首先可能是数据入重复了
检查一下看看是否入库前删除了分区的数据,可能是重复数据入库的问题,如果不是这个那么继续排查。
入库的数据有问题,检测方法
如果报主键冲突了,则group by 一下id,date,然后select 的时候加一个count(1) >1,语句如下
- Select * from (Select id,date,count(1) cnt from table1 group by id) where cnt >1
- 这样基本上就能定位到哪些数据重复了
- 原因的话要不就是你没去重,
- 否则就是你的明细数据关联的时候关联错了,然后再一步一步检查入库数据的关联逻辑什么的,视情况而定
基本上我就是这么解决的。其他的暂时还没遇到过
解决办法1:
我造了三条数据,以此演示一下
import org.apache.spark.sql.SparkSession
object primaryKeyDistinct {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("isNull96PointStat")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val data = Seq(
(16, 18, 187),
(16, 18, 182),
(15, 14, 172),
(14, 16, 198)
).toDF("Id", "Age", "Height")
// 去除重复行,保留一条
val result = data.dropDuplicates("Id")
result.show()
}
}
结果展示
基本上对这个id的去重就ok,视情况而定,我的数据是建立在id这一列,id,对应的后续的其他数据都是一样的,所以我可以这么整
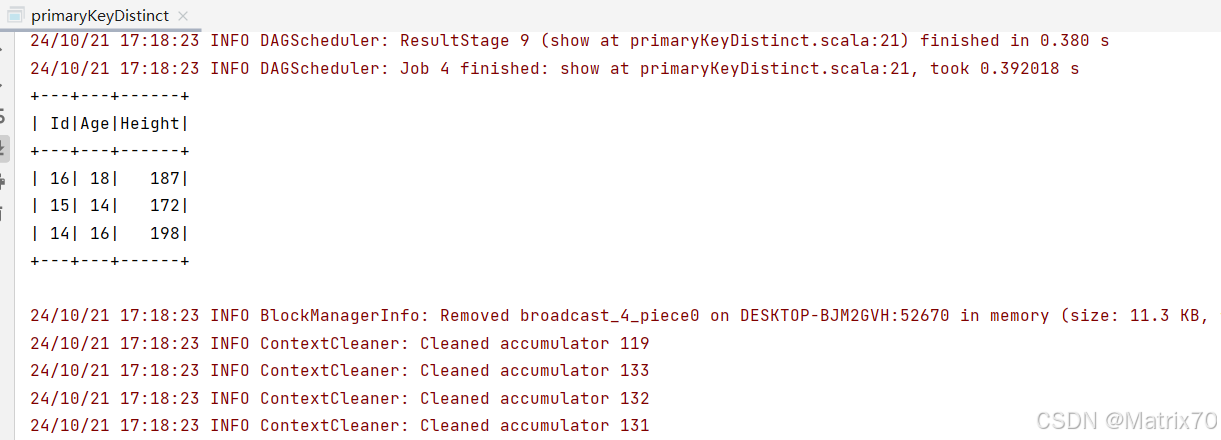
当然,我这个是只以id为主键的,如果你还想保留height,那就是要把id+height作为主键搞。
主一开始表不是我建的,数模也没有标识才造成我这个问题。
解决办法2
另外如果可以避免的话,可以聚合之后取出计算列的最大值,max(),然后再去重即可
以上是我自己的一些经验之谈