首先我们从YGC触发时机开始:如果在创建对象时申请不到内存,那么就会进行一次YGC。
那么我们就从创建对象分配内存空间开始看起:
// Allocation
// IRT_ENTRY是运行解释器的宏,这里就相当于定义了new关键字的方法,使用new关键字的时候就会调用到这个方法
IRT_ENTRY(void, InterpreterRuntime::_new(JavaThread* thread, ConstantPool* pool, int index))
// 从运行时常量池中获取KlassOop
Klass* k_oop = pool->klass_at(index, CHECK);
//然后将其包装成klass包装类,就是instanceKlassHandle句柄
instanceKlassHandle klass (THREAD, k_oop);
// 做了一些验证和初始化操作确保我们没有实例化一个抽象的klass
// Make sure we are not instantiating an abstract klass
klass->check_valid_for_instantiation(true, CHECK);
// 确保klass被初始化
// Make sure klass is initialized
klass->initialize(CHECK);
// At this point the class may not be fully initialized
// because of recursive initialization. If it is fully
// initialized & has_finalized is not set, we rewrite
// it into its fast version (Note: no locking is needed
// here since this is an atomic byte write and can be
// done more than once).
//
// Note: In case of classes with has_finalized we don't
// rewrite since that saves us an extra check in
// the fast version which then would call the
// slow version anyway (and do a call back into
// Java).
// If we have a breakpoint, then we don't rewrite
// because the _breakpoint bytecode would be lost.
// 调用申请内存分配进行实例化的方法,这里返回instanceOop是java class实例的指针
oop obj = klass->allocate_instance(CHECK);
// 将结果返回
thread->set_vm_result(obj);
IRT_END
其中通过klass->check_valid_for_instantiation(true, CHECK);确保了我们没有在实例化一个抽象的k或者是已经加载过的klass:
// 确保我们没有在实例化一个抽象的k或者是已经加载过的klass
void InstanceKlass::check_valid_for_instantiation(bool throwError, TRAPS) {
// 判断是否是接口或者抽象类,如果是就给出相应的异常错误信息
if (is_interface() || is_abstract()) {
ResourceMark rm(THREAD);
THROW_MSG(throwError ? vmSymbols::java_lang_InstantiationError()
: vmSymbols::java_lang_InstantiationException(), external_name());
}
// SystemDictionary 是用来帮助保存 ClassLoader 加载过的类信息的,
// 只是一个拥有很多静态方法的工具类而已
// 如果当前是已经加载过的就给出相应的异常信息
if (this == SystemDictionary::Class_klass()) {
ResourceMark rm(THREAD);
THROW_MSG(throwError ? vmSymbols::java_lang_IllegalAccessError()
: vmSymbols::java_lang_IllegalAccessException(), external_name());
}
}
我们继续从oop obj = klass->allocate_instance(CHECK);进入,查看是如何进行内存分配实例化的:
// InstanceKlass 是Klass子类,是类的元数据
// 通过此方法实例化Klass并给instanceKlass分配一个instanceOop
instanceOop InstanceKlass::allocate_instance(TRAPS) {
// 判断是否定义了finalizer方法
bool has_finalizer_flag = has_finalizer(); // Query before possible GC
// 获得需要分配空间也就是实例的大小
int size = size_helper(); // Query before forming handle.
// 封装成KlassHandle句柄,简单理解 : Klass的封装类
KlassHandle h_k(THREAD, this);
instanceOop i;
// 进行内存分配,成功就初始化对象
i = (instanceOop)CollectedHeap::obj_allocate(h_k, size, CHECK_NULL);
// 如果定义了finalizer方法但是还没有注册的话,就进行注册
if (has_finalizer_flag && !RegisterFinalizersAtInit) {
i = register_finalizer(i, CHECK_NULL);
}
return i;
}
这个方法返回的instanceOop是instanceOopDesc指针的别名,instanceOopDesc是oopDesc的子类,表示java class的实例,InstanceKlass是Klass子类,是类的元数据
instanceOopDesc和InstanceKlass
这个地方涉及到jvm的oop-klass模型:
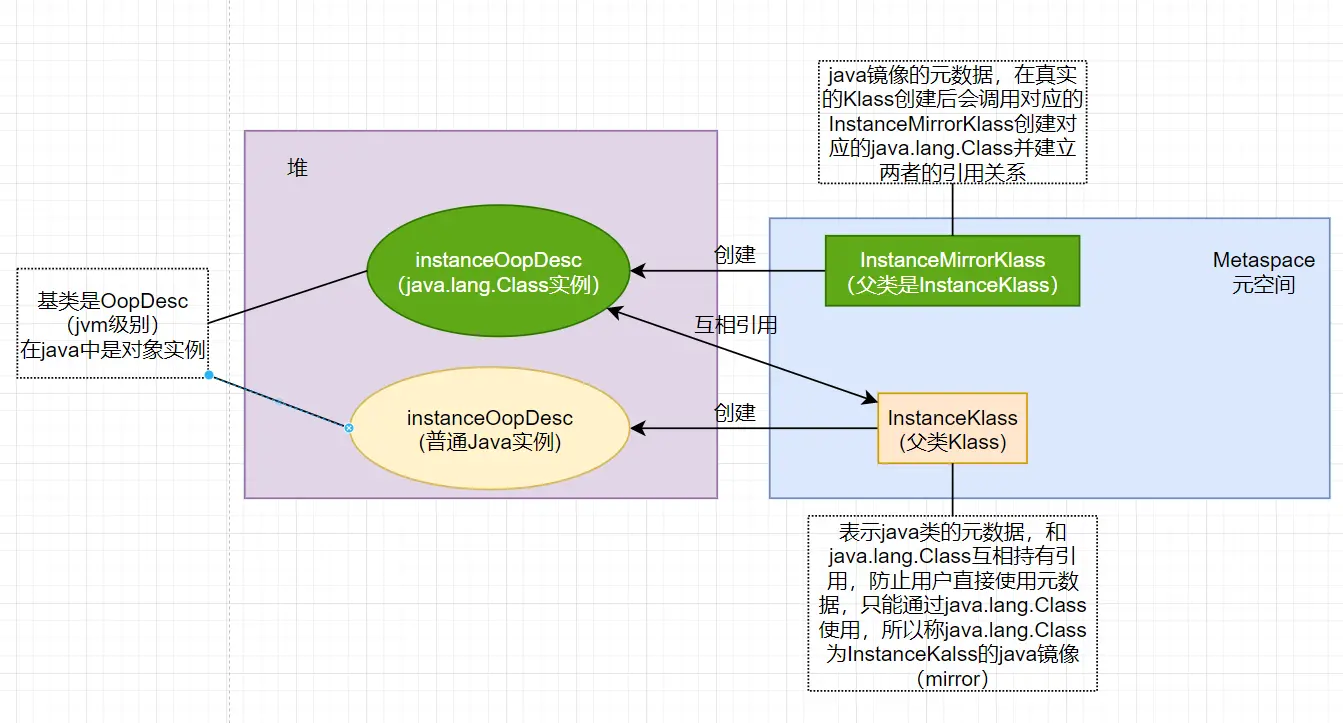
结合例子来看:
public class Test{
public static void main(String[] args) {
Person person = new Person();
}
}
- 编译并运行
.class文件,随后被加载到JVM的元空间 - JVM找到
Test的主函数入口(main),为main函数创建栈帧,开始执行main函数 - main函数的第一条语句是
Person person = new Person(),就是让JVM创建一个Person对象。但是这个时候元空间中没有Person类的信息,所以JVM开始加载Person类:在元空间中创建instanceKlass对象,把Person类信息放到元空间中;同时,使用元空间中创建的instanceKlass类对应的子类instanceMirrorKlass在堆上会自动构造镜像的Class实例提供反射访问(它和instanceKlass持有着双向引用)。 - 加载完
Person类之后,JVM 会为一个新的Person实例分配内存, 然后调用构造函数初始化Person实例,即在堆上创建一个instanceOopDesc实例,并返回该实例的指针OOP到栈空间对应线程。
继续从(instanceOop)CollectedHeap::obj_allocate(h_k, size, CHECK_NULL);往下看:
// 进行内存分配
oop CollectedHeap::obj_allocate(KlassHandle klass, int size, TRAPS) {
debug_only(check_for_valid_allocation_state());
// gc 的时候不可以进行分配
assert(!Universe::heap()->is_gc_active(), "Allocation during gc not allowed");
assert(size >= 0, "int won't convert to size_t");
// 申请内存并初始化对象
HeapWord* obj = common_mem_allocate_init(klass, size, CHECK_NULL);
// 对堆上的oop对象进行初始化
post_allocation_setup_obj(klass, obj, size);
NOT_PRODUCT(Universe::heap()->check_for_bad_heap_word_value(obj, size));
return (oop)obj;
}
// 申请内存并初始化对象
HeapWord* CollectedHeap::common_mem_allocate_init(KlassHandle klass, size_t size, TRAPS) {
// 先申请内存
HeapWord* obj = common_mem_allocate_noinit(klass, size, CHECK_NULL);
// 完成对对象内存空间的对齐和填充
init_obj(obj, size);
return obj;
}
最后通过common_mem_allocate_noinit(klass, size, CHECK_NULL);进入到内存申请方法中,此方法不包括初始化对象:
// 申请内存不包含对象初始化
HeapWord* CollectedHeap::common_mem_allocate_noinit(KlassHandle klass, size_t size, TRAPS) {
// Clear unhandled oops for memory allocation. Memory allocation might
// not take out a lock if from tlab, so clear here.
CHECK_UNHANDLED_OOPS_ONLY(THREAD->clear_unhandled_oops();)
if (HAS_PENDING_EXCEPTION) {
NOT_PRODUCT(guarantee(false, "Should not allocate with exception pending"));
return NULL; // caller does a CHECK_0 too
}
// 堆中的内存地址都需要通过 HeapWord* 指针进行表示
// 例如申请内存起始地址的函数一般返回的都是HeapWord*, 大小也是 HeapWordSize 的整数倍,
// 因为 Java 堆是按照一定内存大小对齐的
HeapWord* result = NULL;
// 是否使用TLAB
if (UseTLAB) {
// 使用TLAB分配空间,优先进行快速分配
result = allocate_from_tlab(klass, THREAD, size);
if (result != NULL) {
assert(!HAS_PENDING_EXCEPTION,
"Unexpected exception, will result in uninitialized storage");
return result;
}
}
bool gc_overhead_limit_was_exceeded = false;
// 堆中申请内存,这个方法返回的是当前jvm使用的堆类,所以这里返回的是g1CollectedHeap.cpp
// 进入慢分配
result = Universe::heap()->mem_allocate(size,
&gc_overhead_limit_was_exceeded);
// ...
}
判断是否开启了TLAB分配空间,如果开启了则优先采用TLAB进行空间分配,以下开始介绍G1中的TLAB。
TLAB
在使用TLAB分配对象之前,会优先进行栈上分配,我们这里考虑的是无法栈上分配需要共享的对象,这里对栈上分配就不作描述了。
G1提供了两种对象的分配策略:基于线程本地分配缓冲区(TLAB,Thread Local Allocation Buffer)的快速分配和慢速分配。
无论是快速分配还是慢速分配,都应该在STW之外调用,都应该避免使用全局锁。因此优先进行无锁分配,再进行加锁,从而尽可能地满足并行化分配。
目前大多数应用内存分配是多线程的,都从主内存中分配,但是CAS 更新重试过于频繁导致效率低下。目前的应用,一般根据不同业务区分了不同的线程池,在这种情况下,一般每个线程分配内存的特性是比较稳定的。这里的比较稳定指的是,每次分配对象的大小,每轮 GC 分配区间内的分配对象的个数以及总大小。所以,我们可以考虑每个线程分配内存后,就将这块内存保留起来,用于下次分配,这样就不用每次从主内存中分配了。
快速分配
TLAB的目的就是为了进行内存的快速分配,因此TLAB试图通过为每一个线程分配一个缓冲区来避免和减少使用锁。分配线程对象的时候,**从JVM堆中分配一个固定大小的内存区域并将其作为线程的私有缓冲区,这个缓冲区就被称为TLAB。**有了TLAB之后,只有为每个线程分配TLAB缓冲区的时候才需要锁定整个JVM堆。不同的线程不共享TLAB,我们尝试分配一个对象的时候优先从当前线程的TLAB中分配对象,不需要锁,所以达到了快速分配的目的。
TLAB区是Eden区域中的一块内存,不同线程的TLAB都位于Eden区,所有的TLAB内存堆所有的线程都是可见的。每个线程都有一个TLAB的数据结构,但是仅仅只是保存待内存区间的起始地址(start)和结束地址(end)。在分配的时候也只在这个区间内做分配,从而达到无锁分配。
G1中使用CAS来分配TLAB空间,一个TLAB空间分区中可能存在多个TLAB块,但是一个TLAB是不能跨分区的。
快速TLAB对象分配存在两步:
- 从线程的TLAB分配空间,如果成功就返回
- 如果不能分配,就先尝试分配一个新的TLAB,再尝试分配对象
从TLAB已分配的缓冲区直接分配对象,采用的方式为指针碰撞:TLAB会保存top指针(用于标记当前对象分配的位置),如果剩余空间大小大于待分配对象的空间大小,直接分配并更新top指针(top=top+objSize),如果分配失败则进入allocate_from_tlab_slow(TLAB慢速分配)中。
此时就需要对TLAB的空间大小进行判断斟酌:
- 如果TLAB设置的过小,可能需要不断重新分配新的TLAB
- 如果TLAB设置的过大,可能会在GC的时候花费更长的时间,还可能会导致内存碎片问题
JVM提供了TLABSize来控制TLAB的大小,默认值是0,如果为默认值那么JVM会推断这个值多大更合适,采用的参数为TLABWasteTargetPercent,用于设置TLAB可以占用的Eden空间的百分比,默认是1%。如果是由JVM自行推断的,那么推断方式为:
T L A B S i z e = E d e n ∗ T L A B W a s t e T a r g e t P e r c e n t ∗ 2 线 程 个 数 TLABSize = \frac{Eden * TLABWasteTargetPercent*2 }{线程个数} TLABSize=线程个数Eden∗TLABWasteTargetPercent∗2
乘2是因为假设内存使用服从均匀发分布,这里采用的启发式推断仅仅是一个近似值,实际上线程在使用内存分配对象时并不会完全服从正太分布,不同的线程类型对内存的使用也不同,一些线程几乎不会分配新的对象。
如果之前分配失败则说明空间不足,或者是TLAB满了。应对这种情况无需额外操作,只需要保留这部分空间,然后重新在Eden区中分配一块空间给TLAB,然后再在TLAB中分配具体对象。
JVM内部维护**refill_waste**值,当请求对象大于**refill_waste**时,会选择在堆中分配;小于该值,则会废弃当前TLAB,新建TLAB来分配对象。
这个阈值可以使用TLABRefillWasteFraction(它表示TLAB中允许这种浪费的比例,默认为64,表示使用约1/64的TLAB空间来作为refill_waste)来调整。
JVM还提供了一个参数TLABWasteIncrement(默认值为4个字)用于动态增加这个refill_waste的值,默认情况下,TLAB大小和refill_waste都会在运行时不断调整,使系统的运行状态达到最优。动态调整也不能无限变更,所以JVM提供提供了MinTLABSize(默认为2k)用于控制最小值。也可以通过-XX:-ResizeTLAB禁用自动调整TLAB大小。
从源码上继续从result = allocate_from_tlab(klass, THREAD, size);进入,查看TLAB快速分配流程:
// TLAB 快速分配
HeapWord* CollectedHeap::allocate_from_tlab(KlassHandle klass, Thread* thread, size_t size) {
assert(UseTLAB, "should use UseTLAB");
// 分配size大小的空间
// TLAB中使用指针碰撞法分配对象:TLAB保存top指针用于标记当前对象分配的位置,
// 如果剩余空间大小大于待分配对象的空间大小,直接分配并更新top指针(top=top+objSize)
HeapWord* obj = thread->tlab().allocate(size);
if (obj != NULL) {
return obj;
}
// Otherwise...
// 没有分配到则进入分配一个新的TLAB流程
return allocate_from_tlab_slow(klass, thread, size);
}
其中从tlab().allocate(size);进入查看tlab分配空间:
// 分配空间
inline HeapWord* ThreadLocalAllocBuffer::allocate(size_t size) {
// 校验指针是否在start 和 end 的范围内
invariants();
// 获得_top指针位置
HeapWord* obj = top();
// 如果当前剩余空间大于等于需要分配的空间大小
if (pointer_delta(end(), obj) >= size) {
// successful thread-local allocation
#ifdef ASSERT
// Skip mangling the space corresponding to the object header to
// ensure that the returned space is not considered parsable by
// any concurrent GC thread.
size_t hdr_size = oopDesc::header_size();
Copy::fill_to_words(obj + hdr_size, size - hdr_size, badHeapWordVal);
#endif // ASSERT
// This addition is safe because we know that top is
// at least size below end, so the add can't wrap.
// 设置top指针位置为 原top + 需要分配的大小
set_top(obj + size);
// 对设置后的top指针进行校验查看指针是否在start 和 end 的范围内
invariants();
// 返回_top
return obj;
}
// 如果剩余的空间不够则直接返回NULL
return NULL;
}
其中的invariants();的作用是校验指针是否在start 和 end 的范围内:
void invariants() const { assert(top() >= start() && top() <= end(), "invalid tlab"); }
如果剩余空间不够需要分配的空间,那么就进入collectedHeap.inline.hpp中的allocate_from_tlab_slow(klass, thread, size);方法进入到TLAB慢速分配流程分配一个新的TLAB。
TLAB慢速分配
如果TLAB快速分配没有分配成功就会尝试进行TLAB慢速分配,具体有以下两种情况:
- 如果TLAB的剩余空间过小,那么就对老TLAB进行填充一个
dummy对象,然后去申请一个新的TLAB - 如果TLAB的剩余空间并不小,那么就更新
refill_waste的值,然后不使用TLAB进行分配,直接返回
当我们重新分配一个TLAB时,为什么要对老的TLAB做清理操作?
这里的清理操作指的是:向老的TLAB中的尚未分配的空间中分配一个dummy对象(哑元对象),这个对象通常是int[],为了供栈解析的时候使用。
栈解析:
G1在进行某些需要线性扫描堆中对象的操作的时候,如果这个区域是对象,那么就可以直接跳过这个对象大小的位置。但是如果是空白的空间,那么就无法跳过,只能一个字节一个字节的进行扫描,所以速度会很慢。所以为了提高栈解析的速度,我们向老的TLAB中的空白空间中分配一个对象,使得解析的时候可以跳过这些空间。
我们进入allocate_from_tlab_slow(klass, thread, size);方法查看其操作流程:
// TLAB慢速分配流程 分配一个新的TLAB
HeapWord* CollectedHeap::allocate_from_tlab_slow(KlassHandle klass, Thread* thread, size_t size) {
// Retain tlab and allocate object in shared space if
// the amount free in the tlab is too large to discard.
// 判断TLAB的剩余空间是否可以丢弃,如果剩余空间大于设定的阈值 (refill_waste_limit)就保留
// free() 计算 top 到 end 之间的大小,也就是剩余大小
// refill_waste_limit() 返回 _refill_waste_limit 值
// 运行到这里的情况为:要分配的对象的大小大于TLAB的剩余空间,该TLAB不够分配。
// 并且该TLAB的大小仍然大于_refill_waste_limit的值,无法新分配一个TLAB
if (thread->tlab().free() > thread->tlab().refill_waste_limit()) {
// 无法丢弃,就通过TLAWasteIncrement更新refill_waste的阈值
thread->tlab().record_slow_allocation(size);
// 返回NULL,使得后续对象直接分配在堆中非TLAB的Eden区域中
return NULL;
}
// Discard tlab and allocate a new one.
// To minimize fragmentation, the last TLAB may be smaller than the rest.
// 为了避免内存碎片化,新分配的TLAB会比之前分配的更小,compute_size就是计算待分配的TLAB的大小,如果返回0说明Eden区内存不足
size_t new_tlab_size = thread->tlab().compute_size(size);
// 分配前先清理老的TLAB,为了让堆保parsable可解析
thread->tlab().clear_before_allocation();
// 计算待分配的TLAB的大小为0的话说明Eden区堆内存不足了,返回NULL(可能会触发Eden区的垃圾回收)
if (new_tlab_size == 0) {
return NULL;
}
// Allocate a new TLAB...
// 分配一个新的TLAB,G1实现在g1CollectedHeap.cpp中,有可能分配失败
HeapWord* obj = Universe::heap()->allocate_new_tlab(new_tlab_size);
if (obj == NULL) {
return NULL;
}
// 如果启用了 ZeroTLAB 这个 JVM 参数,则将对象所有字段置零值
if (ZeroTLAB) {
// ..and clear it.
Copy::zero_to_words(obj, new_tlab_size);
} else {
// ...and zap just allocated object.
#ifdef ASSERT
// Skip mangling the space corresponding to the object header to
// ensure that the returned space is not considered parsable by
// any concurrent GC thread.
size_t hdr_size = oopDesc::header_size();
Copy::fill_to_words(obj + hdr_size, new_tlab_size - hdr_size, badHeapWordVal);
#endif // ASSERT
}
// 新分配的TLAB的属性初始化
thread->tlab().fill(obj, obj + size, new_tlab_size);
return obj;
}
可以看到一开始判断了TLAB中的剩余空间是否大于了refill_waste的阈值,如果大于则更新refill_waste的值,然后不使用TLAB进行分配,直接返回;如果剩余空间小于等于refill_waste的阈值,就对老TLAB进行填充一个dummy对象,然后去申请一个新的TLAB。
其中通过tlab().record_slow_allocation(size);该方法查看如何更新refill_waste的阈值:
// 通过TLAWasteIncrement更新refill_waste的阈值
void ThreadLocalAllocBuffer::record_slow_allocation(size_t obj_size) {
// Raise size required to bypass TLAB next time. Why? Else there's
// a risk that a thread that repeatedly allocates objects of one
// size will get stuck on this slow path.
// 修改方式为:(TLABWasteIncrement + _refill_waste_limit)
// 避免某个线程一直请求大于当前free空间的内存,但是因为free空间一直小于refill_waste_limit而一直走慢速分配的情形
set_refill_waste_limit(refill_waste_limit() + refill_waste_limit_increment());
// 增加走慢速分配的次数
_slow_allocations++;
if (PrintTLAB && Verbose) {
Thread* thrd = myThread();
gclog_or_tty->print("TLAB: %s thread: " INTPTR_FORMAT " [id: %2d]"
" obj: " SIZE_FORMAT
" free: " SIZE_FORMAT
" waste: " SIZE_FORMAT "\n",
"slow", p2i(thrd), thrd->osthread()->thread_id(),
obj_size, free(), refill_waste_limit());
}
}
** **回到allocate_from_tlab_slow()方法继续往下阅读,可以看到通过tlab().compute_size(size)重新计算了新的TLAB大小,其计算方式为:
// 计算TLAB的大小
inline size_t ThreadLocalAllocBuffer::compute_size(size_t obj_size) {
// 将传入大小按照8字节向上取整,返回字宽大小
const size_t aligned_obj_size = align_object_size(obj_size);
// Compute the size for the new TLAB.
// The "last" tlab may be smaller to reduce fragmentation.
// unsafe_max_tlab_alloc is just a hint.
// 给新的TLAB计算大小,新的TLAB有可能为了减少内存碎片而变得更小
const size_t available_size = Universe::heap()->unsafe_max_tlab_alloc(myThread()) /
HeapWordSize;
// 新的TLAB大小为 两者最小值
size_t new_tlab_size = MIN2(available_size, desired_size() + aligned_obj_size);
// Make sure there's enough room for object and filler int[].
// alignment_reserve() 方法返回TLAB中必须保留的内存大小,是 dummy object 填充的对象头大小
// obj_plus_filler_size 表示待分配内存的最低值
const size_t obj_plus_filler_size = aligned_obj_size + alignment_reserve();
if (new_tlab_size < obj_plus_filler_size) {
// 空间不足,分配失败
// If there isn't enough room for the allocation, return failure.
if (PrintTLAB && Verbose) {
gclog_or_tty->print_cr("ThreadLocalAllocBuffer::compute_size(" SIZE_FORMAT ")"
" returns failure",
obj_size);
}
return 0;
}
// 分配成功,返回计算的大小
if (PrintTLAB && Verbose) {
gclog_or_tty->print_cr("ThreadLocalAllocBuffer::compute_size(" SIZE_FORMAT ")"
" returns " SIZE_FORMAT,
obj_size, new_tlab_size);
}
return new_tlab_size;
}
首先通过align_object_size(obj_size);方法获得了需要分配对象的字宽,例如传入大小是14字节,取整后就是16字节,所以返回2。具体计算方式为:
**(((size) + ((alignment) - 1)) & ~((alignment) - 1))**
然后再通过unsafe_max_tlab_alloc()方法计算出可用空间大小,计算过程为:
size_t G1CollectedHeap::unsafe_max_tlab_alloc(Thread* ignored) const {
// Return the remaining space in the cur alloc region, but not less than
// the min TLAB size.
// Also, this value can be at most the humongous object threshold,
// since we can't allow tlabs to grow big enough to accommodate
// humongous objects.
// 当前用户线程/java线程尝试从剩余给TLAB的空间中分配了一个分区,但是不一定有足够的空间
HeapRegion* hr = _allocator->mutator_alloc_region(AllocationContext::current())->get();
// 获取当前TLAB可以设置的最大值,也就是Region大小的一半
size_t max_tlab = max_tlab_size() * wordSize;
// 如果没有分配到,那么就返回最大大小
if (hr == NULL) {
return max_tlab;
} else {
// 如果分配到了,并且大小在TLAB的大小范围之内就返回该大小
return MIN2(MAX2(hr->free(), (size_t) MinTLABSize), max_tlab);
}
}
于是我们获得了从堆剩余给 TLAB 可分配的空间中分配的一个分区,最终新TLAB应该分配的大小为堆剩余给 TLAB 可分配的空间中分配的一个分区大小和desired_size() + aligned_obj_size(TLAB期望大小 + 这次需要分配对象的大小)的最小值。
通过将这次需要分配的对象的大小加上TLAB中必须保留的内存大小得到了obj_plus_filler_size的值,这意味着待分配内存的最小值。如果最终新TLAB的大小比待分配空间的最小值还要小就说明空间不足,分配失败返回0,在外层返回NULL,不使用TLAB进行分配。反之,则返回新TLAB应该分配的大小。
TLAB 期望大小
size_t desired_size() const { return _desired_size; }
期望大小其实是在TLAB初始化的时候进行设置的:
// TLAB 初始化逻辑
void ThreadLocalAllocBuffer::initialize() {
// 设置初始指针,由于还没有从 Eden 分配内存,所以这里都设置为 NULL
initialize(NULL, // start
NULL, // top
NULL); // end
// 设置期望大小值
set_desired_size(initial_desired_size());
// Following check is needed because at startup the main
// thread is initialized before the heap is. The initialization for
// this thread is redone in startup_initialization below.
if (Universe::heap() != NULL) {
// 所有 TLAB 总大小,不同的 GC 实现有不同的 TLAB 容量, 一般是 Eden 区大小
size_t capacity = Universe::heap()->tlab_capacity(myThread()) / HeapWordSize;
// Keep alloc_frac as float and not double to avoid the double to float conversion
// 计算这个线程的 TLAB 期望占用所有 TLAB 总体大小比例
// TLAB 期望占用大小也就是这个 TLAB 大小 乘以 期望 refill 的次数
float alloc_frac = desired_size() * target_refills() / (float) capacity;
// 记录下来,用于计算 EMA
// sample() 就是根据传入值去计算出一个新的权重值
_allocation_fraction.sample(alloc_frac);
}
#if INCLUDE_ALL_GCS
if (UsePerTenantTLAB) {
_my_thread = Thread::current();
}
#endif
// 计算初始 refill 最大浪费空间,并设置
// 初始大小就是 TLAB 的大小(_desired_size) / TLABRefillWasteFraction
set_refill_waste_limit(initial_refill_waste_limit());
// 重置统计
initialize_statistics();
}
进入initial_desired_size()方法查看其设置_desired_size的具体逻辑:
// 初始化设置TLAB期望大小
size_t ThreadLocalAllocBuffer::initial_desired_size() {
size_t init_sz = 0;
// 如果通过 -XX:TLABSize 设置了 TLAB 大小,则用这个值作为初始期望大小
if (TLABSize > 0) {
// 表示堆内存占用大小都需要用占用几个 HeapWord 表示,所以用TLABSize / HeapWordSize
init_sz = TLABSize / HeapWordSize;
} else if (global_stats() != NULL) {
// Initial size is a function of the average number of allocating threads.
// 获取当前epoch内线程数量期望,这个如之前所述通过 EMA 预测
unsigned nof_threads = global_stats()->allocating_threads_avg();
// 不同的 GC 实现有不同的 TLAB 容量,Universe::heap()->tlab_capacity(thread()) 一般是 Eden 区大小
// target_refills已经在 JVM 初始化所有 TLAB 全局配置的时候初始化好了
// 期望大小 等于 Eden区大小/(当前 epcoh 内会分配对象期望线程个数 * 每个 epoch 内每个线程 refill 次数配置)
init_sz = (Universe::heap()->tlab_capacity(myThread()) / HeapWordSize) /
(nof_threads * target_refills());
// 考虑对象对齐,得出最后的大小
init_sz = align_object_size(init_sz);
}
// 保持大小在 min_size() 还有 max_size() 之间
init_sz = MIN2(MAX2(init_sz, min_size()), max_size());
// 返回大小
return init_sz;
}
可以看出:
- 如果设置了使用TLAB,并且设置了
TLABSize,那么这个期望大小就是你所设置的TLAB的大小 - 如果你没有设置的话,这个期望大小则为将 (Eden空间大小 / 期望所使用的TLAB的个数 )的值按照8字节向上取整后的值
最后得出的值,确保是在TLAB的最小大小和最大大小范围之内的。
EMA
EMA(Exponential Moving Average 指数平均数)算法,也就是每次输入采样值,根据历史采样值得出最新的期望值。最小权重越大,变化得越快,受历史数据影响越小。根据应用设置合适的最小权重,可以让期望更加理想。在这里不详细介绍,感兴趣的同学可以去查看gcUtil.hpp中的AdaptiveWeightedAverage自行了解。
我们回到allocate_from_tlab_slow中继续流程:清理老的TLAB,从tlab().clear_before_allocation();进入查看具体清理操作:
void ThreadLocalAllocBuffer::clear_before_allocation() {
// 增加慢分配下refill浪费的内存空间值
_slow_refill_waste += (unsigned)remaining();
// 使得TLAB可以支持parsable,同时丢弃这个TLAB
make_parsable(true); // also retire the TLAB
}
** **具体操作在make_parsable();中:
void ThreadLocalAllocBuffer::make_parsable(bool retire) {
if (end() != NULL) {
// 校验 top 是处于start 和 end 位置之间的
invariants();
// (这里的是否丢弃值为 true)
if (retire) {
// 增加当前线程已分配的内存数,used_bytes方法返回TLAB中使用掉的内存(top - start)
myThread()->incr_allocated_bytes(used_bytes());
}
// 将TLAB中top位置后面的空间全部填充
CollectedHeap::fill_with_object(top(), hard_end(), retire);
// 如果设置了ZeroTLAB,那么就将属性全部置空,该TLAB就不能用来分配对象
if (retire || ZeroTLAB) { // "Reset" the TLAB
set_start(NULL);
set_top(NULL);
set_pf_top(NULL);
set_end(NULL);
}
}
assert(!(retire || ZeroTLAB) ||
(start() == NULL && end() == NULL && top() == NULL),
"TLAB must be reset");
}
其中incr_allocated_bytes(used_bytes())就是将当前线程已经分配的大小_allocated_bytes加上已经使用的内存,具体的填充老TLAB的操作在fill_with_object()中,最终会调用到collectedHeap.cpp中的fill_with_object_impl()方法:
void
CollectedHeap::fill_with_object_impl(HeapWord* start, size_t words, bool zap)
{
// 校验待填充的内存是否大于数组的最大大小
assert(words <= filler_array_max_size(), "too big for a single object");
// 如果要填充的空间大小大于等于数组填充的最小值
if (words >= filler_array_min_size()) {
// 那么就使用int数组进行填充
fill_with_array(start, words, zap);
} else if (words > 0) {
assert(words == min_fill_size(), "unaligned size");
// 如果比数组填充的最小值还要小,那么就使用Object对象填充
post_allocation_setup_common(SystemDictionary::Object_klass(), start);
}
}
我们可以在fill_with_array()中看到这里使用的数组是int数组:
// 使用int数组进行填充
void
CollectedHeap::fill_with_array(HeapWord* start, size_t words, bool zap)
{
assert(words >= filler_array_min_size(), "too small for an array");
assert(words <= filler_array_max_size(), "too big for a single object");
// 计算待填充大小
const size_t payload_size = words - filler_array_hdr_size();
// 通过待填充大小计算出int数组应该要多长
const size_t len = payload_size * HeapWordSize / sizeof(jint);
assert((int)len >= 0, err_msg("size too large " SIZE_FORMAT " becomes %d", words, (int)len));
// Set the length first for concurrent GC.
((arrayOop)start)->set_length((int)len);
// int数组填充
post_allocation_setup_common(Universe::intArrayKlassObj(), start);
DEBUG_ONLY(zap_filler_array(start, words, zap);)
}
最终两者都调用了post_allocation_setup_common();这个方法来进行填充,这边就不继续深入了,感兴趣的同学可以自行深入。** **
继续回到原流程allocate_from_tlab_slow中去,如果计算出来的新TLAB大小不为0,就说明空间仍够使用,那么就会进入到allocate_new_tlab(new_tlab_size);方法中分配一个新的TLAB。
// 分配一个新的TLAB
HeapWord* G1CollectedHeap::allocate_new_tlab(size_t word_size) {
assert_heap_not_locked_and_not_at_safepoint();
assert(!isHumongous(word_size), "we do not allow humongous TLABs");
uint dummy_gc_count_before;
uint dummy_gclocker_retry_count = 0;
// 主要执行逻辑
return attempt_allocation(word_size, &dummy_gc_count_before, &dummy_gclocker_retry_count);
}
其主要执行逻辑处于attempt_allocation方法中,步骤也可以分为两个部分:快速无锁分配和慢速分配。
inline HeapWord* G1CollectedHeap::attempt_allocation(size_t word_size,
uint* gc_count_before_ret,
uint* gclocker_retry_count_ret) {
assert_heap_not_locked_and_not_at_safepoint();
// 根据大小判断是否是大对象
assert(!isHumongous(word_size), "attempt_allocation() should not "
"be called for humongous allocation requests");
// 首先尝试分配TLAB空间的快速无锁分配
AllocationContext_t context = AllocationContext::current();
HeapWord* result = _allocator->mutator_alloc_region(context)->attempt_allocation(word_size,
false /* bot_updates */);
if (result == NULL) {
// 分配TLAB快速分配未成功,则正式进入TLAB慢速分配
result = attempt_allocation_slow(word_size,
context,
gc_count_before_ret,
gclocker_retry_count_ret);
}
assert_heap_not_locked();
if (result != NULL) {
dirty_young_block(result, word_size);
}
return result;
}
**快速无锁分配:**在当前可以分配的堆分区中使用CAS来获取一块内存,如果成功就可以作为TLAB的空间。因为CAS有可能失败,如果失败则进行TLAB慢速分配。
快速分配执行逻辑为:
inline HeapWord* G1OffsetTableContigSpace::par_allocate_impl(size_t size,
HeapWord* const end_value) {
do {
HeapWord* obj = top();
if (pointer_delta(end_value, obj) >= size) {
HeapWord* new_top = obj + size;
HeapWord* result = (HeapWord*)Atomic::cmpxchg_ptr(new_top, top_addr(), obj);
if (result == obj) {
assert(is_aligned(obj) && is_aligned(new_top), "checking alignment");
return obj;
}
} else {
return NULL;
}
} while (true);
}
**TLAB慢速分配:**需要尝试对堆进行加锁,扩展新生代区域或者垃圾回收等处理之后再进行分配。
// TLAB 慢速分配
HeapWord* G1CollectedHeap::attempt_allocation_slow(size_t word_size,
AllocationContext_t context,
uint* gc_count_before_ret,
uint* gclocker_retry_count_ret) {
// Make sure you read the note in attempt_allocation_humongous().
assert_heap_not_locked_and_not_at_safepoint();
// 根据大小校验是否是大对象,本方法不适用于大对象的分配
assert(!isHumongous(word_size), "attempt_allocation_slow() should not "
"be called for humongous allocation requests");
// We should only get here after the first-level allocation attempt
// (attempt_allocation()) failed to allocate.
// We will loop until a) we manage to successfully perform the
// allocation or b) we successfully schedule a collection which
// fails to perform the allocation. b) is the only case when we'll
// return NULL.
HeapWord* result = NULL;
for (int try_count = 1; /* we'll return */; try_count += 1) {
bool should_try_gc;
uint gc_count_before;
{
// 加锁分配
MutexLockerEx x(Heap_lock);
// 还是先去申请内存这个方法申请内存失败会将_mutator_alloc_region中的活跃区域进行retire并填充
// retire即将现在活跃的eden区region填充后加入到增量cset(即将要被回收的集合)中
// 之后再去申请一块新的region代替当前活跃区域
// 如果申请新的region失败才会继续下面操作进行GC
result = _allocator->mutator_alloc_region(context)->attempt_allocation_locked(word_size,
false /* bot_updates */);
if (result != NULL) {
return result;
}
// If we reach here, attempt_allocation_locked() above failed to
// allocate a new region. So the mutator alloc region should be NULL.
assert(_allocator->mutator_alloc_region(context)->get() == NULL, "only way to get here");
// 当 _needs_gc 和 (jni活跃实例数) _jni_lock_count > 0 同时满足时为true
// 程序中如果使用了jni开发,就可能会为true
if (GC_locker::is_active_and_needs_gc()) {
// 判断是否可以对新生代分区进行扩展(young_list_length < max_young_list_length)
if (g1_policy()->can_expand_young_list()) {
// No need for an ergo verbose message here,
// can_expand_young_list() does this when it returns true.
// 再申请一次
result = _allocator->mutator_alloc_region(context)->attempt_allocation_force(word_size,
false /* bot_updates */);
if (result != NULL) {
return result;
}
}
should_try_gc = false;
} else {
// The GCLocker may not be active but the GCLocker initiated
// GC may not yet have been performed (GCLocker::needs_gc()
// returns true). In this case we do not try this GC and
// wait until the GCLocker initiated GC is performed, and
// then retry the allocation.
// 判断GC_locker是不是需要gc,如果为true则说明有线程进入了临界区GC被丢弃,会在执行结束后再次触发gc并将本值置为false
if (GC_locker::needs_gc()) {
// 在这里我们会等待再次触发gc后,进行重新分配,所以并不需要我们这里尝试GC,因此之里应该置为false
should_try_gc = false;
} else {
// Read the GC count while still holding the Heap_lock.
// 在保持Heap_lock的时候拿到此时发生gc的次数
gc_count_before = total_collections();
// 此时说明没有GC被丢弃过,这里我们可以尝试进行GC,因此将should_try_gc置true
should_try_gc = true;
}
}
}
// 前流程分配失败,判断是否需要我们尝试GC
if (should_try_gc) {
// GCLocker 只有需要GC的时候才会进入这里,意味着GCLocker没有进入临界区,可以进行垃圾回收
// 简单来说,java代码可以和本地代码交互,在访问JNI代码时,JNI可能会进入临界区,所以此时会阻止GC垃圾回收操作
bool succeeded;
// 执行GC,再分配一个TLAB空间返回
result = do_collection_pause(word_size, gc_count_before, &succeeded,
GCCause::_g1_inc_collection_pause);
if (result != NULL) {
assert(succeeded, "only way to get back a non-NULL result");
return result;
}
if (succeeded) {
// If we get here we successfully scheduled a collection which
// failed to allocate. No point in trying to allocate
// further. We'll just return NULL.
// 如果我们到达这里,我们成功地安排了一个分配失败的集合。试图进一步分配没有意义。我们只返回NULL。
MutexLockerEx x(Heap_lock);
// total_collections:发生gc的次数
*gc_count_before_ret = total_collections();
return NULL;
}
} else {
// 不需要尝试GC
// 判断是否达到分配阈值
if (*gclocker_retry_count_ret > GCLockerRetryAllocationCount) {
// 如果大于则直接返回NULL
MutexLockerEx x(Heap_lock);
*gc_count_before_ret = total_collections();
return NULL;
}
// The GCLocker is either active or the GCLocker initiated
// GC has not yet been performed. Stall until it is and
// then retry the allocation.
// GCLocker处于活动状态,或者尚未执行GCLocker启动的GC。
// 运行到这里会循环wait,直到GCLocker中的_needs_gc被重新置为false,然后重试分配。
GC_locker::stall_until_clear();
// 每执行一次就将分配次数加1
(*gclocker_retry_count_ret) += 1;
}
// We can reach here if we were unsuccessful in scheduling a
// collection (because another thread beat us to it) or if we were
// stalled due to the GC locker. In either can we should retry the
// allocation attempt in case another thread successfully
// performed a collection and reclaimed enough space. We do the
// first attempt (without holding the Heap_lock) here and the
// follow-on attempt will be at the start of the next loop
// iteration (after taking the Heap_lock).
// 有可能其他线程正在分配或者GCLocker正被竞争使用,再尝试一次TLAB无锁快速分配
// 再次执行一次流程,每执行一次尝试分配次数都会增加直到到达阈值返回NULL
result = _allocator->mutator_alloc_region(context)->attempt_allocation(word_size,
false /* bot_updates */);
if (result != NULL) {
return result;
}
// Give a warning if we seem to be looping forever.
if ((QueuedAllocationWarningCount > 0) &&
(try_count % QueuedAllocationWarningCount == 0)) {
warning("G1CollectedHeap::attempt_allocation_slow() "
"retries %d times", try_count);
}
}
ShouldNotReachHere();
return NULL;
}
具体流程如下:
- 首先尝试对堆分区进行加锁分配,成功则返回,在
attempt_allocation_locked完成。 - 不成功,则判定是否可以对新生代分区进行扩展,如果可以扩展则扩展后再分配TLAB,成功则返回,在
attempt_allocation_force完成。 - 不成功,判定是否可以进行垃圾回收,如果可以进行垃圾回收后再分配,成功则返回,在
do_collection_pause完成。 - 不成功,如果尝试分配次数达到阈值(默认值是2次)则返回失败。
- 如果还可以继续尝试,再次判定是否进行快速分配,如果成功则返回。
- 不成功则通过for循环重新再尝试一次流程,直到成功或者达到阈值失败。
其中使用到了GC_locker::needs_gc()这一方法,会返回_needs_gc的值。具体的含义为:
使用本地方法JNI函数访问JVM中的字符串或数组数据(代码在临界区执行),为了防止gc移动字符串或者数组数据导致指针失效,需要利用GC_locker加锁,保证临界区代码的正确执行。如果在此时需要发生GC,那么此次GC就会被丢弃,并将其中的_needs_gc置为true,在临界区代码执行完毕后,再次触发GC操作,之后将_needs_gc重新复位为false。
所以TLAB慢速分配要么成功分配,要么尝试次数达到阈值后结束并返回NULL。
继续回到common_mem_allocate_noinit方法中,如果TLAB分配全部失败,就会进入到mem_allocate方法中,在其中会继续尝试分配。如果在这里分配仍然失败,那么就会触发YGC流程:
HeapWord*
G1CollectedHeap::mem_allocate(size_t word_size,
bool* gc_overhead_limit_was_exceeded) {
assert_heap_not_locked_and_not_at_safepoint();
// Loop until the allocation is satisfied, or unsatisfied after GC.
for (uint try_count = 1, gclocker_retry_count = 0; /* we'll return */; try_count += 1) {
uint gc_count_before;
HeapWord* result = NULL;
// 根据是否是大对象再次尝试分配
if (!isHumongous(word_size)) {
result = attempt_allocation(word_size, &gc_count_before, &gclocker_retry_count);
} else {
result = attempt_allocation_humongous(word_size, &gc_count_before, &gclocker_retry_count);
}
// 成功则返回
if (result != NULL) {
return result;
}
// 创建垃圾回收操作,gc操作任务类
// Create the garbage collection operation...
VM_G1CollectForAllocation op(gc_count_before, word_size);
op.set_allocation_context(AllocationContext::current());
// ...and get the VM thread to execute it.
// 使用VMThread去执行gc操作
VMThread::execute(&op);
// ...
// Give a warning if we seem to be looping forever.
if ((QueuedAllocationWarningCount > 0) &&
(try_count % QueuedAllocationWarningCount == 0)) {
warning("G1CollectedHeap::mem_allocate retries %d times", try_count);
}
}
ShouldNotReachHere();
return NULL;
}
这一部分和之前的do_collection_pause方法尝试GC操作类似:
HeapWord* G1CollectedHeap::do_collection_pause(size_t word_size,
uint gc_count_before,
bool* succeeded,
GCCause::Cause gc_cause) {
assert_heap_not_locked_and_not_at_safepoint();
// 记录gc停顿
g1_policy()->record_stop_world_start();
// gc操作任务类,第三个参数表示本次gc是不是老年代并发gc
VM_G1IncCollectionPause op(gc_count_before,
word_size,
false, /* should_initiate_conc_mark */
g1_policy()->max_pause_time_ms(),
gc_cause);
op.set_allocation_context(AllocationContext::current());
// 真正的停顿方法,使用VMThread执行操作任务
VMThread::execute(&op);
HeapWord* result = op.result();
bool ret_succeeded = op.prologue_succeeded() && op.pause_succeeded();
assert(result == NULL || ret_succeeded,
"the result should be NULL if the VM did not succeed");
*succeeded = ret_succeeded;
assert_heap_not_locked();
return result;
}
真正执行的方法都为VMThread::execute(&op);,其逻辑为:
// VMThread执行操作
void VMThread::execute(VM_Operation* op) {
Thread* t = Thread::current();
// 判断当前线程是否是vm线程,这里t->is_VM_thread()返回true
if (!t->is_VM_thread()) {
// 不是虚拟机线程情况下的处理逻辑不看
// ...
} else {
// 如果是虚拟机线程
// invoked by VM thread; usually nested VM operation
assert(t->is_VM_thread(), "must be a VM thread");
// 获取当前的虚拟机任务操作
VM_Operation* prev_vm_operation = vm_operation();
if (prev_vm_operation != NULL) {
// Check the VM operation allows nested VM operation. This normally not the case, e.g., the compiler
// does not allow nested scavenges or compiles.
// 检查该VM操作是否允许嵌套VM操作
if (!prev_vm_operation->allow_nested_vm_operations()) {
fatal(err_msg("Nested VM operation %s requested by operation %s",
op->name(), vm_operation()->name()));
}
// 如果允许嵌套VM操作,就设置该vm操作的优先级
op->set_calling_thread(prev_vm_operation->calling_thread(), prev_vm_operation->priority());
}
EventMark em("Executing %s VM operation: %s", prev_vm_operation ? "nested" : "", op->name());
// Release all internal handles after operation is evaluated
HandleMark hm(t);
_cur_vm_operation = op;
// 判断任务是否需要在安全点执行且当前是否在安全点
if (op->evaluate_at_safepoint() && !SafepointSynchronize::is_at_safepoint()) {
// 如果不是安全点,则等待所有线程进入安全点,然后把线程暂时挂起
SafepointSynchronize::begin();
// 开始任务, op是刚刚传入的VM_G1IncCollectionPause操作任务类
// evaluate()方法最后会调用gc操作任务类的doit()方法
op->evaluate();
// 安全点结束
SafepointSynchronize::end();
} else {
// 是安全点则直接执行
op->evaluate();
}
// Free memory if needed
if (op->is_cheap_allocated()) delete op;
// 执行完当前操作,重新复位原操作任务
_cur_vm_operation = prev_vm_operation;
}
}
SafepointSynchronize::begin();方法中包含了准备进入安全点直到所有的线程全部进入安全点并挂起的过程,因此在此时YGC的全局停顿开始了。所以有的时候因为发生全局停顿,导致程序出现不能提供服务的时候不能只盲目的区查fullGC日志,实际上通过源码我们可以看到G1的YGC过程也会产生全局停顿。
继续进入evaluate();方法查看任务执行逻辑:
// 开始任务
void VM_Operation::evaluate() {
ResourceMark rm;
if (TraceVMOperation) {
tty->print("[");
NOT_PRODUCT(print();)
}
// 先开始执行准备操作
doit();
if (TraceVMOperation) {
tty->print_cr("]");
}
}
其中进入doit()方法中继续查看从准备工作开始的逻辑:
// G1 YGC 准备工作
void VM_G1IncCollectionPause::doit() {
G1CollectedHeap* g1h = G1CollectedHeap::heap();
assert(!_should_initiate_conc_mark || g1h->should_do_concurrent_full_gc(_gc_cause),
"only a GC locker, a System.gc(), stats update, whitebox, or a hum allocation induced GC should start a cycle");
if (_word_size > 0) {
AllocationContextMark acm(this->allocation_context());
// An allocation has been requested. So, try to do that first.
// 继续尝试分配
_result = g1h->attempt_allocation_at_safepoint(_word_size, allocation_context(),
false /* expect_null_cur_alloc_region */);
if (_result != NULL) {
// If we can successfully allocate before we actually do the
// pause then we will consider this pause successful.
_pause_succeeded = true;
return;
}
}
GCCauseSetter x(g1h, _gc_cause);
G1ContextCauseSetter set_ctxt(g1h, this->allocation_context());
// youngGC这里是之前创建VM_G1IncCollectionPause的第三个参数:false
// 表示此次youngGC不属于老年代并发gc的周期,这里直接跳过
if (_should_initiate_conc_mark) {
// ...
}
// 执行的gc方法
_pause_succeeded =
g1h->do_collection_pause_at_safepoint(_target_pause_time_ms);
// gc 成功
if (_pause_succeeded && _word_size > 0) {
AllocationContextMark acm(this->allocation_context());
// An allocation had been requested.
// 再去申请内存
_result = g1h->attempt_allocation_at_safepoint(_word_size, allocation_context(),
true /* expect_null_cur_alloc_region */);
} else {
assert(_result == NULL, "invariant");
if (!_pause_succeeded) {
// Another possible reason reason for the pause to not be successful
// is that, again, the GC locker is active (and has become active
// since the prologue was executed). In this case we should retry
// the pause after waiting for the GC locker to become inactive.
_should_retry_gc = true;
}
}
}
进入do_collection_pause_at_safepoint方法:
// 我们忽略掉一些记日志和统计数据的方法,看关键的几个方法
bool
G1CollectedHeap::do_collection_pause_at_safepoint(double target_pause_time_ms) {
assert_at_safepoint(true /* should_be_vm_thread */);
guarantee(!is_gc_active(), "collection is not reentrant");
// 判断是否有线程再临界区,如果有则舍弃本次gc,并把need_gc参数设置为true
// 这里是我们刚刚提到的gc_locker
if (GC_locker::check_active_before_gc()) {
return false;
}
// 打印一些heap日志和统计数据
_gc_timer_stw->register_gc_start();
_gc_tracer_stw->report_gc_start(gc_cause(), _gc_timer_stw->gc_start());
SvcGCMarker sgcm(SvcGCMarker::MINOR);
ResourceMark rm;
print_heap_before_gc();
trace_heap_before_gc(_gc_tracer_stw);
verify_region_sets_optional();
verify_dirty_young_regions();
// 这个方法将会判断此次youngGC是不是一次初次标记
// (即老年代并发垃圾回收时,会伴随一次youngGC,此时会返回true)
// 纯youngGC阶段这里会返回false
g1_policy()->decide_on_conc_mark_initiation();
// We do not allow initial-mark to be piggy-backed on a mixed GC.
assert(!g1_policy()->during_initial_mark_pause() ||
g1_policy()->gcs_are_young(), "sanity");
// We also do not allow mixed GCs during marking.
assert(!mark_in_progress() || g1_policy()->gcs_are_young(), "sanity");
// 是否处于初始标记停顿阶段(youngGC这里返回的是false)
bool should_start_conc_mark = g1_policy()->during_initial_mark_pause();
// Inner scope for scope based logging, timers, and stats collection
{
EvacuationInfo evacuation_info;
// youngGC这里是false我们直接跳过
if (g1_policy()->during_initial_mark_pause()) {
// We are about to start a marking cycle, so we increment the
// full collection counter.
increment_old_marking_cycles_started();
register_concurrent_cycle_start(_gc_timer_stw->gc_start());
}
// 打印GC开始日志和活跃线程数
_gc_tracer_stw->report_yc_type(yc_type());
// ...
// 将二级空闲region列表合并到主空闲列表中
// 二级空闲region列表包括之前释放的region
if (!G1StressConcRegionFreeing) {
append_secondary_free_list_if_not_empty_with_lock();
}
// ...
{ // Call to jvmpi::post_class_unload_events must occur outside of active GC
IsGCActiveMark x;
if (G1ElasticHeap) {
elastic_heap()->prepare_in_gc_start();
}
// 填充tlab,扫描所有java线程的tlab并用空对象填充,之后再重置
gc_prologue(false);
increment_total_collections(false /* full gc */);
// ...
// 启动在全局停顿时期的软引用发现执行器
ref_processor_stw()->enable_discovery(true /*verify_disabled*/,
true /*verify_no_refs*/);
{
// 关闭并发扫描阶段的软引用发现执行器
NoRefDiscovery no_cm_discovery(ref_processor_cm());
// 重置_mutator_alloc_region即主动将其中的活跃区域retire但是这次不会填充还没使用的区域
// 因为马上要gc了,之后将活跃的region并将其加入到_inc_cset_head中(增量cset)
// _mutator_alloc_region前面我们提到过是申请伊甸区内存的类
// 此时增量cset中将包含所有的eden区region
_allocator->release_mutator_alloc_region();
_hr_printer.start_gc(false /* full */, (size_t) total_collections());
double sample_start_time_sec = os::elapsedTime();
#if YOUNG_LIST_VERBOSE
gclog_or_tty->print_cr("\nBefore recording pause start.\nYoung_list:");
_young_list->print();
g1_policy()->print_collection_set(g1_policy()->inc_cset_head(), gclog_or_tty);
#endif // YOUNG_LIST_VERBOSE
g1_policy()->record_collection_pause_start(sample_start_time_sec, *_gc_tracer_stw);
double scan_wait_start = os::elapsedTime();
bool waited = _cm->root_regions()->wait_until_scan_finished();
double wait_time_ms = 0.0;
if (waited) {
double scan_wait_end = os::elapsedTime();
wait_time_ms = (scan_wait_end - scan_wait_start) * 1000.0;
}
g1_policy()->phase_times()->record_root_region_scan_wait_time(wait_time_ms);
#if YOUNG_LIST_VERBOSE
gclog_or_tty->print_cr("\nAfter recording pause start.\nYoung_list:");
_young_list->print();
#endif // YOUNG_LIST_VERBOSE
if (g1_policy()->during_initial_mark_pause()) {
concurrent_mark()->checkpointRootsInitialPre();
}
// ...
// 这里会筛选cset,这个方法会将增量cset设置成cset ,YGC时cset中将包含所有的eden区
// 同时在其中判断是否存在大对象分区的引用,
// 并将youngRegion中的survivor区全部设置成单纯的young区
// 因为gc之后老的survivor区将变成新的eden区
g1_policy()->finalize_cset(target_pause_time_ms, evacuation_info);
// ...
// 设置存放活跃对象的大小
setup_surviving_young_words();
// Initialize the GC alloc regions.
// 初始化GC要申请的region,包括要用的新的survivor区域和old区域
// 标记要GC的分区
_allocator->init_gc_alloc_regions(evacuation_info);
// Actually do the work...
// 并行处理Cset中的引用,释放内存
evacuate_collection_set(evacuation_info);
// 后面是gc的收尾工作,后面在看
// ...
return true;
}
在进入关键方法evacuate_collection_set之前,需要先讲一下接下来会涉及的知识点:
RSet 记忆集相关概念(RSet&卡表、DCQ&DCQS、Refine线程)
为了记录对象在不同代际之间的引用关系,目的是在垃圾回收的时候快速地找到活跃对象,不用遍历整个堆空间。G1中引入了新的Refine线程用于处理这种引用关系。
1.记忆集和卡表
**RSet(Remember Set,简称RSet)。**因为标记阶段需要标记所有的存活对象,而在分代垃圾收集下,新生代和老年代处于不同的收集阶段,没有必要去标记所有的存活对象。因此使用了一个RSet记录从非收集部分指向收集部分的指针的集合,描述了对象的引用关系。RSet是针对于Region的。
通常有两种方法记录引用关系:
Point Out,在RSet中记录引用对象的地址,操作简单,但是标记扫描时需要扫描所有的RSet。Point In,在RSet中记录被引用对象的地址,操作复杂,标记扫描时可以直接找到有用和无用的对象,因为RSet中的对象可以认为是根对象。
Region之间的引用关系可以划分为:
- Region内部有引用关系,垃圾回收的时候是针对分区,回收时会遍历整个分区,无需记录这种关系。
- 新生代到新生代Region,无需记录,因为三种回收算法都会全量处理新生代分区,它们会被遍历。
- 新生代到老年代Region,对于YGC来说,会针对新生代分区所以无需记录,对于混合GC来说,G1会使用新生代分区作为根,遍历新生代分区的时候自然会找到老年代分区,因此无需记录,对于Full GC来说,所有的分区都会被处理,更无需记录。
- 老年代到新生代Region,需要被记录,YGC的时候需要知道哪些对象是被老年代分区所引用的,YGC的时候有两种根,一个就是栈空间/全局空间变量的引用,另一个就是老年代分区到新生代分区的引用。
- 老年代到老年代Region,需要被记录,在混合GC的时候可能只有部分分区被回收,所以必须记录引用关系,快速找到哪些对象是活跃的。
G1中使用了Point In的方法,算法可以简化为找到需要收集的分区Region集合,所以YGC只需要扫描Root Set和RSet即可,如果对象的引用发生了变化(通常就是赋值操作),必须要通知RSet,更改其中的记录。对于一个分区来说,里面的对象可能被很多分区引用,这就要求这个分区记录所有引用者的信息,所以G1垃圾收集器使用了一种新的数据结构:PRT (Per Region Table)来记录这种变化。
那么有了RSet之后怎么来表示引用关系呢?
**卡表(card table)**全局只有一个可以理解为是一个bitmap,并且其中每个元素即是卡页(card)与堆中的512字节内存相互映射,当这512个字节中的引用发生修改时,写屏障就会把这个卡页标记为脏卡(dirty_card)。
其实在很多博客中,都提到了卡表使用的是堆空间。然而这是不正确的!
由于card_table在heap之后才会申请创建,也就是说是堆内存确认之后才会开始进行卡表的内存申请,且是随机映射,而heap是根据对应地址去映射,所以card_table并不是使用的heap空间。
我们再来看RSet:
每个HeapRegion都包含了一个HeapRegionRemSet,每个HeapRegionRemSet都包含了一个OtherRegionsTable,引用数据就保存在这个OtherRegionsTable中。
class OtherRegionsTable VALUE_OBJ_CLASS_SPEC {
BitMap _coarse_map;//粗粒度位图
PerRegionTable** _fine_grain_regions;//细粒度PRT
SparsePRT _sparse_table;//稀疏哈希表
// ...
}
OtherRegionsTable使用了三种不同的粒度来描述引用,因为G1采用了Point In,它的缺点是一个对象可能被引用多次,次数不固定,为了提高效率,使用了动态化数据结构存储,三种粒度对应RSet中的三种数据类型:
稀疏PRT:通过哈希表方式来存储。表中每个entry默认存放card index的数组长度为4。细粒度PRT:通过PRT指针的指针,所以可以简单地理解为PRT指针的数组。其数组长度可以指定也可以自动计算得到。粗粒度PRT:通过位图来指示,每一位表示对应的分区有引用到该分区数据结构。
稀疏PRT:
通过SparsePRT类中的RSHashTable进行存储,哈希表中的entry为SparsePRTEntry:
class SparsePRTEntry: public CHeapObj<mtGC> {
private:
RegionIdx_t _region_ind; // 存放被引用对象所在Region的index
int _next_index;
CardIdx_t _cards[1]; // 存放被引用对象所在的相应的卡表index
// ...
}
向稀疏PRT中entry中添加引用关系:
// 向稀疏哈希表entry中添加引用
bool RSHashTable::add_card(RegionIdx_t region_ind, CardIdx_t card_index) {
// 根据region index获取 稀疏哈希表Entry
SparsePRTEntry* e = entry_for_region_ind_create(region_ind);
assert(e != NULL && e->r_ind() == region_ind,
"Postcondition of call above.");
// 添加卡表索引到稀疏哈希表Entry
SparsePRTEntry::AddCardResult res = e->add_card(card_index);
// 如果添加卡表索引结果为added ,则将持有的卡页数量加1
if (res == SparsePRTEntry::added) _occupied_cards++;
#if SPARSE_PRT_VERBOSE
gclog_or_tty->print_cr(" after add_card[%d]: valid-cards = %d.",
pointer_delta(e, _entries, SparsePRTEntry::size()),
e->num_valid_cards());
#endif
assert(e->num_valid_cards() > 0, "Postcondition");
// 最后返回添加结果是不是overflow
return res != SparsePRTEntry::overflow;
}
继续进入其add_card方法:
// 定义好的结果状态
enum AddCardResult {
overflow,
found,
added
};
// 定义 UNROLL_CARD_LOOPS 为 1
#define UNROLL_CARD_LOOPS 1
// 添加card index
SparsePRTEntry::AddCardResult SparsePRTEntry::add_card(CardIdx_t card_index) {
// 定义好了该值为1
#if UNROLL_CARD_LOOPS
assert((cards_num() & (UnrollFactor - 1)) == 0, "Invalid number of cards in the entry");
CardIdx_t c;
// 进入循环:UnrollFactor = 4
for (int i = 0; i < cards_num(); i += UnrollFactor) {
// 如果已经存在,则返回found状态,否则就设置为该位置的值,返回added状态
c = _cards[i];
if (c == card_index) return found;
if (c == NullEntry) { _cards[i] = card_index; return added; }
c = _cards[i + 1];
if (c == card_index) return found;
if (c == NullEntry) { _cards[i + 1] = card_index; return added; }
c = _cards[i + 2];
if (c == card_index) return found;
if (c == NullEntry) { _cards[i + 2] = card_index; return added; }
c = _cards[i + 3];
if (c == card_index) return found;
if (c == NullEntry) { _cards[i + 3] = card_index; return added; }
}
#else
for (int i = 0; i < cards_num(); i++) {
CardIdx_t c = _cards[i];
if (c == card_index) return found;
if (c == NullEntry) { _cards[i] = card_index; return added; }
}
#endif
// Otherwise, we're full.
// 否则就返回 overflow状态
return overflow;
}
其中的cards_num()值为:
// Returns the size of the card array.
static int cards_num() {
// The number of cards should be a multiple of 4, because that's our current
// unrolling factor.
static const int s = MAX2<int>(G1RSetSparseRegionEntries & ~(UnrollFactor - 1), UnrollFactor);
return s;
}
G1RSetSparseRegionEntries为全局flag,值为0。所以前面G1RSetSparseRegionEntries & ~(UnrollFactor - 1)的值为0。UnrollFactor为public常量,值为4。所以这里返回的值为4。(~ 为翻位操作)
每个entry中的cards数组的长度都应该为4的倍数,因为4是我们现在使用的扩展因子。
SparsePRTEntry初始化操作,会将entry中的cards数组初始化为-1,步骤和上述相似,就不赘述了:
// 稀疏PRT初始化
void SparsePRTEntry::init(RegionIdx_t region_ind) {
_region_ind = region_ind;
// NullEntry为public常量,值为-1
_next_index = NullEntry;
#if UNROLL_CARD_LOOPS
assert((cards_num() & (UnrollFactor - 1)) == 0, "Invalid number of cards in the entry");
for (int i = 0; i < cards_num(); i += UnrollFactor) {
_cards[i] = NullEntry;
_cards[i + 1] = NullEntry;
_cards[i + 2] = NullEntry;
_cards[i + 3] = NullEntry;
}
#else
for (int i = 0; i < cards_num(); i++)
_cards[i] = NullEntry;
#endif
}
细粒度PRT
当引用逐渐增多,RSet占用的内存空间就太大了。所以会将这种引用关系记录的详细程度往下降,描述不再那么详细进而存储更多的引用关系。当稀疏表中的某一个entry中的cards数组长度为4之后,就会将该entry中的所有记录转到细粒度PRT中。
class PerRegionTable: public CHeapObj<mtGC> {
friend class OtherRegionsTable;
friend class HeapRegionRemSetIterator;
HeapRegion* _hr; // Heap Region指针
BitMap _bm; // 位图,每一位映射Region中一个card
jint _occupied; // 引用数量
// next pointer for free/allocated 'all' list
PerRegionTable* _next;
// prev pointer for the allocated 'all' list
PerRegionTable* _prev;
// next pointer in collision list
PerRegionTable * _collision_list_next;
// Global free list of PRTs
static PerRegionTable* _free_list;
}
总体结构为:是一个双向链表且一个Region一个节点,每个节点中存放了一个key是card index的位图。向细粒度PRT中添加引用为:
// 细粒度PRT添加引用关系
void add_card_work(CardIdx_t from_card, bool par) {
// 如果不在细粒度PRT的位图中,就进行添加
if (!_bm.at(from_card)) {
// par 参数代表此时是不是并行添加
if (par) {
// 并行采用CAS添加
if (_bm.par_at_put(from_card, 1)) {
// 并行,使用原子自增引用数量 + 1
Atomic::inc(&_occupied);
}
} else {
_bm.at_put(from_card, 1);
// 引用数量 + 1
_occupied++;
}
}
}
粗粒度PRT:
对于被引用很多很多的对象来说,细粒度PRT的记录数同样也会不断飙升,所以在达到了G1设定的阈值之后,会转为使用粗粒度PRT:一个Region的粗粒度表就是一个位图。位图的0和1代表Region级别的引用关系。
具体结构其实就是OtherRegionsTable中的BitMap _coarse_map:
class OtherRegionsTable VALUE_OBJ_CLASS_SPEC {
BitMap _coarse_map;//粗粒度位图
// ...
}
至于细粒度PRT什么情况下会转为粗粒度PRT以及粗粒度PRT是如何添加引用关系的,我们会在接下来的向RSet中添加引用关系的逻辑操作中看到:
我们来看OtherRegionsTable中的add_reference向RSet中添加引用相关逻辑操作:
// 向RSet中的OtherRegionsTable中添加引用关系
void OtherRegionsTable::add_reference(OopOrNarrowOopStar from, int tid) {
// 获得当前region的index序列
uint cur_hrm_ind = hr()->hrm_index();
if (G1TraceHeapRegionRememberedSet) {
gclog_or_tty->print_cr("ORT::add_reference_work(" PTR_FORMAT "->" PTR_FORMAT ").",
from,
UseCompressedOops
? (void *)oopDesc::load_decode_heap_oop((narrowOop*)from)
: (void *)oopDesc::load_decode_heap_oop((oop*)from));
}
// 计算引用者所在的卡表位置
int from_card = (int)(uintptr_t(from) >> CardTableModRefBS::card_shift);
if (G1TraceHeapRegionRememberedSet) {
gclog_or_tty->print_cr("Table for [" PTR_FORMAT "...): card %d (cache = " INT32_FORMAT ")",
hr()->bottom(), from_card,
FromCardCache::at((uint)tid, cur_hrm_ind));
}
// 卡表缓存如果存在就直接返回
if (FromCardCache::contains_or_replace((uint)tid, cur_hrm_ind, from_card)) {
if (G1TraceHeapRegionRememberedSet) {
gclog_or_tty->print_cr(" from-card cache hit.");
}
assert(contains_reference(from), err_msg("We just found " PTR_FORMAT " in the FromCardCache", from));
return;
}
// Note that this may be a continued H region.
// 获取引用者card所在的region和index
HeapRegion* from_hr = _g1h->heap_region_containing_raw(from);
RegionIdx_t from_hrm_ind = (RegionIdx_t) from_hr->hrm_index();
// If the region is already coarsened, return.
// 如果RSet已经变成了粗粒度的关系,
// 也就是说其中记录的是引用者对象所在的分区而不是对象对应的卡表地址,则可以直接返回
// 这里的_coarse_map 是一个位图也就是粗粒度存储
// 如果在粗粒度位图中,直接返回
// 这个粗粒度位图的key是region_index
if (_coarse_map.at(from_hrm_ind)) {
// G1TraceHeapRegionRememberedSet 全局bool flags
// 代表HeapRegionRSet是否启用打印debug日志
if (G1TraceHeapRegionRememberedSet) {
gclog_or_tty->print_cr(" coarse map hit.");
}
assert(contains_reference(from), err_msg("We just found " PTR_FORMAT " in the Coarse table", from));
return;
}
// RSet 不是粗粒度关系,找到细粒度RPT引用关系添加到RSet中
// Otherwise find a per-region table to add it to.
// region index根据细粒度PerRegionTable的最大容量取模
size_t ind = from_hrm_ind & _mod_max_fine_entries_mask;
// 找到对应Region的细粒度PRT:通过PRT指针的指针,所以可以简单地理解为PRT指针的数组。其数组长度可以指定也可以自动计算得到
PerRegionTable* prt = find_region_table(ind, from_hr);
if (prt == NULL) {
// 如果细粒度PRT不存在
// 多线程访问,加锁。再次确认有没有细粒度PRT、针对并发情况
// 防止万一有其它线程这个时候将RSet数据结构进行转换
MutexLockerEx x(_m, Mutex::_no_safepoint_check_flag);
// Confirm that it's really not there...
prt = find_region_table(ind, from_hr);
if (prt == NULL) {
// 双重check,确保细粒度prt真的不存在
// 使用稀疏表存储
uintptr_t from_hr_bot_card_index =
uintptr_t(from_hr->bottom())
>> CardTableModRefBS::card_shift;
// 获取card_index
CardIdx_t card_index = from_card - from_hr_bot_card_index;
assert(0 <= card_index && (size_t)card_index < HeapRegion::CardsPerRegion,
"Must be in range.");
if (G1HRRSUseSparseTable &&
// 直接加入稀疏表,如果成功则返回,失败则继续执行
_sparse_table.add_card(from_hrm_ind, card_index)) {
if (G1RecordHRRSOops) {
HeapRegionRemSet::record(hr(), from);
if (G1TraceHeapRegionRememberedSet) {
gclog_or_tty->print(" Added card " PTR_FORMAT " to region "
"[" PTR_FORMAT "...) for ref " PTR_FORMAT ".\n",
align_size_down(uintptr_t(from),
CardTableModRefBS::card_size),
hr()->bottom(), from);
}
}
if (G1TraceHeapRegionRememberedSet) {
gclog_or_tty->print_cr(" added card to sparse table.");
}
assert(contains_reference_locked(from), err_msg("We just added " PTR_FORMAT " to the Sparse table", from));
return;
} else {
// 加入失败,打印稀疏表overflow状态的日志
if (G1TraceHeapRegionRememberedSet) {
gclog_or_tty->print_cr(" [tid %d] sparse table entry "
"overflow(f: %d, t: %u)",
tid, from_hrm_ind, cur_hrm_ind);
}
}
// 判断细粒度PerRegionTable是否满了
if (_n_fine_entries == _max_fine_entries) {
// 如果满了则删除当前表非空且引用数量最多的PRT
prt = delete_region_table();
// There is no need to clear the links to the 'all' list here:
// prt will be reused immediately, i.e. remain in the 'all' list.
// 再将返回的节点重新初始化
prt->init(from_hr, false /* clear_links_to_all_list */);
} else {
// 如果没满,则证明没有这个细粒度PerRegionTable
// 申请并与所有细粒度PerRegionTable关联
prt = PerRegionTable::alloc(from_hr);
// 连接到表头
link_to_all(prt);
}
// 将新申请的或者初始化的细粒度PerRegionTable加入细粒度PerRegionTable表集合中
PerRegionTable* first_prt = _fine_grain_regions[ind];
prt->set_collision_list_next(first_prt);
// The assignment into _fine_grain_regions allows the prt to
// start being used concurrently. In addition to
// collision_list_next which must be visible (else concurrent
// parsing of the list, if any, may fail to see other entries),
// the content of the prt must be visible (else for instance
// some mark bits may not yet seem cleared or a 'later' update
// performed by a concurrent thread could be undone when the
// zeroing becomes visible). This requires store ordering.
OrderAccess::release_store_ptr((volatile PerRegionTable*)&_fine_grain_regions[ind], prt);
_n_fine_entries++;
if (G1HRRSUseSparseTable) {
// Transfer from sparse to fine-grain.
// 程序走到这说明该Region在稀疏表中对应的SparsePRTEntry的cards数组都已经被使用了
// 并且我们已经申请了一个细粒度PRT
// 那我们要将稀疏表引用信息添迁移到细粒度PRT
// 1、获取稀疏哈希表
SparsePRTEntry *sprt_entry = _sparse_table.get_entry(from_hrm_ind);
assert(sprt_entry != NULL, "There should have been an entry");
// 2、遍历稀疏哈希表,将引用信息添加到细粒度PRT中
for (int i = 0; i < SparsePRTEntry::cards_num(); i++) {
CardIdx_t c = sprt_entry->card(i);
if (c != SparsePRTEntry::NullEntry) {
prt->add_card(c);
}
}
// Now we can delete the sparse entry.
// 稀疏表没用了,可以干掉了
bool res = _sparse_table.delete_entry(from_hrm_ind);
assert(res, "It should have been there.");
}
}
assert(prt != NULL && prt->hr() == from_hr, "consequence");
}
// Note that we can't assert "prt->hr() == from_hr", because of the
// possibility of concurrent reuse. But see head comment of
// OtherRegionsTable for why this is OK.
assert(prt != NULL, "Inv");
// 以上,数据结构转换完毕,将本次新增引用记录添加到细粒度PRT
// 加入PerRegionTable的位图中,这个位图key是card index
prt->add_reference(from);
if (G1RecordHRRSOops) {
HeapRegionRemSet::record(hr(), from);
if (G1TraceHeapRegionRememberedSet) {
gclog_or_tty->print("Added card " PTR_FORMAT " to region "
"[" PTR_FORMAT "...) for ref " PTR_FORMAT ".\n",
align_size_down(uintptr_t(from),
CardTableModRefBS::card_size),
hr()->bottom(), from);
}
}
assert(contains_reference(from), err_msg("We just added " PTR_FORMAT " to the PRT", from));
}
总体流程其实并不繁琐,现在对于之前保留的两个问题进行解答。细粒度在什么条件下会转换为粗粒度呢,我们可以看到在_n_fine_entries == _max_fine_entries这里的判断条件。在判断细粒度PerRegionTable是否满了的地方,也就是判断细粒度PRT是否达到了JVM给细粒度设定的阈值。如果没有达到,那么就会分配内存存值,并且会连接到细粒度PRT双向链表的表头。反之,如果没有达到,就会进入delete_region_table()方法。
关于转换的相关逻辑细节就需要进入delete_region_table()方法进行查看:
// 细粒度PRT转粗粒度PRT,并删除当前细粒度PRT
PerRegionTable* OtherRegionsTable::delete_region_table() {
assert(_m->owned_by_self(), "Precondition");
assert(_n_fine_entries == _max_fine_entries, "Precondition");
PerRegionTable* max = NULL;
jint max_occ = 0;
PerRegionTable** max_prev = NULL;
size_t max_ind;
size_t i = _fine_eviction_start;
// _fine_eviction_sample_size 细粒度PRT中已存个数
for (size_t k = 0; k < _fine_eviction_sample_size; k++) {
size_t ii = i;
// Make sure we get a non-NULL sample.
// 从细粒度PRT中_fine_eviction_start位置开始,找到第一个不为null的位置
while (_fine_grain_regions[ii] == NULL) {
ii++;
if (ii == _max_fine_entries) ii = 0;
guarantee(ii != i, "We must find one.");
}
// 将当前cur指针指向刚刚寻找到的位置
PerRegionTable** prev = &_fine_grain_regions[ii];
PerRegionTable* cur = *prev;
while (cur != NULL) {
// 获取当前Region index的key下的引用数量
jint cur_occ = cur->occupied();
if (max == NULL || cur_occ > max_occ) {
// 如果max还没有赋值或者引用数量大于max引用数量
// 使用max 保存当前相关数据
max = cur;
max_prev = prev;
max_ind = i;
max_occ = cur_occ;
}
// 获取下一个
prev = cur->collision_list_next_addr();
cur = cur->collision_list_next();
}
i = i + _fine_eviction_stride;
if (i >= _n_fine_entries) i = i - _n_fine_entries;
}
_fine_eviction_start++;
if (_fine_eviction_start >= _n_fine_entries) {
_fine_eviction_start -= _n_fine_entries;
}
guarantee(max != NULL, "Since _n_fine_entries > 0");
guarantee(max_prev != NULL, "Since max != NULL.");
// Set the corresponding coarse bit.
// 转换为粗粒度PRT位图
// 获取region index,这里的max实际上应该细粒度PRT中引用个数最多的那个
size_t max_hrm_index = (size_t) max->hr()->hrm_index();
// 如果粗粒度位图中没有这个region index
if (!_coarse_map.at(max_hrm_index)) {
// 就在位图塞入 key - region index,value - true
_coarse_map.at_put(max_hrm_index, true);
// 将 entry 数量 + 1
_n_coarse_entries++;
// 这里还是判断是否开启日志
if (G1TraceHeapRegionRememberedSet) {
gclog_or_tty->print("Coarsened entry in region [" PTR_FORMAT "...] "
"for region [" PTR_FORMAT "...] (%d coarse entries).\n",
hr()->bottom(),
max->hr()->bottom(),
_n_coarse_entries);
}
}
// Unsplice.
*max_prev = max->collision_list_next();
// 是否已经进行粗化, 原子自增1
Atomic::inc(&_n_coarsenings);
// 细粒度PRT中entry个数减一
_n_fine_entries--;
return max;
}
总体上来看其实就是,找到细粒度PRT中不为空并且引用数量最多的那个节点,将这个节点从细粒度双向链表中去除,并且存入在粗粒度PRT中的位图中。返回此节点重新进行初始化,之后再接回细粒度PRT中供再次使用。
OK,到这里关于引用关系存储结构这块就结束了。那么就会得到下一个问题:
有了RSet这样的动态存储引用关系的数据结构之后,我们应该通过什么样的方式来管理这样的引用数据?以及通过什么样的方式来提高处理这些引用关系的能力呢?
想要知道这两个问题的答案,就需要了解下一个相关的知识点。
2.Refine线程、DCQ&DCQS
Refine线程是G1新引入的并发线程,线程默认个数为G1ConcRefinementThreads + 1,如果没有设置则为ParallelGCThreads个 , 功能为:
- 处理新生代分区的抽样,并且在满足响应时间的这个指标下,更新YHR的个数,通常有一个线程来处理。我们把用于此功能的线程称为抽样线程。
- 主要功能:管理RSet,RSet的更新并不是同步完成的,G1会把所有的引用关系都先放入到一个队列中,称为
dirty card queue(DCQ),然后使用线程来消费这个队列以完成更新。正常来说有G1ConcRefinementThreads个线程处理;实际上除了Refine线程更新RSet之外,GC线程或者Mutator也可能会更新RSet;DCQ通过Dirty Card Queue Set(DCQS)来管理;为了能够并发地处理,每个Refine线程只负责DCQS中的某几个DCQ。
下面我们来详细介绍一下这些功能:
抽样处理新生代分区
Refine线程池中的最后一个线程就是抽样线程,主要作用是设置新生代分区的个数,使得G1满足垃圾回收的预测停顿时间。G1是一个响应时间优先的GC算法,用户可以设定整个GC过程的期望停顿时间,可以通过参数MaxGCPauseMillis控制,默认值为200ms。但是这个值只是期望值,表示G1会尽可能的在这个时间范围内完成垃圾回收的工作,但是并不能保证一定可以完成垃圾回收工作。
那么为什么满足垃圾回收预测停顿时间需要设置新生代分区个数呢?
对于Young GC来说,会逐渐减少Eden区个数,减少Eden空间那么Young GC的处理时间就会相应减少,因此会无法满足垃圾回收预测停顿时间。并且减少Eden的总空间时,就会更加频繁的触发Young GC,也就是会加快Mixed GC的执行频率,因为Mixed GC是由Young GC触发的,或者说借机同时执行的。频繁GC会对应用的吞吐量造成影响,每次Mixed GC回收时间太短,回收的垃圾量太少,可能最后GC的垃圾清理速度赶不上应用产生的速度,可能会造成串行的Full GC,这是要极力避免的。
同时为了满足用户的期望,G1还使用了停顿预测模型。G1根据这个模型统计计算出来的历史数据来预测本次收集需要的堆分区数量,也就是选择收集哪些内存空间。最简单的方法就是使用算术的平均值建立一个线性关系来进行预测。比如:过去10次一共收集了10GB的内存,花费了1s。那么在200ms的时间下,最多可以收集2GB的内存空间。而G1的预测逻辑是基于衰减平均值和衰减标准差来确定的。
衰减平均: 用来计算一个数列的平均值,核心是给近期的数据更高的权重,强调近期数据对结果的印象。
G1还可以自适应扩展内存空间的。参数-XX:GCTimeRatio表示了GC和应用的耗时比,默认为9。也就是说如果GC时间和应用时间占比不超过10%的话就不需要动态扩展。有一个参数G1ExpandByPercentOfAvailable(默认值为20)为一次扩展的比例。每次都至少从未提交的内存中申请20%大小的空间。当然也存在下限要求最少不能少于1MB,最大也不能超过当前已分配内存的一倍。
Refine优化线程的执行逻辑都存在于ConcurrentG1RefineThread::run()方法中,在这里就先介绍其中抽样线程的执行部分:
// 设置YHR - 新生代分区的个数,使G1满足GC的预测停顿时间-XX:MaxGCPauseMillis
void ConcurrentG1RefineThread::run_young_rs_sampling() {
// 获取DCQS - 线程共享
DirtyCardQueueSet& dcqs = JavaThread::dirty_card_queue_set();
_vtime_start = os::elapsedVTime();
// while 循环采样
while(!_should_terminate) {
// 采样方法
sample_young_list_rs_lengths();
if (os::supports_vtime()) {
_vtime_accum = (os::elapsedVTime() - _vtime_start);
} else {
_vtime_accum = 0.0;
}
// 加锁 - 线程共享、并发
MutexLockerEx x(_monitor, Mutex::_no_safepoint_check_flag);
if (_should_terminate) {
break;
}
// 每次采样间隔时间G1ConcRefinementServiceIntervalMillis
// 使用参数G1ConcRefinementServiceIntervalMillis控制抽样线程运行的频度,如果发现采样不足可以减少该时间,如果系统运行稳定满足预测时间,可以增大该值减少采样
_monitor->wait(Mutex::_no_safepoint_check_flag, G1ConcRefinementServiceIntervalMillis);
}
}
具体的抽样逻辑存在于方法sample_young_list_rs_lengths();中:
// Refine 线程采样方法,在 GC 停顿之间循环执行,迭代统计 CSet 中Reigon的 RSet 长度。
void ConcurrentG1RefineThread::sample_young_list_rs_lengths() {
SuspendibleThreadSetJoiner sts;
// 获取G1管理的堆空间
G1CollectedHeap* g1h = G1CollectedHeap::heap();
// G1收集器的当前策略对象
G1CollectorPolicy* g1p = g1h->g1_policy();
// 判断是否开启自适应策略
// 默认开启自适应策略,但是有两种情况会关闭:
// 设置了 NewRatio(但是未设置 NewSize 和 MaxNewSize)设置了 NewRatio(但是未设置 NewSize 和 MaxNewSize)
// 设置了 NewSize 和 MaxNewSize,并且数值一致(也就是设置 Xmn)
if (g1p->adaptive_young_list_length()) {
int regions_visited = 0;
// 初始化新生代分区链表的采样长度和位置
g1h->young_list()->rs_length_sampling_init();
// 循环将抽样分区加入到新生代分区集合
// young_list是所有新生代分区形成的一个链表
// rs_length_sampling_more判断当前分区指针是否为null,也就是判断当前操作是否可以继续执行下去
while (g1h->young_list()->rs_length_sampling_more()) {
// rs_length_sampling_next 处理一个分区,并将分区指针指向新生代分区链表中下一个分区
// 总体操作为:对新生代分区链表中的每个Region都判断是否在新生代回收集合CSet中,如果在,则将这个Region的RSet大小也就是它的PRT的分区个数加入到新生代回收需要处理的分区数目中
g1h->young_list()->rs_length_sampling_next();
// 当前线程处理分区个数加一
++regions_visited;
// 每次处理10个分区、主动让出cpu
// we try to yield every time we visit 10 regions
if (regions_visited == 10) {
if (sts.should_yield()) {
sts.yield();
// we just abandon the iteration
break;
}
regions_visited = 0;
}
}
// 用上面抽样数据更新YHR数目
// 使用停顿预测模型更新新生代分区数目
g1p->revise_young_list_target_length_if_necessary();
}
}
真正修正数目的操作则是在revise_young_list_target_length_if_necessary();中:
// 更新YHR数据方法 (修正新生代分区数目)
void G1CollectorPolicy::revise_young_list_target_length_if_necessary() {
guarantee( adaptive_young_list_length(), "should not call this otherwise" );
// 获取上面采样数目,每次采样所采样的RSet中被引用Region的个数大小
size_t rs_lengths = _g1->young_list()->sampled_rs_lengths();
// 判断大小是否超过了预测的大小
if (rs_lengths > _rs_lengths_prediction) {
// 将预测大小增加10%
// add 10% to avoid having to recalculate often
size_t rs_lengths_prediction = rs_lengths * 1100 / 1000;
// 更新数目,参数为采样得到的分区数目,使用方法为停顿预测模型
update_young_list_target_length(rs_lengths_prediction);
}
}
如果大小超过了预测的大小,就将预测的大小增加10%,并在update_young_list_target_length方法中通过停顿预测模型计算出分区个数之后进行更新。这里读者就不进行过多赘述了,想深入了解G1的停顿预测模型的同学可以继续从这里深入进行了解。
上面的源码中还提到了一下DCQS,虽然并没有涉及到使用,但是会在下一个功能点中大量涉及同时也是为了让读者更好地理解逻辑,所以我会在下一个功能点中进行相关介绍。
管理Remeber Set
G1中使用Refine线程异步维护和管理RSet的引用关系,因为是异步所以必须要有一个数据结构来维护这些需要引用的对象。JVM声明了一个全局的静态变量DirtyCardQueueSet(DCQS),每个DCQS中存放的是DirtyCardQueue(DCQ),为了性能,所有处理引用关系的线程共享DCQS,每个用户线程Mutator线程在初始化的时候都会关联DCQS。
每个用户线程都有一个私有的DCQ,每个队列的最大长度由G1UpdateBufferSize(默认256)确定,即最多存放256个引用关系对象。每次的引用修改都会执行写后屏障方法(简单理解类似切面),而写后屏障方法会把对应位置的卡页标记为脏卡,并加入DCQ中,这样所有的有效引用关关系都会在DCQ中,只要我们处理DCQ,就可以从中过滤出所有跨代引用。当满256个时,就把这个队列加入到DCQS中,因为DCQS被所有线程共享,所以放入时需要加锁,当然也可以手动提交当前线程的队列,但是当队列还没有满的时候,提交时需要指明有多少个引用关系,DCQ也是通过Refine线程来进行处理的。
dirty_card_queue_set().initialize(NULL, // Should never be called by the Java code
DirtyCardQ_CBL_mon, // 全局montior锁
DirtyCardQ_FL_lock,
-1, // never trigger processing 不需要处理
-1, // no limit on length 不做长度限制
Shared_DirtyCardQ_lock,
&JavaThread::dirty_card_queue_set() // java线程关联上DCQS,每个JavaTHread都可以通过dirty_card_queue_set()方法拿到DCQS
);
以上是初始化DCQS的方法,这里全局的Monitor的目的为:任意的用户线程都可以通过JavaThread中的静态方法找到DCQS这个静态成员变量,当DCQ满了之后就会把DCQ加入到DCQS中,当DCQ加入成功并且满足一定的条件(DCQS中DCQ的个数大于一个阈值,这个阈值和Green Zone相关),就会获取静态变量Monitor,然后通过这个Monitor发送Notify通知0号Refine线程启动,因为0号Refine线程可能会被任意一个用户线程通知,所以这里的Monitor是一个全局变量。
我们来看将对象加入到DCQ的逻辑:
// 把对象放入DCQ中,实际上DCQ就是一个buffer
void enqueue(void* ptr) {
if (!_active) return;
else
// 判断当前DCQ是否还有空间
enqueue_known_active(ptr);
}
继续下一步enqueue_known_active(ptr);:
// 根据判断当前DCQ是否还有空间来执行相关操作
void PtrQueue::enqueue_known_active(void* ptr) {
assert(0 <= _index && _index <= _sz, "Invariant.");
assert(_index == 0 || _buf != NULL, "invariant");
// _index个人理解为buffer的剩余空间大小 只有初始化和_buf满时_index会为0
while (_index == 0) {
// 处理index为0的情况
handle_zero_index();
}
assert(_index > 0, "postcondition");
// oopSize 在全局常量定义类中定义为一个char指针大小
_index -= oopSize;
_buf[byte_index_to_index((int)_index)] = ptr;
assert(0 <= _index && _index <= _sz, "Invariant.");
}
这里的_buf[]数组其实就是DCQ类中用于存放数据的地方。这里的_index其实是代表的是_buf[]的大小而不是下标。下标是通过byte_index_to_index((int)_index)进行计算所得,_index的值会在初始化的时候被设为0,以及在reset方法中被设为_buf[]大小的值。oopSize的值是被定义在JVM中的全局常量定义类中的,为sizeof(char*)其实就是一个指针大小,指针的大小和指针类型并没有什么关系都是4Byte大小。所以就不难理解为什么_index在加入对象到该DCQ后需要减去oopSize大小的原因了。因为存在_buf[]中的是指针,而_index代表的其实是_buf[]的大小。因此需要扣除存入指针的大小。
我们继续往下看handle_zero_index();这个方法只有在初始化和扩容的时候会进入:
// 对index为0的情况进行处理
// 只有在初始化和扩容的时候会进入
void PtrQueue::handle_zero_index() {
assert(_index == 0, "Precondition.");
// This thread records the full buffer and allocates a new one (while
// holding the lock if there is one).
// 判断是初始化还是扩容为null则为初始化
// true为DCQ已满
if (_buf != NULL) {
// should_enqueue_buffer 这里始终为true
if (!should_enqueue_buffer()) {
assert(_index > 0, "the buffer can only be re-used if it's not full");
return;
}
// 这个锁是和本DCQ关联的,将DCQ加入DCQS必须保证操作唯一
if (_lock) {
assert(_lock->owned_by_self(), "Required.");
// buf 指向原_buf[]内容
void** buf = _buf; // local pointer to completed buffer
// _buf 清除数据置空
_buf = NULL; // clear shared _buf field
// 加锁处理入队
locking_enqueue_completed_buffer(buf); // enqueue completed buffer
// While the current thread was enqueuing the buffer another thread
// may have a allocated a new buffer and inserted it into this pointer
// queue. If that happens then we just return so that the current
// thread doesn't overwrite the buffer allocated by the other thread
// and potentially losing some dirtied cards.
// 因为在加锁处理入队方法中对_lock进行了解锁,加上之前将_buf置空,所以可能有另外一个线程走到了下面的分配内存逻辑,所以这里如果不为null就直接返回
if (_buf != NULL) return;
} else {
// 处理DCQ,根据情况判断是否需要用户线程介入
if (qset()->process_or_enqueue_complete_buffer(_buf)) {
// Recycle the buffer. No allocation.
// 说明用户线程暂停执行应用代码,帮助处理DCQ,所以此时可以重用DCQ
_sz = qset()->buffer_size();
_index = _sz;
return;
}
}
}
// Reallocate the buffer
// 重新为DCQ中的_buf分配内存空间 / 初始化分配内存
_buf = qset()->allocate_buffer();
_sz = qset()->buffer_size();
// index 重新被设置为_buf的大小
_index = _sz;
assert(0 <= _index && _index <= _sz, "Invariant.");
}
把DCQ加入到DCQS的方法是enqueue_complete_buffer,它定义在PtrQueueSet中,PtrQueueSet是DirtyCardQueueSet的父类。process_or_enqueue_complete_buffer(_buf)和locking_enqueue_completed_buffer(buf)都会通过这个方法来实现将DCQ加入到DCQS中。我们继续来看process_or_enqueue_complete_buffer(_buf)这个方法:
// 处理DCQ,根据情况判断是否需要用户线程介入
bool PtrQueueSet::process_or_enqueue_complete_buffer(void** buf) {
// 判断当前线程是否是java线程也就是用户线程
if (Thread::current()->is_Java_thread()) {
// We don't lock. It is fine to be epsilon-precise here.
// 说明需要用户线程介入,没有加锁,允许一定的竞争,原因在于如果条件不满足,最坏的后果就是用户线程处理
// 如果是java线程判断当前refine线程负载也就是DCQS是否达到了红色区域
if (_max_completed_queue == 0 || _max_completed_queue > 0 &&
_n_completed_buffers >= _max_completed_queue + _completed_queue_padding) {
// 用户线程处理buff,实现在dirtyCardQueue.cpp中
bool b = mut_process_buffer(buf);
if (b) {
// True here means that the buffer hasn't been deallocated and the caller may reuse it.
return true;
}
}
}
// The buffer will be enqueued. The caller will have to get a new one.
// 用户线程没有介入,将buffer(DCQ)加入到DCQS中
enqueue_complete_buffer(buf);
return false;
}
在process_or_enqueue_complete_buffer中如果Mutator发现refine线程的负载已经到了红色区域也就是DCQS已经快满了,那么就不继续往DCQS中添加了,这个时候说明引用变更太多了,Refine线程负载太重,这个Mutator就会暂停代码执行,替代Refine线程来更新RSet。
Refine线程忙不过来时,G1会让用户线程帮忙处理引用变更。Refine线程的个数可以由用户设置,但是仍然可能存在因为对象引用修改太多,导致Refine线程太忙,处理不过来。所以让用户线程来处理引用变更,这样不仅可以暂停业务处理,还可以帮助处理引用关系。如果发生这种情况,要么就是修改关系太多,要么就是Refine线程数目设置太少。我们可以通过参数G1SummarizeRSetStats打开RSet处理过程中的日志,可以在其中查看处理线程的信息。
有些同学可能对这里所描述的线程负载和"红色区域"的关系有些模糊,之后的逻辑过程正好也需要使用到这部分的相关概念,因此在这里优先介绍一下这部分知识。
Refinement Zone
JVM为了防止没有足够多的引用变更关系从而导致Refine线程空转的现象,通过wait和notify来控制Refine的冻结和激活,设计思想为:前一个线程发现自己太忙,就会激活后一个线程,后一个线程发现自己太闲,就会主动冻结自己,第0个线程则由java【用户】线程来进行激活。如果用户线程尝试把修改的引用放入到队列的时候,如果0号线程还没有被激活,那么就发送notify信号来激活0号线程,因为0号线程可能被任意的用户线程激活,所以0号线程等待的是一个全局的变量的monitor,剩余之后的线程中的monitor则全部都为局部变量。
我们知道Refine线程的工作情况会根据其负载情况而改变,如果线程负载大则会唤醒后一个Refine线程一起工作,如果DCQS太满,所有的Refine线程负载都很大则会使用用户线程来帮助Refine线程进行处理引用关系。而这里的工作负载就是通过Refinement Zone来进行控制的,G1提供三个值,分别为Green、Yellow、Red,将整个DCQS计划分为四个区:
- 白区:[0,Green) ,此区域内,Refine线程不处理,交给GC线程来处理DCQ
- 绿区:[Green,Yellow),该区中,Refine线程开始启动,根据DCQS的大小启动不同数量的Refine线程来处理DCQ
- 黄区:[Yellow,Red),该区中,所有的Refine线程(除了抽样线程)都会参与DCQ处理
- 红区:[Red,无穷),在黄区处理的基础上还要加上用户线程也会参与处理DCQ
稍微了解了Refinement Zone的相关知识点之后,我们继续来查看如果DCQS已经使用到了红区,用户线程是如何来处理的:
// 用户线程操作buffer
bool DirtyCardQueueSet::mut_process_buffer(void** buf) {
// Used to determine if we had already claimed a par_id
// before entering this method.
bool already_claimed = false;
// We grab the current JavaThread.
// 获取当前java线程
JavaThread* thread = JavaThread::current();
// We get the the number of any par_id that this thread
// might have already claimed.
// 获取线程par_id
uint worker_i = thread->get_claimed_par_id();
// If worker_i is not UINT_MAX then the thread has already claimed
// a par_id. We make note of it using the already_claimed value
// 如果worker_i不为 unint_max 就证明线程已经申请过par_id
if (worker_i != UINT_MAX) {
already_claimed = true;
} else {
// 否则重新获取个par_id
// Otherwise we need to claim a par id
worker_i = _free_ids->claim_par_id();
// 存储par_id
// And store the par_id value in the thread
thread->set_claimed_par_id(worker_i);
}
bool b = false;
if (worker_i != UINT_MAX) {
// 处理脏卡队列的主要逻辑操作
b = DirtyCardQueue::apply_closure_to_buffer(_mut_process_closure, buf, 0,
_sz, true, worker_i);
if (b) Atomic::inc(&_processed_buffers_mut);
// If we had not claimed an id before entering the method
// then we must release the id.
// 如果是本次调用申请的par_id则要归还
if (!already_claimed) {
// 归还par_id
// we release the id
_free_ids->release_par_id(worker_i);
//同时将线程par_id设置为 uint_max
// and set the claimed_id in the thread to UINT_MAX
thread->set_claimed_par_id(UINT_MAX);
}
}
return b;
}
其中调用了关键方法apply_closure_to_buffer来处理脏卡队列。其实这个方法也是refine线程用来处理脏卡时会调用的逻辑方法。具体的refine线程的运行逻辑存在于ConcurrentG1RefineThread::run()中:
// Refine 线程的主要工作逻辑
void ConcurrentG1RefineThread::run() {
// 初始化线程私有信息
initialize_in_thread();
wait_for_universe_init();
// 最后一个线程用于处理YHR的数目 (worker_id 线程id,判断是否是最后一个Refine线程)
if (_worker_id >= cg1r()->worker_thread_num()) {
// 进行抽样预测使得停顿时间可以满足要求并调整YHR的数目
run_young_rs_sampling();
terminate();
return;
}
_vtime_start = os::elapsedVTime();
// 根据当前线程的_should_terminate属性判断是否应该终止
// 如果不是最后一个Refine线程,则没有调用terminate();
// 因此以下逻辑只能用于0 ~(n-1)的真正的Refine线程,处理RSet
while (!_should_terminate) {
DirtyCardQueueSet& dcqs = JavaThread::dirty_card_queue_set();
// Wait for work
// 前一线程通知后一个线程实现,0号线程由Mutator通知
wait_for_completed_buffers();
if (_should_terminate) {
break;
}
_sts.join();
do {
int curr_buffer_num = (int)dcqs.completed_buffers_num();
// If the number of the buffers falls down into the yellow zone,
// that means that the transition period after the evacuation pause has ended.
if (dcqs.completed_queue_padding() > 0 && curr_buffer_num <= cg1r()->yellow_zone()) {
dcqs.set_completed_queue_padding(0);
}
// 根据负载判断是否需要停止当前的Refine线程
if (_worker_id > 0 && curr_buffer_num <= _deactivation_threshold) {
// If the number of the buffer has fallen below our threshold
// we should deactivate. The predecessor will reactivate this
// thread should the number of the buffers cross the threshold again.
deactivate();
break;
}
// 根据负载判断是否需要通知/启动新的Refine线程
// Check if we need to activate the next thread.
if (_next != NULL && !_next->is_active() && curr_buffer_num > _next->_threshold) {
_next->activate();
}
// Refine线程的主要工作就是处理DCQS,其逻辑就在apply_closure_to_completed_buffer中
// _worker_id + _worker_id_offset, 工作线程要处理的开始位置,使得不同的Refine线程处理DCQS中不同的DCQ
// cg1r()->green_zone() ,就是Green Zone的数值,所有的Refine线程在处理的时候都知道要跳过多少至少Green个的DCQ
} while (dcqs.apply_closure_to_completed_buffer(_worker_id + _worker_id_offset, cg1r()->green_zone()));
// We can exit the loop above while being active if there was a yield request.
// 当有yield请求时退出循环,目的是为了进入安全点
if (is_active()) {
deactivate();
}
_sts.leave();
if (os::supports_vtime()) {
_vtime_accum = (os::elapsedVTime() - _vtime_start);
} else {
_vtime_accum = 0.0;
}
}
assert(_should_terminate, "just checking");
terminate();
}
最后一个Refine线程处理YHR的数目,具体逻辑已经在之前给出了。之后调用了DCQS中的方法apply_closure_to_completed_buffer会走到以下逻辑方法:
// refine线程实际run()中while调用本方法
bool DirtyCardQueueSet::apply_closure_to_completed_buffer(CardTableEntryClosure* cl,
uint worker_i,
int stop_at,
bool during_pause) {
assert(!during_pause || stop_at == 0, "Should not leave any completed buffers during a pause");
// 这个方法是获取已经满的buf
// stop_at是之前传入的绿标记,即Refine线程只处理白标记到绿标记之间的
BufferNode* nd = get_completed_buffer(stop_at);
// 进行处理
bool res = apply_closure_to_completed_buffer_helper(cl, worker_i, nd);
if (res) Atomic::inc(&_processed_buffers_rs_thread);
return res;
}
继续查看apply_closure_to_completed_buffer_helper:
bool DirtyCardQueueSet::
apply_closure_to_completed_buffer_helper(CardTableEntryClosure* cl,
uint worker_i,
BufferNode* nd) {
if (nd != NULL) {
void **buf = BufferNode::make_buffer_from_node(nd);
size_t index = nd->index();
// 可以看到还是调用和Mutator同样的方法,更新RSet
bool b =
DirtyCardQueue::apply_closure_to_buffer(cl, buf,
index, _sz,
true, worker_i);
// 更新成功
if (b) {
// 将该空缓冲区返回到空闲列表
deallocate_buffer(buf);
return true; // In normal case, go on to next buffer.
} else {
// 更新失败就继续尝试将本DCQ加入DCQS中
enqueue_complete_buffer(buf, index);
return false;
}
} else {
return false;
}
}
不难看出这里的apply_closure_to_buffer是和之前用户线程所调用的方法一致。于是通过查看此方法逻辑就可以得知G1在Refine线程和用户线程中是如何更新RSet的:
bool DirtyCardQueue::apply_closure_to_buffer(CardTableEntryClosure* cl,
void** buf,
size_t index, size_t sz,
bool consume,
uint worker_i) {
if (cl == NULL) return true;
for (size_t i = index; i < sz; i += oopSize) {
// 获取 index
int ind = byte_index_to_index((int)i);
jbyte* card_ptr = (jbyte*)buf[ind];
if (card_ptr != NULL) {
// Set the entry to null, so we don't do it again (via the test
// above) if we reconsider this buffer.
if (consume) buf[ind] = NULL;
// 实现关键
// 闭包方法do_card_ptr
if (!cl->do_card_ptr(card_ptr, worker_i)) return false;
}
}
return true;
}
其中的do_card_ptr是一个闭包方法是一种带有上下文的函数是能够读取其他函数内部变量的函数,在JVM中可以调用这个闭包方法的类为:RefineCardTableEntryClosure、ClearLoggedCardTableEntryClosure、RedirtyLoggedCardTableEntryClosure、RefineRecordRefsIntoCSCardTableEntryClosure。在本场景中Refine和Mutator线程中都是:RefineCardTableEntryClosure,在之后要继续介绍的YoungGC中则是:RefineRecordRefsIntoCSCardTableEntryClosure。
bool do_card_ptr(jbyte* card_ptr, uint worker_i) {
bool oops_into_cset = G1CollectedHeap::heap()->g1_rem_set()->refine_card(card_ptr, worker_i, false);
// This path is executed by the concurrent refine or mutator threads,
// concurrently, and so we do not care if card_ptr contains references
// that point into the collection set.
assert(!oops_into_cset, "should be");
if (_concurrent && SuspendibleThreadSet::should_yield()) {
// Caller will actually yield.
return false;
}
// Otherwise, we finished successfully; return true.
return true;
}
其中调用了refine_card方法,开始使用Refine线程处理我们之前的脏卡:
bool G1RemSet::refine_card(jbyte* card_ptr, uint worker_i,
bool check_for_refs_into_cset) {
assert(_g1->is_in_exact(_ct_bs->addr_for(card_ptr)),
err_msg("Card at " PTR_FORMAT " index " SIZE_FORMAT " representing heap at " PTR_FORMAT " (%u) must be in committed heap",
p2i(card_ptr),
_ct_bs->index_for(_ct_bs->addr_for(card_ptr)),
_ct_bs->addr_for(card_ptr),
_g1->addr_to_region(_ct_bs->addr_for(card_ptr))));
// If the card is no longer dirty, nothing to do.
// 判断card是否是脏卡,如果不是则直接返回
if (*card_ptr != CardTableModRefBS::dirty_card_val()) {
// No need to return that this card contains refs that point
// into the collection set.
return false;
}
// 获取card所映射的内存开始地址
// Construct the region representing the card.
HeapWord* start = _ct_bs->addr_for(card_ptr);
// And find the region containing it.
// 获取所在的分区
HeapRegion* r = _g1->heap_region_containing(start);
if (r->is_young()) {
return false;
}
// 判断在不在回收集合中,引用所在的region在回收集合中,就证明其在下次GC时会被扫描,所以也不用进入记忆集合
if (r->in_collection_set()) {
return false;
}
// 热卡缓存,判断是否用了热卡缓存,如果用了则加入
G1HotCardCache* hot_card_cache = _cg1r->hot_card_cache();
if (hot_card_cache->use_cache()) {
assert(!check_for_refs_into_cset, "sanity");
assert(!SafepointSynchronize::is_at_safepoint(), "sanity");
card_ptr = hot_card_cache->insert(card_ptr);
if (card_ptr == NULL) {
// There was no eviction. Nothing to do.
return false;
}
start = _ct_bs->addr_for(card_ptr);
r = _g1->heap_region_containing(start);
}
// 计算card映射的内存结束位置
HeapWord* end = start + CardTableModRefBS::card_size_in_words;
// 将这个区域声明为脏区
MemRegion dirtyRegion(start, end);
#if CARD_REPEAT_HISTO
init_ct_freq_table(_g1->max_capacity());
ct_freq_note_card(_ct_bs->index_for(start));
#endif
G1ParPushHeapRSClosure* oops_in_heap_closure = NULL;
// 如果是refine线程调用,那么这个参数的值为false,所以对应oops_in_heap_closure的值为null
if (check_for_refs_into_cset) {
assert((size_t)worker_i < n_workers(), "index of worker larger than _cset_rs_update_cl[].length");
oops_in_heap_closure = _cset_rs_update_cl[worker_i];
}
// 更新RSet或者入列引用的闭包方法
G1UpdateRSOrPushRefOopClosure update_rs_oop_cl(_g1,
_g1->g1_rem_set(),
oops_in_heap_closure,
check_for_refs_into_cset,
worker_i);
update_rs_oop_cl.set_from(r);
G1TriggerClosure trigger_cl;
FilterIntoCSClosure into_cs_cl(NULL, _g1, &trigger_cl);
G1InvokeIfNotTriggeredClosure invoke_cl(&trigger_cl, &into_cs_cl);
G1Mux2Closure mux(&invoke_cl, &update_rs_oop_cl);
// 这个闭包封装了G1UpdateRSOrPushRefOopClosure,可以看到当oops_in_heap_closure为null
//会直接使用update_rs_oop_cl
FilterOutOfRegionClosure filter_then_update_rs_oop_cl(r,
(check_for_refs_into_cset ?
(OopClosure*)&mux :
(OopClosure*)&update_rs_oop_cl));
bool card_processed =
// 处理卡页逻辑
r->oops_on_card_seq_iterate_careful(dirtyRegion,
&filter_then_update_rs_oop_cl,
card_ptr);
// ...
return has_refs_into_cset;
}
其中有一个小点,就是会判断脏卡所在的分区Region是不是属于新生代分区,如果是,则会直接返回。这是因为youngGC的时候我们只需要知道老年代到新生代的引用关系,只处理这种关系而不处理老年代到老年代的引用关系可以避免遍历整个老年代。至于新生代到新生代或者老年代的引用不应该被记录。在YoungGC中check_for_refs_into_cset的值为true,会将引用关系存放到一个队列中去。具体操作会在之后继续介绍YoungGC的时候进行展开。
这里呢我们只需要关注处理卡页逻辑的操作,从oops_on_card_seq_iterate_careful方法中进入:
// 处理卡页逻辑
bool HeapRegion::oops_on_card_seq_iterate_careful(MemRegion mr,
FilterOutOfRegionClosure* cl,
jbyte* card_ptr) {
assert(card_ptr != NULL, "pre-condition");
G1CollectedHeap* g1h = G1CollectedHeap::heap();
if (g1h->is_gc_active()) {
mr = mr.intersection(MemRegion(bottom(), scan_top()));
} else {
mr = mr.intersection(used_region());
}
if (mr.is_empty()) {
return true;
}
// 如果是新生代的分区那么就直接返回
if (is_young()) {
return true;
}
// 将这个卡的标记置为清理过的状态
*card_ptr = CardTableModRefBS::clean_card_val();
// 通过storeload屏障确保对所有的处理器可见
OrderAccess::storeload();
// Special handling for humongous regions.
// 特殊处理大对象分区
if (isHumongous()) {
return do_oops_on_card_in_humongous(mr, cl, this, g1h);
}
// 缓存memory region的起始和结束位置
HeapWord* const start = mr.start();
HeapWord* const end = mr.end();
// 获取最开始的不在该region中的引用对象的地址
HeapWord* cur = block_start(start);
do {
// 获取当前位置的对象
oop obj = oop(cur);
// 校验对象
assert(obj->is_oop(true), err_msg("Not an oop at " PTR_FORMAT, p2i(cur)));
assert(obj->klass_or_null() != NULL,
err_msg("Unparsable heap at " PTR_FORMAT, p2i(cur)));
// 判断对象是否存活
if (g1h->is_obj_dead(obj, this)) {
// Carefully step over dead object.
// 如果对象已经死亡,则将cur指针向后移动至下一个引用本对象的位置
cur += block_size(cur);
} else {
// 如果对象仍然存活
// 将cur指针向后移动对象的大小
cur += obj->size();
// 如果当前对象不是数组(供堆可栈解析时添加的dummy对象),或者 该对象时本region中的引用对象
if (!obj->is_objArray() || (((HeapWord*)obj) >= start && cur <= end)) {
obj->oop_iterate(cl);
} else {
// 处理数组或者是跨region的引用
// 这里会调用很多宏命令定义的方法,最后会用传入的闭包G1UpdateRSOrPushRefOopClosure进行遍历
obj->oop_iterate(cl, mr);
}
}
// 从最前的引用地址开始,一直到最后的引用地址,进行遍历
} while (cur < end);
return true;
}
传参中的jbyte* card_ptr是DCQS中DCQ中一个元素指向一个卡页的指针,MemRegion mr是将这个指针指向位置为起始位置在之前标记的脏卡区域。DCQ中存放的数据应该是引用者所在的卡页信息。每个卡页映射的区域都是512字节,当这个卡页被标记为脏时,说明这512字节中会存在被修改的引用,所以我们要遍历这个区域的所有引用。
因为我们之前使用的是闭包G1UpdateRSOrPushRefOopClosure,所以最终会调用到G1UpdateRSOrPushRefOopClosure::do_oop_nv该核心方法,其中会调用到我们之前提到的add_reference方法来向RSet中更新引用关系。
// 将引用关系添加至RSet
template <class T>
inline void G1UpdateRSOrPushRefOopClosure::do_oop_nv(T* p) {
// 将p转换得到对象
oop obj = oopDesc::load_decode_heap_oop(p);
if (obj == NULL) {
return;
}
assert(_from != NULL, "from region must be non-NULL");
assert(_from->is_in_reserved(p), "p is not in from");
// to指向上述对象所在的region
HeapRegion* to = _g1->heap_region_containing(obj);
// _from 是 上一个持有对象的卡页所在的Region
// 也就是说如果现在Region和上一个处理的Region是同一个,就说明本次obj的处理效果和上一次的相同,所以可以直接跳过
if (_from == to) {
return;
}
// _record_refs_into_cset的值根据注解可以得知:
// true: 在一个evacuation pause中更新RSet的时候
// false: 1. 在full GC后重新构建RSet时 2. 在refine线程并发调用时 3. 在evacuation failure事件中更新CSet中Region的RSet时
// 先在to指向的Region已经存在于CSet中
if (_record_refs_into_cset && to->in_collection_set()) {
// 如果从标记中使用的编码形式恢复oop的地址不是obj的地址
if (!self_forwarded(obj)) {
assert(_push_ref_cl != NULL, "should not be null");
// G1ParScanThreadState 中将引用关系塞入引用队列中
_push_ref_cl->do_oop(p);
}
} else {
assert(to->rem_set() != NULL, "Need per-region 'into' remsets.");
// 更新to指向Region的RSet
to->rem_set()->add_reference(p, _worker_i);
}
}
总之,Refine通过DCQS来维护RSet的整体更新流程为:对于通过DCQS选出的需要处理分区的512字节,通过遍历的方式寻找到第一个对象,当作引用者来处理,通过引用者寻找到被引用者,在被引用者所在的分区中更新其RSet中记录的引用关系。
在Refine线程的执行过程中,被引用者的地址不会发生变化,因为Refine线程过程中并不会发生GC,因此对象地址都是固定的。
OK,我们继续回到关键方法evacuate_collection_set,这个方法中会选择需要收集的CSet,针对新生代而言就是整个新生代分区。然后加入收集任务中,去并行处理引用。引用关系搜索完毕之后,就是进行对象引用回收,处理对象晋升,晋升失败的还原对象头,尝试扩展内存等。现在查看其前半部分中逻辑:
void G1CollectedHeap::evacuate_collection_set(EvacuationInfo& evacuation_info) {
_expand_heap_after_alloc_failure = true;
_evacuation_failed = false;
// Should G1EvacuationFailureALot be in effect for this GC?
NOT_PRODUCT(set_evacuation_failure_alot_for_current_gc();)
// 这个方法会把dcqs中没有满的dcq加入满的集合
// 因为之后要更新脏卡到rset中,所以这里会把所有没满的集合标记成满的集合,之后只需要处理被标记为满的queue就可以了
g1_rem_set()->prepare_for_oops_into_collection_set_do();
// Disable the hot card cache.
// 先关闭热卡缓存
G1HotCardCache* hot_card_cache = _cg1r->hot_card_cache();
hot_card_cache->reset_hot_cache_claimed_index();
hot_card_cache->set_use_cache(false);
// 获取gc工作线程数
const uint n_workers = workers()->active_workers();
assert(UseDynamicNumberOfGCThreads ||
n_workers == workers()->total_workers(),
"If not dynamic should be using all the workers");
set_par_threads(n_workers);
init_for_evac_failure(NULL);
rem_set()->prepare_for_younger_refs_iterate(true);
assert(dirty_card_queue_set().completed_buffers_num() == 0, "Should be empty");
double start_par_time_sec = os::elapsedTime();
double end_par_time_sec;
{
G1RootProcessor root_processor(this);
// youngGC任务类
G1ParTask g1_par_task(this, _task_queues, &root_processor);
// InitialMark needs claim bits to keep track of the marked-through CLDs.
if (g1_policy()->during_initial_mark_pause()) {
ClassLoaderDataGraph::clear_claimed_marks();
}
// 使用gc工作线程执行gc任务
if (G1CollectedHeap::use_parallel_gc_threads()) {
// The individual threads will set their evac-failure closures.
if (ParallelGCVerbose) G1ParScanThreadState::print_termination_stats_hdr();
// These tasks use ShareHeap::_process_strong_tasks
assert(UseDynamicNumberOfGCThreads ||
workers()->active_workers() == workers()->total_workers(),
"If not dynamic should be using all the workers");
// 使用并发GC线程执行任务
workers()->run_task(&g1_par_task);
} else {
g1_par_task.set_for_termination(n_workers);
g1_par_task.work(0);
}
end_par_time_sec = os::elapsedTime();
// Closing the inner scope will execute the destructor
// for the G1RootProcessor object. We record the current
// elapsed time before closing the scope so that time
// taken for the destructor is NOT included in the
// reported parallel time.
}
// ...
}
可以看到在其中添加了一个G1ParTask任务放到队列中,使用了并发GC线程去执行该任务。我们可以通过查看G1ParTask中的work()方法来了解到底执行了哪些逻辑操作。此方法是YoungGC的真正的入口,之前所有的操作全部都是GC前的准备操作并没有真正开始执行GC。在其中可以从我们熟悉的扫描根节点的方法开始真正进入到YoungGC的核心流程。
GC核心流程
// YGC 并行处理入口
void work(uint worker_id) {
if (worker_id >= _n_workers) return; // no work needed this round
_g1h->g1_policy()->phase_times()->record_time_secs(G1GCPhaseTimes::GCWorkerStart, worker_id, os::elapsedTime());
{
ResourceMark rm;
HandleMark hm;
ReferenceProcessor* rp = _g1h->ref_processor_stw();
G1ParScanThreadState pss(_g1h, worker_id, rp);
G1ParScanHeapEvacFailureClosure evac_failure_cl(_g1h, &pss, rp);
pss.set_evac_failure_closure(&evac_failure_cl);
bool only_young = _g1h->g1_policy()->gcs_are_young();
// Non-IM young GC.
G1ParCopyClosure<G1BarrierNone, G1MarkNone> scan_only_root_cl(_g1h, &pss, rp);
G1CLDClosure<G1MarkNone> scan_only_cld_cl(&scan_only_root_cl,
only_young, // Only process dirty klasses.
false); // No need to claim CLDs.
// IM young GC.
// Strong roots closures.
G1ParCopyClosure<G1BarrierNone, G1MarkFromRoot> scan_mark_root_cl(_g1h, &pss, rp);
G1CLDClosure<G1MarkFromRoot> scan_mark_cld_cl(&scan_mark_root_cl,
false, // Process all klasses.
true); // Need to claim CLDs.
// Weak roots closures.
G1ParCopyClosure<G1BarrierNone, G1MarkPromotedFromRoot> scan_mark_weak_root_cl(_g1h, &pss, rp);
G1CLDClosure<G1MarkPromotedFromRoot> scan_mark_weak_cld_cl(&scan_mark_weak_root_cl,
false, // Process all klasses.
true); // Need to claim CLDs.
OopClosure* strong_root_cl;
OopClosure* weak_root_cl;
CLDClosure* strong_cld_cl;
CLDClosure* weak_cld_cl;
bool trace_metadata = false;
if (_g1h->g1_policy()->during_initial_mark_pause()) {
// We also need to mark copied objects.
strong_root_cl = &scan_mark_root_cl;
strong_cld_cl = &scan_mark_cld_cl;
if (ClassUnloadingWithConcurrentMark) {
weak_root_cl = &scan_mark_weak_root_cl;
weak_cld_cl = &scan_mark_weak_cld_cl;
trace_metadata = true;
} else {
weak_root_cl = &scan_mark_root_cl;
weak_cld_cl = &scan_mark_cld_cl;
}
} else {
strong_root_cl = &scan_only_root_cl;
weak_root_cl = &scan_only_root_cl;
strong_cld_cl = &scan_only_cld_cl;
weak_cld_cl = &scan_only_cld_cl;
}
pss.start_strong_roots();
// 处理根
_root_processor->evacuate_roots(strong_root_cl,
weak_root_cl,
strong_cld_cl,
weak_cld_cl,
trace_metadata,
worker_id);
G1ParPushHeapRSClosure push_heap_rs_cl(_g1h, &pss);
// 处理DCQS中剩下的dcq,以及把RSet做为根进行扫描处理
_root_processor->scan_remembered_sets(&push_heap_rs_cl,
weak_root_cl,
worker_id);
pss.end_strong_roots();
{
double start = os::elapsedTime();
// 开始复制对象到survivor区域
G1ParEvacuateFollowersClosure evac(_g1h, &pss, _queues, _terminator.terminator());
evac.do_void();
double elapsed_sec = os::elapsedTime() - start;
double term_sec = pss.term_time();
_g1h->g1_policy()->phase_times()->add_time_secs(G1GCPhaseTimes::ObjCopy, worker_id, elapsed_sec - term_sec);
_g1h->g1_policy()->phase_times()->record_time_secs(G1GCPhaseTimes::Termination, worker_id, term_sec);
_g1h->g1_policy()->phase_times()->record_thread_work_item(G1GCPhaseTimes::Termination, worker_id, pss.term_attempts());
}
_g1h->g1_policy()->record_thread_age_table(pss.age_table());
_g1h->update_surviving_young_words(pss.surviving_young_words()+1);
if (ParallelGCVerbose) {
MutexLocker x(stats_lock());
pss.print_termination_stats(worker_id);
}
assert(pss.queue_is_empty(), "should be empty");
// Close the inner scope so that the ResourceMark and HandleMark
// destructors are executed here and are included as part of the
// "GC Worker Time".
}
_g1h->g1_policy()->phase_times()->record_time_secs(G1GCPhaseTimes::GCWorkerEnd, worker_id, os::elapsedTime());
}
可以看到在G1ParTask中,主要做了以下几件事:
- 执行根扫描,扫描直接强引用。主要是JVM根和Java根。
- 对RSet进行相关处理。
- 复制对象到survivor区域
我们首先来查看根扫描的相关逻辑:
根处理
JVM中的根也成为强根,指的是JVM的堆外空间引用到堆空间的对象,有栈或者全局变量等。根分为两大类:
- Java根:主要是类加载器和线程栈
**类加载器:**主要是遍历这个类加载器中所有存活的Klass(JVM对Java对象的元数据描述,Java对象的创建都需要通过元数据获得)并复制到Survivor或者晋升到老年代。
**线程栈:**这里既会处理Java线程栈分配的局部变量,也会处理本地方法栈访问的堆对象。
- JVM根:一般是全局对象,比如
Universe、JNIHandles、ObjectSynchronizer、FlatProfiler、Management、JvmtiExport、SystemDictionary、StringTable。
从evacuate_roots进入查看其逻辑:
// 处理根
void G1RootProcessor::evacuate_roots(OopClosure* scan_non_heap_roots,
OopClosure* scan_non_heap_weak_roots,
CLDClosure* scan_strong_clds,
CLDClosure* scan_weak_clds,
bool trace_metadata,
uint worker_i) {
// First scan the shared roots.
double ext_roots_start = os::elapsedTime();
G1GCPhaseTimes* phase_times = _g1h->g1_policy()->phase_times();
// 使用BufferingOopClosure,主要是为了缓存对象,然后一次性处理,大小为1024
// 如果溢出,那么就先进行处理,提高了处理的效率
BufferingOopClosure buf_scan_non_heap_roots(scan_non_heap_roots);
BufferingOopClosure buf_scan_non_heap_weak_roots(scan_non_heap_weak_roots);
OopClosure* const weak_roots = &buf_scan_non_heap_weak_roots;
OopClosure* const strong_roots = &buf_scan_non_heap_roots;
// CodeBlobClosures are not interoperable with BufferingOopClosures
G1CodeBlobClosure root_code_blobs(scan_non_heap_roots);
// 处理Java根,主要指类加载器和线程栈
process_java_roots(strong_roots,
trace_metadata ? scan_strong_clds : NULL,
scan_strong_clds,
trace_metadata ? NULL : scan_weak_clds,
&root_code_blobs,
phase_times,
worker_i);
if (trace_metadata) {
worker_has_discovered_all_strong_classes();
}
// 处理jvm根,通常是全局对象,如:Universe,JNIHandles,Management等
process_vm_roots(strong_roots, weak_roots, phase_times, worker_i);
// 处理StringTable JVM字符串哈希表的引用
process_string_table_roots(weak_roots, phase_times, worker_i);
{
// Now the CM ref_processor roots.
// 处理引用发现
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::CMRefRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_refProcessor_oops_do)) {
_g1h->ref_processor_cm()->weak_oops_do(&buf_scan_non_heap_roots);
}
}
if (trace_metadata) {
{
// 混合回收的时候,把并发标记中已经失效的引用关系移除,YGC不会执行到这里
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::WaitForStrongCLD, worker_i);
wait_until_all_strong_classes_discovered();
}
// Now take the complement of the strong CLDs.
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::WeakCLDRoots, worker_i);
ClassLoaderDataGraph::roots_cld_do(NULL, scan_weak_clds);
} else {
phase_times->record_time_secs(G1GCPhaseTimes::WaitForStrongCLD, worker_i, 0.0);
phase_times->record_time_secs(G1GCPhaseTimes::WeakCLDRoots, worker_i, 0.0);
}
// ...
// 等待所有的任务结束
_process_strong_tasks.all_tasks_completed();
}
可以看到对于Java根的处理是调用了process_java_roots(),对于JVM根的处理则是调用了process_vm_roots。
JAVA根处理
其中对于Java根的处理是:
// java根的处理
void G1RootProcessor::process_java_roots(OopClosure* strong_roots,
CLDClosure* thread_stack_clds,
CLDClosure* strong_clds,
CLDClosure* weak_clds,
CodeBlobClosure* strong_code,
G1GCPhaseTimes* phase_times,
uint worker_i) {
assert(thread_stack_clds == NULL || weak_clds == NULL, "There is overlap between those, only one may be set");
// Iterating over the CLDG and the Threads are done early to allow us to
// first process the strong CLDs and nmethods and then, after a barrier,
// let the thread process the weak CLDs and nmethods.
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::CLDGRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_ClassLoaderDataGraph_oops_do)) {
// 类加载器处理
ClassLoaderDataGraph::roots_cld_do(strong_clds, weak_clds);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::ThreadRoots, worker_i);
// 线程栈处理
Threads::possibly_parallel_oops_do(strong_roots, thread_stack_clds, strong_code);
}
}
类加载器处理
有关于类加载器的处理为:
// 处理java根中有关类加载器的部分
void ClassLoaderDataGraph::roots_cld_do(CLDClosure* strong, CLDClosure* weak) {
// 遍历ClassLoaderDataGraph中的ClassLoaderData链表中的数据,ClassLoaderData中记录的是关联的Java ClassLoader实例
for (ClassLoaderData* cld = _head; cld != NULL; cld = cld->_next) {
// keep_alive()返回_keep_alive。如果值为true,表示ClassLoaderData是活跃的但是没有关联的活跃对象,比如匿名类的类加载器和启动类加载器实例,为true则不能被GC回收掉
CLDClosure* closure = cld->keep_alive() ? strong : weak;
if (closure != NULL) {
closure->do_cld(cld);
}
}
}
通过遍历的了ClassLoaderDataGraph中的ClassLoaderData链表中的数据得到了其中对应的关联的ClassLoader实例,最终会调用到do_klass():
void ClassLoaderData::oops_do(OopClosure* f, KlassClosure* klass_closure, bool must_claim) {
if (must_claim && !claim()) {
return;
}
f->do_oop(&_class_loader);
_dependencies.oops_do(f);
_handles.oops_do(f);
if (klass_closure != NULL) {
classes_do(klass_closure);
}
}
// classes_do(klass_closure);
void ClassLoaderData::classes_do(KlassClosure* klass_closure) {
// 对每个ClassLoaderData中的加载的所有Klass进行遍历
// _klasses指向该ClassLoaderData加载的所有Klass链表
for (Klass* k = _klasses; k != NULL; k = k->next_link()) {
klass_closure->do_klass(k);
assert(k != k->next_link(), "no loops!");
}
}
我们继续查看do_klass方法搞清楚对每个加载过的Klass做了哪些操作:
void do_klass(Klass* klass) {
// If the klass has not been dirtied we know that there's
// no references into the young gen and we can skip it.
if (!_process_only_dirty || klass->has_modified_oops()) {
// Clean the klass since we're going to scavenge all the metadata.
klass->clear_modified_oops();
// Tell the closure that this klass is the Klass to scavenge
// and is the one to dirty if oops are left pointing into the young gen.
_closure->set_scanned_klass(klass);
// 通过G1ParCopyHelper来把活跃的对象复制到新的分区中
klass->oops_do(_closure);
_closure->set_scanned_klass(NULL);
}
_count++;
}
我们通过不断深入oops_do()方法,最后可以找到其最终调用的g1CollectedHeap.cpp中的G1ParCopyClosure下的do_oop_work来把活跃对象复制到新分区:
// 真正的迭代方法
template <G1Barrier barrier, G1Mark do_mark_object>
template <class T>
void G1ParCopyClosure<barrier, do_mark_object>::do_oop_work(T* p) {
// 根据指针获取对象值,这里的对象是GCRoot引用的对象
T heap_oop = oopDesc::load_heap_oop(p);
// 简单判空
if (oopDesc::is_null(heap_oop)) {
return;
}
// 获取对象
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
assert(_worker_id == _par_scan_state->queue_num(), "sanity");
// 判断对象是否在CSet中
const InCSetState state = _g1->in_cset_state(obj);
if (state.is_in_cset()) {
oop forwardee;
markOop m = obj->mark();
// 根据对象的对象头中的标记信息判断对象是否已经完成复制
if (m->is_marked()) {
// 完成复制,直接获取到新的对象
forwardee = (oop) m->decode_pointer();
} else {
// 复制还没有被进行,就开始复制对象,返回新对象的引用
// 这个方法会判断对象的年龄,根据年龄去survivor区或者old区申请内存并复制对象
forwardee = _par_scan_state->copy_to_survivor_space(state, obj, m);
}
assert(forwardee != NULL, "forwardee should not be NULL");
// 修改引用 p->fowardee
oopDesc::encode_store_heap_oop(p, forwardee);
if (do_mark_object != G1MarkNone && forwardee != obj) {
// If the object is self-forwarded we don't need to explicitly
// mark it, the evacuation failure protocol will do so.
// 如果复制对象成功,就把新对象的地址设置到老对象的对象头
mark_forwarded_object(obj, forwardee);
}
if (barrier == G1BarrierKlass) {
do_klass_barrier(p, forwardee);
}
} else {
// 对于不在CSet中的对象,先把对象标记为活的,在并发标记的时候作为根对象
if (state.is_humongous()) {
_g1->set_humongous_is_live(obj);
}
// The object is not in collection set. If we're a root scanning
// closure during an initial mark pause then attempt to mark the object.
if (do_mark_object == G1MarkFromRoot) {
mark_object(obj);
}
}
if (barrier == G1BarrierEvac) {
// 如果是Evac失败的情况,则需要将对象记录到一个特殊的队列中,在最后Redirty时需要
// 重构RSet
_par_scan_state->update_rs(_from, p, _worker_id);
}
}
这里用到了对象头的标记信息,当发现对象需要被复制,先复制对象到新的位置,复制之后把老对象(对象老位置的引用)的对象头标记为11(其实就是判断markword中相应位置的两位是不是11,在代码中可以看到最后的比较值marked_value是3),然后把对象头里面的指针指向新的对象(对象新位置的引用)。这样当一个对象被多个对象引用时,只有第一次遍历对象的时候才需要进行复制操作,后续都不需要进行复制操作,直接通过这个指针就能找到新的对象,后面的复制引用直接修改自己的指针指向新的对象就完成了遍历。这里为了方便理解,稍作讲解:
Java对象的对象头由 Mark Word (8byte)和 class pointer(4byte) 两部分组成。
- class pointer 是存储对象的类型指针,该指针指向它的类元数据
- Mark Word 是对象自身的运行时数据
Mark Word存储 hashcode、GC 分代年龄、锁类型标记、偏向锁线程 ID、CAS 锁指向线程 LockRecord 的指针等,synchronized 锁的机制与这个部分(markwork)密切相关,用 markword 中最低的三位代表锁的状态,其中一位是偏向锁标记,另外两位是锁状态标记:

我们这里就是使用到了"11" - GC标记。
继续深入copy_to_survivor_space,查看复制对象的具体逻辑:
// 将Java根中指向的活跃对象根据条件复制至Survivor区或老年代分区
oop G1ParScanThreadState::copy_to_survivor_space(InCSetState const state,
oop const old,
markOop const old_mark) {
const size_t word_sz = old->size();
HeapRegion* const from_region = _g1h->heap_region_containing_raw(old);
// +1 to make the -1 indexes valid...
const int young_index = from_region->young_index_in_cset()+1;
assert( (from_region->is_young() && young_index > 0) ||
(!from_region->is_young() && young_index == 0), "invariant" );
const AllocationContext_t context = from_region->allocation_context();
uint age = 0;
// 判断对象是要到Survivor还是到Old区,判断的依据是根据对象age。当发现对象超过晋升的阈值或者Survivor不能存放的时候
// 会把对象晋升到老年代分区
InCSetState dest_state = next_state(state, old_mark, age);
// 在PLAB(晋升本地缓冲区)中尝试分配空间
HeapWord* obj_ptr = _g1_par_allocator->plab_allocate(dest_state, word_sz, context);
// PLAB allocations should succeed most of the time, so we'll
// normally check against NULL once and that's it.
if (obj_ptr == NULL) {
// 分配空间失败,尝试重新分配一个新的PLAB或者直接在堆中分配对象
obj_ptr = _g1_par_allocator->allocate_direct_or_new_plab(dest_state, word_sz, context);
if (obj_ptr == NULL) {
// 仍然失败,如果是在新生代分区中(也就是Survivor区),就再次尝试在老年代分区中分配
// 如果是在老年代分区中,则直接报错
obj_ptr = allocate_in_next_plab(state, &dest_state, word_sz, context);
if (obj_ptr == NULL) {
// This will either forward-to-self, or detect that someone else has
// installed a forwarding pointer.
// 还是失败,说明无法复制对象,会将对象头设置为自己
return _g1h->handle_evacuation_failure_par(this, old);
}
}
if (_g1h->_gc_tracer_stw->should_report_promotion_events()) {
// The events are checked individually as part of the actual commit
report_promotion_event(dest_state, old, word_sz, age, obj_ptr, context);
}
}
assert(obj_ptr != NULL, "when we get here, allocation should have succeeded");
#ifndef PRODUCT
// Should this evacuation fail?
if (_g1h->evacuation_should_fail()) {
// Doing this after all the allocation attempts also tests the
// undo_allocation() method too.
_g1_par_allocator->undo_allocation(dest_state, obj_ptr, word_sz, context);
return _g1h->handle_evacuation_failure_par(this, old);
}
#endif // !PRODUCT
// We're going to allocate linearly, so might as well prefetch ahead.
Prefetch::write(obj_ptr, PrefetchCopyIntervalInBytes);
const oop obj = oop(obj_ptr);
const oop forward_ptr = old->forward_to_atomic(obj, memory_order_relaxed);
if (forward_ptr == NULL) {
// 对象头里面没有指针,说明是第一次复制。这里的复制是内存的完全复制,复制之后引用关系不变
Copy::aligned_disjoint_words((HeapWord*) old, obj_ptr, word_sz);
// 更新age信息和对象头
if (dest_state.is_young()) {
if (age < markOopDesc::max_age) {
age++;
}
if (old_mark->has_displaced_mark_helper()) {
// In this case, we have to install the mark word first,
// otherwise obj looks to be forwarded (the old mark word,
// which contains the forward pointer, was copied)
// 对于重量级锁,前面的ptr指向的是Monitor对象,其中ObjectMonitor的第一个字段是oopDes,
// 所以要先设置old mark再获得Monitor,最后再更新age
obj->set_mark(old_mark);
markOop new_mark = old_mark->displaced_mark_helper()->set_age(age);
old_mark->set_displaced_mark_helper(new_mark);
} else {
obj->set_mark(old_mark->set_age(age));
}
age_table()->add(age, word_sz);
} else {
obj->set_mark(old_mark);
}
// 将字符串对象送去字符串去重队列,由去重线程处理
if (G1StringDedup::is_enabled()) {
const bool is_from_young = state.is_young();
const bool is_to_young = dest_state.is_young();
assert(is_from_young == _g1h->heap_region_containing_raw(old)->is_young(),
"sanity");
assert(is_to_young == _g1h->heap_region_containing_raw(obj)->is_young(),
"sanity");
G1StringDedup::enqueue_from_evacuation(is_from_young,
is_to_young,
queue_num(),
obj);
}
size_t* const surv_young_words = surviving_young_words();
surv_young_words[young_index] += word_sz;
// 如果对象是一个对象类型的数组,就是说数组里面的元素都是一个对象而不是原始值,
// 并且它的长度超过阈值ParGCArrayScanChunk(默认值50),则可以先把它放入到队列
// 而不是放入到深度搜索的对象栈中。目的是为了防止在遍历对象数组里面的每一个元素时
// 因为数组太长而导致处理队列溢出。所以在这里只是把原始对象放入,后续还会继续处理
if (obj->is_objArray() && arrayOop(obj)->length() >= ParGCArrayScanChunk) {
// We keep track of the next start index in the length field of
// the to-space object. The actual length can be found in the
// length field of the from-space object.
arrayOop(obj)->set_length(0);
oop* old_p = set_partial_array_mask(old);
push_on_queue(old_p);
} else {
HeapRegion* const to_region = _g1h->heap_region_containing_raw(obj_ptr);
_scanner.set_region(to_region);
// 把obj的每一个Field对象都通过scanner
obj->oop_iterate_backwards(&_scanner);
// oop_iterate_backwards实际上是一个宏,定义在oopDesc::oop_iterate_backwards
// 在这里最终会调用到klass()->oop_oop_iterate_backwards##nv_suffix(this,blk)
}
return obj;
} else {
_g1_par_allocator->undo_allocation(dest_state, obj_ptr, word_sz, context);
return forward_ptr;
}
}
其中提及到了PLAB,这部分和之前提及的TLAB类似,先计算是否需要分配一个新的PLAB,同样这块也是由参数控制。对于新生代分区,PLAB的大小为16KB(32位JVM),由YoungPLABSize控制。对于老年代PLAB的大小为4KB(32位JVM)由OldPLABSize控制。还有一个参数,由ParallelGCBufferWastePct控制,表示PLAB浪费的比例,当PLAB剩余空间小于PLABSize * 10%,即1634或者409个字节(根据目标是在Survivor还是在老年代分区),可
以分配一个新的PLAB,否则直接在堆中分配。同样的道理如果压迫分配一个新的PLAB的时候,需要把PLAB里面的碎片部分填充哑元dummy对象。
最后我们再看一下如何处理每个对象中的每一个field的。将所有的field都放入到待处理的队列中。触发的位置在obj->oop_iterate_backwards(&_scanner),真正的工作在G1ParScanClosure中:
template <class T>
inline void G1ParScanClosure::do_oop_nv(T* p) {
T heap_oop = oopDesc::load_heap_oop(p);
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
const InCSetState state = _g1->in_cset_state(obj);
if (state.is_in_cset()) {
Prefetch::write(obj->mark_addr(), 0);
Prefetch::read(obj->mark_addr(), (HeapWordSize*2));
assert((obj == oopDesc::load_decode_heap_oop(p)) ||
(obj->is_forwarded() &&
obj->forwardee() == oopDesc::load_decode_heap_oop(p)),
"p should still be pointing to obj or to its forwardee");
// 如果field需要回收,也就是在CSet中,就放入队列,准备后续复制
_par_scan_state->push_on_queue(p);
} else {
if (state.is_humongous()) {
_g1->set_humongous_is_live(obj);
}
// 如果不需要,仅仅只需要在后面重构RSet,保持引用关系即可
_par_scan_state->update_rs(_from, p, _worker_id);
}
}
}
线程栈处理
从process_java_roots()方法中的possibly_parallel_oops_do()方法进入:
// 对于线程栈的处理
void Threads::possibly_parallel_oops_do(OopClosure* f, CLDClosure* cld_f, CodeBlobClosure* cf) {
// ...
// 遍历所有的java线程
ALL_JAVA_THREADS(p) {
if (p->claim_oops_do(is_par, cp)) {
p->oops_do(f, cld_f, cf);
}
}
// 遍历所有的VM线程
VMThread* vmt = VMThread::vm_thread();
if (vmt->claim_oops_do(is_par, cp)) {
vmt->oops_do(f, cld_f, cf);
}
}
可以看到都是通过调用方法oops_do()对所有的java线程和vm线程进行遍历。以对Java线程的操作为例:
// 遍历Java线程
void JavaThread::oops_do(OopClosure* f, CLDClosure* cld_f, CodeBlobClosure* cf) {
// Verify that the deferred card marks have been flushed.
assert(deferred_card_mark().is_empty(), "Should be empty during GC");
// The ThreadProfiler oops_do is done from FlatProfiler::oops_do
// since there may be more than one thread using each ThreadProfiler.
// Traverse the GCHandles
Thread::oops_do(f, cld_f, cf);
assert( (!has_last_Java_frame() && java_call_counter() == 0) ||
(has_last_Java_frame() && java_call_counter() > 0), "wrong java_sp info!");
if (has_last_Java_frame()) {
// Record JavaThread to GC thread
RememberProcessedThread rpt(this);
// Traverse the privileged stack
// privileged_stack用于实现Java安全功能的类
if (_privileged_stack_top != NULL) {
_privileged_stack_top->oops_do(f);
}
// traverse the registered growable array
if (_array_for_gc != NULL) {
for (int index = 0; index < _array_for_gc->length(); index++) {
f->do_oop(_array_for_gc->adr_at(index));
}
}
// Traverse the monitor chunks
// 遍历monitor块
for (MonitorChunk* chunk = monitor_chunks(); chunk != NULL; chunk = chunk->next()) {
chunk->oops_do(f);
}
// Traverse the execution stack
// 遍历栈,处理栈帧
for(StackFrameStream fst(this); !fst.is_done(); fst.next()) {
fst.current()->oops_do(f, cld_f, cf, fst.register_map());
}
}
if (EnableCoroutine) {
Coroutine* current = _coroutine_list;
do {
current->oops_do(f, cld_f, cf);
if (UseWispMonitor) {
current->wisp_thread()->oops_do(f, cld_f, cf);
}
current = current->next();
} while (current != _coroutine_list);
}
// callee_target is never live across a gc point so NULL it here should
// it still contain a methdOop.
set_callee_target(NULL);
assert(vframe_array_head() == NULL, "deopt in progress at a safepoint!");
// If we have deferred set_locals there might be oops waiting to be
// written
// 遍历jvmti
GrowableArray<jvmtiDeferredLocalVariableSet*>* list = deferred_locals();
if (list != NULL) {
for (int i = 0; i < list->length(); i++) {
list->at(i)->oops_do(f);
}
}
// Traverse instance variables at the end since the GC may be moving things
// around using this function
// 遍历这些实例对象,这些对象可能也引用了堆对象
f->do_oop((oop*) &_threadObj);
f->do_oop((oop*) &_tenantObj);
f->do_oop((oop*) &_vm_result);
f->do_oop((oop*) &_vm_result_for_wisp);
f->do_oop((oop*) &_exception_oop);
f->do_oop((oop*) &_pending_async_exception);
if (jvmti_thread_state() != NULL) {
jvmti_thread_state()->oops_do(f);
}
}
在这里我们只关注于如何对遍历的栈帧进行处理,继续深入最终会得到以下部分的源码:
void frame::oops_interpreted_arguments_do(Symbol* signature, bool has_receiver, OopClosure* f) {
InterpretedArgumentOopFinder finder(signature, has_receiver, this, f);
finder.oops_do();
}
// finder.oops_do();
// InterpretedArgumentOopFinder
void oop_offset_do() {
oop* addr;
addr = (oop*)_fr->interpreter_frame_tos_at(_offset);
_f->do_oop(addr);
}
其中_f为G1ParCopyClosure实例化的对象,它的真正工作在do_oop_work(也就是之前在对于类加载器处理一节中提到过的g1CollectedHeap.cpp中的do_oop_work这一方法),用于把对象复制到新的分区(Survivor或者老生代分区)。
JVM根处理
我们回到分开处理Java根和JVM根的步骤,去深入process_vm_roots方法:
void G1RootProcessor::process_vm_roots(OopClosure* strong_roots,
OopClosure* weak_roots,
G1GCPhaseTimes* phase_times,
uint worker_i) {
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::UniverseRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_Universe_oops_do)) {
Universe::oops_do(strong_roots);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::JNIRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_JNIHandles_oops_do)) {
JNIHandles::oops_do(strong_roots);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::ObjectSynchronizerRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_ObjectSynchronizer_oops_do)) {
ObjectSynchronizer::oops_do(strong_roots);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::FlatProfilerRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_FlatProfiler_oops_do)) {
FlatProfiler::oops_do(strong_roots);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::ManagementRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_Management_oops_do)) {
Management::oops_do(strong_roots);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::JVMTIRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_jvmti_oops_do)) {
JvmtiExport::oops_do(strong_roots);
}
}
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::SystemDictionaryRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_SystemDictionary_oops_do)) {
SystemDictionary::roots_oops_do(strong_roots, weak_roots);
}
}
if (TenantHeapIsolation) {
// process references from G1TenantAllocationContext
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::TenantAllocationContextRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_TenantAllocationContext_oops_do)) {
G1TenantAllocationContexts::oops_do(strong_roots);
}
}
}
其实也是调用的G1ParCopyHelper的do_oop()方法,只不过对JVM根而言则是各种全局对象。所以就不"细嗦"了。
RSet处理
有关于RSet的处理逻辑在scan_remembered_sets方法中,这个步骤本质其实是将dcq和rset中的存在跨代引用的card全部加入到pss(G1ParScanThreadState)中的queue中。其中方法会调用到G1RemSet::oops_into_collection_set_do,此方法具体逻辑为:
// 处理RSet
void G1RemSet::oops_into_collection_set_do(G1ParPushHeapRSClosure* oc,
CodeBlobClosure* code_root_cl,
uint worker_i) {
#if CARD_REPEAT_HISTO
ct_freq_update_histo_and_reset();
#endif
// We cache the value of 'oc' closure into the appropriate slot in the
// _cset_rs_update_cl for this worker
assert(worker_i < n_workers(), "sanity");
// 缓存闭包(更新rset的迭代方法)
_cset_rs_update_cl[worker_i] = oc;
// into_cset_dirty_card_queue_set 本质就是DCQS
// 但是这里的DCQ主要是用于记录复制失败后,要保留的引用
// 此队列数据将传递到用于管理RSet更新的DirtyCardQueueSet
DirtyCardQueue into_cset_dcq(&_g1->into_cset_dirty_card_queue_set());
assert((ParallelGCThreads > 0) || worker_i == 0, "invariant");
// 更新RSet
updateRS(&into_cset_dcq, worker_i);
// 扫描并处理RSet
scanRS(oc, code_root_cl, worker_i);
// We now clear the cached values of _cset_rs_update_cl for this worker
_cset_rs_update_cl[worker_i] = NULL;
}
简单来说:
- **更新RSet:**就是把引用关系存储到RSet对应的PRT中;
- **扫描RSet:**就是根据RSet中的存储信息扫描找到对应的引用者,也就是将RSet作为根去扫描。因为之前我们提到RSet使用了三种不同粒度的动态存储类型,所以RSet中指向的其实是引用者的内存块,这些内存块的大小随着RSet中粒度的不同而改变,有可能是512字节也有可能是一整个分区的大小。然后会根据这些内存块找到引用的对象;
更新RSet
我们先来看updateRS更新RSet的相关逻辑:
// 更新RSet, 第三个参数为0,表示处理所有的DCQ
void G1RemSet::updateRS(DirtyCardQueue* into_cset_dcq, uint worker_i) {
G1GCParPhaseTimesTracker x(_g1p->phase_times(), G1GCPhaseTimes::UpdateRS, worker_i);
// Apply the given closure to all remaining log entries.
// 处理card的闭包,之后会碰到
RefineRecordRefsIntoCSCardTableEntryClosure into_cset_update_rs_cl(_g1, into_cset_dcq);
// 进行迭代处理
_g1->iterate_dirty_card_closure(&into_cset_update_rs_cl, into_cset_dcq, false, worker_i);
}
继续深入iterate_dirty_card_closure方法:
void G1CollectedHeap::iterate_dirty_card_closure(CardTableEntryClosure* cl,
DirtyCardQueue* into_cset_dcq,
bool concurrent,
uint worker_i) {
// Clean cards in the hot card cache
// 处理热表,如果失败则将卡入列到刚刚创建的dcq中
G1HotCardCache* hot_card_cache = _cg1r->hot_card_cache();
hot_card_cache->drain(worker_i, g1_rem_set(), into_cset_dcq);
// 处理DCQS中剩下的DCQ
DirtyCardQueueSet& dcqs = JavaThread::dirty_card_queue_set();
size_t n_completed_buffers = 0;
// 处理dcqs中满的队列,在我们准备阶段已经把不满的队列标记为满的队列,所以这里相当于处理所有dcq
// 调用关键方法apply_closure_to_completed_buffer
while (dcqs.apply_closure_to_completed_buffer(cl, worker_i, 0, true)) {
n_completed_buffers++;
}
g1_policy()->phase_times()->record_thread_work_item(G1GCPhaseTimes::UpdateRS, worker_i, n_completed_buffers);
// 重置n_completed_buffers为0
dcqs.clear_n_completed_buffers();
assert(!dcqs.completed_buffers_exist_dirty(), "Completed buffers exist!");
}
在while循环中调用了我们之前的解析过的DirtyCardQueueSet::apply_closure_to_completed_buffer方法,忘记了具体逻辑的同学可以爬爬楼。其实就是循环调用了之前提到的Refine线程去更新RSet时的方法,最终会调用到do_card_ptr这个闭包方法,因为我们这边传入的是RefineRecordRefsIntoCSCardTableEntryClosure,所以会执行以下逻辑:
bool do_card_ptr(jbyte* card_ptr, uint worker_i) {
// The only time we care about recording cards that
// contain references that point into the collection set
// is during RSet updating within an evacuation pause.
// In this case worker_i should be the id of a GC worker thread.
assert(SafepointSynchronize::is_at_safepoint(), "not during an evacuation pause");
assert(worker_i < (ParallelGCThreads == 0 ? 1 : ParallelGCThreads), "should be a GC worker");
// 这个是更新rset的方法,注意这里第三个参数是true
// 这里会检查引用是不是跨代且引用的对象是否在回收集合中,如果引用是old->young且引用的对象也在回收集合中
// 则会用G1ParPushHeapRSClosure(之前提到过的pss)进行遍历
// G1ParPushHeapRSClosure其内部其实是一个queue先将card保存起来,之后统一处理
if (_g1rs->refine_card(card_ptr, worker_i, true)) {
// 'card_ptr' contains references that point into the collection
// set. We need to record the card in the DCQS
// (G1CollectedHeap::into_cset_dirty_card_queue_set())
// that's used for that purpose.
//
// Enqueue the card
// 如果card中的引用引用的是回收集合的对象则会加入回收集合dcq中
_into_cset_dcq->enqueue(card_ptr);
}
return true;
}
其中的refine_card逻辑也在之前已经描述过,这里就不赘述了。其实更新RSet最终也是通过和Refine线程一样的更新方法来进行更新的,区别就是处理的DCQ对象不同。所有的DCQ队列中的脏卡的引用是跨代且引用的对象在回收集合中,那么就会将卡页加入到 G1ParPushHeapRSClosure 中的queue中。
扫描RSet
扫描RSet会处理CSet中所有待回收的分区。先找到RSet中的老生代分区对象,这些对象指向CSet中的对象。然后对这些老生代对象处理,把老生代对象field指向的对象的地址放入队列中待后续处理。具体逻辑如下:
// 扫描RSet逻辑
void G1RemSet::scanRS(G1ParPushHeapRSClosure* oc,
CodeBlobClosure* code_root_cl,
uint worker_i) {
double rs_time_start = os::elapsedTime();
// 获取cset开始的region
// 从这里看出,每个GC的线程都只会针对部分的分区进行处理,所以它们可以并行运行
HeapRegion *startRegion = _g1->start_cset_region_for_worker(worker_i);
// 创建扫描rset的闭包
ScanRSClosure scanRScl(oc, code_root_cl, worker_i);
// 遍历回收集合,这里是用上面创建的闭包进行扫描所有cset中的region
// 第一次扫描,处理一般对象
_g1->collection_set_iterate_from(startRegion, &scanRScl);
// 第二次扫描,处理代码对象
scanRScl.set_try_claimed();
_g1->collection_set_iterate_from(startRegion, &scanRScl);
double scan_rs_time_sec = (os::elapsedTime() - rs_time_start)
- scanRScl.strong_code_root_scan_time_sec();
assert(_cards_scanned != NULL, "invariant");
_cards_scanned[worker_i] = scanRScl.cards_done();
_g1p->phase_times()->record_time_secs(G1GCPhaseTimes::ScanRS, worker_i, scan_rs_time_sec);
_g1p->phase_times()->record_time_secs(G1GCPhaseTimes::CodeRoots, worker_i, scanRScl.strong_code_root_scan_time_sec());
}
scanRScl是一个闭包方法,传入的是ScanRSClusure。我们先来看第一次扫描:
void G1CollectedHeap::collection_set_iterate_from(HeapRegion* r,
HeapRegionClosure *cl) {
if (r == NULL) {
// The CSet is empty so there's nothing to do.
return;
}
assert(r->in_collection_set(),
"Start region must be a member of the collection set.");
// 处理本线程的第一个分区
HeapRegion* cur = r;
while (cur != NULL) {
HeapRegion* next = cur->next_in_collection_set();
// 使用传入闭包中的 doHeapRegion 方法来处理每一个分区
// 最主要的功能就是找到引用者分区并扫描分区
if (cl->doHeapRegion(cur) && false) {
cl->incomplete();
return;
}
cur = next;
}
// 如果本线程已经处理完属于自己处理的发呢去,就窃取其他线程处理的分区
cur = g1_policy()->collection_set();
while (cur != r) {
HeapRegion* next = cur->next_in_collection_set();
// 使用传入闭包中的 doHeapRegion 方法来处理每一个分区
if (cl->doHeapRegion(cur) && false) {
cl->incomplete();
return;
}
cur = next;
}
}
由于传入的闭包是ScanRSClusure,所以我们去查看对应的doHeapRegion方法:
// 最主要的功能就是找到引用者分区并扫描分区
bool doHeapRegion(HeapRegion* r) {
assert(r->in_collection_set(), "should only be called on elements of CS.");
// 获取当前遍历的region的rset
HeapRegionRemSet* hrrs = r->rem_set();
if (hrrs->iter_is_complete()) return false; // All done.
if (!_try_claimed && !hrrs->claim_iter()) return false;
// 这里会把当前遍历的回收集合中的region加入脏卡region集合
// 脏卡region集合仅用于GC之后清理卡表(Rset)
// 因为被回收所以其Rset也需要清理
_g1h->push_dirty_cards_region(r);
// 创建RSet的迭代器
HeapRegionRemSetIterator iter(hrrs);
size_t card_index;
// 这里_block_size由参数G1RSetScanBlockSize控制,默认值为64
// 这个值表示一次扫描多少个分区块,这个值是为了提高效率,越大说明扫描的吞吐量越大
// 例如RSet是细粒度PRT存储,则一次处理64个元素
size_t jump_to_card = hrrs->iter_claimed_next(_block_size);
// 这里会对RSet集合中的card进行遍历
for (size_t current_card = 0; iter.has_next(card_index); current_card++) {
if (current_card >= jump_to_card + _block_size) {
jump_to_card = hrrs->iter_claimed_next(_block_size);
}
if (current_card < jump_to_card) continue;
HeapWord* card_start = _g1h->bot_shared()->address_for_index(card_index);
#if 0
gclog_or_tty->print("Rem set iteration yielded card [" PTR_FORMAT ", " PTR_FORMAT ").\n",
card_start, card_start + CardTableModRefBS::card_size_in_words);
#endif
// 获取card所属的region,即引用所在region
HeapRegion* card_region = _g1h->heap_region_containing(card_start);
_cards++;
// 这里会把引用所在region也加入脏卡集合
if (!card_region->is_on_dirty_cards_region_list()) {
_g1h->push_dirty_cards_region(card_region);
}
// 引用所在的分区不在CSet且非脏的card,会扫描card中映射的对象
// Rset中的card本质都是脏card只不过进入Rset之后脏标记会被清除
// 所以这里对非脏进行扫描,即这些card映射的对象引用的对象都是存活的,需要被迁移
if (!card_region->in_collection_set() &&
!_ct_bs->is_card_dirty(card_index)) {
scanCard(card_index, card_region);
}
}
if (!_try_claimed) {
// Scan the strong code root list attached to the current region
// 处理编译的代码
scan_strong_code_roots(r);
hrrs->set_iter_complete();
}
return false;
}
引用者分区处理的思路,是找到卡表所在的区域,因为RSet中存储的是对象起始地址所对应的卡表地址,所以肯定可以找到对象。但是这个卡表对应512个字节的区域,而区域可能有多个对象,这个时候就会可能产生浮动垃圾。对引用者所在分区且不在CSet中的分区的处理在scanCard中:
void scanCard(size_t index, HeapRegion *r) {
// Stack allocate the DirtyCardToOopClosure instance
HeapRegionDCTOC cl(_g1h, r, _oc,
CardTableModRefBS::Precise);
// Set the "from" region in the closure.
_oc->set_region(r);
MemRegion card_region(_bot_shared->address_for_index(index), G1BlockOffsetSharedArray::N_words);
MemRegion pre_gc_allocated(r->bottom(), r->scan_top());
MemRegion mr = pre_gc_allocated.intersection(card_region);
if (!mr.is_empty() && !_ct_bs->is_card_claimed(index)) {
// We make the card as "claimed" lazily (so races are possible
// but they're benign), which reduces the number of duplicate
// scans (the rsets of the regions in the cset can intersect).
_ct_bs->set_card_claimed(index);
_cards_done++;
// 逻辑操作
cl.do_MemRegion(mr);
}
}
通过注解可以得知,这里的do_MemeRegion是通过HeapRegionDCTOC调用它的父类DirtyCardToOopClosure中的do_MemeRegion方法:
void DirtyCardToOopClosure::do_MemRegion(MemRegion mr) {
// ...
// 关键点:如果region不是空的,就执行HeapRegionDCTOC::walk_mem_region
if (!extended_mr.is_empty()) {
walk_mem_region(extended_mr, bottom_obj, top);
}
// ...
}
在这个方法中通过一些赋值和校验获取对应范围的MemRegion,通过判断分区中的使用记录的值是否为0来判断这个分区的是否为空,如果为空就跳过什么都不做,如果不是空的那么就会执行HeapRegionDCTOC中的walk_mem_region逻辑:
// 执行分区内存扫描
void HeapRegionDCTOC::walk_mem_region(MemRegion mr,
HeapWord* bottom,
HeapWord* top) {
G1CollectedHeap* g1h = _g1;
size_t oop_size;
HeapWord* cur = bottom;
// 从内存块所在的分区的头部也就是第一个字节开始处理,这里的bottom已经指向内存分区中的第一个对象的地址,
// top是最后一个对象的地址
// 从这个循环中也可以看出,这里主要是为了遍历512字节里面的所有对象
if (!g1h->is_obj_dead(oop(cur), _hr)) {
oop_size = oop(cur)->oop_iterate(_rs_scan, mr);
} else {
oop_size = _hr->block_size(cur);
}
cur += oop_size;
if (cur < top) {
oop cur_oop = oop(cur);
oop_size = _hr->block_size(cur);
HeapWord* next_obj = cur + oop_size;
while (next_obj < top) {
// 过滤分区中的存活对象
if (!g1h->is_obj_dead(cur_oop, _hr)) {
// 对存活对象执行处理逻辑
cur_oop->oop_iterate(_rs_scan);
}
cur = next_obj;
cur_oop = oop(cur);
oop_size = _hr->block_size(cur); // 这个方法里判断了如果不是对象的相关处理
// 这里就是为什么TLAB,PLAB填充dummy哑元对象的原因,也是需要heap parsable的原因
// 是对象就直接跳过对象大小的位置
next_obj = cur + oop_size;
}
// 最后一个对象,注意这个对象的起始地址在这个内存块中,结束位置有可能跨内存块
// 所以需要对最后一个对象进行特殊处理
if (!g1h->is_obj_dead(oop(cur), _hr)) {
oop(cur)->oop_iterate(_rs_scan, mr);
}
}
}
这里的oop_iterate将遍历这个引用者的每一个field,当发现field指向的对象(即被引用者)在CSet中就把对象放入G1ParScanThreadState中的队列里(pss),如果不在则跳过这个field。这里的_rs_scan是G1ParPushHeapRSClosure类指针,oop_iterate最终会调用到G1ParPushHeapRSClosure中的do_oop_nv:
template <class T>
inline void G1ParPushHeapRSClosure::do_oop_nv(T* p) {
T heap_oop = oopDesc::load_heap_oop(p);
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
if (_g1->is_in_cset_or_humongous(obj)) {
// 如果对象中的field指向的对象在CSet中
// 就将这个对象加入到pss队列中
Prefetch::write(obj->mark_addr(), 0);
Prefetch::read(obj->mark_addr(), (HeapWordSize*2));
// Place on the references queue
_par_scan_state->push_on_queue(p);
} else {
assert(!_g1->obj_in_cs(obj), "checking");
}
}
}
这里的_par_scan_state是G1ParScanThreadState类指针,所以会调用到G1ParScanThreadState中的入队方法进行入队流程:
template <class T> void push_on_queue(T* ref) {
assert(verify_ref(ref), "sanity");
// RefToScanQueue* _refs;
_refs->push(ref);
}
那么这里为什么是只对在CSet的对象进行操作呢?
is_in_cset_or_humongous此方法起始本质上是:
bool is_in_cset_or_humongous() const {
return _value != NotInCSet;
}
NotInCSet是一个枚举常量:
Humongous = -1, // The region is humongous - note that actually any value < 0 would be possible here.
NotInCSet = 0, // The region is not in the collection set.
Young = 1, // The region is in the collection set and a young region.
Old = 2, // The region is in the collection set and an old region.
可以通过注解得知NotInCSet的值是0,代表这个分区不在CSet中,所以这里做的判断是这个对象所在的分区不在CSet中。
这里做这层校验的原因是field引用的对象不在CSet就说明它不会被回收,所以也就不涉及位置变化。另外要注意这里放入队列中的对象和Java根处理有点不同,Java根处理的时候对根的直接引用对象会复制到新的分区,但是这里仅仅是把指向field对象的地址放入队列中。
每个分区里面的引用关系通过RSet的形式来存储。其中RSet里面的每一个PRT存储的就是对应卡表的位置也就是卡表指针。由于卡表是按照512字节对齐,所以如果被同一个卡表中的不同对象引用,那么这些引用对象在被引用对象的分区的RSet中共用一个卡表指针。那么如果同一个卡表中的多个对象中的某一个对象引用了新生代的对象的时候,那么根据被引用对象所在分区的RSet之能找到这个卡表的地址,但是不知道引用对象是这个卡表中的具体哪个对象。所以要准确的找出引用对象,一般来说有这两种方法:
- 从整个分区的头部开始扫描,然后针对每一个对象将地址对齐到卡表,跳过所有不在这个卡表的对象。因为可能有不只一个对象的地址会对齐到同一个卡表,所以这里可能会出现浮动垃圾的情况。
- 借助额外的数据结构来标记对象所在块的起始位置。
在G1中,选择了第二种处理方式,借助了G1BlockOffsetTable数据结构来进行记录。G1BlockOffsetTable内部也是用类似位图来存储第一个对象距离卡表起始位置的偏移量,在内部使用的字符数组来存储。当一个对象非常大的时候,超过了一个卡表的空间,为了让后续的卡表能够快速地找到对象所在的第一个卡表的位置,所以设计了复杂的滑动窗口机制,这里就不进行相关介绍了。感兴趣的同学可以自行了解。
相关的操作就是,先根据卡表指针找到其对应分区位置的相关对象,根据G1BlockOffsetTable中记录的数值找到这个卡表中第一个对象的起始位置开始,在范围中,遍历这些对象。并且判断这些对象所有的field是否都有到CSet的引用,如果有,说明该field是一个有效地引用,把该field放入到待处理队列(pss)用于后续的遍历和复制。
复制处理
当GC流程执行到这里,我们已经把DCQ中的脏card和RSet中脏但实际没有脏标记的card都加入到了pss(G1ParScanThreadState)的队列中。我们从复制Evac处理开始看起,这个处理实际上就是将在Java根和RSet根找到的子对象全部复制到新的分区中,具体逻辑为:
// Evac复制
void G1ParEvacuateFollowersClosure::do_void() {
//获取pss
G1ParScanThreadState* const pss = par_scan_state();
// 对pss队列中的每个对象进行处理
pss->trim_queue();
// 处理完后,可以尝试去窃取其他没有完成线程的没有处理的对象
do {
pss->steal_and_trim_queue(queues());
} while (!offer_termination());
}
在Evac因为涉及对象复制,这将是非常耗时的。所以在这个阶段还提供任务窃取的功能。在并发执行的过程中,GC线程优先处理本地的队列。当本地的队列没有任务的时候,窃取别的队列的任务,帮助别的队列。这里的trim_queue会调用到G1ParScanThreadState::trim_queue():
void G1ParScanThreadState::trim_queue() {
assert(_evac_failure_cl != NULL, "not set");
StarTask ref;
// 取出每一个对象进行处理
do {
// Drain the overflow stack first, so other threads can steal.
while (_refs->pop_overflow(ref)) {
if (!_refs->try_push_to_taskqueue(ref)) {
// 逻辑处理
dispatch_reference(ref);
}
}
while (_refs->pop_local(ref)) {
// 逻辑处理
dispatch_reference(ref);
}
} while (!_refs->is_empty());
}
可以看到其实都是调用了dispatch_reference这个方法来进行处理的,而dispatch_reference这个方法中又调用了deal_with_reference方法来真正进行相关处理:
inline void G1ParScanThreadState::dispatch_reference(StarTask ref) {
assert(verify_task(ref), "sanity");
if (ref.is_narrow()) {
deal_with_reference((narrowOop*)ref);
} else {
deal_with_reference((oop*)ref);
}
}
于是,我们进入deal_with_reference来查看具体的逻辑:
template <class T> inline void G1ParScanThreadState::deal_with_reference(T* ref_to_scan) {
if (!has_partial_array_mask(ref_to_scan)) {
// Note: we can use "raw" versions of "region_containing" because
// "obj_to_scan" is definitely in the heap, and is not in a
// humongous region.
// 对一般对象的处理
HeapRegion* r = _g1h->heap_region_containing_raw(ref_to_scan);
do_oop_evac(ref_to_scan, r);
} else {
// 如果待处理对象是对象数组,并且长度比较大,在之前的过程中会设置特殊的标志位,会在这里进行处理
do_oop_partial_array((oop*)ref_to_scan);
}
}
如果待处理对象是对象数组的话,会在之前提到的流程中打上特殊的标志,可以爬下楼回顾一下。这里呢我们只需要关心一般对象的处理方法,相关逻辑在do_oop_evac方法中:
// 一般对象的处理
template <class T> void G1ParScanThreadState::do_oop_evac(T* p, HeapRegion* from) {
assert(!oopDesc::is_null(oopDesc::load_decode_heap_oop(p)),
"Reference should not be NULL here as such are never pushed to the task queue.");
// 这里的 p 其实是引用者中的field的地址
oop obj = oopDesc::load_decode_heap_oop_not_null(p);
const InCSetState in_cset_state = _g1h->in_cset_state(obj);
if (in_cset_state.is_in_cset()) {
oop forwardee;
markOop m = obj->mark();
if (m->is_marked()) {
// 如果对象已经标记,说明对象已经被复制
forwardee = (oop) m->decode_pointer();
} else {
// 如果对象没有标记,复制对象到新的分区
forwardee = copy_to_survivor_space(in_cset_state, obj, m);
}
// 更新引用者field所引用对象的地址
oopDesc::encode_store_heap_oop(p, forwardee);
} else if (in_cset_state.is_humongous()) {
_g1h->set_humongous_is_live(obj);
} else {
assert(!in_cset_state.is_in_cset_or_humongous(),
err_msg("In_cset_state must be NotInCSet here, but is " CSETSTATE_FORMAT, in_cset_state.value()));
}
assert(obj != NULL, "Must be");
// 最后维护一下新生成的对象的RSet
update_rs(from, p, queue_num());
}
阅读这部分逻辑的时候会觉得比较熟悉,因为在之前的流程中曾经调用过G1ParCopyClosure下的do_oop_work来把活跃对象复制到新分区。那部分的逻辑和这里的逻辑相类似,并且关键都是调用了copy_to_survivor_space这一方法来进行实现拷贝的。这部分逻辑已经在之前所描述过,这里就不再进行赘述。
至此YGC的主要流程就已经结束了,如果一切顺利,在CSet中所有活跃的对象都将被复制到新的分区中,并且在复制的过程中,引用关系也随之处理。如果发生了失败,处理流程也基本类似,但是对于失败的对象要进行额外的处理,感兴趣的同学可以自行了解。
GC首尾工作 - 其他处理
之后呢,会继续一些收尾工作,会处理一些Soft,Weak,Phantom,Final,JNI,Weak等引用。这些逻辑都在evacuate_collection_set的后半段中,此时YGC的停顿还没有解除,然后还会去释放清理重建CSet等,具体在do_collection_pause_at_safepoint的后半段中:
bool G1CollectedHeap::do_collection_pause_at_safepoint(double target_pause_time_ms) {
// 后面是gc的收尾工作
free_collection_set(g1_policy()->collection_set(), evacuation_info);
// 回收大对象分区,清空CSet
eagerly_reclaim_humongous_regions();
g1_policy()->clear_collection_set();
cleanup_surviving_young_words();
g1_policy()->start_incremental_cset_building();
clear_cset_fast_test();
// 重置Young List
_young_list->reset_sampled_info();
assert(check_young_list_empty(false /* check_heap */),
"young list should be empty");
g1_policy()->record_survivor_regions(_young_list->survivor_length(),
_young_list->first_survivor_region(),
_young_list->last_survivor_region());
_young_list->reset_auxilary_lists();
if (evacuation_failed()) {
_allocator->set_used(recalculate_used());
uint n_queues = MAX2((int)ParallelGCThreads, 1);
for (uint i = 0; i < n_queues; i++) {
if (_evacuation_failed_info_array[i].has_failed()) {
_gc_tracer_stw->report_evacuation_failed(_evacuation_failed_info_array[i]);
}
}
} else {
_allocator->increase_used(g1_policy()->bytes_copied_during_gc());
}
if (g1_policy()->during_initial_mark_pause()) {
concurrent_mark()->checkpointRootsInitialPost();
set_marking_started();
}
allocate_dummy_regions();
// 初始化Eden区申请分区
_allocator->init_mutator_alloc_region();
// 尝试去计算要扩展的内存的大小,返回则去进行扩展
{
// 扩容策略
size_t expand_bytes = g1_policy()->expansion_amount();
if (expand_bytes > 0) {
size_t bytes_before = capacity();
if (!expand(expand_bytes)) {
}
}
}
}
这里主要是对YGC中用到一些集合进行重置,计算扩容策略,记录统计和日志信息等等,具体就不进行展开。
其他处理通常是串行处理,大多是因为处理过程需要同步等待,需要独占访问临界区。其他处理大部分工作是在并行工作之后完成开始的,除了几个特别的任务如Redirty,字符串去重和引用外都是串行处理。实际上GC一直致力于提高运行的效率,所以未来不排除把一些串行化处理并行化的可能性。
至此,YGC的主要流程结束。