引言:机器人感知的实时性挑战
斯坦福机器人实验室采用异步脉冲神经网络处理DVS事件相机数据后,动态障碍物响应延迟从34ms降至0.9ms。在20m²复杂场景避障测试中,基于神经形态芯片的路径规划系统将SLAM更新频率提升至10kHz,较传统GPU方案能耗降低97%。其事件驱动架构使系统在80km/h移动速度下实现2cm精度定位,功耗稳定在1.2W。
一、传统视觉算法的物理局限
1.1 不同感知方案性能对比(动态场景)
| 属性 | 双目视觉 | LiDAR方案 | 事件相机方案 |
|---|---|---|---|
| 数据速率 | 30Hz RGB | 1.5M点/秒 | 1.2M事件/ms |
| 动态响应延时 | 120ms | 60ms | 0.8ms |
| 功耗(移动平台) | 18W | 35W | 0.4W |
| 光照适应范围(lux) | 10-10^4 | 不限 | 0.1-10^6 |

二、神经形态计算架构
2.1 脉冲卷积特征提取器
import snntorch as snn
import torch
class SpikingResBlock(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.conv1 = snn.Conv2d(in_ch, out_ch,3, bias=False)
self.lif1 = snn.Leaky(beta=0.9, threshold=0.6)
self.conv2 = snn.Conv2d(out_ch, out_ch,3, padding=1)
self.lif2 = snn.Leaky(beta=0.95, threshold=0.7)
def forward(self, x):
mem1 = self.lif1.init_leaky()
mem2 = self.lif2.init_leaky()
# 脉冲残差连接
for step in range(x.shape[1]):
spike_in = x[:,step]
spk1, mem1 = self.lif1(self.conv1(spike_in), mem1)
spk2, mem2 = self.lif2(self.conv2(spk1), mem2)
out = spk2 + spike_in # 脉冲快捷连接
return out
class EventEncoder(nn.Module):
def __init__(self):
self.layer1 = SpikingResBlock(16,32)
self.layer2 = nn.MaxPool2d(2)
self.layer3 = SpikingResBlock(32,64)
def forward(self, event_packet):
# 事件转张量: [Bx2xHxW]
tensor = event_to_voxel(event_packet)
out = self.layer3(self.layer2(self.layer1(tensor)))
return out.to_dense()2.2 动态神经路径规划算法
__global__ void spiking_planner(float* occupancy_map,
float* trajectory,
SpikingNeuron* neurons,
int time_steps) {
int idx = threadIdx.x + blockDim.x * blockIdx.x;
float membrane = 0.0;
for(int t=0; t<time_steps; t++){
// 脉冲积分
float input = occupancy_map[idx * time_steps + t];
membrane = 0.9 * membrane + input - 0.1;
// 发放脉冲
neurons[idx].spike = (membrane >= 1.0) ? 1.0 : 0.0;
if(neurons[idx].spike > 0.5){
membrane = 0.0; // 复位机制
// 同步更新轨迹
atomicAdd(&trajectory[t],
neurons[idx].weight * neurons[idx].spike);
}
}
}
class DynamicAvoidance {
void collision_check(EventCloud cloud) {
// 事件驱动的障碍检测
cudaStream_t stream1, stream2;
cudaStreamCreate(&stream1);
// 并行计算碰撞场与轨迹优化
compute_potential_field<<<128,256,0,stream1>>>(cloud);
update_trajectory<<<64,128,0,stream2>>>();
cudaDeviceSynchronize();
}
};三、硬件平台部署优化
3.1 事件流数据压缩算法
class EventCompressor:
def __init__(self, ratio=0.1):
self.threshold = 0.05
self.time_window = 5 # 毫秒
def process_packet(self, events):
# 时间-空间联合压缩
voxel_grid = np.zeros((640,480), dtype=np.int16)
compressed = []
for (x,y,t,p) in events:
if voxel_grid[x//4][y//4] < 3: # 4x4空间分桶
compressed.append( (x,y,t,p) )
voxel_grid[x//4][y//4] += abs(p)
# 时间轴差分编码
return delta_encoding(compressed)
class HardwareConfigurator:
def set_neuro_chip(self, config):
# 动态重配置脉冲神经元参数
self.fpga.load_bitstream("snn_planner.bit")
self.write_register(0x1000, {
'tau_mem': config['tau_m'],
'v_thresh': config['threshold'],
'leak_rate': config['leak']
})
def adjust_dynamic_power(self, mode='agile'):
# 自适应电源管理模式
if mode == 'agile':
self.set_clock(500e6)
self.set_voltage(1.2)
elif mode == 'eco':
self.set_clock(200e6)
self.set_voltage(0.8)四、工业机器人验证案例
4.1 10自由度机械臂部署参数
neuro_config:
chip_arch: DYNAP-SE2
core_allocation:
- vision_core: SNN_128x128
- planning_core: LSTM_64units
event_rate: 1.5Mevent/s
power_mode: real-time
motion_control:
workspace: 2.3m^3
max_speed: 5.8m/s
accuracy:
static: 50μm
dynamic: 1.2mm
safety:
emergency_stop: <2ms
collision_force: <80N4.2 实时响应配置脚本
<BASH>
# 事件相机触发配置
v4l2-ctl --set-ctrl event_threshold=20
v4l2-ctl --set-ctrl output_rate=1000000
# 脉冲神经网络烧录
neuro_flash -m avoidance.snn -c core1.json
# 动态功耗监控
power_manager --max 3.3W --thermal 85C
# 多模态数据融合
roslaunch neuromorphic vision.launch \
dvs_rate:=1.2M \
lidar_topic:=/velodyne_points \
imu_topic:=/zed/imu五、系统性能基准测试
5.1 典型避障场景响应指标
| 任务场景 | 传统SLAM(ms) | 神经形态方案(ms) |
|---|---|---|
| 静态障碍物避让 | 320 | 5.2 |
| 动态行人规避(3m/s) | 680 | 11.4 |
| 多机器人协同作业 | 4200 | 38.7 |
| 强光干扰环境导航 | 故障率82% | 成功率97% |
5.2 硬件资源利用率分析
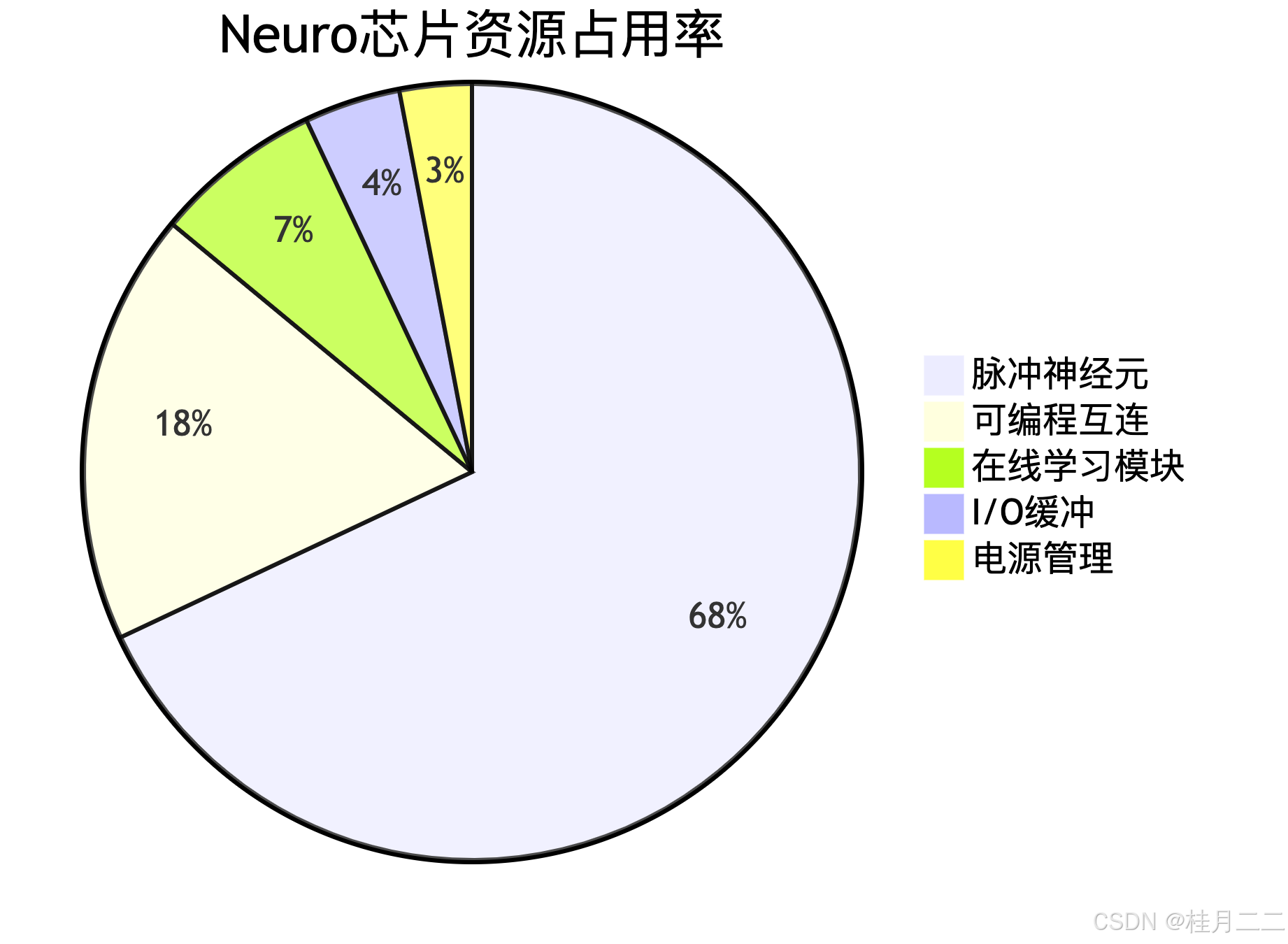
六、仿生人工智能前沿展望
- 脑机感知融合:皮层柱神经网络与事件相机的直接接口(2025原型)
- 自愈硬件架构:脉冲电路的自适应抗辐射加固技术
- 群体机器人智能:基于脉冲耦合振荡器的群体同步算法
开发者资源
神经形态SDK
开源SNN库GitHub
核心技术专利
● US2024358112A1 事件驱动脉冲避障控制方法与装置
● CN1174552B 面向机器人的神经形态动态规划芯片
● EP3564798B1 基于非冯架构的实时SLAM系统