
model.to(device) # 将模型移动到设备上
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,用于分类任务
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # 随机梯度下降优化器
# 训练模型
def train(model, device, train_loader, criterion, optimizer, epoch):
model.train() # 设置模型为训练模式
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device) # 将数据移动到设备上
optimizer.zero_grad() # 清空梯度
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新模型参数
if batch_idx % 100 == 0: # 每100个批次打印一次训练状态
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}]\tLoss: {loss.item():.6f}')
# 测试模型
def test(model, device, test_loader, criterion):
model.eval() # 设置模型为评估模式
test_loss = 0 # 初始化测试损失
correct = 0 # 初始化正确分类的数量
with torch.no_grad(): # 禁用梯度计算
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data) # 前向传播
test_loss += criterion(output, target).item() # 累积测试损失
pred = output.argmax(dim=1, keepdim=True) # 获取预测的最大概率类别
correct += pred.eq(target.view_as(pred)).sum().item() # 统计正确分类的数量
test_loss /= len(test_loader.dataset) # 计算平均损失
accuracy = 100. * correct / len(test_loader.dataset) # 计算准确率
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')
# 主循环:训练和测试
num_epochs = 10 # 定义训练轮数
for epoch in range(1, num_epochs + 1):
train(model, device, train_loader, criterion, optimizer, epoch) # 调用训练函数
test(model, device, test_loader, criterion) # 调用测试函数