- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
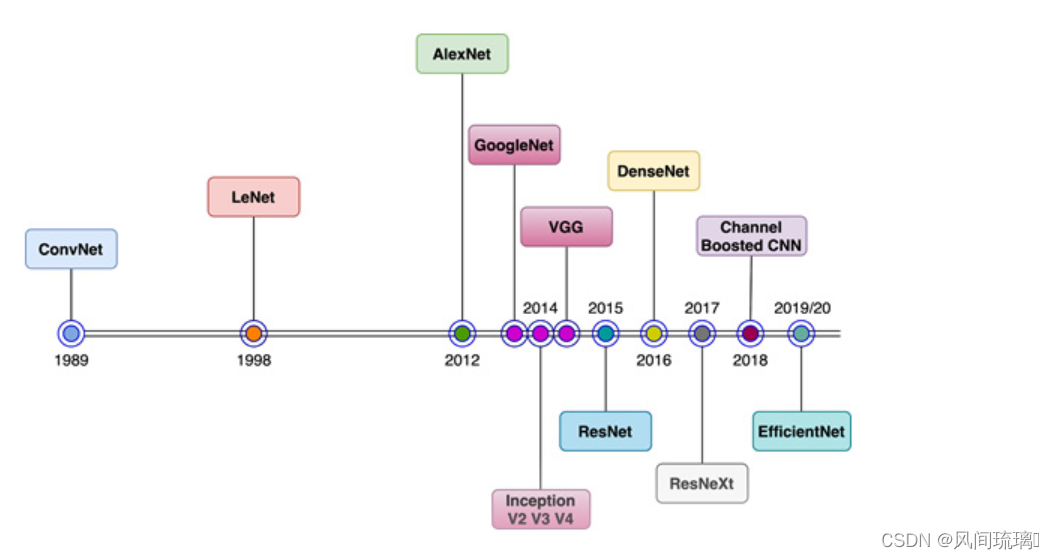
CNN自1989年以来一直存在,当时第一个多层CNN,称为ConvNet,由Yann LeCun开发。该模型可以执行视觉认知任务,例如识别手写数字。1998年,LeCun开发了一种改进的ConvNet模型,称为LeNet。由于其在光学识别任务中的高精度,LeNet在发明后不久就被工业使用。从那时起,CNN一直是工业界和学术界最成功的机器学习模型之一。下图显示了 CNN 生命周期中架构发展的简要时间表,从 1989 年一直到 2020 年,
十年来,计算机视觉(CV)突飞猛进,VGGNet,GoogLeNet/Inception,ResNeXt,DenseNet,MobileNet 和 EfficientNet等一大批ImageNet竞赛的年度冠军等优秀模型蓬勃发展,你方唱罢我登场,精彩纷呈,卷积神经网络CNN作为图像处理的标配卷过了AI的大半边天。
在此之前,自然语言处理 (NLP) 和CV是像两条平行线,各自相对独立的发展。RNN和CNN是教科书中两个独立的章节,分别对应自然语言的序列(Sequence)和图像局部特征的特点。自从2017年,Google在NLP领域发表了Attention is all you need,提出基于自注意力(self-attention)的Transformer,随后ViT(Vision Transformer)在CV领域大放异彩,越来越多的研究人员开始拥入Transformer的怀抱。
之后在CV领域发的文章绝大多数都是基于Transformer的,比如2021年ICCV 的best paper Swin Transformer,而卷积神经网络已经开始慢慢淡出舞台中央,难道卷积神经网络要被Transformer取代了吗?也许会在不久的将来。
在2022年1月,A ConvNet for the 2020s一论文提出ConvNeXt,借鉴了 Vision Transformer 和 CNN 的成功经验,构建一个纯卷积网络,其性能超越了高大上(复杂的) 基于Transformer 的先进的模型。
ConvNeXt的出现证明,并不一定需要Transformer那么复杂的结构,只对原有CNN的技术和参数优化也能达到SOTA,未来CV领域,CNN和Transformer谁主沉浮?
一、ConvNeXt设计决策
1.设计方案
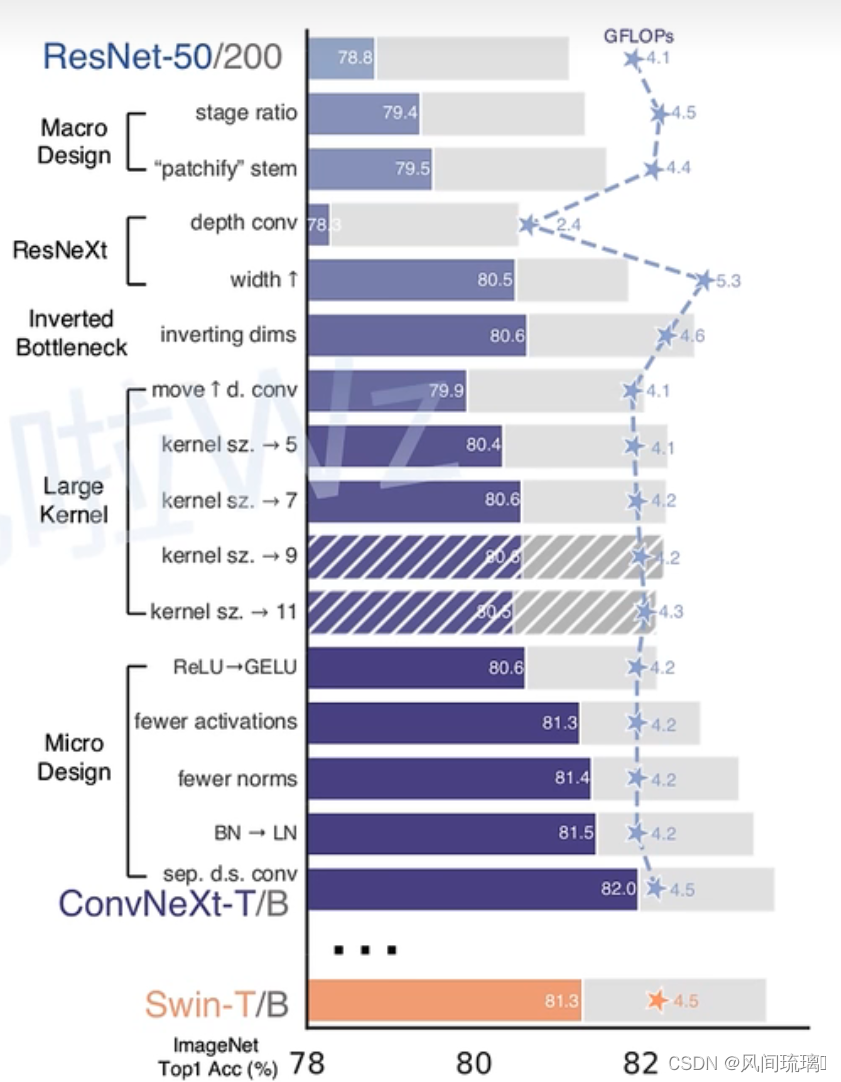
作者将设计 vision Transformer(Swin) 的技巧应用到标准的卷积网络(ResNet-50)。纵坐标代表采取的操作,横坐标表示在ImageNet数据集上的top1准确率。星星表示网络的计算量。斜条纹(kernel size=9/11)表示不采取该操作。实验结果展示 在计算量相同的情况下,纯卷积网络(ConvNext)表现优于Swin Transformer。
作者首先利用训练vision Transformers的策略去训练原始的ResNet50模型,发现比原始效果要好很多,并将此结果作为后续实验的基准baseline。然后作者罗列了接下来实验包含哪些部分:
∙ \bullet ∙ macro design
∙ \bullet ∙ ResNeXt
∙ \bullet ∙ inverted bottleneck
∙ \bullet ∙ large kerner size
∙ \bullet ∙various layer-wise micro designs
依次从宏观设计,深度可分离卷积(ResNeXt),逆瓶颈层(MobileNet v2),大卷积核,细节设计这五个角度依次借鉴Swin Transformer的思想,然后在ImageNet-1K上进行训练和评估,得到ConvNeXt的核心结构。
ConvNeXt本质上没有提出新的创新点,ConvNeXt使用的全部都是现有的结构和方法,没有任何结构或者方法的创新。
2.Training Techniques
随着深度学习在各个领域上的不断探索,残差网络采用的原始策略已经不能充分的压榨残差结构的性能。Vision Transformers不仅带来新的模块和框架设计,同时也介绍了不同的训练技巧。
在ConvNeXt中,它的优化策略借鉴了Swin-Transformer。具体的优化策略包括:
∙ \bullet ∙ 将训练的epochs从原先的90增加到300。
∙ \bullet ∙ 优化器从SGD改为使用AdamW优化器。
∙ \bullet ∙ 更复杂的数据扩充策略,包括Mixup,CutMix,RandAugment,Random Erasing
∙ \bullet ∙ 增加正则策略,例如随机深度,标签平滑,EMA等
实验结果显示,ResNet-50在ImageNet数据集上的Top1准确率从 76.1%增到78.8%(+2.7%)。这表明,传统的卷积网络和vision Transformer的差异可能源于训练技巧(training techniques)的不同。
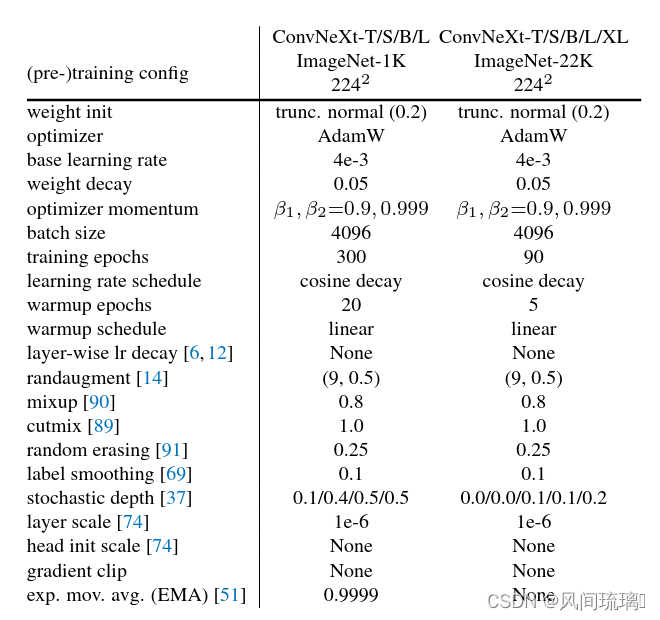
更具体的预训练和微调的超参数如下图
3.Macro Design
Swin Transformer使用multi-stage的设计,即每个stage有不同的特征图分辨率,主要包括stage compute ratio和stem cell结构。
🥇Changing stage compute ratio
VGG提出了把骨干网络分成若干个网络块的结构,每个网络块通过池化操作将Feature Map降采样到不同的尺寸。在VGG中,每个网络块的网络层的数量基本是相同,当深层的网络块层数更多时,模型的表现更好。例如,ResNet-50中共有4个不同的网络块,它的每个网络块的层数是(3,4,6,3) ,比例大概是(1:1:2:1)。
在Swin-Transformer中,每个骨干网络被分成了4个不同的Stage,每个Stage又是由若干个Block组成,在Swin-Transformer中,这个Block的比例是**(1:1:3:1)**,而对于更大的模型来说,这个比例是(1:1:9:1) 。
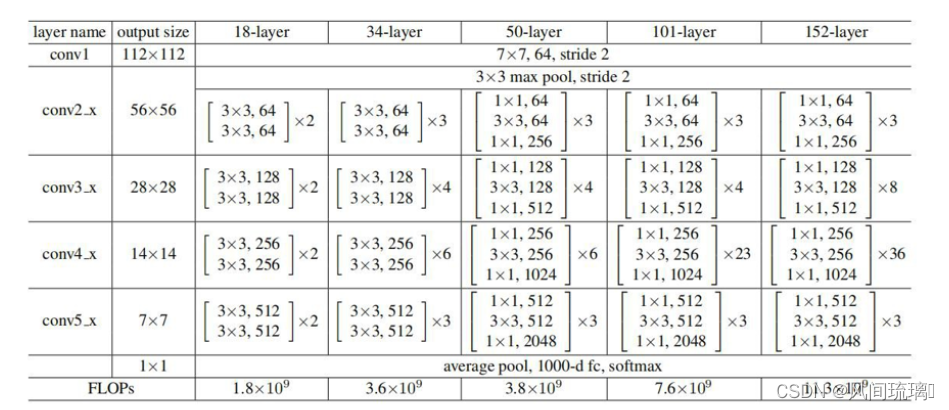
ConvNeXt的改进是将ResNet-50的每个Stage的block的比例调整到(1:1:3:1) ,最终得到的block数是(3,3,9,3) ,进行调整后,准确率由78.8%提升到了79.4%。
🥈Change stem to “Patchify”
对于ImageNet数据集,通常采用224x224的输入尺寸,该尺寸对于Transformer的模型来说是非常大的,在Transformer模型中一般都是通过一个 卷积核非常大且相邻窗口之间没有重叠的(即stride等于kernel_size)卷积层进行下采样。比如在Swin Transformer中采用的是一个卷积核大小为4x4步距为4的卷积层构成patchify(补丁化),同样是下采样4倍,这一部分在Swin-Transformer中叫做stem层,它是位于输入之后的一个降采样层。
“patchify”策略作为 stem cell使用:
∙ \bullet ∙ 使用一个大的卷积核
∙ \bullet ∙ non-overlapping卷积(stride=kernel size)
通常情况下,stem cell主要在网络的最前头用于处理输入图像。即下采样输入图像到合适的图像尺寸。
在标准的ResNet中,一般最初的下采样模块stem一般都是通过一个卷积核大小为7x7步距为2的卷积层以及一个步距为2的最大池化下采样共同组成,高和宽都下采样4倍。
在ConvNeXt中,作者将Stem层也换成和Swin Transformer一样的patchify,使用一个步长为4,大小为4的卷积操作,这一操作将准确率从79.4%提升至79.5%,GFLOPs从4.5降到4.4%。
4.ResNeXt-ify
作者采用ResNext的思想,它比普通的ResNet具有更好的FLOPs/accuracy权衡。核心部分是分组卷积(grouped convolution)即卷积核被分成不同的组,用来提升模型的计算速度。
作者使用depthwise convolution,这是分组卷积的一种特殊情况,即分组的数量等于通道的数量。如下图所示。
在Swin-Tranformer的Self-Attention也是以通道为单位的运算单元,不同的是可分离卷积是可学习的卷积核,Self-Attention是根据数据动态计算的权值。
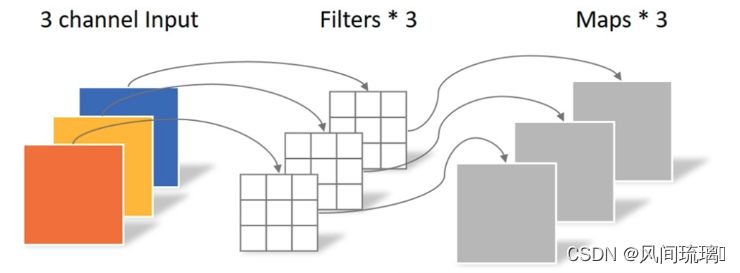
在ConvNeXt中,也引入了分组卷积的思想,它将bottleneck中3x3卷积替换成了3x3 的分组卷积,这个操作将GFLOPs从4.4降到了2.4,但是它也将准确率从79.5%降到了78.3%。**为了弥补准确率的下降,它将ResNet-50的基础通道数从64增加至96。**这个操作将GFLOPs增加到了5.3,但是准确率提升到了80.5%。
5. Inverted Bottleneck
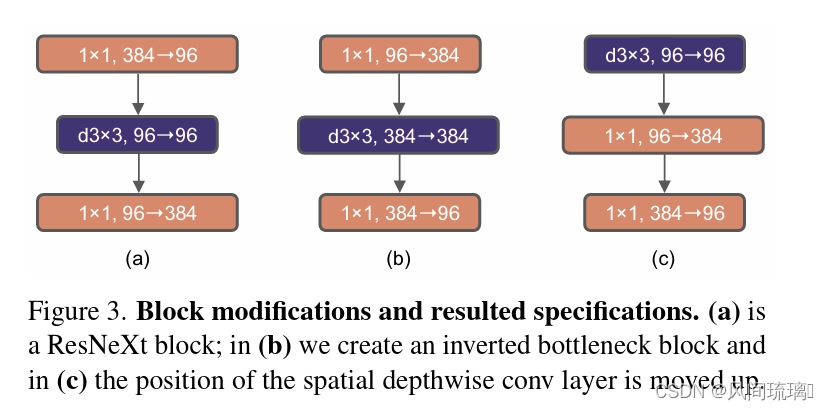
作者认为Transformer block中的MLP模块(中间层维度数是两端的4倍)非常像MobileNetV2中的Inverted Bottleneck模块,即两头细中间粗。下图a是ReNet中采用的Bottleneck模块(大维度-小维度-大维度),b是MobileNetV2采用的Inverted Botleneck模块(小维度-大维度-小维度),c是ConvNeXt采用的是Inverted Bottleneck模块。
作者采用Inverted Bottleneck模块后,在较小的模型上准确率由80.5%提升到了80.6%,在较大的模型上准确率由81.9%提升到82.6%。
6.Large Kernel Size
Transformer中,non-local self-attention能够获得全局的感受野。研究者认为更大的感受野是ViT性能更好的可能原因之一,作者尝试增大卷积的kernel,使模型获得更大的感受野。
接着作者做了如下两个改动:
⋆
\star
⋆ Moving up depthwise conv layer,将depthwise conv提前到1x1 conv之前,之后用384个1x1x96的conv将模型宽度提升4倍,在用96个1x1x96的conv恢复模型宽度。
反映在上图中就是由(b)变为©,原来是1x1 conv -> depthwise conv -> 1x1 conv,现在变成了depthwise conv -> 1x1 conv -> 1x1 conv。这么做是因为在Transformer中,MSA模块是放在MLP模块之前的,所以这里进行效仿,将depthwise conv上移。由于3x3的conv数量减少,模型FLOPs由5.3G减少到4G,相应地性能暂时下降到79.9%。
⋆
\star
⋆ Increasing the kernel size,然后作者尝试增大depthwise conv的卷积核大小,证明7x7(Swin Transformer中也是7x7)大小的卷积核效果达到最佳,并且准确率从79.9% (3×3) 增长到 80.6% (7×7)。
7.Micro Design
接下来开始细节层面的讨论,主要体现在激活函数和归一化层的选择。
✨Replacing ReLU with GELU
ReLU是比较早期的激活函数,在卷积神经网络中比较常用。在Transformer中基本上选择使用GELU作为激活函数,如Swin Transformer。
GELU可以认为是ReLU的平滑版本。作者实验发现,在ConvNeXt将ReLu使用GELU代替,但是精度没有变化(80.6%)。但是为了对齐其它指标,ConvNeXt还是选择了GELU作为激活函数。
✨Fewer activation functions
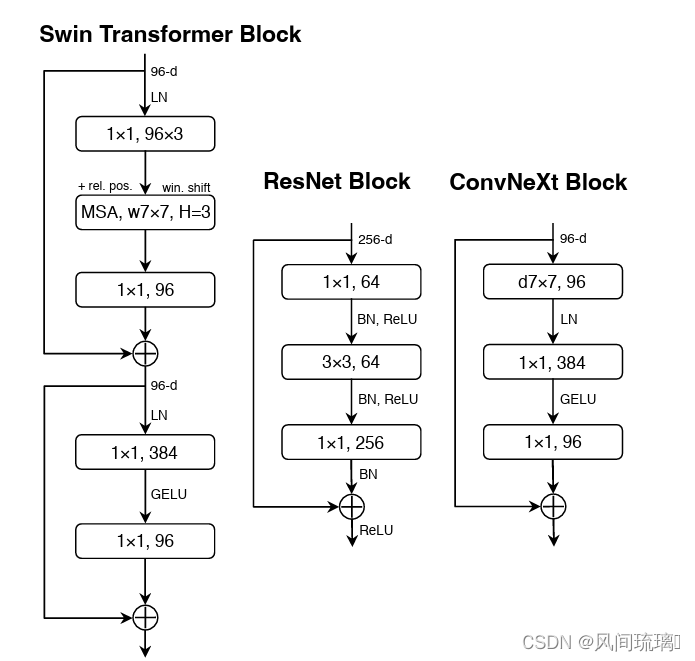
在卷积神经网络中,一般会在每个卷积层或全连接后都接上一个激活函数。但在Transformer中并不是每个模块后都跟有激活函数。如下图所示,Swin Transformer block中只有MLP有一个激活函数(RELU)。
ConvNeXt也借鉴了Transformer的思想,它仅在两个1x1卷积之间添加了一个GELU激活函数。实验结果表明这个操作将准确率从80.6%提升至81.3%。
✨Fewer normalization layers
在Transformer中,Normalization使用的也比较少,接着作者也减少了ConvNeXt Block中的Normalization层,只保留了depthwise conv后的Normalization层。此时准确率已经达到了81.4%,已经超过了Swin-T。根据经验,作者发现,在block的开始添加一个额外的Normalization层并不能改善性能。
✨Substituting BN with LN
BatchNorm是卷积神经网络的重要组成部分,因为它提高了收敛性并减少了过拟合。虽然BN也有很多错综复杂的地方,会对模型的性能产生不利影响,但BN仍然是大多数视觉任务的首选方法。
但在Transformer中使用了更简单的Layer Normalization(LN),因为最开始Transformer是应用在NLP领域的,BN又不适用于NLP相关任务。接着作者将BN全部替换成了LN,发现准确率还有小幅提升达到了81.5%。
✨Separate downsampling layers
在ResNet网络中stage2-stage4的下采样都是通过将主分支上3x3的卷积层步距设置成2,short分支上1x1的卷积层步距设置成2进行下采样的。
但在Swin Transformer中是通过一个单独的Patch Merging实现的。接着作者就为ConvNext网络单独使用了一个下采样层,使用卷积核为2,步长为2的卷积层进行空间下采样操作,又因为这样会使训练不稳定,因此在每个下采样层前面增加了Laryer Normalization(LN)来稳定训练,更改后准确率就提升到了82.0%。
二、ConvNeXt网络结构
1.网络配置参数
对于ConvNeXt网络,作者提出了T/S/B/L/XL五个版本,这五个版本的配置如下:
∙ \bullet ∙ ConvNeXt-T: C = (96, 192, 384, 768), B = (3, 3, 9, 3)
∙ \bullet ∙ ConvNeXt-S: C = (96, 192, 384, 768), B = (3, 3, 27, 3)
∙ \bullet ∙ ConvNeXt-B: C = (128, 256, 512, 1024), B = (3, 3, 27, 3)
∙ \bullet ∙ ConvNeXt-L: C = (192, 384, 768, 1536), B = (3, 3, 27, 3)
∙ \bullet ∙ ConvNeXt-XL: C = (256, 512, 1024, 2048), B = (3, 3, 27, 3)
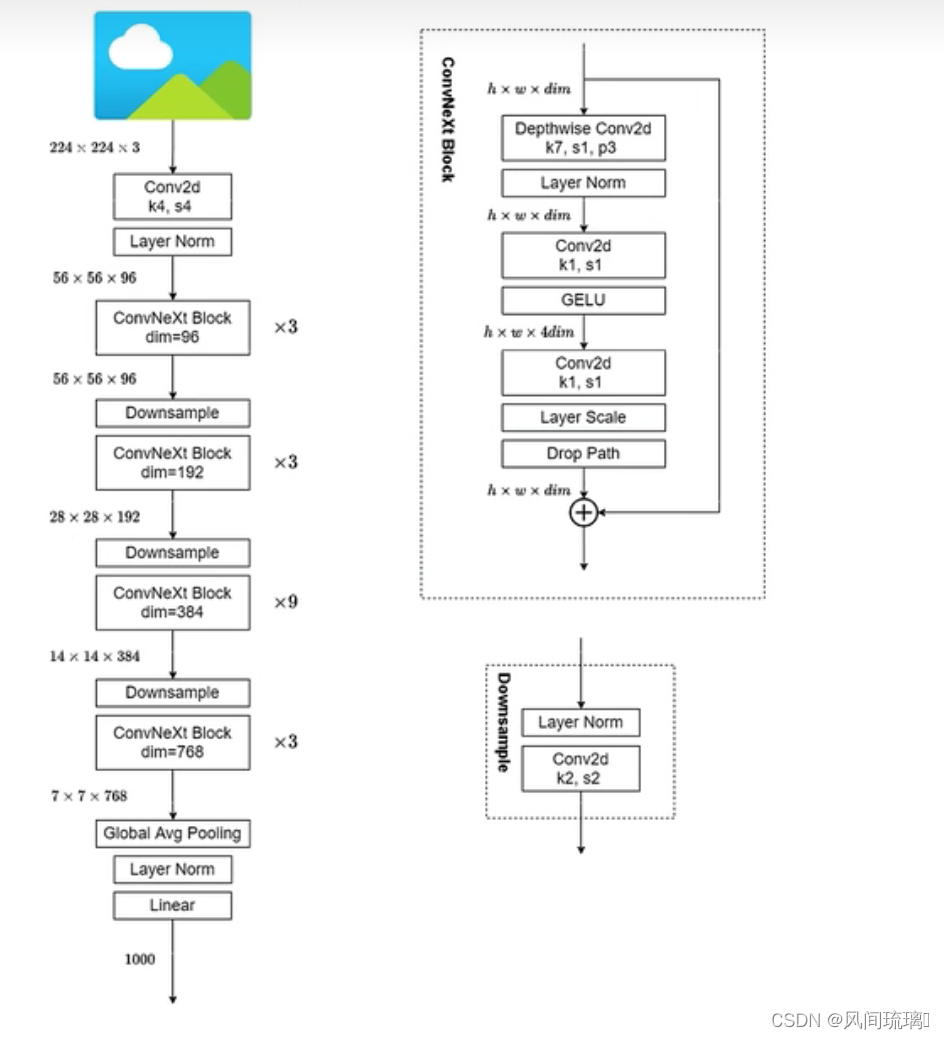
其中C代表4个stage中输入的通道数,B代表每个stage重复堆叠block的次数,ConvNeXt-T版本如下图所示。
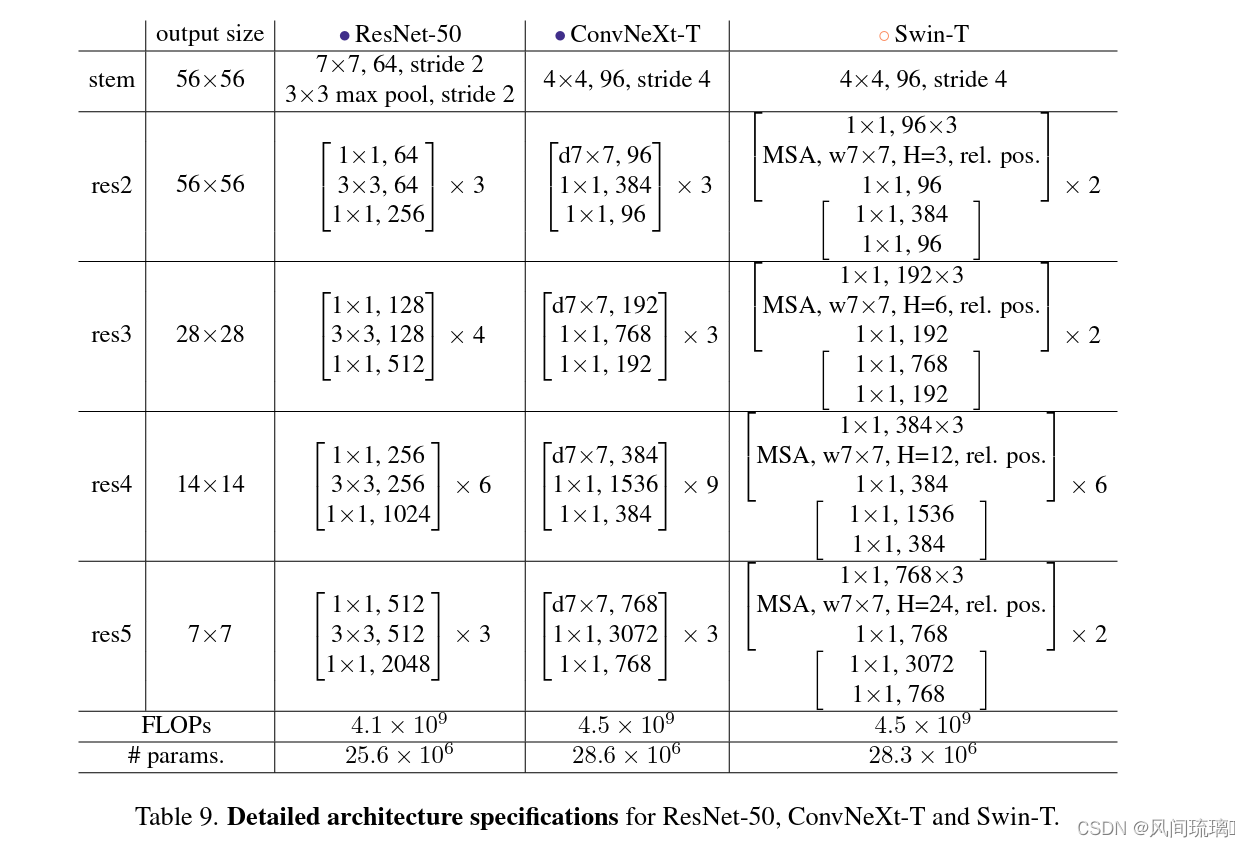
2.ConvNeXt-T 结构
ConvNeXt-T网络结构图如下,来自B站大佬的。
注意,ConvNeXt Block中还有一个Layer Scale操作,它就是将输入的特征层乘上一个可训练的参数,该参数就是一个向量,元素个数与特征层channel相同,即对每个channel的数据进行缩放。
三、ConvNeXt-T网络实现
1.构建ConvNeXt-T网络
"""
original code from facebook research:
https://github.com/facebookresearch/ConvNeXt
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class LayerNorm(nn.Module):
r""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape), requires_grad=True)
self.bias = nn.Parameter(torch.zeros(normalized_shape), requires_grad=True)
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise ValueError(f"not support data format '{self.data_format}'")
self.normalized_shape = (normalized_shape,)
def forward(self, x: torch.Tensor) -> torch.Tensor:
if self.data_format == "channels_last": # 维度:(batch_size, height, width, channels)使用官方的函数
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first": # 维度:(batch_size, channels, height, width)自定义使用LN
# [batch_size, channels, height, width]
mean = x.mean(1, keepdim=True) # CHANNEL维度
var = (x - mean).pow(2).mean(1, keepdim=True)
x = (x - mean) / torch.sqrt(var + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
# ConvNeXt block
class Block(nn.Module):
r""" ConvNeXt Block. There are two equivalent implementations:
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
We use (2) as we find it slightly faster in PyTorch
Args:
dim (int): Number of input channels.
drop_rate (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_rate=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6, data_format="channels_last")
# 1x1的卷积层使用Linear实现
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
# Layer Scale
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim,)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_rate) if drop_rate > 0. else nn.Identity()
def forward(self, x: torch.Tensor) -> torch.Tensor:
shortcut = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # [N, C, H, W] -> [N, H, W, C]
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # [N, H, W, C] -> [N, C, H, W]
x = shortcut + self.drop_path(x)
return x
class ConvNeXt(nn.Module):
r""" ConvNeXt
A PyTorch impl of : `A ConvNet for the 2020s` -
https://arxiv.org/pdf/2201.03545.pdf
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(self, in_chans: int = 3, num_classes: int = 1000, depths: list = None,
dims: list = None, drop_path_rate: float = 0., layer_scale_init_value: float = 1e-6,
head_init_scale: float = 1.):
super().__init__()
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
# 下采样:convd2d k4 s4 + LN
stem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first"))
self.downsample_layers.append(stem)
# 对应stage2-stage4前的3个downsample:LN + conv2d k2 s2
for i in range(3):
downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2))
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple blocks
dp_rates = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
# 构建每个stage中堆叠的block
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_rate=dp_rates[cur + j], layer_scale_init_value=layer_scale_init_value)
for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
nn.init.trunc_normal_(m.weight, std=0.2)
nn.init.constant_(m.bias, 0)
def forward_features(self, x: torch.Tensor) -> torch.Tensor:
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.forward_features(x)
x = self.head(x)
return x
def convnext_tiny(num_classes: int):
# https://dl.fbaipublicfiles.com/convnext/convnext_tiny_1k_224_ema.pth
model = ConvNeXt(depths=[3, 3, 9, 3],
dims=[96, 192, 384, 768],
num_classes=num_classes)
return model
def convnext_small(num_classes: int):
# https://dl.fbaipublicfiles.com/convnext/convnext_small_1k_224_ema.pth
model = ConvNeXt(depths=[3, 3, 27, 3],
dims=[96, 192, 384, 768],
num_classes=num_classes)
return model
def convnext_base(num_classes: int):
# https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_224_ema.pth
# https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pth
model = ConvNeXt(depths=[3, 3, 27, 3],
dims=[128, 256, 512, 1024],
num_classes=num_classes)
return model
def convnext_large(num_classes: int):
# https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_224_ema.pth
# https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_224.pth
model = ConvNeXt(depths=[3, 3, 27, 3],
dims=[192, 384, 768, 1536],
num_classes=num_classes)
return model
def convnext_xlarge(num_classes: int):
# https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_224.pth
model = ConvNeXt(depths=[3, 3, 27, 3],
dims=[256, 512, 1024, 2048],
num_classes=num_classes)
return model
2.训练和测试模型
import os
import argparse
import torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from my_dataset import MyDataSet
from model import convnext_tiny as create_model
from utils import read_split_data, create_lr_scheduler, get_params_groups, train_one_epoch, evaluate
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
print(f"using {device} device.")
if os.path.exists("./weights") is False:
os.makedirs("./weights")
tb_writer = SummaryWriter()
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)
img_size = 224
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(img_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(int(img_size * 1.143)),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)
model = create_model(num_classes=args.num_classes).to(device)
if args.weights != "":
assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights)
weights_dict = torch.load(args.weights, map_location=device)["model"]
# 删除有关分类类别的权重
for k in list(weights_dict.keys()):
if "head" in k:
del weights_dict[k]
print(model.load_state_dict(weights_dict, strict=False))
if args.freeze_layers:
for name, para in model.named_parameters():
# 除head外,其他权重全部冻结
if "head" not in name:
para.requires_grad_(False)
else:
print("training {}".format(name))
# pg = [p for p in model.parameters() if p.requires_grad]
pg = get_params_groups(model, weight_decay=args.wd)
optimizer = optim.AdamW(pg, lr=args.lr, weight_decay=args.wd)
lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), args.epochs,
warmup=True, warmup_epochs=1)
best_acc = 0.
for epoch in range(args.epochs):
# train
train_loss, train_acc = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch,
lr_scheduler=lr_scheduler)
# validate
val_loss, val_acc = evaluate(model=model,
data_loader=val_loader,
device=device,
epoch=epoch)
tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]
tb_writer.add_scalar(tags[0], train_loss, epoch)
tb_writer.add_scalar(tags[1], train_acc, epoch)
tb_writer.add_scalar(tags[2], val_loss, epoch)
tb_writer.add_scalar(tags[3], val_acc, epoch)
tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)
if best_acc < val_acc:
torch.save(model.state_dict(), "./weights/best_model.pth")
best_acc = val_acc
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=100)
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--batch-size', type=int, default=8)
parser.add_argument('--lr', type=float, default=5e-4)
parser.add_argument('--wd', type=float, default=5e-2)
# 数据集所在根目录
# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path', type=str,
default="F:/NN/Learn_Pytorch/flower_photos")
# 预训练权重路径,如果不想载入就设置为空字符
# 链接: https://pan.baidu.com/s/1aNqQW4n_RrUlWUBNlaJRHA 密码: i83t
parser.add_argument('--weights', type=str, default='./convnext_tiny_1k_224_ema.pth',
help='initial weights path')
# 是否冻结head以外所有权重
parser.add_argument('--freeze-layers', type=bool, default=False)
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
main(opt)
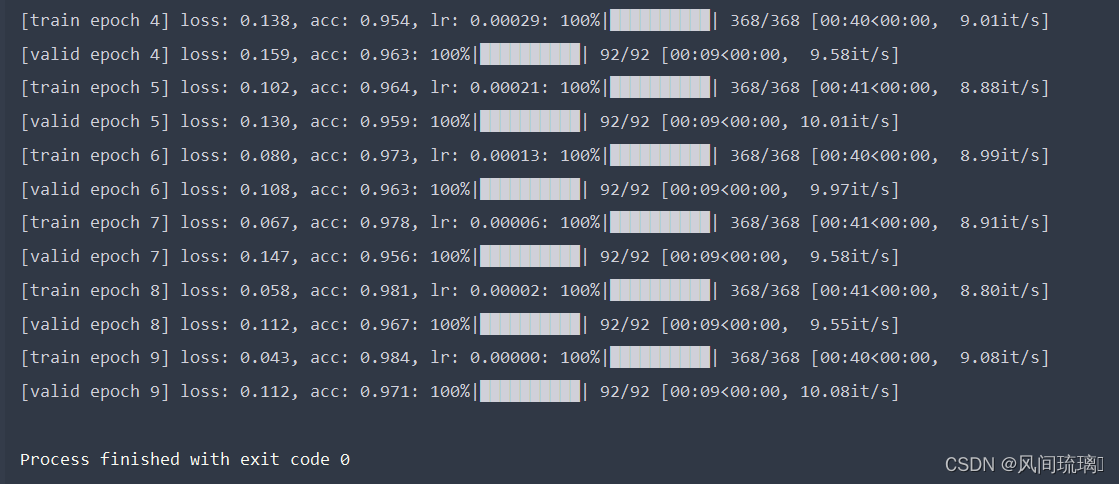
这里使用了预训练权重,在其基础上训练自己的数据集。训练10epoch的准确率能到达98%左右。
四、实现图像分类
这里使用花朵数据集,下载连接:https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"using {device} device.")
num_classes = 5
img_size = 224
data_transform = transforms.Compose(
[transforms.Resize(int(img_size * 1.14)),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# 加载图片
img_path = 'sunflower1.jpg'
assert os.path.exists(img_path), "file: '{}' does not exist.".format(img_path)
image = Image.open(img_path)
# image.show()
# [N, C, H, W]
img = data_transform(image)
# 扩展维度
img = torch.unsqueeze(img, dim=0)
# 获取标签
json_path = 'class_indices.json'
assert os.path.exists(json_path), "file: '{}' does not exist.".format(json_path)
with open(json_path, 'r') as f:
# 使用json.load()函数加载JSON文件的内容并将其存储在一个Python字典中
class_indict = json.load(f)
# create model
model = create_model(num_classes=num_classes).to(device)
# load model weights
model_weight_path = "./weights/best_model.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
with torch.no_grad():
# 对输入图像进行预测
output = torch.squeeze(model(img.to(device))).cpu()
# 对模型的输出进行 softmax 操作,将输出转换为类别概率
predict = torch.softmax(output, dim=0)
# 得到高概率的类别的索引
predict_cla = torch.argmax(predict).numpy()
res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)], predict[predict_cla].numpy())
draw = ImageDraw.Draw(image)
# 文本的左上角位置
position = (10, 10)
# fill 指定文本颜色
draw.text(position, res, fill='green')
image.show()
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)], predict[i].numpy()))
预测结果:

结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。