1.先前工作存在的问题
作者认为,在这篇论文之前的基于神经隐式表达的稠密视觉SLAM系统大多数要么依赖 RGB-D 传感器,要么需要单独的单目 SLAM 方法进行相机跟踪,并且不能产生高保真密集 3D 场景重建。之所以强调不能依赖RGB-D相机,是因为基于RGB-D相机的系统在室外场景或深度传感器不可用时会失效。同时,对于未观察到的区域,他们很难做出合理的几何估计。当然也存在少数仅用RGB信息来进行相机位姿追踪和神经隐式建图的SLAM系统,但是它们的跟踪和建图流程彼此独立,因为它们依赖于不同的场景表示(比如可能跟踪用SDF表示场景,建图用MLP神经隐式场表示场景)来完成这些任务。
2.作者解决上述问题的思路
我们能否构建一个具有神经隐式场景表示的统一密集 SLAM 系统,用于单目RGB的跟踪和建图?也就是说,作者想用输入的RGB信息监督训练得到一个神经隐式表示(建图过程),并用建得的地图直接来优化相机位姿。
3.在这篇论文中,作者主要干了什么事
①构建了一种基于隐式的稠密RGB SLAM系统,它可以针对建图和跟踪进行端到端优化,并且还能够学习准确的场景表示以进行新视图合成(合成在训练时没采用过的视图)。
②对于场景几何和颜色,作者提出从粗到细的分层特征网格来对符号距离函数 (SDF) 进行建模。
③作者在系统的损失函数中添加了用于监督的附加损失项,包括易于获得的单目几何线索和光流,并且还引入了简单的扭曲损失以进一步增强几何一致性。
④改进了将SDF值映射到体密度的函数,以适应大场景建图。
暂时看不懂不要紧,之后会详细阐述。
4.核心内容概述
①分层神经隐式表示:
作者将场景的颜色和几何特征拆分开来表示。也就是说,这个系统中有两个分层神经隐式网格,一个用来表示颜色特征,一个用来表示几何特征,但是这两个分层神经隐式网格的层数、分辨率以及特征维数是不一样的。
首先来看看“几何分层神经隐式网格”的粗级表示。 粗级几何表示的目标是有效地对粗场景几何(不捕获几何细节)和场景布局(例如墙壁、地板)进行建模,用分辨率为 32 × 32 × 32 的密集体素网格表示场景,每个体素中都有一个 32 维的特征。当我们有一个三维坐标x时,找到与这个坐标最近的几个体素网格,用这几个体素网格的特征插值得到x的32维特征,再将x进行位置编码和32维特征拼接后送入一个小的MLP解码网络,即可得到SDF值(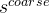
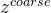
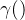
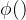
再来看看“几何分层神经隐式网格”的精细级表示。虽然可以通过我们的粗级表示来获得粗略几何形状,但捕获场景中的高频几何细节非常重要(这就需要网格的分辨率小一点)。精细级表示有好几层,用L表示层的数量,每一层的分辨率的计算公式为,其中
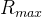
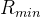
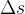
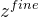
最后来聊“颜色分层神经隐式网格”。颜色表示也分层,但是并不像几何表示那些有两个MLP解码器,颜色表示只有一个MLP解码器,这个解码器以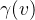
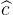
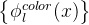
其中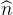
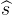
②改进体渲染
熟悉NeRF的朋友肯定知道,体渲染需要从MLP中预测一个“体密度”来计算三维坐标点的透明度。但是从上述描述的MLP(有三个MLP输出)的输出来看都没有“体密度”这一值,只有SDF值
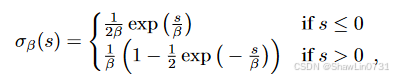
这个公式就是将
所以作者提出,可以为每一个体素维护一个计数器来存储建图过程中体素内采样点的个数。并用这个数
其中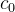
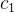
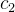
有了体密度之后就可以用来渲染,这是NeRF的基础内容,不清楚的得先了解,这里就不赘述了:
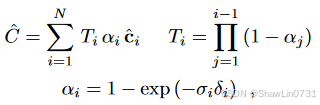
③端到端联合建图和跟踪
要仅从颜色色彩损失来建模场景的几何和颜色特征是很难的,尤其是对几何特征而言,只是用颜色是欠约束的,所以为了添加额外的约束,作者使用了如下的损失值。
RGB渲染损失。这就是最老生常谈的损失,就是用从帧上采样得到像素值与通过该像素的射线上的采样点渲染后得到的渲染值相减,具体如下,不过多赘述:
RGB Warping Loss。这个损失我不知怎么翻译,但是我们可以从公式上看出作者的意图。假设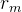
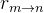
光流损失。RGB渲染损失和RGB Warping Loss都容易出现局部最小值。假设第m帧中的样本像素为rm,第n帧中对应的投影像素为rn,添加光流损失如下,其中 GM(rm→n) 表示 GMFlow估计的光流:
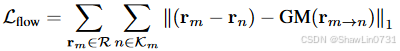
以下还有几个损失,可以参考我之前的文章MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction添加单目几何提示的隐式重建-CSDN博客:
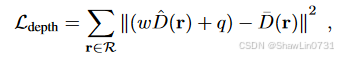
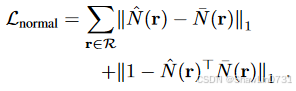
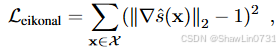
④训练策略
作者用下面的总损失来训练MLP模型和分层网格隐式表示的特征值:
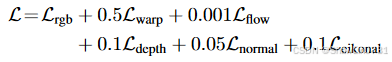
再就是作者对建图训练的顺序有如下的策略,个人感觉去理解为什么这样做,意义不是很大,因为多少带一点炼丹的成分,像是一个启发式的过程,自己训练时可以调整,言之有理即可。所以直接给大家看原文,不做赘述:

对于相机位姿的优化就是用之前定义的RGB渲染损失作为损失函数,但是优化过程中保持MLP解码网络的参数和分层隐式表示的特征值不变,只优化位姿,至于怎么优化参考我之前的文章STaR: Self-supervised Tracking and Reconstruction of Rigid Objects in Motion with Neural Rendering-CSDN博客
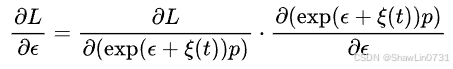
4.系统总览图
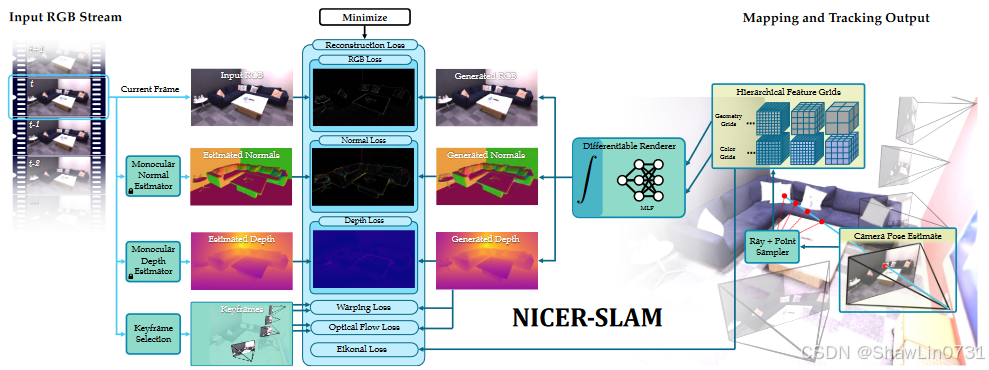
只要能够看懂这张图,基本上就已经理解了这篇论文。