目录
前言
在当今的数据驱动时代,抓取大量评论数据能够为消费者提供决策参考,也为商家和研究人员提供了有价值的信息。在这篇文章中,我们将详细讲解如何使用 Python 爬取京东商城某商品的评论数据,包括评论内容、时间和评分,目标是提取不少于 100 条评论数据。
1. 爬取目标
我们的目标是从京东商城爬取特定商品的评论数据。具体要求如下:
-
评论内容:用户对该商品的具体评价。
-
评论时间:用户发布评论的时间。
-
评分:用户给该商品的评分。
我们将以某一款京东商城的产品为例,示范如何使用 Python 爬取其评论数据。
2. 所涉及知识点
为了完成这项任务,我们将涉及以下几个关键知识点:
-
HTTP 请求:了解如何使用
requests库进行网络请求。 -
JSON 数据解析:京东的评论接口返回 JSON 格式的数据(通过 Ajax),我们需要掌握如何解析 JSON 数据。
-
数据 Pandas 操作:使用
pandas库来处理和存储数据。 -
异常处理:保障程序在运行中的稳定性和鲁棒性。
-
基本的 Python 编程:编写和调试 Python 代码的基本技能。
3. 步骤分析
3.1 准备工作
在开始之前,请确保你已安装以下 Python 库。可以通过以下命令安装:
pip install requests pandas
3.2 分析京东评论接口
我们需要先访问京东商品评论的接口,分析返回的数据格式。以某款商品的评论为例(如“华为 Mate 40 Pro”):
评论的 API 地址通常是:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=商品ID&pageSize=10&score=0&sortType=5&isShadowSku=0&fold=1
其中的 productId 是该商品的 ID,pageSize 控制每次请求返回的评论数量。
3.3 发送 HTTP 请求获取评论
利用 requests 库向 API 发送请求获取评论数据并解析 JSON。
以下是代码示例,用于获取和解析评论:
import requests
import pandas as pd
import json
import time
def get_comments(product_id, page):
"""获取指定商品分页的评论数据"""
url = f'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={product_id}&pageSize=10&score=0&sortType=5&isShadowSku=0&fold=1&page={page}'
# 发送请求
try:
response = requests.get(url)
content = response.text.strip('fetchJSON_comment98();') # 去掉callback函数名称
comments_data = json.loads(content) # 解析 JSON 数据
return comments_data
except Exception as e:
print(f"请求错误: {e}")
return None
# 示例商品ID
product_id = '100012043978' # 以某款商品 ID 为例
# 初始化一个空列表,用于存储评论
all_comments = []
# 爬取前 10 页的评论
for page in range(1, 11):
comments_data = get_comments(product_id, page)
if comments_data:
for comment in comments_data['comments']:
all_comments.append({
'内容': comment['content'],
'时间': comment['creationTime'],
'评分': comment['score']
})
# 控制请求频率,避免被封
time.sleep(1)
# 输出爬取的评论数
print(f"成功爬取 {len(all_comments)} 条评论")
这段代码定义了 get_comments 函数,通过拼接 API 地址和指定的 product_id 和页码来获取评论数据,并在每次请求之间暂停 1 秒,以避免被封。
3.4 数据处理与存储
获得评论数据后,我们可以利用 pandas 库将其存储到 CSV 文件中,以便后续分析或者导出。
# 将爬取到的所有评论转换为 DataFrame
comments_df = pd.DataFrame(all_comments)
# 存储到 CSV 文件
comments_df.to_csv('jd_comments.csv', index=False, encoding='utf-8-sig')
print("评论数据已成功保存到 jd_comments.csv 文件中!")
在这段代码中,我们将评论数据转化为 DataFrame 格式,并使用 to_csv 方法将其保存为 CSV 文件。
4. 爬取结果
成功执行上述代码后,你将在当前目录下找到一个名为 jd_comments.csv 的文件,其中包含了抓取的京东商品评论数据。以下是 CSV 文件的一部分示例内容:

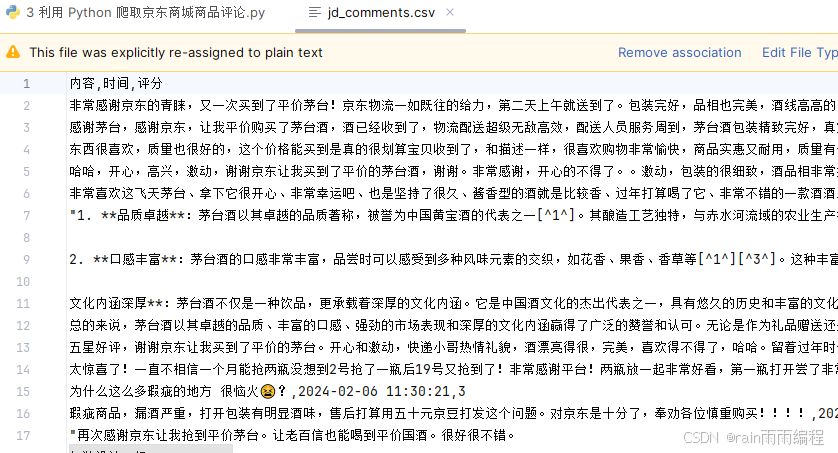
如表所示,我们能够分别提取到评论内容、评论时间和评分。这将为商品分析及市场研究提供必要的信息。
5. 完整代码
下面是完整的代码,将之前的步骤整合在一起,方便大家直接运行:
import requests
import pandas as pd
import json
import time
def get_comments(product_id, page):
"""获取指定商品分页的评论数据"""
url = f'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={product_id}&pageSize=10&score=0&sortType=5&isShadowSku=0&fold=1&page={page}'
# 发送请求
try:
response = requests.get(url)
content = response.text.strip('fetchJSON_comment98();') # 去掉callback函数名称
comments_data = json.loads(content) # 解析 JSON 数据
return comments_data
except Exception as e:
print(f"请求错误: {e}")
return None
# 示例商品ID(替换为具体商品的ID)
product_id = '100012043978' # 以某款商品 ID 为例
# 初始化一个空列表,用于存储评论
all_comments = []
# 爬取前 10 页的评论
for page in range(1, 11):
comments_data = get_comments(product_id, page)
if comments_data:
for comment in comments_data['comments']:
all_comments.append({
'内容': comment['content'],
'时间': comment['creationTime'],
'评分': comment['score']
})
# 控制请求频率,避免被封
time.sleep(1)
# 输出爬取的评论数
print(f"成功爬取 {len(all_comments)} 条评论")
# 将爬取到的所有评论转换为 DataFrame
comments_df = pd.DataFrame(all_comments)
# 存储到 CSV 文件
comments_df.to_csv('jd_comments.csv', index=False, encoding='utf-8-sig')
print("评论数据已成功保存到 jd_comments.csv 文件中!")
总结
通过本项目,我们成功爬取了京东商城某商品的评论数据,并将其保存为 CSV 文件。这一过程展示了如何与网络接口交互、解析数据、以及将数据存储到本地。在未来的实际应用中,我们可以进一步分析爬取的数据,提取用户的偏好和趋势,帮助消费者更好地做出购买决策。
希望本文可以帮助你理解如何使用 Python 进行网页数据爬取。如果你对爬虫技术感兴趣,欢迎大家深入学习,探索更多有趣的项目!
文章持续跟新,可以微信搜一搜公众号 [ rain雨雨编程 ],或扫描下方二维码,第一时间阅读,涉及爬虫,机器学习,Java编程,实战项目等。
