获取微博排行榜是获取微博html页面的数据,而非直接调用微博后端接口获取
PHP实现
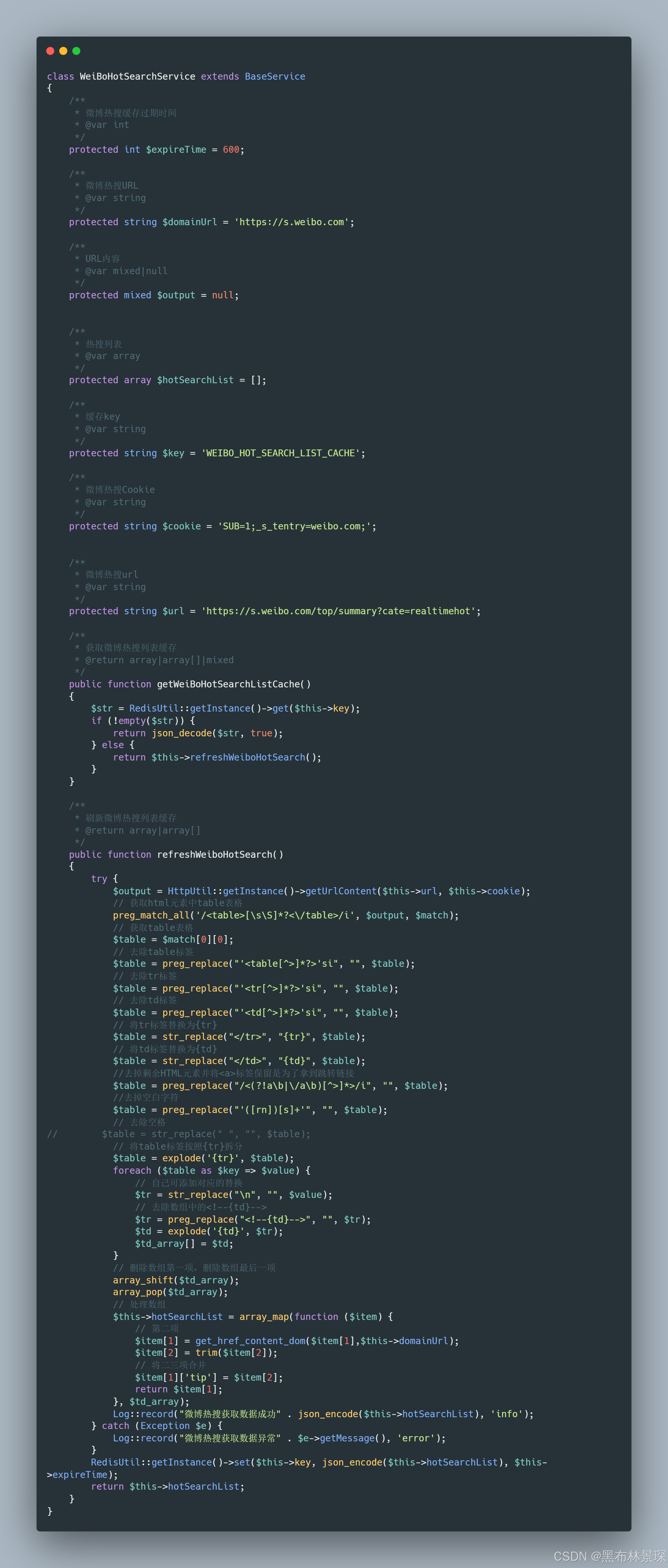
class WeiBoHotSearchService extends BaseService
{
/**
* 微博热搜缓存过期时间
* @var int
*/
protected int $expireTime = 600;
/**
* 微博热搜URL
* @var string
*/
protected string $domainUrl = 'https://s.weibo.com';
/**
* URL内容
* @var mixed|null
*/
protected mixed $output = null;
/**
* 热搜列表
* @var array
*/
protected array $hotSearchList = [];
/**
* 缓存key
* @var string
*/
protected string $key = 'WEIBO_HOT_SEARCH_LIST_CACHE';
/**
* 微博热搜Cookie
* @var string
*/
protected string $cookie = 'SUB=1;_s_tentry=weibo.com;';
/**
* 微博热搜url
* @var string
*/
protected string $url = 'https://s.weibo.com/top/summary?cate=realtimehot';
/**
* 获取微博热搜列表缓存
* @return array|array[]|mixed
*/
public function getWeiBoHotSearchListCache()
{
$str = RedisUtil::getInstance()->get($this->key);
if (!empty($str)) {
return json_decode($str, true);
} else {
return $this->refreshWeiboHotSearch();
}
}
/**
* 刷新微博热搜列表缓存
* @return array|array[]
*/
public function refreshWeiboHotSearch()
{
try {
$output = HttpUtil::getInstance()->getUrlContent($this->url, $this->cookie);
// 获取html元素中table表格
preg_match_all('/<table>[\s\S]*?<\/table>/i', $output, $match);
// 获取table表格
$table = $match[0][0];
// 去除table标签
$table = preg_replace("'<table[^>]*?>'si", "", $table);
// 去除tr标签
$table = preg_replace("'<tr[^>]*?>'si", "", $table);
// 去除td标签
$table = preg_replace("'<td[^>]*?>'si", "", $table);
// 将tr标签替换为{tr}
$table = str_replace("</tr>", "{tr}", $table);
// 将td标签替换为{td}
$table = str_replace("</td>", "{td}", $table);
//去掉剩余HTML元素并将<a>标签保留是为了拿到跳转链接
$table = preg_replace("/<(?!a\b|\/a\b)[^>]*>/i", "", $table);
//去掉空白字符
$table = preg_replace("'([rn])[s]+'", "", $table);
// 去除空格
// $table = str_replace(" ", "", $table);
// 将table标签按照{tr}拆分
$table = explode('{tr}', $table);
foreach ($table as $key => $value) {
// 自己可添加对应的替换
$tr = str_replace("\n", "", $value);
// 去除数组中的<!--{td}-->
$tr = preg_replace("<!--{td}-->", "", $tr);
$td = explode('{td}', $tr);
$td_array[] = $td;
}
// 删除数组第一项,删除数组最后一项
array_shift($td_array);
array_pop($td_array);
// 处理数组
$this->hotSearchList = array_map(function ($item) {
// 第二项
$item[1] = get_href_content_dom($item[1],$this->domainUrl);
$item[2] = trim($item[2]);
// 将二三项合并
$item[1]['tip'] = $item[2];
return $item[1];
}, $td_array);
Log::record("微博热搜获取数据成功" . json_encode($this->hotSearchList), 'info');
} catch (Exception $e) {
Log::record("微博热搜获取数据异常" . $e->getMessage(), 'error');
}
RedisUtil::getInstance()->set($this->key, json_encode($this->hotSearchList), $this->expireTime);
return $this->hotSearchList;
}
}上面的RedisUtil就是一个工具类,其中只用了String类型的set和get方法
下期使用Python实现