前言
Java进阶部分内容总结归纳,包含Stream流,线程,反射,动态代理,对象克隆等
一、Stream流
1. 简介
在Java中,Stream 是一个从数据源获取数据元素的序列。它并不是一种新的数据结构,而是对已有集合(如 List, Set 等)或者数组进行操作的一种方式。使用 Stream API 可以让我们用一种声明式的方式来处理数据,即我们告诉程序“我们想要做什么”,而不是“怎么做”。Stream API 支持函数式编程风格的操作。
Stream 的特性:
- 懒执行:Stream 操作不会立即执行,只有当调用了终止操作(如 collect(), forEach(), reduce(), toArray() 等)时才会触发管道中的所有中间操作。
- 管道式:中间操作可以链接起来形成流水线,使得多个操作可以串联在一起。
- 非破坏性:Stream 操作不会改变原始数据源,而是返回一个新的结果。
Stream 的创建:
- 通过 Collection 的 stream() 或者 parallelStream() 方法来创建 Stream。
- 使用 Arrays.stream(T[] array) 方法将数组转换为 Stream。
- 使用 Stream.of(T… values) 创建 Stream。
- 使用 Stream.iterate() 或 Stream.generate() 创建无限 Stream。
Stream 的操作类型:
- 中间操作:这些操作接受一个或多个 Stream 并返回一个新的 Stream。常见的中间操作包括 filter(), map(), flatMap(), distinct(), sorted() 等。
- 终端操作:这些操作对 Stream 进行终结操作,并且没有返回值或返回最终结果。常见的终端操作有 forEach(), reduce(), collect(), count() 等。
2. Stream常用方法总览
package day09;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Set;
import java.util.function.Predicate;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class Test04 {
public static void main(String[] args) {
/*
Stream流:简化单例集合(Collection)或数组的操作没有构造方法
获取方式:
1.集合------>Stream
Collection提供的了 stream() 方法将集合转换为Stream流
public Stream<T> stream()
集合对象.stream()
2.数组------>Stream
Stream类提供了静态方法of用于 接收引用类型可变参数
Stream.of(T...arr) 参数为可变参,可以接收集合或任意个数的数据,但是由于被泛型修饰,所以只能接收引用数据
所以传入基本数据类型的数组时,只能接搜数组本身无法接收数组中元素
Arrays类中提供了静态方法stream用于接收任意类型数组
Arrays.stream(任意类型数组)
这里转成了对应XxxStream如果想调用Stream的方法需要调用boxed
方法转成Stream
注意:Stream流只能操作一次,每次需要使用流时都需要重新获取,猜测每次获取到流操作一次后,流都会自动关闭,所以无法用变量引用的方式
多次使用,推荐链式编程
*/
List<String> list = new ArrayList<>();
list.add("常胜将军赵子龙");
list.add("武圣关二爷");
list.add("张翼德");
list.add("玄德君");
//集合转--->Stream()
Stream<String> stream = list.stream();
//引用类型可变参数--->Stream S
Integer[] integers = {1,2,3,4,5,6,7,8,9};
Stream.of(integers);
Stream.of(1,2,3,4,5,6,7,8,9);
//基本类型数组--->Stream
int[] arr = {1,2,3,4,5,6,7,8,9};
Stream.of(1,2,3,4,5,6,7,8,9);
Stream.of(arr);
/* 终结方法
特点:方法调用结束后返回的不是Stream流,无法在调用Stream流的方法
void forEach(Consumer<T> action) 遍历流 (参数为接口,遍历出每个元素都执行重写方法)
long count() 获取流的元素个数
Optionl<T> max(Comparator<T> c) 获取"最大值"(返回值>0则当前值大)
Optionl中提供了 T get() 来取出Optional对象中的值
*/
/*forEach*/
/*
内名内部类形式(未指定规则)
list.stream().forEach(new Consumer<String>() {
@Override
public void accept(String s) {
}
});*/
list.stream().forEach(s-> System.out.println(s));
System.out.println("---------------------------");
//count
System.out.println(list.stream().count());
System.out.println("---------------------------");
/*max方法和Optionl的get方法*/
/*
max方法匿名内部类形式(未指定规则)
list.stream().max(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return 0;
}
})*/
String s = list.stream().max((a, b) -> a.length() - b.length()).get();//链式编程
System.out.println(s);
System.out.println("---------------------------");
/* 中间方法
特点:方法调用结束后返回新的Stream流
Stream<T> filter(Predicate<T> p) 根据条件过滤流 (接口方法返回值为false时,跳过该元素 为true时拿到该元素放入新的Stream流中)
Stream<T> sorted() 按照元素内部的比较规则排序,要求元素实现Comprarble接口
Stream<T> sorted(Comparator<T> c) 按照比较器的比较规则排序,要求元素实现Comprarble接口(重新方法返回值为1放到右边)
Stream<T> limt(int i) 获取前i个元素
Stream<T> skip(int i) 跳过前i个元素
Stream<T> distinct() stream流去重,要求自定义元素重写hashCode和equals方法,否则无法去重
static Stream<T> concat(Stream<E1>s1,Stream<E2> s2) 合并流
Stream<T> map(Function<T,R> mapper) 修改流的元素或者将流的元素转化为另一种类型(R为执行方法后的元素
后的方法返回值类型,它会将方法返回的新数据重新放到新的流中)
Stream<T> distinct() 根据元素的equals进行去重
*/
/*sorted方法*/
/*
sorted方法内部类形式(未指定规则)
list.stream().sorted(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return 0;
}
})*/
list.stream().sorted(((o1, o2) -> o1.length()-o2.length())).forEach(z-> System.out.println(z));
System.out.println("---------------------------");
/*filter方法*/
/*
filter方法内部类形式(未指定规则)
list.stream().filter(new Predicate<String>() {
@Override
public boolean test(String s) {
return false;
}
})*/
list.stream().filter(k->k.length()>3).forEach(z-> System.out.println(z));
System.out.println("---------------------------");
//limit
list.stream().skip(2).forEach(z-> System.out.println(z));
System.out.println("---------------------------");
/*map --- 将方法apply的返回值装到新的流中*/
/*
map方法内部类形式
list.stream().map(new Function<String,Object>() {
@Override
public Object apply(String s) {
return s+"666";
}
})*/
list.stream().map(z->z+"666").forEach(z-> System.out.println(z));
System.out.println("-----------------");
/*
转换方法也叫收集方法
流更擅长过滤,但是没有新增功能
Stream流提了collect实例方法用于将流转为集合
collect(Collector collector)将流转为集合
参数
Collectors.toList()
Collectors.toSet()
Collectors.toMap()(了解)
注意事项:
流只能操作一次,不能多次操作,支持链式编程
*/
Set<String> collect = list.stream().filter(c -> c.length() >= 4).collect(Collectors.toSet());
//Stream流中同样有toList方法
for (String string : collect) {
System.out.println(string);
}
}
}
执行结果


3. 扩展
Collectors.toMap()
Collectors.toMap 是 Java 8 中引入的一个非常强大的工具方法,用于将流 (Stream) 中的元素收集到 Map 中。这个方法非常灵活,可以根据不同的需求定制不同的收集逻辑。下面我将详细介绍 Collectors.toMap 的用法及其参数。
- Collectors.toMap 的基本用法
- Collectors.toMap 的基本语法如下:
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier)
/*
● 参数:
○ keyMapper: 一个函数,用于将流中的每个元素映射为 Map 的键。
○ valueMapper: 一个函数,用于将流中的每个元素映射为 Map 的值。
○ mergeFunction: 一个二元操作函数,用于解决键冲突时的合并策略。
○ mapSupplier: 一个供应商函数,用于创建 Map 实例。
○ 前两个参数跟我们Stream.map方法中的参数是一致的,用于处理当前元素并返回一个新元素取代当前元素。
○ 以上接口均是函数式接口
*/
- 常见用法
- 最简单的用法
当你不需要处理键冲突的情况时,可以使用以下简化形式:
Collector<T, ?, Map<K, U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper)
//这里省略了 mergeFunction 和 mapSupplier 参数。默认情况下,如果遇到相同的键,后面出现的值会覆盖前面的值。
- 处理键冲突
当你需要自定义键冲突的处理策略时,可以使用以下形式:
Collector<T, ?, Map<K, U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction)
//这里的 mergeFunction 是一个二元操作函数,当流中有多个元素映射到同一个键时,该函数将决定如何合并这些值。
- 指定 Map 类型
如果你想使用特定类型的 Map(例如 LinkedHashMap 或 TreeMap),可以使用完整形式:
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier)
//这里的 mapSupplier 参数允许你指定创建 Map 的类型。
示例
/*
下面是一个具体的示例,演示如何使用 Collectors.toMap
将一个 List<Person> 收集到 Map 中,
键为 name,
值为 Person 对象本身。
*/
import java.util.*;
import java.util.function.Function;
import java.util.stream.Collectors;
public class ToMapExample {
public static void main(String[] args) {
List<Person> people = Arrays.asList(
new Person("Alice", 30),
new Person("Bob", 25),
new Person("Alice", 30), // 重复的名字
new Person("Charlie", 22)
);
// 使用最简单的形式
Map<String, Person> nameToPerson = people.stream()
.collect(Collectors.toMap(
Person::getName, // keyMapper
Function.identity() // valueMapper
));
// 输出结果
nameToPerson.forEach((name, person) -> System.out.println(name + ": " + person));
}
}
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
输出结果
Alice: Person{name='Alice', age=30}
Bob: Person{name='Bob', age=25}
Charlie: Person{name='Charlie', age=22}
处理键冲突
如果我们想要在遇到相同名字时保留年龄较大的人,可以使用 mergeFunction 参数来指定合并策略:
// 使用自定义合并策略
Map<String, Person> nameToPersonWithMerge = people.stream()
.collect(Collectors.toMap(
Person::getName, // keyMapper
Function.identity(), // valueMapper
(person1, person2) -> person1.getAge() >= person2.getAge() ? person1 : person2 // mergeFunction
));
// 输出结果
nameToPersonWithMerge.forEach((name, person) -> System.out.println(name + ": " + person));
指定 Map 类型
如果你想使用 LinkedHashMap 来保持插入顺序,可以指定 mapSupplier 参数:
// 使用 LinkedHashMap
Map<String, Person> nameToPersonLinked = people.stream()
.collect(Collectors.toMap(
Person::getName, // keyMapper
Function.identity(), // valueMapper
(person1, person2) -> person1.getAge() >= person2.getAge() ? person1 : person2, // mergeFunction
LinkedHashMap::new // mapSupplier
// () -> new LinkedHashMap<String, Person>()
));
// 输出结果
nameToPersonLinked.forEach((name, person) -> System.out.println(name + ": " + person));
Function.identity()
Function.identity() 是 Java 8 中 java.util.function.Function 接口提供的一种实用方法,用于返回一个恒等函数(identity function)。这种函数的作用是返回输入值本身,即 f(x) = x。这在许多情况下非常有用,特别是当你需要一个函数来作为参数传递给其他方法,但又不需要对输入值做任何转换时。
- Function.identity() 的用法
- Function.identity() 返回一个实现了 Function 接口的对象,该对象的 apply 方法只是简单地返回传入的参数。这对于一些方法(如 Collectors.toMap 中的 valueMapper 参数)非常有用,因为你不需要显式地定义一个 lambda 表达式来返回相同的值。
示例:下面是一个具体的例子,演示如何使用 Function.identity() 作为 valueMapper 参数:
import java.util.*;
import java.util.function.Function;
import java.util.stream.Collectors;
public class IdentityFunctionExample {
public static void main(String[] args) {
List<Person> people = Arrays.asList(
new Person("Alice", 30),
new Person("Bob", 25),
new Person("Alice", 30), // 重复的名字
new Person("Charlie", 22)
);
// 使用 Function.identity() 作为 valueMapper
Map<String, Person> nameToPerson = people.stream()
.collect(Collectors.toMap(
Person::getName, // keyMapper
Function.identity() // valueMapper
));
// 输出结果
nameToPerson.forEach((name, person) -> System.out.println(name + ": " + person));
}
}
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
- 在这个示例中,我们有一个 List,我们想要将其转换为一个 Map<String, Person>,其中键是每个人的名字(name),值是 Person 对象本身。
- keyMapper: Person::getName 是一个方法引用,它将 Person对象映射为其 name 属性。
- valueMapper: Function.identity()是一个函数,它返回输入值本身。在这里,它将 Person 对象映射为 Person 对象本身,即不进行任何转换。
allMatch()/anyMatch()
Java 8的Stream API中,allMatch() 和 anyMatch() 方法是非常有用的终端操作,用于检查流中的元素是否满足特定的条件。这两种方法都返回一个布尔值,但它们的目的略有不同。
allMatch()
allMatch() 方法用于检查流中的所有元素是否都满足给定的谓词(即一个返回布尔值的函数)。如果所有元素都满足条件,则返回 true;如果有任何一个元素不满足条件,则返回 false。
//用法
boolean result = stream.allMatch(predicate);
//stream: Stream对象。
//predicate: 一个返回布尔值的函数,用于测试每个元素。
示例:假设我们有一个整数列表,我们想检查列表中的所有数是否都是偶数:
List<Integer> numbers = Arrays.asList(2, 4, 6, 8, 10);
boolean allEven = numbers.stream().allMatch(n -> n % 2 == 0);
System.out.println("All numbers are even: " + allEven); // 输出: true
anyMatch()
anyMatch() 方法用于检查流中是否至少有一个元素满足给定的谓词。如果有任何一个元素满足条件,则返回 true;如果没有任何一个元素满足条件,则返回 false。
//用法
boolean result = stream.anyMatch(predicate);
//stream: Stream对象。
//predicate: 一个返回布尔值的函数,用于测试每个元素。
示例:假设我们有一个整数列表,我们想检查列表中是否有任何数是偶数:
List<Integer> numbers = Arrays.asList(1, 3, 5, 7, 9, 2);
boolean anyEven = numbers.stream().anyMatch(n -> n % 2 == 0);
System.out.println("Any number is even: " + anyEven); // 输出: true
总结
- allMatch():
- 用于检查所有元素是否都满足给定的条件。
- 如果所有元素都满足条件,则返回 true;否则返回 false。
- anyMatch():
- 用于检查是否至少有一个元素满足给定的条件。
- 如果有任何一个元素满足条件,则返回 true;否则返回 false。
下面是一个使用 allMatch() 和 anyMatch() 的综合示例:
import java.util.Arrays;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
public class CheckElementsNotInSet {
public static void main(String[] args) {
List<Integer> collect = Arrays.asList(1, 2, 3, 4);
Set<Integer> ids = Set.of(5, 6, 7);
boolean allNotInIds = collect.stream().anyMatch(id -> ids.contains(id));
System.out.println("All elements not in ids: " + allNotInIds);
}
}
/*分析
1. collect.stream():
○ 将 collect 集合转换为 Stream。
2. anyMatch:
○ 检查 Stream 中的是否有元素包含在 ids 集合中。
○ 如果所有元素都不包含,则返回 false;否则返回 true。
*/
二、线程
1. 概念
进程是一个程序
线程是一个进程中的执行场景/执行单元
一个进程可以启动多个线程
Eg:火车站是一个进程,每个检票口都是一个线程
进程之间内存独立不共享,在java中线程之间堆内存和方法区内存共享,栈内存独立
多线程并发多个线程同时执行互不影响
并发为交替执行,并行为同时执行
2. 线程的创建
package ThreadClass;
public class ThreadText1 {
//main方法,属于主线程,在主栈中运行
public static void main(String[] args) {
// 实现线程的第一种方法:编写一个类继承java.lang.Thread,重写void run()方法
//新建一个分支线程对象
MyThread myThread = new MyThread();
/*启动线程
start方法的作用:启动一个分支线程,在JVM中开辟一个新的栈空间,该代码执行后就结束了
只要新的栈空间开辟出来,start()方法就时间结束了
启动成功的线程会自动调用run方法,run方法在分支的栈底部,run与main()平级
*/
myThread.start();
//这个位置如果直接调用run方法(MyThread.run())不会启用新的分支找,还是在主栈中执行的
//main中的其他代码仍然是在主栈中执行
// 实现线程的第二种方法:编写一个类实现java.lang.Runnable接口,重写void run()方法 (注意:这并不是Tread线程类)
//Thread thread = new Thread(new myThread1())
//创建一个可运行对象
MyTread1 myTread1 = new MyTread1();
//包装成线程对象
Thread thread = new Thread(myTread1);
//启动线程
thread.start();
for (int i=1;i<=10;i++){
System.out.println("主线程--->"+i);
}
}
}
//方法一
class MyThread extends Thread{
public void run(){
for(int i=0;i<10;i++){
System.out.println("分支线程--->"+i);
}
}
}
//方法二 该接口为函数式接口可以使用lambde表达式简化匿名内部类的创建
class MyTread1 implements Runnable{
public void run(){
for (int i=0;i<=10;i++){
System.out.println("分支线程1--->"+i);
}
}
}
/*创建线程的第三种方式 了解
* 实现callable接口 该接口的call方法不同run方法,有异常抛出及方法返回值
* interface Callable<V>{
* <V> call() throws Exception;
* }
*
* 创建callable对象
* 利用callable对象创建FutureTask对象
* FutureTask的get方法获取call方法的返回值 该方法也会抛出异常 且会阻塞当前线程
* 将Futuretask对象包装进Thread中
* 调用thread的start方法启动线程
* */
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class ThreadCallable {
public static void main(String[] args) {
Mycallable mycallable = new Mycallable();
FutureTask<String> futureTask = new FutureTask(mycallable);
Thread t = new Thread(futureTask);
t.start();
try {
System.out.println(futureTask.get());
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ExecutionException e) {
throw new RuntimeException(e);
}
System.out.println("main线程");
}
}
class Mycallable implements Callable<String> {
public String call() throws Exception{
int sum = 0;
for(int i = 0;i<=10;i++){
sum = sum+i;
System.out.println(sum);
}
return Thread.currentThread().getName()+" "+sum;
}
}
原理解析
- 继承实现线程的方式:start方法底层调用了start0本地方法,通过操作系统资源开辟线程栈 , 然后自动回调了我们定义的run方法, run方法会加载到当前线程的线程栈中运行,注意直接调用run方法, 并没有开启线程栈。
- Runnable接口实现的线程方式:同样是通过start方法调用start0本地方法,这是会走Thread的run,在run方法中会判断是否传入了Runnable,如果传递了,就会走Rrunnable实现类的run方法。
- 第一种和第二种开启线程的优缺点:
- 第一种:
- 优点: 简单易懂,采用继承, 可以直接使用Thread的方法
- 缺点:
- 单继承的局限(无法在继承其他父类)
- 代码和线程耦合度过高
- 第二种:
- 优点:弥补了单继承的局限,代码和线程耦合度低 缺点:不是Thread的子类不能直接使用Thread的方法,但是可以通过Thread.currentThread()(推荐)
- 第一种:
3. 线程常用方法
package ThreadClass;
public class ThreadMethod {
public static void main(String[] args) {
ThreadMy threadMy = new ThreadMy();
//run() 专门放任务的地方 这个方法是用来从写的
//start 开启线程,底层调用了start0开启线程,一条线程只能被开启一次
//final String getName() 获取线程名字
System.out.println(threadMy.getName());//Thread-0
//final void setName(String s)将线程名字修改为s
threadMy.setName("1"); //线程,默认名字为Thread-i(由0开始第几个线程为几)
System.out.println(threadMy.getName());// 1
//启用线程
threadMy.start();
System.out.println("主线程");
//static Thread currentThread() 获取当前线程对象(方法出现在哪个线程中就返回那个线程对象)
//这个方法解决了第二章线程不能直接访问的线程的问题
System.out.println(Thread.currentThread().getName()); //main
//static void sleep(long millis) millis为毫秒 使当前线程进入指定时间的休眠(之后代码继续在当前位置执行)
//(该方法会抛出InterrupteException异常)不释放锁
for (int i=0;i<=10;i++){ //该方法可以实现程序每隔特定时间执行一次特定代码
System.out.println("main--->"+i);
try {
Thread.sleep(1000L);
} catch (Exception e) {
e.printStackTrace();
}
}
//void interrupt() 中断休眠---依靠异常机制try-catch抛出异常后执行后续代码
threadMy.interrupt();
//终止线程
ThreadMy2 threadMy2 = new ThreadMy2();
Thread thread = new Thread(threadMy2);
thread.start();
//需要终止线程时只需要将定义的run变量值改为false
//.....进行数据保存等关闭线程前的操作
threadMy2.run = false;
}
}
class ThreadMy extends Thread {
public void run() {
try {
//休眠一年
Thread.sleep(1000 * 60 * 60 * 24 * 365L); //该方法抛出异常不能选择上抛,因为run方法在Thread类中并没有抛出异常(抛出异常不能更多)
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("分支线程");
}
}
//终止线程
class ThreadMy2 implements Runnable{
//定义一个boolean类型的run变量,值为false
boolean run = true;
public void run() {
if (run) {
for (int i = 0; i <= 10; i++) {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}else {
return;
}
}
}
4. 线程调度
- 线程调度:优先级,让位,合并------了解
- 常见的线程调度模型
- 抢占式调度模型:
- 线程的优先级较高,抢到的CPU时间片的概率就高。Java采用的就是抢占式调度模型。
- 均分式调度模型:
- 平均分配CPU时间片。每个线程占有的CPU时间片时间长度一样。平均分配,一切平等。
有一些编程语言,线程调度模型采用的是这种方式。
- 平均分配CPU时间片。每个线程占有的CPU时间片时间长度一样。平均分配,一切平等。
- 抢占式调度模型:
- 线程调度常用方法
- 实例方法:
- void setpriority (int newPriority):设置线程的优先级
- int getPriority():获取线程优先级
- 最低优先级1
- 默认优先级是5
- 最高优先级10
- int getPriority():获取线程优先级
- 静态方法:
- static void yield():让位方法:暂停当前正在执行的线程对象,并执行其他线程yield()方法不是阻塞方法。让当前线程让位,让给其它线程使用。yield()方法的执行会让当前线程从“运行状态”回到“就绪状态”。
- 注意:在回到就绪之后,有可能还会再次抢到CPU
- 实例方法:
void join() :合并线程,让当前线程进入阻塞,调用该方法的线程执行,调用方法的线程结束。当前线程才可以继续
- void setpriority (int newPriority):设置线程的优先级
- 实例方法:
线程合并
class MyThread1 extends Thread {
public void doSome(){
Mythread2 t = new MyThread2();
t.join();
//当前线程(此案例当前线程为mian线程---目前正在执行的线程)进入阻塞,t线程执行,t线程结束。当前线程才可以继续
}
}
class MyThread2 extends Thread{
}
//eg:二
package ThreadClass;
public class ThreadMerge {
public static void main(String[] args){
System.out.println("main begin");
Thread thread = new Thread(new ThreadMy4());
thread.setName("t");
thread.start();
//final void join() throws InterruptedException: 将目标线程合并到当前的线程中,当前线程受阻塞,目标线程执行直到结束再继续执行main线程。
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("main over");
}
}
class ThreadMy4 implements Runnable{
public void run(){
System.out.println("t线程负责内容 begin---over");
}
}
优先级
package ThreadClass;
public class ThreadPriority {
public static void main(String[] args){
System.out.println("线程最高优先级"+Thread.MAX_PRIORITY); //10
System.out.println("线程最低优先级"+Thread.MIN_PRIORITY); //1
System.out.println("线程默认优先级"+Thread.NORM_PRIORITY); //5
// int getPriority():获取当前线程优先级
System.out.println(Thread.currentThread().getName()+"线程的优先级是"+Thread.currentThread().getPriority()); //5
Thread thread = new Thread(new ThreadTest());
//void setPriority(int newPriority):设置线程优先级
thread.setPriority(10);
thread.start();
}
}
class ThreadTest implements Runnable{
public void run(){
System.out.println(Thread.currentThread().getName()+"线程的优先级是"+Thread.currentThread().getPriority()); //10
}
}
线程让位
package ThreadClass;
public class ThreadGiveWay {
public static void main(String[] args) {
ThreadMy3 t = new ThreadMy3();
t.setName("t");
t.start();
int i = 1;
for (;i<=10; i++){
if (i%2==0){
System.out.println("main让出CPU时间片");
//static void yield():让位(使当前线程回到就绪状态---依然也可能抢到时间片)
Thread.yield();
}
System.out.println("mian--->"+i);
}
}
}
class ThreadMy3 extends Thread{
public void run(){
for(int i=1;i<=10;i++){
System.out.println("t--->"+i);
if (i==10){
System.out.println("t线程执行结束");
}
}
}
}
5. 线程安全(重点)
线程安全产生的原因
- 多个线程在对共享数据进行读改写的时候,可能导致的数据错乱就是线程的安全问题了。Eg:电影院售票问题来举例—三个窗口同时售卖100张票
/*
1 定义一个类Ticket实现Runnable接口,里面定义一个成员变量:private int ticketCount = 100;
2 在Ticket类中重写run()方法实现卖票,代码步骤如下
A:判断票数大于0,就卖票,并告知是哪个窗口卖的
B:票数要减1
C:卖光之后,线程停止
3 定义一个测试类TicketDemo,里面有main方法,代码步骤如下
A:创建Ticket类的对象
B:创建三个Thread类的对象,把Ticket对象作为构造方法的参数,并给出对应的窗口名称
C:启动线程
*/
package com.itheima.ticket_demo;
/*
电影院
*/
public class Ticket implements Runnable {
private int ticketCount = 100; // 一共有一百张票
@Override
public void run() {
while (true) {
// 如果票的数量为0 , 那么停止买票
if (ticketCount == 0) {
break;
} else {
// 模拟出票的时间
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 有剩余的票 , 开始卖票
ticketCount--;
System.out.println(Thread.currentThread().getName() + "卖出一张票,剩下" + ticketCount + "张");
}
}
}
}
package com.itheima.ticket_demo;
public class TicketDemo {
public static void main(String[] args) {
// 创建任务类对象
Ticket ticket = new Ticket();
// 创建三个线程类对象
Thread t1 = new Thread(ticket);
Thread t2 = new Thread(ticket);
Thread t3 = new Thread(ticket);
// 给三个线程命名
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
// 开启三个线程
t1.start();
t2.start();
t3.start();
}
}
/*通过上述代码的执行结果 , 发现了出现了负号票 , 和相同的票 , 数据有问题
问题出现的原因 : 多个线程在对共享数据进行读改写的时候,可能导致的数据错乱
就是线程的安全问题了
*/
线程的同步
- 概述
- Java允许多线程并发执行,当多个线程同时操作一个可共享的资源变量时(如数据的增删改查),将会导致数据不准确,相互之间产生冲突,因此加入同步锁以避免在该线程没有完成操作之前,被其他线程的调用,从而保证该变量的唯一性和准确性
- 分类
- 同步代码块
- 同步方法
- 锁机制-Lock
同步代码块
- 同步代码块 :
- 锁住多条语句操作共享数据,可以使用同步代码块实现
- 第一部分 : 格式
synchronized(任意对象) { //该对象要求唯一,建议为同步的进程公共对象
共享代码
} - 第二部分 : 注意
1 默认情况锁是打开的,只要有一个线程进去执行代码了,锁就会关闭
2 当线程执行完出来了,锁才会自动打开 - 第三部分 : 同步的好处和弊端
好处 : 解决了多线程的数据安全问题
弊端 : 当线程很多时,因为每个线程都会去判断同步上的锁,这是很耗费资源的,无形中会降低程序的运行效率
public class Ticket implements Runnable {
private int ticketCount = 100; // 一共有一百张票
@Override
public void run() {
while (true) {
synchronized (this) {
// 如果票的数量为0 , 那么停止买票
if (ticketCount == 0) {
break;
} else {
// 模拟出票的时间
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 有剩余的票 , 开始卖票
ticketCount--;
System.out.println(Thread.currentThread().getName() + "卖出一张票,剩下" + ticketCount + "张");
}
}
}
}
}
package com.itheima.synchronized_demo1;
public class TicketDemo {
public static void main(String[] args) {
// 创建任务类对象
Ticket ticket = new Ticket();
// 创建三个线程类对象
Thread t1 = new Thread(ticket);
Thread t2 = new Thread(ticket);
Thread t3 = new Thread(ticket);
// 给三个线程命名
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
// 开启三个线程
t1.start();
t2.start();
t3.start();
}
}
同步方法(同步方法的类都已经淘汰了)
- 同步方法:就是把synchronized关键字加到方法上
- 格式:
- 修饰符 synchronized 返回值类型 方法名(方法参数) { }
- 格式:
- 同步代码块和同步方法的区别:
1 同步代码块可以锁住指定代码,同步方法是锁住方法中所有代码
2 同步代码块可以指定锁对象,同步方法不能指定锁对象 - 注意 : 同步方法时不能指定锁对象的 , 但是有默认 的锁对象的。
1 对于非static方法,同步锁就是this。
2 对于static方法,我们使用当前方法所在类的字节码对象(类名.class)。 Class类型的对象 - 同步方法的缺点:
- 锁对象是写死的, 要么非静态是this, 要么静态的当前的字节码对象不能指定锁对象
- 一锁锁所有, 锁定方法代码, 不能锁住局部
package com.itheima.synchronized_demo2;
public class Ticket implements Runnable {
private int ticketCount = 100; // 一共有一百张票
@Override
public void run() {
while (true) {
if (method()) {
break;
}
}
}
private synchronized boolean method() { //ctrl+alt+M idea中选择代码生成指定方法
// 如果票的数量为0 , 那么停止买票
if (ticketCount <= 0) {
return true;
} else {
// 模拟出票的时间
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 有剩余的票 , 开始卖票
ticketCount--;
System.out.println(Thread.currentThread().getName() + "卖出一张票,剩下" + ticketCount + "张");
return false;
}
}
}
Lock锁(JDK1.5出现的最没用的东西)
- 虽然我们可以理解同步代码块和同步方法的锁对象问题,但是我们并没有直接看到在哪里加上了锁,在哪里释放了锁,为了更清晰的表达如何加锁和释放锁,JDK5以后提供了一个新的锁对象Lock
- Lock中提供了获得锁和释放锁的方法
void lock():获得锁
void unlock():释放锁 - Lock是接口不能直接实例化,这里采用它的实现类ReentrantLock来实例化
ReentrantLock的构造方法
ReentrantLock():创建一个ReentrantLock的实例 - 注意:多个线程使用相同的Lock锁对象,需要多线程操作数据的代码放在lock()和unLock()方法之间。一定要确保unlock最后能够调用
package com.itheima.synchronized_demo3;
import java.util.concurrent.locks.ReentrantLock;
public class Ticket implements Runnable {
private int ticketCount = 100; // 一共有一百张票
ReentrantLock lock = new ReentrantLock();
@Override
public void run() {
while (true) {
try {
lock.lock();// 加锁
// 如果票的数量为0 , 那么停止买票
if (ticketCount == 0) {
break;
} else {
// 模拟出票的时间
Thread.sleep(100);
// 有剩余的票 , 开始卖票
ticketCount--;
System.out.println(Thread.currentThread().getName() + "卖出一张票,剩下" + ticketCount + "张");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();// 释放锁
}
}
}
}
死锁
- 概念:
- 死锁是一种少见的,而且难于调试的错误,在两个线程对两个同步锁对象具有循环依赖时,就会大概率的出现死锁。我们要避免死锁的产生。否则一旦死锁,除了重启没有其他办法的
- 产生条件 :
- 多个线程
- 存在锁对象的循环依赖
package com.itheima.deadlock_demo;
public class DeadLockDemo {
public static void main(String[] args) {
String 筷子A = "筷子A";
String 筷子B = "筷子B";
//线程一
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
synchronized (筷子A) {
System.out.println("小白拿到了筷子A ,等待筷子B....");
synchronized (筷子B) {
System.out.println("小白拿到了筷子A和筷子B , 开吃!!!!!");
}
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, "小白").start();
//线程二
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
synchronized (筷子B) {
System.out.println("小黑拿到了筷子B ,等待筷子A....");
synchronized (筷子A) {
System.out.println("小黑拿到了筷子B和筷子A , 开吃!!!!!");
}
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, "小黑").start();
}
}
/*
该代码会出现小黑拿到筷子A等待筷子B
同时小白拿到筷子B等待筷子A的情况 这种情况就是死锁
*/
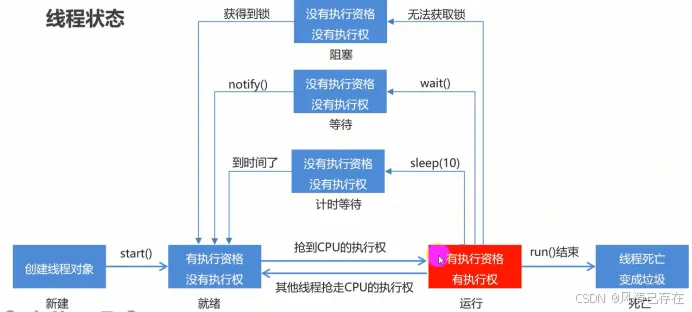
线程状态

线程通信
- 线程间的通讯技术就是通过等待和唤醒机制,来实现多个线程协同操作完成某一项任务,例如经典的生产者和消费者案例。等待唤醒机制其实就是让线程进入等待状态或者让线程从等待状态中唤醒,需要用到两种方法,这两种方法都需要锁对象来调用,因为“万物”皆可为锁,所以Object中也定义了如下方法:
- 等待方法 :
- void wait() 让线程进入无限等待。
- void wait(long timeout) 让线程进入计时等待
○ 以上两个方法调用会导致当前线程释放掉锁资源。
○ 唤醒方法 : - void notify() 唤醒在此对象监视器(锁对象)上等待的单个线程。(随机唤醒除了本线程外的任意一个等待的线程)
- void notifyAll() 唤醒在此对象监视器上等待的所有线程。
- 等待方法 :
- 以上两个方法调用不会导致当前线程释放掉锁资源
- 注意
- 等待和唤醒的方法,都要使用锁对象调用(需要在同步代码块中调用)
- 等待和唤醒方法应该使用相同的锁对象调用
package com.itheima.waitnotify_demo;
/*
线程进入无限等待后被唤醒
注意:等待和唤醒是两个或多个线程之间实现的。进入无限等待的线程是不会自动唤醒,只能通过其他线程来唤醒。
*/
public class Test2 {
public static void main(String[] args) {
Object obj = new Object(); // 作为锁对象
//线程进入无限期等待
new Thread(new Runnable() {
@Override
public void run() {
synchronized (obj) {
System.out.println("线程开始执行");
System.out.println("线程进入无线等待....");
try {
obj.wait(); // 进入无线等待状态 , 并释放锁
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("无线等待被唤醒....");
}
}
}).start();
//该线程唤醒上述等待线程
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (obj) {
obj.notify();// 随机唤醒此监视器中等待的线程 , 不会释放锁
System.out.println("唤醒后 , 5秒钟后释放锁");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}// 释放锁
}
}).start();
}
}
package com.itheima.waitnotify_demo;
/*
3 线程进入计时等待并唤醒
注意:进入计时等待的线程,时间结束前可以被其他线程唤醒。时间结束后会自动唤醒
*/
public class Test3 {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
synchronized (Test3.class) {
System.out.println("获取到锁 , 开始执行");
try {
System.out.println("进入计时等待...3秒");
Test3.class.wait(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("自动唤醒.");
}
}
}).start();
}
}
6. 线程池
创建线程池
- 在JDK5版本中提供了代表线程池的接口ExecutorService,而这个接口下有一个实现类叫ThreadPoolExecutor类,使用ThreadPoolExecutor类就可以用来创建线程池对象。

- 临时线程创建时间
- 新任务提交时,发现核心线程都在忙、任务队列满了、并且还可以创建临时线程,此时会创建临时线程。
- 拒绝新任务时间
- 核心线程和临时线程都在忙、任务队列也满了、新任务过来时才会开始拒绝任务。
package cn.itheima.d8_thread_pool.create;
import java.util.concurrent.*;
/* (类比餐厅)
public ThreadPoolExecutor(int corePoolSize, // 核心线程数量(正式工)
int maximumPoolSize, //最大线程数量,核心线程+临时线程(正式工+临时工)
long keepAliveTime, //临时线程存活时间(临时工闲多久被开除)
TimeUnit unit, //临时线程存活时间的时间单位(枚举类型)
BlockingQueue<Runnable> workQueue, //指定线程池的任务队列(客人排队的地方)
ThreadFactory threadFactory, //指定线程池的线程工厂(负责招聘的hr)
RejectedExecutionHandler handler) //指定线程池的任务拒绝策略.[线程都在忙,任务队列也满了的时候,新任务来了该怎么处理](餐厅忙不过来咋整)
*/
public class Test {
public static void main(String[] args) {
ExecutorService pool = new ThreadPoolExecutor(3, 5, 8,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(4), //new ArrayBlockingQueue<>(4)->底层是数组,需要指定长度.
// new LinkedBlockingDeque<>()->底层是链表,不需要指定长度,可以随便放(垃圾)
Executors.defaultThreadFactory(), //默认工厂(这个是个接口但是没有提供实现类
//Executors工具类中提供了一个默认工厂,这个方法中返回了一个实现类)
new ThreadPoolExecutor.AbortPolicy());
// 拒绝策略:
// new ThreadPoolExecutor.AbortPolicy() --- 丢弃任务并抛出异常入(默认策略,最佳策略)
// new ThreadPoolExecutor.DiscardPolicy() --- 丢弃任务,但不抛出异常(不推荐,最垃圾的策略)
// new ThreadPoolExecutor.DiscardOldestPolicy() --- 丢弃队列中等待最久的任务,然后把当前的任务加入到队列中,不抛异常(最有病的策略)
// new ThreadPoolExecutor.CallerRunsPolicy() --- 不拒绝,由主线(main线程 )程负责调用任务,从而绕过线程池直接执行 (老板亲自端盘子)
}
}
线程池工具类(废物)



三、反射
1. 反射获取字节码文件
实体类
package day14.reflect.MyClass;
public class Student {
private String name;
private int age;
public Student(){}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public void eat(String s){
System.out.println(s);
}
}
反射获取
/*
反射: 就是解剖字节码对象的一种方式
如何获取字节码对象:
(1) 类名.class
Class<类名> c1 = 类名.class;
(2) 通过对象反向获取字节码对象
Class<? extends 类名> c2 = 类名.getClass();
(3) Class的静态方法 forName(全类名);
什么是全类名: 包名 +"."+ 类名
Class<?> c3 = Class.forName("全类名");
Class类常见的功能(实例方法):
String getName(); 获取全类名
ClassLoader getClassloader(); 获取当前字节码的类加载器!!!
*/
public class Test {
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException {
//1.类名.class
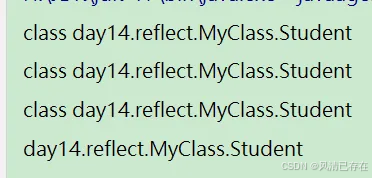
Class<Student> c1 = Student.class;
System.out.println(c1);
//2.通过对象反向获取字节码对
Student student = new Student();
Class<? extends Student> c2 = student.getClass();
System.out.println(c2);
//3.Class的静态方法 forName(全类名);
Class<?> c3 = Class.forName("day14.reflect.MyClass.Student");
System.out.println(c3);
//getName(); 获取全类名
String name = c3.getName();
System.out.println(name);
//getClassLoader() 获取(第三类)类加载器
ClassLoader classLoader = c3.getClassLoader();
}
}
2. 反射获取构造方法
Japanese类
package day14.reflect.MyClassConstructor;
public class Japanese {
private String name;
private int age;
private String address;
public Japanese() {
}
public Japanese(String name, int age) {
this.name = name;
this.age = age;
}
private Japanese(String name, int age, String address) {
this.name = name;
this.age = age;
this.address = address;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String killSelf(){
System.out.println(name+"拿刀抹脖子了~~");
return "好开心";
}
private String killSelf(String family){
System.out.println(name+"搂着"+family+"一起拿刀抹脖子了~~");
return "一家人团员开心";
}
@Override
public String toString() {
return "Japanese{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
'}';
}
}
反射获取构造方法
package day14.reflect.MyClassConstructor;
/*
传统方式创建对象的优缺点:
优点简单易懂,使用方便。
缺点创建对象的格式没有统一,导致代码不通用,导致如果有修改对象的需求不得不修改源码才能做到修改对象的目的!!!!!!!!
反射统一了创建对象的方式, 不管是哪个类的创建对象都是newInstance创建的
还可以动态读取字节码的全类名创建对象, 可以修改配置文件达到动态创建对象的目的!!!!!!!!!!!!!!
小知识:
如果我们反射的是public修饰的无参构造的话, 可以简化书写, 直接通过字节码的newInstance就可以创建对象
少了一级!!!!!
*/
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
/*
反射: 解剖构造:
(1) 先拿到字节码才能解剖
(2) 通过字节码对象获取构造函数对象 (可变参数为构造方法参数的.class)
Constructor<T>[] getConstructors(); 获取所有的public修饰的构造函数们!!!
Constructor<T>[] getDeclaredConstructors(); 获取所有的构造函数们!!!
(常用)
Constructor<T> getConstructor(Class...clazz); 获取单个public修饰的构造函数!!!
Constructor<T> getDeclaredConstructor(Class...clazz); 获取单个任意修饰符的构造!!!
(3) 使用构造
Constructor类常用方法
<T> newInstance(Object... args);创建对象
反射使用无参构造创建对象时可以直接通过Class对象调用newIntance()方法
void setAccessible(boolean access); 暴力反射 默认为false 设置为true则可以调用私有构造
*/
public class Test {
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException {
//获取Class类对象(字节码对象)
Class<Japanese> c = Japanese.class;
//通过字节码对象获取Construcutor对象
Constructor<Japanese> constructor = c.getDeclaredConstructor(String.class, int.class);
//通过Constructor对象的newIntance()方法创建对象
Japanese japanese = constructor.newInstance("陈", 18);
System.out.println(japanese);
//通过暴力反射创建对象
Constructor<Japanese> declaredConstructor1 = c.getDeclaredConstructor(String.class, int.class,String.class);
//上面获取的Constructor对象为私有构造方法的构造对象,调用Accessible方法破解
declaredConstructor1.setAccessible(true);
//创建对象
Japanese japanese1 = declaredConstructor1.newInstance("陈", 18, "rb");
System.out.println(japanese1);
}
}

3. 反射获取注解
在Java中,你可以使用反射来获取一个方法上的注解信息。下面我将展示如何从一个方法中获取@AutoFill注解的信息,这与你提供的代码片段中的做法是一致的。
首先,你需要确保你的方法上有@AutoFill注解。例如,假设我们有这样一个方法:
public class ExampleMapper {
@AutoFill(OperationType.INSERT)
public void insertExampleEntity(ExampleEntity entity) {
// 插入逻辑
}
@AutoFill(OperationType.UPDATE)
public void updateExampleEntity(ExampleEntity entity) {
// 更新逻辑
}
}
接下来,我们可以使用反射来获取这些方法上的@AutoFill注解信息。这里我将展示一个简单的例子,而不是在一个完整的AOP切面中:
import com.sky.annotation.AutoFill;
import com.sky.enumeration.OperationType;
import java.lang.reflect.Method;
public class AnnotationDemo {
public static void main(String[] args) throws Exception {
Class<ExampleMapper> mapperClass = ExampleMapper.class;
// 获取带有 @AutoFill 注解的方法
Method insertMethod = mapperClass.getMethod("insertExampleEntity", ExampleEntity.class);
Method updateMethod = mapperClass.getMethod("updateExampleEntity", ExampleEntity.class);
// 获取 @AutoFill 注解
AutoFill insertAnnotation = insertMethod.getAnnotation(AutoFill.class);
AutoFill updateAnnotation = updateMethod.getAnnotation(AutoFill.class);
// 输出注解中的信息
System.out.println("Insert operation type: " + insertAnnotation.value());
System.out.println("Update operation type: " + updateAnnotation.value());
}
}
在上面的例子中,我们做了以下几件事:
- 我们获取了ExampleMapper类的一个Class实例。
- 我们使用getMethod方法来获取具体的方法。getMethod需要两个参数:方法名和方法参数类型的数组。
- 我们使用getAnnotation方法来获取方法上的@AutoFill注解。
- 最后,我们可以通过注解的属性(在这个例子中是value)来获取具体的信息。
反射获取成员变量
使用的还是上面的Japanese类
package day14.reflect.MyClassField;
/*
反射操作成员变量的好处
传统方式: 由于成员变量名字不一样, 导致无法批量操作成员变量!!!!
反射, 反射统一了成员变量操作方式, 都是get, 都是set , 通用性很强!!!
*/
import day14.reflect.MyClassConstructor.Japanese;
import java.lang.reflect.Field;
/*
解剖成员变量:
(1) 先获取字节码
(2) 获取成员变量
Field[] getFields(); 获取所有public修饰的成员
Field[] getDeclaredFields(); 获取所有的成员
(重要)
Field getField(String name); 获取单个public修饰的成员 参数为属性名
Field getDeclaredField(String name); 获取单个的成员 参数为属性名
(3) 使用
Filed类常用方法
void set(对象, 新值) 将指定对象的指定属性修改为新值
T get(对象)
void setAccessible(boolean acces) 暴力反射 默认为false 设置为true则可以调用私有属性
*/
public class Test {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
Japanese japanese1 = new Japanese();
japanese1.setName("陈大法官");
japanese1.setAge(18);
japanese1.setAddress("rb");
//获取Class类对象(字节码对象)
Class<Japanese> c = Japanese.class;
//通过Class对象获取Field对象
Field name = c.getDeclaredField("age");
//属性为私有 暴力反射
name.setAccessible(true);
//通过Field的set方法设置属性值
name.set(japanese1,38);
System.out.println(japanese1);
}
}

5. 反射获取成员方法
使用的还是上面的Japanese类
package day14.reflect.MyClassMethod;
/*
传统方式调用方法的缺点:
由于方法名不一致导致, 导入格式不统一, 没有办法批量操作
反射可以统一方法的调用格式
反射,不管是什么方法调用方法都是invoke!!!!!!!!!!!!!!
*/
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class Test {
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
/*
解剖成员方法:
(1) 先获取字节码对象
(2) 获取成员方法
Method[] getMethods(); 获取自己以及所有父类有关的public 修饰的所有方法
Method[] getDeclaredMethods(); 获取本类的所有的方法, 无视修饰符
(主要)
Method getMethod(String methodName, Class ... clazz); 获取单个 第一参数为方法名,可变参为参数列表的.class
Method getDeclaredMethod(String methodName, Class ... clazz);获取无视修饰符的单个
(3) 使用成员方法
Method类常用方法
Object invoke(对象, Object... args); 调用对象指定方法,返回方法执行结果,可变参为方法参数列表
如果反射调用的是静态方法我们第一个参数传入null
void setAccessible(boolean a);
*/
Japanese japanese1 = new Japanese("陈大法官",19);
Japanese japanese2 = new Japanese("王大法官",18);
//获取Class类对象(字节码对象)
Class<Japanese> japaneseClass = Japanese.class;
/*
Method[] methods = japaneseClass.getDeclaredMethods();
for (Method method : methods) {
System.out.println(method);
}
*/
//通过Class对象获取MetHod对象
Method method1 = japaneseClass.getMethod("killSelf");
//调用方法
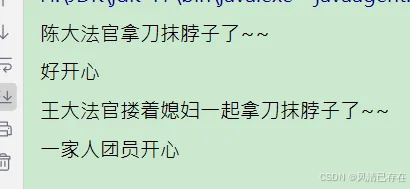
Object invoke = method1.invoke(japanese1);// japanese1.killSelf();
System.out.println(invoke);
Method method2 = japaneseClass.getDeclaredMethod("killSelf", String.class);
method2.setAccessible(true);
//泛型在编译后会被擦除,所以返回值为Object
Object invoke1 = method2.invoke(japanese2, "媳妇");//japanese2.killSelf("媳妇");
System.out.println(invoke1);
}
}
四、注解
package day14.annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.TYPE) //@Target(value = {ElementType.TYPE} )
@Retention(RetentionPolicy.RUNTIME)
public @interface Anno {
// public final static int num = 10;
/*
注解反编译后的产物:
public interface Anno extends java.lang.annotation.Annotation {
}
注解的本质是接口 而且是基于JDK1.5的接口 所以只能有常量和抽象方法
注解的抽象方法有要求:
(1) 只能是如下的返回值类型
基本类型
String
枚举类型
字节码类型
注解类型
以上类型的一维数组
(2) 没有参数列表
注解的使用
@注解名(重写方法名=返回值,...,) 就是接口实现类
解析注解:
注解一般加载类上, 方法上, 成员变量上,构造函数上, 参数列表上, 必须通过反射才能获取各个部分的注解
注解放在什么地方, 就解剖哪一部分
T 获取注解对象 getAnnotation(T.class);
@Anno(method = 10)
如果我们的抽象方法名为value, 而且仅仅只是对这个value的方法进行赋值的时候可以省略value不写
如果我们的抽象方法的返回值是数组类型, 但是赋值的时候只有一个值,此时我们的{}可以省略不写
元注解就是采用的这种简化
元注解:
jdk设计出来专门用于修饰注解的注解叫做元注解
@Target : 专门限制注解修饰的范围
@Retention: 限制注解存在阶段
默认我们自定义的注解如果没有使用元注解的修饰的话
默认修饰的范围: 所有范围
默认存在阶段: 源码阶段
注解的作用:
取代部分的xml文件功能, 用来和框架进行对话的!!!
*/
public int method();
}
注解的使用
package day14.annotation;
@Anno(method = 10) //这里相当于接口实现类,method为方法名,10为返回值
public class A {
// @Anno(method = 11)
public void aVoid(){
System.out.println("fadsf");
}
}
五、动态代理
代理就是在不改变原有数据的情况下,对原功能进行增强。
1. 生成动态代理对象
Java为开发者提供的一个生成代理对象的类叫Proxy类。
java.lang.reflect.Proxy包下
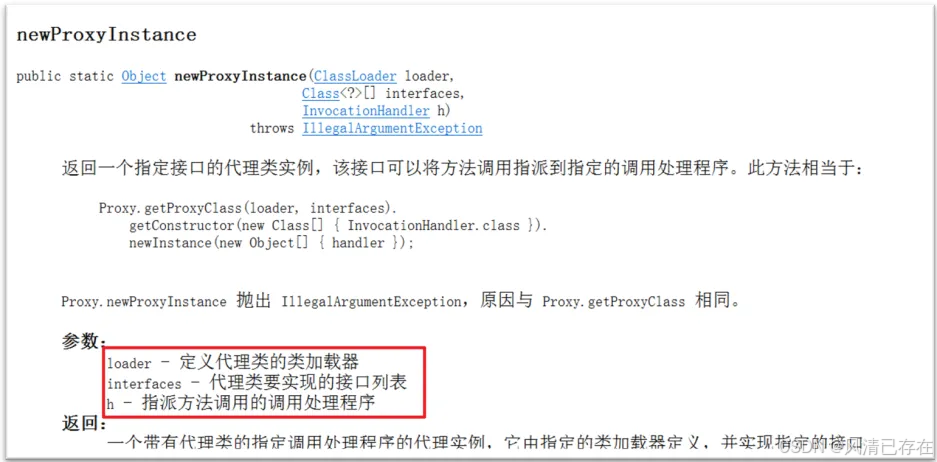
通过Proxy类的静态方法newProxyInstance(…)方法可以为实现了同一接口的类生成代理对象。 调用方法时需要传递三个参数,该方法的参数解释可以查阅API文档,如下。
/* newProxyInstance(
ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h);
参数1:用于指定一个类加载器
参数2:指定生成的代理长什么样子,也就是有哪些方法(就是实现接口的类型)
参数3:用来指定生成的代理对象要干什么事情
*/
/*方法分析
这里底层其实就是new了一个接口实现类,在实现类中的每一个重写的方法中都调用了接口InvocationHandler实现类中invoket方法
*/
//eg
public interface A {
void eat();
void sleep();
void drink();
}
A a = (A)Proxy.newProxyInstance(
ren.getClass().getClassLoader(),
new Class[]{A.class},
new InvocationHandler() {
@Override
public Object invoke(Object proxy,Method method,Object[] args) throws Throwable{
return null;
}
});//假设该接口实现类引用地址为001
/*
底层先new一个接口实现类
new A(){
重写接口方法
public void(String) eat(){
在每个方法中都调用了InvocationHandler接口实现类的invoke方法
参数个数如下
Object result = 001.invoke(this,eat方法对象.new Object[](这里将参数包装到了Object数组中))
(return result) relust为方法结果,如果方法有返回值则需要将该结果返回
}
public void sleep(){
Object result = 001.invoke(this,sleep方法对象.new Object[](这里将参数包装到了Object数组中))
}
public void drink(){
Object result = 001.invoke(this,drink方法对象.new Object[](这里将参数包装到了Object数组中))
}
}
*/
接口
package day14.proxy;
public interface A {
void eat();
void sleep();
void drink();
}
原有对象
package day14.proxy;
public class Ren implements A {
@Override
public void eat() {
System.out.println("吃饭");
}
@Override
public void sleep() {
System.out.println("睡觉");
}
@Override
public void drink() {
System.out.println("喝水");
}
}
代理增强
package day14.proxy;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
/*
动态代理:
增强功能存在
增强功能的方式:
(1) 继承方式
优点: 通俗易懂
缺点: (1) 不能批量增强 (2) 对象的创建权必须在自己手中才行
(2) 装饰者设计模式 (今天不讲)
(3) 动态代理设计模式
优点:解决 第一种的缺点
缺点: 必须面向接口编程!!!
*/
public class Test {
public static void main(String[] args) {
//1.原有对象
Ren ren = new Ren();
//调用Proxy的静态方法newProxyInstance()得到代理对象
A a = (A)Proxy.newProxyInstance(
ren.getClass().getClassLoader(),
new Class[]{A.class},
new InvocationHandler() { //该接口同样为函数式接口可以使用lambde简化
@Override
public Object invoke(Object proxy,Method method,Object[] args) throws Throwable{
//挑出需要增强的方法,进行增强
if (method.getName().equals("eat")){
//增强
System.out.println("准备干饭");
//回掉了原对象方法(根据实际需求)
Object invoke = method.invoke(ren);
System.out.println("吃黄焖鸡米饭");
return invoke;
}else if (method.getName().equals("drink")){
//增强
System.out.println("口渴");
//回掉了原对象方法
Object invoke = method.invoke(ren);
System.out.println("来瓶和其正");
return invoke;
}else {
Object invoke = method.invoke(ren);
return invoke;
}
}
});
//调用代理对象
a.eat();
a.drink();
a.sleep();
}
}
六、对象的克隆
目的:获取对象的当前状态
1. 对象的克隆(浅拷贝)
/*
步骤(浅克隆):
1. 被复制的类需要实现Clonenable接口(不实现的话在调用clone方法会抛出CloneNotSupportedException异常),
该接口为标记接口(不含任何方法)
2. 覆盖clone()方法,访问修饰符设为public。方法中调用super.clone()方法得到需要的复制对象,将复制的对象返回。
(native为本地方法)
*/
class Student implements Cloneable{
private int number;
public int getNumber() {
return number;
}
public void setNumber(int number) {
this.number = number;
}
@Override
public Object clone() {
Student stu = null;
try{
stu = (Student)super.clone();
}catch(CloneNotSupportedException e) {
e.printStackTrace();
}
return stu;
}
}
public class Test {
public static void main(String args[]) {
Student stu1 = new Student();
stu1.setNumber(12345);
Student stu2 = (Student)stu1.clone();
System.out.println("学生1:" + stu1.getNumber()); //12345
System.out.println("学生2:" + stu2.getNumber()); //12345
System.out.println(stu1==stu2); //false
//拷贝了一个对象,与原地址不同
}
}
Object的clone方法解析
/*
Creates and returns a copy of this object. The precise meaning of "copy" may depend on the class of the object.
The general intent is that, for any object x, the expression:
1) x.clone() != x will be true
2) x.clone().getClass() == x.getClass() will be true, but these are not absolute requirements.
3) x.clone().equals(x) will be true, this is not an absolute requirement.
*/
protected native Object clone() throws CloneNotSupportedException;
/*
该方法是一个native方法,native方法是非Java语言实现的代码,供Java程序调用的,因为Java程序是运行在JVM虚拟机上面的,
要想访问到比较底层的与操作系统相关的就没办法了,只能由靠近操作系统的语言来实现。
因为每个类直接或间接的父类都是Object,因此它们都含有clone()方法,但是因为该方法是protected,所以都不能在类外进行访问。
要想对一个对象进行复制,就需要对clone方法覆盖。重写方法提高修饰权限为public
*/
2. 深拷贝
/*
对于拷贝对象中的引用类型变量,浅拷贝只是复制了变量的引用,并没有真正的开辟另一块空间。导致拷贝对象和拷贝生成的对象中的
引用类型数据共同指向了同一个地址。
所以,为了达到真正的复制对象,而不是纯粹引用复制。我们需要将拷贝对象中的引用类型数据可复制化。
*/
package abc;
class Address implements Cloneable {
private String add;
public String getAdd() {
return add;
}
public void setAdd(String add) {
this.add = add;
}
@Override
public Object clone() {
Address addr = null;
try{
addr = (Address)super.clone();
}catch(CloneNotSupportedException e) {
e.printStackTrace();
}
return addr;
}
}
class Student implements Cloneable{
private int number;
private Address addr;
public Address getAddr() {
return addr;
}
public void setAddr(Address addr) {
this.addr = addr;
}
public int getNumber() {
return number;
}
public void setNumber(int number) {
this.number = number;
}
@Override
public Object clone() {
Student stu = null;
try{
stu = (Student)super.clone(); //浅复制 克隆一遍
}catch(CloneNotSupportedException e) {
e.printStackTrace();
}
stu.addr = (Address)addr.clone(); //深度复制 将克隆类中的引用,改为该引用,克隆后的数据
return stu;
}
}
public class Test {
public static void main(String args[]) {
Address addr = new Address();
addr.setAdd("杭州市");
Student stu1 = new Student();
stu1.setNumber(123);
stu1.setAddr(addr);
Student stu2 = (Student)stu1.clone();
System.out.println("学生1:" + stu1.getNumber() + ",地址:" + stu1.getAddr().getAdd());
//学生1:123,地址:杭州市
System.out.println("学生2:" + stu2.getNumber() + ",地址:" + stu2.getAddr().getAdd());
//学生2:123,地址:杭州市
addr.setAdd("西湖区");
System.out.println("学生1:" + stu1.getNumber() + ",地址:" + stu1.getAddr().getAdd());
//学生1:123,地址:西湖区
System.out.println("学生2:" + stu2.getNumber() + ",地址:" + stu2.getAddr().getAdd());
//学生2:123,地址:杭州市
}
}
