深度学习 Day 30——YOLOv5-C3模块实现
文章目录
一、前言

本期博客我们将利用YOLOv5算法中的C3模块搭建网络,了解学习一下C3的结构,方便后续我们的YOLOv5算法的学习,并在最后我们尝试增加C3模块来进行训练模型,看看准确率是否增加了。
二、我的环境
print("============查看GPU信息================")
# 查看GPU信息
!/opt/bin/nvidia-smi
print("==============查看pytorch版本==============")
# 查看pytorch版本
import torch
print(torch.__version__)
print("============查看虚拟机硬盘容量================")
# 查看虚拟机硬盘容量
!df -lh
print("============查看cpu配置================")
# 查看cpu配置
!cat /proc/cpuinfo | grep model\ name
print("=============查看内存容量===============")
# 查看内存容量
!cat /proc/meminfo | grep MemTotal
============查看GPU信息================
Tue Apr 4 07:08:04 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 43C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
==============查看pytorch版本==============
2.0.0+cu118
============查看虚拟机硬盘容量================
Filesystem Size Used Avail Use% Mounted on
overlay 79G 27G 53G 34% /
tmpfs 64M 0 64M 0% /dev
shm 5.7G 0 5.7G 0% /dev/shm
/dev/root 2.0G 1.1G 841M 58% /usr/sbin/docker-init
tmpfs 6.4G 88K 6.4G 1% /var/colab
/dev/sda1 78G 46G 32G 59% /opt/bin/.nvidia
tmpfs 6.4G 0 6.4G 0% /proc/acpi
tmpfs 6.4G 0 6.4G 0% /proc/scsi
tmpfs 6.4G 0 6.4G 0% /sys/firmware
drive 15G 0 15G 0% /content/drive
============查看cpu配置================
model name : Intel(R) Xeon(R) CPU @ 2.00GHz
model name : Intel(R) Xeon(R) CPU @ 2.00GHz
=============查看内存容量===============
MemTotal: 13297200 kB
三、数据处理
1、导入依赖项设置GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warnings
import random
warnings.filterwarnings('ignore')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
device(type='cuda')
2、导入数据
这里我们导入的是之前天气识别的数据集。
data_dir = '/content/drive/Othercomputers/我的笔记本电脑/深度学习/data/weather_photos'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split('/')[8] for path in data_paths]
classeNames
['cloudy', 'rain', 'shine', 'sunrise']
3、数据转换
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(data_dir, transform=train_transforms)
total_data
Dataset ImageFolder
Number of datapoints: 1125
Root location: /content/drive/Othercomputers/我的笔记本电脑/深度学习/data/weather_photos
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=warn)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
total_data.class_to_idx
{'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3}
4、划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset
(<torch.utils.data.dataset.Subset at 0x7f93a0387fa0>,
<torch.utils.data.dataset.Subset at 0x7f93a0387d00>)
batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=1)
5、查看数据信息
for x, y in test_dl:
print("Shape of x [N, C, H, W]:", x.shape)
print("Shape of y:", y.shape, y.dtype)
break
Shape of x [N, C, H, W]: torch.Size([4, 3, 224, 224])
Shape of y: torch.Size([4]) torch.int64
四、搭建包含YOLOv5-C3模块的模型
1、搭建模型
import torch.nn.functional as F
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class model_B(nn.Module):
def __init__(self):
super(model_B, self).__init__()
# 卷积模块
self.Conv = Conv(3, 32, 3, 2)
# C3模块1
self.C3_1 = C3(32, 64, 3, 2)
# 全连接网络层,用于分类
self.classifier = nn.Sequential(
nn.Linear(in_features=802816, out_features=100),
nn.ReLU(),
nn.Linear(in_features=100, out_features=4)
)
def forward(self, x):
x = self.Conv(x)
x = self.C3_1(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = model_B().to(device)
model
Using cuda device
model_B(
(Conv): Conv(
(conv): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_1): C3(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(classifier): Sequential(
(0): Linear(in_features=802816, out_features=100, bias=True)
(1): ReLU()
(2): Linear(in_features=100, out_features=4, bias=True)
)
)
2、查看模型参数
# 查看模型参数
for name, param in model.named_parameters():
print(name, '\t', param.shape)
Conv.conv.weight torch.Size([32, 3, 3, 3])
Conv.bn.weight torch.Size([32])
Conv.bn.bias torch.Size([32])
C3_1.cv1.conv.weight torch.Size([32, 32, 1, 1])
C3_1.cv1.bn.weight torch.Size([32])
C3_1.cv1.bn.bias torch.Size([32])
C3_1.cv2.conv.weight torch.Size([32, 32, 1, 1])
C3_1.cv2.bn.weight torch.Size([32])
C3_1.cv2.bn.bias torch.Size([32])
C3_1.cv3.conv.weight torch.Size([64, 64, 1, 1])
C3_1.cv3.bn.weight torch.Size([64])
C3_1.cv3.bn.bias torch.Size([64])
C3_1.m.0.cv1.conv.weight torch.Size([32, 32, 1, 1])
C3_1.m.0.cv1.bn.weight torch.Size([32])
C3_1.m.0.cv1.bn.bias torch.Size([32])
C3_1.m.0.cv2.conv.weight torch.Size([32, 32, 3, 3])
C3_1.m.0.cv2.bn.weight torch.Size([32])
C3_1.m.0.cv2.bn.bias torch.Size([32])
C3_1.m.1.cv1.conv.weight torch.Size([32, 32, 1, 1])
C3_1.m.1.cv1.bn.weight torch.Size([32])
C3_1.m.1.cv1.bn.bias torch.Size([32])
C3_1.m.1.cv2.conv.weight torch.Size([32, 32, 3, 3])
C3_1.m.1.cv2.bn.weight torch.Size([32])
C3_1.m.1.cv2.bn.bias torch.Size([32])
C3_1.m.2.cv1.conv.weight torch.Size([32, 32, 1, 1])
C3_1.m.2.cv1.bn.weight torch.Size([32])
C3_1.m.2.cv1.bn.bias torch.Size([32])
C3_1.m.2.cv2.conv.weight torch.Size([32, 32, 3, 3])
C3_1.m.2.cv2.bn.weight torch.Size([32])
C3_1.m.2.cv2.bn.bias torch.Size([32])
classifier.0.weight torch.Size([100, 802816])
classifier.0.bias torch.Size([100])
classifier.2.weight torch.Size([4, 100])
classifier.2.bias torch.Size([4])
3、查看模型详情
import torchsummary as summary
summary.summary(model, (3, 224, 224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 112, 112] 864
BatchNorm2d-2 [-1, 32, 112, 112] 64
SiLU-3 [-1, 32, 112, 112] 0
Conv-4 [-1, 32, 112, 112] 0
Conv2d-5 [-1, 32, 112, 112] 1,024
BatchNorm2d-6 [-1, 32, 112, 112] 64
SiLU-7 [-1, 32, 112, 112] 0
Conv-8 [-1, 32, 112, 112] 0
Conv2d-9 [-1, 32, 112, 112] 1,024
BatchNorm2d-10 [-1, 32, 112, 112] 64
SiLU-11 [-1, 32, 112, 112] 0
Conv-12 [-1, 32, 112, 112] 0
Conv2d-13 [-1, 32, 112, 112] 9,216
BatchNorm2d-14 [-1, 32, 112, 112] 64
SiLU-15 [-1, 32, 112, 112] 0
Conv-16 [-1, 32, 112, 112] 0
Bottleneck-17 [-1, 32, 112, 112] 0
Conv2d-18 [-1, 32, 112, 112] 1,024
BatchNorm2d-19 [-1, 32, 112, 112] 64
SiLU-20 [-1, 32, 112, 112] 0
Conv-21 [-1, 32, 112, 112] 0
Conv2d-22 [-1, 32, 112, 112] 9,216
BatchNorm2d-23 [-1, 32, 112, 112] 64
SiLU-24 [-1, 32, 112, 112] 0
Conv-25 [-1, 32, 112, 112] 0
Bottleneck-26 [-1, 32, 112, 112] 0
Conv2d-27 [-1, 32, 112, 112] 1,024
BatchNorm2d-28 [-1, 32, 112, 112] 64
SiLU-29 [-1, 32, 112, 112] 0
Conv-30 [-1, 32, 112, 112] 0
Conv2d-31 [-1, 32, 112, 112] 9,216
BatchNorm2d-32 [-1, 32, 112, 112] 64
SiLU-33 [-1, 32, 112, 112] 0
Conv-34 [-1, 32, 112, 112] 0
Bottleneck-35 [-1, 32, 112, 112] 0
Conv2d-36 [-1, 32, 112, 112] 1,024
BatchNorm2d-37 [-1, 32, 112, 112] 64
SiLU-38 [-1, 32, 112, 112] 0
Conv-39 [-1, 32, 112, 112] 0
Conv2d-40 [-1, 64, 112, 112] 4,096
BatchNorm2d-41 [-1, 64, 112, 112] 128
SiLU-42 [-1, 64, 112, 112] 0
Conv-43 [-1, 64, 112, 112] 0
C3-44 [-1, 64, 112, 112] 0
Linear-45 [-1, 100] 80,281,700
ReLU-46 [-1, 100] 0
Linear-47 [-1, 4] 404
================================================================
Total params: 80,320,536
Trainable params: 80,320,536
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 150.06
Params size (MB): 306.40
Estimated Total Size (MB): 457.04
----------------------------------------------------------------
五、训练模型
1、训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
2、测试函数
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
3、正式训练
import copy
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# 保存最佳模型到 best_model
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
print('Done')
Epoch: 1, Train_acc:64.2%, Train_loss:1.410, Test_acc:81.3%, Test_loss:0.953, Lr:1.00E-04
Epoch: 2, Train_acc:83.4%, Train_loss:0.539, Test_acc:85.3%, Test_loss:0.424, Lr:1.00E-04
Epoch: 3, Train_acc:92.2%, Train_loss:0.234, Test_acc:83.6%, Test_loss:0.525, Lr:1.00E-04
Epoch: 4, Train_acc:93.3%, Train_loss:0.181, Test_acc:88.9%, Test_loss:0.373, Lr:1.00E-04
Epoch: 5, Train_acc:95.8%, Train_loss:0.128, Test_acc:85.3%, Test_loss:0.517, Lr:1.00E-04
Epoch: 6, Train_acc:97.6%, Train_loss:0.076, Test_acc:89.3%, Test_loss:0.494, Lr:1.00E-04
Epoch: 7, Train_acc:97.1%, Train_loss:0.121, Test_acc:85.8%, Test_loss:0.610, Lr:1.00E-04
Epoch: 8, Train_acc:98.1%, Train_loss:0.065, Test_acc:82.7%, Test_loss:0.842, Lr:1.00E-04
Epoch: 9, Train_acc:98.0%, Train_loss:0.070, Test_acc:85.8%, Test_loss:0.517, Lr:1.00E-04
Epoch:10, Train_acc:98.6%, Train_loss:0.071, Test_acc:88.9%, Test_loss:0.483, Lr:1.00E-04
Epoch:11, Train_acc:97.8%, Train_loss:0.073, Test_acc:87.6%, Test_loss:0.516, Lr:1.00E-04
Epoch:12, Train_acc:99.2%, Train_loss:0.018, Test_acc:88.4%, Test_loss:0.492, Lr:1.00E-04
Epoch:13, Train_acc:98.9%, Train_loss:0.041, Test_acc:85.8%, Test_loss:0.593, Lr:1.00E-04
Epoch:14, Train_acc:99.6%, Train_loss:0.008, Test_acc:88.0%, Test_loss:0.497, Lr:1.00E-04
Epoch:15, Train_acc:99.8%, Train_loss:0.006, Test_acc:90.2%, Test_loss:0.495, Lr:1.00E-04
Epoch:16, Train_acc:99.1%, Train_loss:0.032, Test_acc:83.1%, Test_loss:0.661, Lr:1.00E-04
Epoch:17, Train_acc:99.0%, Train_loss:0.033, Test_acc:82.7%, Test_loss:0.715, Lr:1.00E-04
Epoch:18, Train_acc:98.7%, Train_loss:0.051, Test_acc:88.4%, Test_loss:0.599, Lr:1.00E-04
Epoch:19, Train_acc:98.8%, Train_loss:0.042, Test_acc:81.3%, Test_loss:1.786, Lr:1.00E-04
Epoch:20, Train_acc:98.7%, Train_loss:0.037, Test_acc:90.7%, Test_loss:0.586, Lr:1.00E-04
Done
六、训练可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
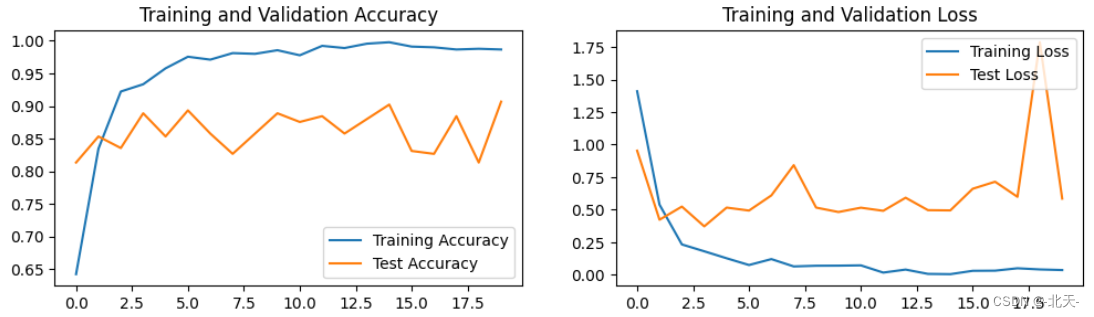
七、评估模型
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
print('Test_acc:{:.1f}%, Test_loss:{:.3f}'.format(epoch_test_acc*100, epoch_test_loss))
Test_acc:90.7%, Test_loss:0.586
八、预测
# 从文件中加载模型参数
PATH = './best_model.pth'
model.load_state_dict(torch.load(PATH))
# 预测
def predict(model, dataloader):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
model.eval()
epoch_test_acc, epoch_test_loss = predict(model, test_dl)
print('Test_acc:{:.1f}%, Test_loss:{:.3f}'.format(epoch_test_acc*100, epoch_test_loss))
Test_acc:90.7%, Test_loss:0.628
九、如何通过增加或者调整C3模块与Conv模块来提高准确率?
要通过调整 C3 和 Conv 模块来提高模型的准确性,可以尝试以下操作:
- 增加 C3 模块的数量:C3 模块是具有三个卷积的瓶颈块。增加网络中 C3 模块的数量有助于捕获更复杂的特征并提高模型的准确性。
- 增加Conv模块中的通道数:Conv模块是一个标准的卷积层。增加该层的输出通道数量可以帮助网络学习更复杂的特征并提高准确性。
- 调整Conv模块中的kernel size和stride:可以调整Conv模块的kernel size和stride来改变卷积层的感受野。增加内核大小和减小步幅可以帮助网络捕获更多全局特征,而减小内核大小和增加步幅可以帮助网络捕获更多局部特征。
- 调整C3模块中的扩展率和瓶颈块数量:C3模块包含多个瓶颈块,每个瓶颈块的扩展率决定了隐藏层的通道数。增加扩展率可以帮助网络学习更复杂的特征,而增加瓶颈块的数量可以帮助加深网络并提高其准确性。
- 添加正则化技术:正则化技术(例如 dropout 或权重衰减)可以帮助防止过度拟合并提高模型的泛化性能。可以尝试将这些技术添加到模型中以提高其准确性。
我试着采取第一种方法增加C3模块,然后出现类似这种报错:
RuntimeError: mat1 and mat2 shapes cannot be multiplied (4x6422528 and 25088x100)
这个错误消息表明模型中某一层的输入和输出之间存在大小不匹配。具体来说,根据报错信息,是全连接层的输入大小不匹配,需要调整全连接层的输入大小,使其与输入张量的大小匹配。具体而言,需要将输入层的输入大小从 in_features=512*16*16 修改为 in_features=512*7*7,然后在全连接层之前添加一个平均池化层,将张量的高度和宽度减小到 7,即:
class model_B(nn.Module):
def __init__(self):
super(model_B, self).__init__()
# 卷积模块
self.Conv = Conv(3, 32, 3, 2)
# C3模块1
self.C3_1 = C3(32, 64, 3, 2)
# Add more C3 modules
self.C3_2 = C3(64, 128, 3, 2)
self.C3_3 = C3(128, 256, 3, 2)
self.C3_4 = C3(256, 512, 3, 2)
# 全连接网络层,用于分类
self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) # 添加平均池化层
self.classifier = nn.Sequential(
nn.Linear(in_features=512*7*7, out_features=100),
nn.ReLU(),
nn.Linear(in_features=100, out_features=4)
)
def forward(self, x):
x = self.Conv(x)
x = self.C3_1(x)
x = self.C3_2(x)
x = self.C3_3(x)
x = self.C3_4(x)
x = self.avgpool(x) # 平均池化
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
修改之后该模型的结构为:
Using cuda device
model_B(
(Conv): Conv(
(conv): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_1): C3(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(C3_2): C3(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(C3_3): C3(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(C3_4): C3(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=100, bias=True)
(1): ReLU()
(2): Linear(in_features=100, out_features=4, bias=True)
)
)
但是再后续训练阶段又报如下错误:
OutOfMemoryError: CUDA out of memory.
这个错误信息是我们的模型使用了过多的显存,导致 CUDA 内存不足。这可能是由于模型或批次大小过大导致的。为了解决这个问题,我们可以尝试减小模型的大小或减小批次大小。
然后我修改了 train_dl 和 test_dl 的批次大小
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=4, pin_memory=True)
test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=2, shuffle=False, num_workers=4, pin_memory=True)
如果你按照我的修改之后还是出现 CUDA 内存不足的错误,可以考虑减小模型的大小,可以尝试删除一些 C3 模块或减小它们的输出通道数,以减小模型的大小,或者尝试使用更小的批次大小或在训练时使用梯度累加来减小显存的使用量。梯度累加是指将多个小批次的梯度累加起来,再进行一次参数更新,从而达到与使用大批次相同的效果。
例如将 train() 函数中的梯度更新改为:
optimizer.zero_grad() # 清空梯度
for xb, yb in train_dl:
xb, yb = xb.to(device), yb.to(device)
output = model(xb)
loss = loss_fn(output, yb) / len(train_dl) # 将损失除以批次数,相当于梯度平均
loss.backward()
optimizer.step() # 更新参数
这样,每个小批次的梯度都将累加起来,等到累加的梯度总数达到批次大小时再进行一次参数更新。这样可以减小显存的使用量,但会增加训练时间。
如果上述方法都没有解决可以自行去网上搜索一下解决办法,例如去Stack Overflow等平台看看。
没有报错之后,我们再次进行模型训练,发现训练的时间很明显的增加了,在epochs = 20的基础上模型一共训练了23分钟多,比之前的训练时间长了不少,下面是模型的训练结果:
Epoch: 1, Train_acc:62.9%, Train_loss:0.918, Test_acc:72.9%, Test_loss:0.689, Lr:1.00E-04
Epoch: 2, Train_acc:76.6%, Train_loss:0.582, Test_acc:85.3%, Test_loss:0.388, Lr:1.00E-04
Epoch: 3, Train_acc:80.4%, Train_loss:0.458, Test_acc:85.8%, Test_loss:0.414, Lr:1.00E-04
Epoch: 4, Train_acc:84.1%, Train_loss:0.400, Test_acc:85.3%, Test_loss:0.372, Lr:1.00E-04
Epoch: 5, Train_acc:86.8%, Train_loss:0.336, Test_acc:88.4%, Test_loss:0.301, Lr:1.00E-04
Epoch: 6, Train_acc:90.3%, Train_loss:0.257, Test_acc:79.1%, Test_loss:0.522, Lr:1.00E-04
Epoch: 7, Train_acc:90.9%, Train_loss:0.246, Test_acc:86.2%, Test_loss:0.428, Lr:1.00E-04
Epoch: 8, Train_acc:92.0%, Train_loss:0.219, Test_acc:88.9%, Test_loss:0.420, Lr:1.00E-04
Epoch: 9, Train_acc:94.1%, Train_loss:0.167, Test_acc:87.6%, Test_loss:0.593, Lr:1.00E-04
Epoch:10, Train_acc:92.2%, Train_loss:0.199, Test_acc:83.1%, Test_loss:0.657, Lr:1.00E-04
Epoch:11, Train_acc:95.2%, Train_loss:0.135, Test_acc:89.3%, Test_loss:0.391, Lr:1.00E-04
Epoch:12, Train_acc:96.2%, Train_loss:0.121, Test_acc:83.6%, Test_loss:0.515, Lr:1.00E-04
Epoch:13, Train_acc:95.1%, Train_loss:0.132, Test_acc:85.8%, Test_loss:0.565, Lr:1.00E-04
Epoch:14, Train_acc:97.0%, Train_loss:0.090, Test_acc:88.9%, Test_loss:0.529, Lr:1.00E-04
Epoch:15, Train_acc:97.0%, Train_loss:0.082, Test_acc:88.4%, Test_loss:0.559, Lr:1.00E-04
Epoch:16, Train_acc:96.7%, Train_loss:0.101, Test_acc:91.1%, Test_loss:0.415, Lr:1.00E-04
Epoch:17, Train_acc:97.9%, Train_loss:0.055, Test_acc:88.4%, Test_loss:0.665, Lr:1.00E-04
Epoch:18, Train_acc:96.1%, Train_loss:0.092, Test_acc:86.7%, Test_loss:0.706, Lr:1.00E-04
Epoch:19, Train_acc:97.6%, Train_loss:0.067, Test_acc:91.1%, Test_loss:0.312, Lr:1.00E-04
Epoch:20, Train_acc:98.8%, Train_loss:0.047, Test_acc:87.1%, Test_loss:0.545, Lr:1.00E-04
Done
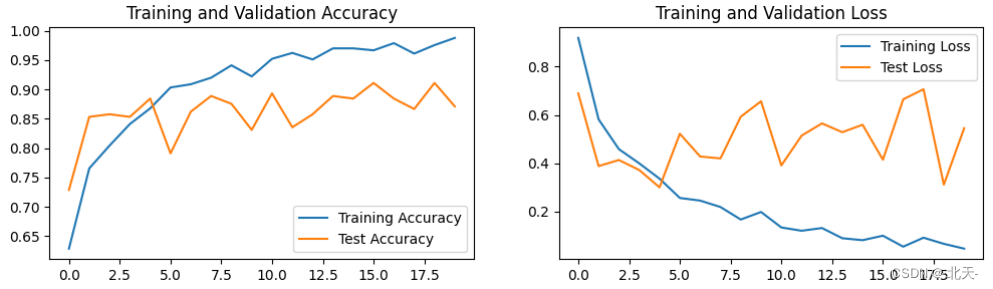
Test_acc:91.1%, Test_loss:0.415
可以看出我们在牺牲训练时间的基础上准确率只是提高了一点点,所以我的调整应该不太好,如果你有更好的方法可以告诉我。