1. 为什么要用线程池? 不能直接new个线程吗?
如果我们在方法中直接new一个线程来处理,当这个方法被调用频繁时就会创建很多线程,不仅会消耗系统资源,还会降低系统的稳定性。
- 降低资源消耗。通过重复利用已创建的线程,降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 增加线程的可管理型。线程是稀缺资源,使用线程池可以进行统一分配,调优和监控。
2. 线程池的核心属性有哪些?
- threadFactory(线程工厂):用于创建工作线程的工厂
- corePoolSize(核心线程数):当线程池运行的线程少于 corePoolSize 时,将创建一个新线程来处理请求,即使其他工作线程处于空闲状态
- workQueue(队列):用于保留任务并移交给工作线程的阻塞队列
- maximumPoolSize(最大线程数):线程池允许开启的最大线程数
- handler(拒绝策略):往线程池添加任务时,将在下面两种情况触发拒绝策略:1)线程池运行状态不是 RUNNING;2)线程池已经达到最大线程数,并且阻塞队列已满时
- keepAliveTime(保持存活时间):如果线程池当前线程数超过 corePoolSize,则多余的线程空闲时间超过 keepAliveTime 时会被终止
- unit(空闲线程存活时间单位):keepAliveTime 的计量单位
3. 线程池的执行流程?
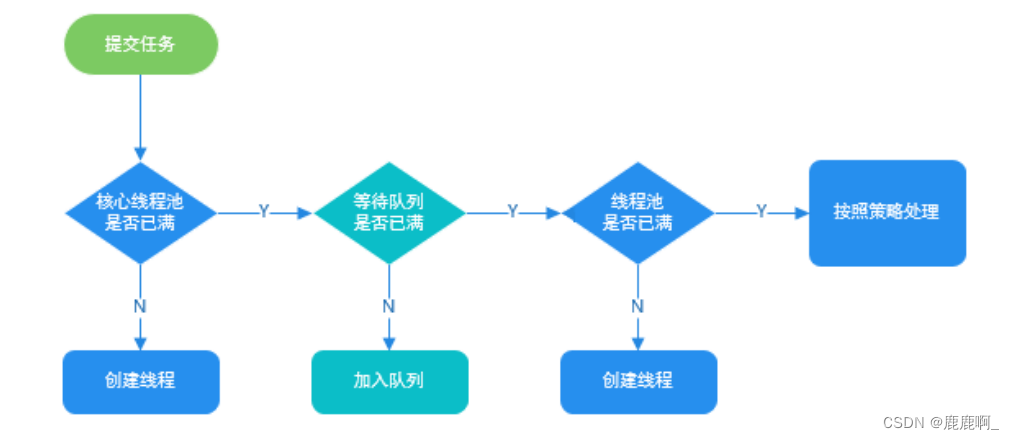
//线程池实现原理
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
// 1.⾸先判断当前线程池中之⾏的任务数量是否小于 corePoolSize
// 如果小于的话,通过addWorker(command, true)新建⼀个线程,并将任务(command)
//添加到该线程中;然后,启动该线程从⽽执⾏任务。
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//2.如果当前执行的任务数量⼤于等于 corePoolSize 的时候就会⾛到这
// 通过 isRunning ⽅法判断线程池状态,线程池处于 RUNNING 状态才会被阻塞队列加⼊任务,该任务才会被加⼊进去
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 再次获取线程池状态,如果线程池状态不是 RUNNING 状态就需要从任务队列中移除任务,并尝试判断线程是否全部执⾏完毕。同时执⾏拒绝策略。
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果当前线程池为空就新创建⼀个线程并执⾏
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//3. 通过addWorker(command, false)新建⼀个线程,
//并将任务(command)添加到该线程中;然后,启动该线程从⽽执⾏任务。
//如果addWorker(command, false)执⾏失败,则通过reject()执⾏相应的拒绝策略的内容。
else if (!addWorker(command, false))
reject(command);
}
4. 线程的状态都有哪些?
- NEW – 尚未启动的线程处于此状态(创建线程对象)
- RUNNABLE – 在Java虚拟机中执行的线程处于此状态(start()开启线程)
- BLOCKED – 被阻塞等待监视器锁定的线程处于此状态(无法获得锁)
- WAITING – 正在等待另一个线程执行特定动作的线程处于此状态(wait()等待)
- TIMED_WAITING – 正在等待另一个线程执行动作达到指定等待时间的线程处于此状态(sleep(long time)睡眠)
- TERMINATED – 已退出的线程处于此状态(线程执行完毕任务)
5. 线程状态之间如何进行切换?
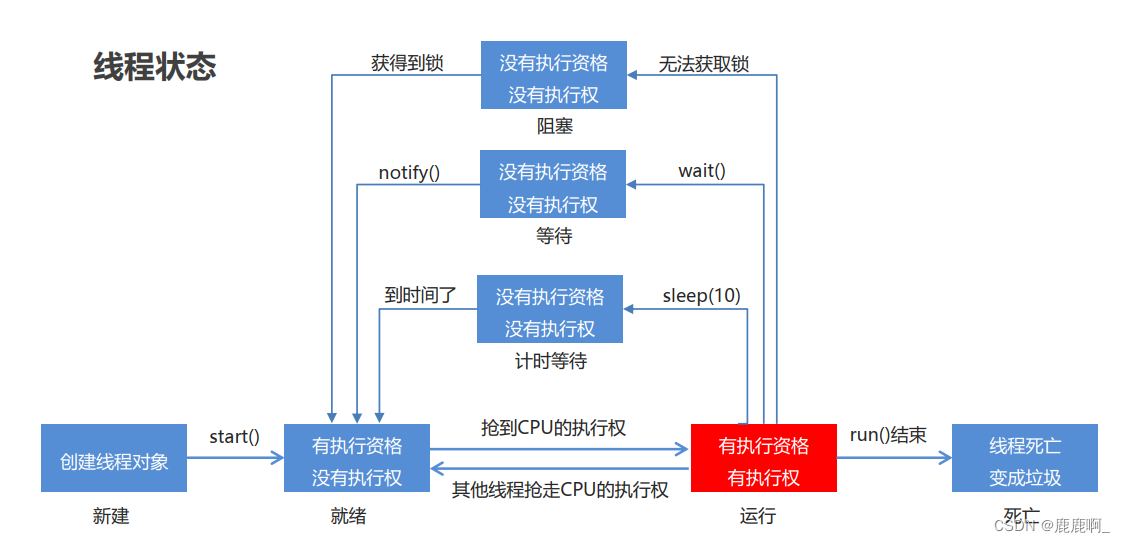
6. 自定义线程池?
//TreadPoolExecutor(自定义参数线程池)(推荐使用)
public class ThreadPoolDemo {
public static void main(String[] args) {
//1. 使用ThreadPoolExecutor指定具体参数的方式创建线程池
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2, //核心线程数
5, //池中允许的最大线程数
2, //空闲线程最大存活时间
TimeUnit.SECONDS, //秒
new ArrayBlockingQueue<>(10),//被添加到线程池中,但尚未被执行的任务
Executors.defaultThreadFactory(), //创建线程工厂,默认
new ThreadPoolExecutor.AbortPolicy()//,如何拒绝任务
);
//2. 执行具体任务
poolExecutor.submit(new MyRunnable());
poolExecutor.submit(new MyRunnable());
//3. 关闭线程池
poolExecutor.shutdown();
}
}
public class MyRunnable implements Runnable{
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"执行了");
}
}
7. Executors 提供了哪些创建线程池的方法?
- newFixedThreadPool:固定线程数的线程池。corePoolSize = maximumPoolSize,keepAliveTime为0,工作队列使用无界的LinkedBlockingQueue。适用于为了满足资源管理的需求,而需要限制当前线程数量的场景,适用于负载比较重的服务器。
- newSingleThreadExecutor:只有一个线程的线程池。corePoolSize = maximumPoolSize = 1,keepAliveTime为0, 工作队列使用无界的LinkedBlockingQueue。适用于需要保证顺序的执行各个任务的场景。
- newCachedThreadPool: 按需要创建新线程的线程池。核心线程数为0,最大线程数为 Integer.MAX_VALUE,keepAliveTime为60秒,工作队列使用同步移交 SynchronousQueue。该线程池可以无限扩展,当需求增加时,可以添加新的线程,而当需求降低时会自动回收空闲线程。适用于执行很多的短期异步任务,或者是负载较轻的服务器。
- newScheduledThreadPool:创建一个以延迟或定时的方式来执行任务的线程池,工作队列为 DelayedWorkQueue。适用于需要多个后台线程执行周期任务。
- newWorkStealingPool:JDK 1.8 新增,用于创建一个可以窃取的线程池,底层使用 ForkJoinPool 实现。
8. 使用队列有什么需要注意的吗?
- 使用有界队列时,需要注意线程池满了后,被拒绝的任务如何处理。
- 使用无界队列时,需要注意如果任务的提交速度大于线程池的处理速度,可能会导致内存溢出。
9. 线程池有哪些拒绝策略?
- AbortPolicy:中止策略。默认的拒绝策略,直接抛出 RejectedExecutionException。调用者可以捕获这个异常,然后根据需求编写自己的处理代码。
- DiscardPolicy:抛弃策略。什么都不做,直接抛弃被拒绝的任务。
- DiscardOldestPolicy:抛弃最老策略。抛弃阻塞队列中最老的任务,相当于就是队列中下一个将要被执行的任务,然后重新提交被拒绝的任务。如果阻塞队列是一个优先队列,那么“抛弃最旧的”策略将导致抛弃优先级最高的任务,因此最好不要将该策略和优先级队列放在一起使用。
- CallerRunsPolicy:调用者运行策略。在调用者线程中执行该任务。该策略实现了一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将任务回退到调用者(调用线程池执行任务的主线程),由于执行任务需要一定时间,因此主线程至少在一段时间内不能提交任务,从而使得线程池有时间来处理完正在执行的任务。
10. 线程只能在任务到达时才启动吗?
默认情况下,即使是核心线程也只能在新任务到达时才创建和启动。但是我们可以使用 prestartCoreThread(启动一个核心线程)或 prestartAllCoreThreads(启动全部核心线程)方法来提前启动核心线程。
11. 核心线程怎么实现一直存活?
阻塞队列方法有四种形式,它们以不同的方式处理操作,如下表。
| 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 | |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除 | remove() | poll() | take() | poll(time,unit) |
| 检查 | element() | peek() | 不可用 | 不可用 |
核心线程在获取任务时,通过阻塞队列的 take() 方法实现的一直阻塞(存活)。
12. 非核心线程能成为核心线程吗?
虽然我们一直讲着核心线程和非核心线程,但是其实线程池内部是不区分核心线程和非核心线程的。只是根据当前线程池的工作线程数来进行调整,因此看起来像是有核心线程于非核心线程。
13. 如何终止线程池?
- shutdown:“温柔”的关闭线程池。不接受新任务,但是在关闭前会将之前提交的任务处理完毕。
- shutdownNow:“粗暴”的关闭线程池,也就是直接关闭线程池,通过 Thread#interrupt() 方法终止所有线程,不会等待之前提交的任务执行完毕。但是会返回队列中未处理的任务。
14. 在我们实际使用中,线程池的大小配置多少合适?
要想合理的配置线程池大小,首先我们需要区分任务是计算密集型还是I/O密集型。
对于计算密集型,设置线程数 = CPU数 + 1,通常能实现最优的利用率。
对于I/O密集型,网上常见的说法是设置 线程数 = CPU数 * 2 ,这个做法是可以的,但个人觉得不是最优的。
在我们日常的开发中,我们的任务几乎是离不开I/O的,常见的网络I/O(RPC调用)、磁盘I/O(数据库操作),并且I/O的等待时间通常会占整个任务处理时间的很大一部分,在这种情况下,开启更多的线程可以让 CPU 得到更充分的使用,一个较合理的计算公式如下:
线程数 = CPU数 * CPU利用率 * (任务等待时间 / 任务计算时间 + 1)
例如我们有个定时任务,部署在4核的服务器上,该任务有100ms在计算,900ms在I/O等待,则线程数约为:4 * 1 * (1 + 900 / 100) = 40个。
并且I/O的等待时间通常会占整个任务处理时间的很大一部分,在这种情况下,开启更多的线程可以让 CPU 得到更充分的使用,一个较合理的计算公式如下:
线程数 = CPU数 * CPU利用率 * (任务等待时间 / 任务计算时间 + 1)
例如我们有个定时任务,部署在4核的服务器上,该任务有100ms在计算,900ms在I/O等待,则线程数约为:4 * 1 * (1 + 900 / 100) = 40个。
当然,具体我们还要结合实际的使用场景来考虑。如果要求比较精确,可以通过压测来获取一个合理的值。