目录
启动Spark Master 和Slaves以及HistoryServers
首先我们在spark官网上下载spark安装包
https://spark.apache.org/downloads.html
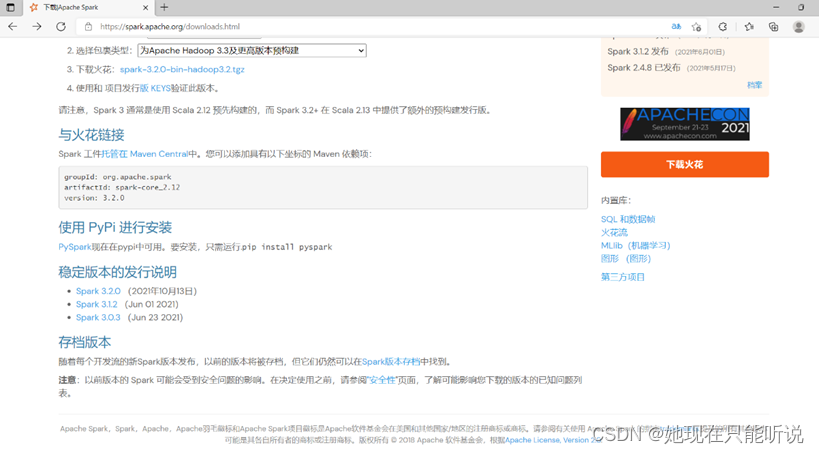
在最下面版本存档里找到与我们之前搭建的Hadoop2.7.5版本对应的spark2.2.0安装包

等待下载完成
上传
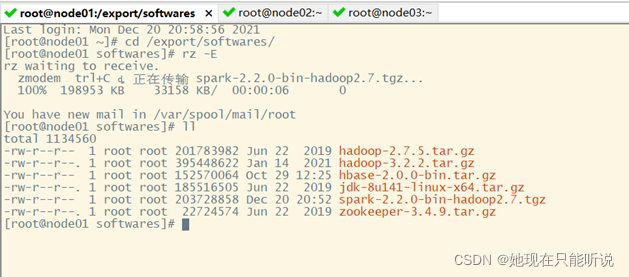
使用Secure CRT 将下载好的spark安装包上传到node01的export/softwares下面
cd /export/softwares/
rz -E
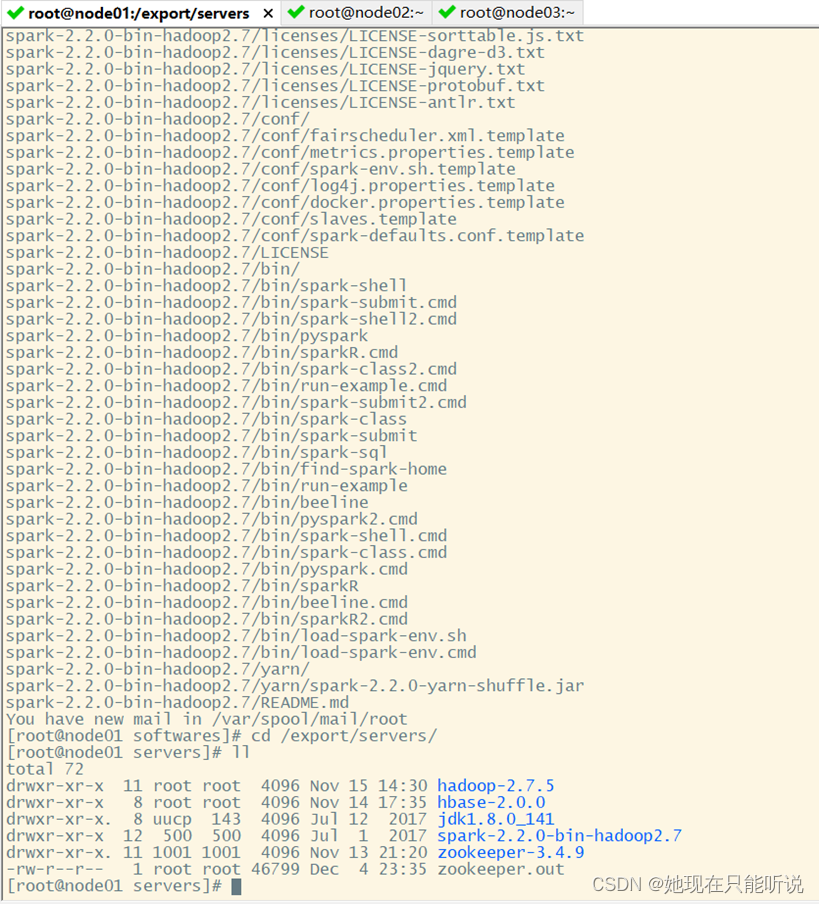
如图,就是我们Hadoop的各个组件,将spark解压到export/serves目录下
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C ../servers/
cd /export/servers/
配置spark-env.sh
先将spark-env.sh.template复制为spark-env.sh
cd /spark-2.2.0-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
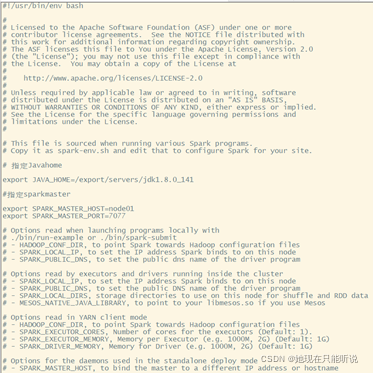
指定Java home
export JAVA_HOME=/export/servers/jdk1.8.0_141
指定sparkmaster地址
export SPARK_MASTER_HOST=node01
export SPARK_MASTER_PORT=7077
配置slaves
指定从节点位置,从而使用sbin/start-all.sh可以启动整个集群的work
cd /export/servers/spark/conf
cp slaves.template slaves
vi slaves

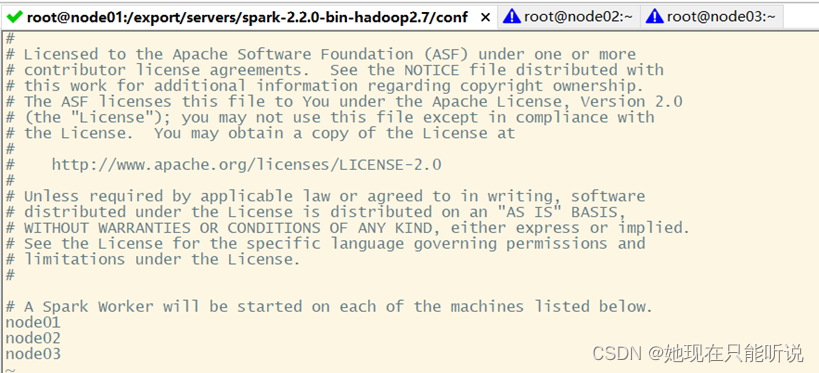
配置从节点位置
node01
node02
node03
三台机器都是从节点
配置historyserver
a默认情况下,spark程序运行完毕后就不能查看运行记录的Web UI了,通过HistoryServer可以提供一个服务,通过读取日志文件,使得我们可以在程序运行后,依然能够查看运行过程
b 复制 spark-defaults.conf,以供修改spark-defaults.conf
cp spark-defults.conf.template spark-defults.conf
vi spark-defults.conf
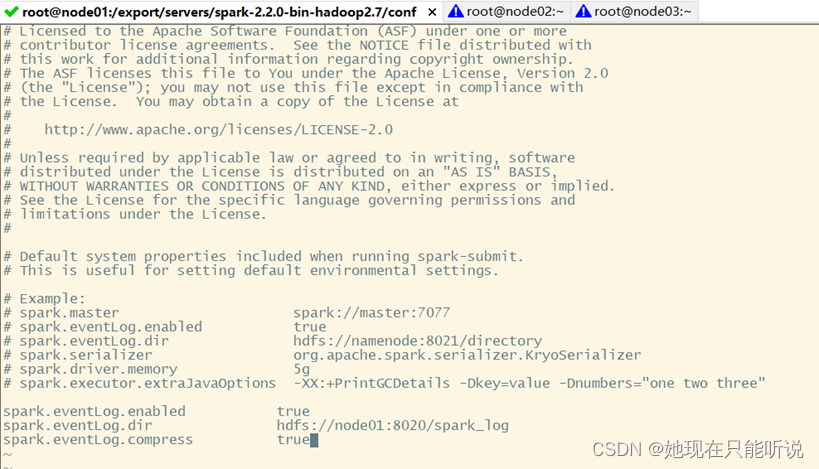
c 将以下内容复制到“spark-defaults.conf”,末尾处,通过这段配置,可以指定spark将日志传输进HDFS中。
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/spark_log
spark.eventLog.compress true
d 将以下内容复制到”spark-env-sh”的末尾,配置HistoryServer启动参数,使得HistoryServer在启动的时候读取HDFS中写入的spark日志
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
e 为spark创建HDFS中的日志目录
hdfs dfs -mkdir -p /spark_log
分发
将spark安装包分发给集群中的其他机器
cd /export/serves
scp -r spark-2.2.0-bin-hadoop2.7 node02:$PWD
scp -r spark-2.2.0-bin-hadoop2.7 node03:$PWD
cd /export/serves/ spark-2.2.0-bin-hadoop2.7
sbin/start-all.sh
sbin/start-history-server.sh
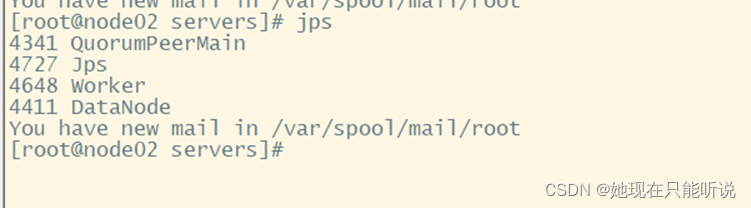
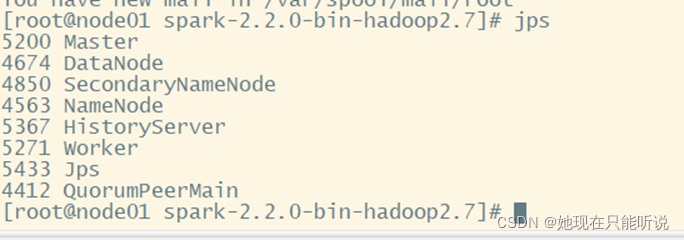
Jps查看node01进程
Jps查看node02进程