最近在训练Yolov8-seg时遇到一个问题,就是如何将CoCo数据Json文件转化成可用于Yolov8-seg训练的txt文件,并且是自己想要训练的类别,CoCo数据有80类,我只需要其中的某几类,例如person、cat、dog等。
Yolov8-seg训练数据目录结构如下:images存放训练集和验证集图片,labels存放训练集和验证集txt
mydata
______images
____________train
_________________001.jpg
____________val
_________________002.jpg
______labels
____________train
_________________001.txt
____________val
_________________002.txt 具体代码如下:分别是utils.py 、cocojson2segtxt.py
utils.py
import glob
import os
import shutil
from pathlib import Path
import numpy as np
from PIL import ExifTags
from tqdm import tqdm
# Parameters
img_formats = ['bmp', 'jpg', 'jpeg', 'png', 'tif', 'tiff', 'dng'] # acceptable image suffixes
vid_formats = ['mov', 'avi', 'mp4', 'mpg', 'mpeg', 'm4v', 'wmv', 'mkv'] # acceptable video suffixes
# Get orientation exif tag
for orientation in ExifTags.TAGS.keys():
if ExifTags.TAGS[orientation] == 'Orientation':
break
def exif_size(img):
# Returns exif-corrected PIL size
s = img.size # (width, height)
try:
rotation = dict(img._getexif().items())[orientation]
if rotation in [6, 8]: # rotation 270
s = (s[1], s[0])
except:
pass
return s
def split_rows_simple(file='../data/sm4/out.txt'): # from utils import *; split_rows_simple()
# splits one textfile into 3 smaller ones based upon train, test, val ratios
with open(file) as f:
lines = f.readlines()
s = Path(file).suffix
lines = sorted(list(filter(lambda x: len(x) > 0, lines)))
i, j, k = split_indices(lines, train=0.9, test=0.1, validate=0.0)
for k, v in {'train': i, 'test': j, 'val': k}.items(): # key, value pairs
if v.any():
new_file = file.replace(s, f'_{k}{s}')
with open(new_file, 'w') as f:
f.writelines([lines[i] for i in v])
def split_files(out_path, file_name, prefix_path=''): # split training data
file_name = list(filter(lambda x: len(x) > 0, file_name))
file_name = sorted(file_name)
i, j, k = split_indices(file_name, train=0.9, test=0.1, validate=0.0)
datasets = {'train': i, 'test': j, 'val': k}
for key, item in datasets.items():
if item.any():
with open(f'{out_path}_{key}.txt', 'a') as file:
for i in item:
file.write('%s%s\n' % (prefix_path, file_name[i]))
def split_indices(x, train=0.9, test=0.1, validate=0.0, shuffle=True): # split training data
n = len(x)
v = np.arange(n)
if shuffle:
np.random.shuffle(v)
i = round(n * train) # train
j = round(n * test) + i # test
k = round(n * validate) + j # validate
return v[:i], v[i:j], v[j:k] # return indices
def make_dirs(dir='new_dir/'):
# Create folders
dir = Path(dir)
if dir.exists():
shutil.rmtree(dir) # delete dir
for p in dir, dir / 'labels', dir / 'images':
p.mkdir(parents=True, exist_ok=True) # make dir
return dir
def write_data_data(fname='data.data', nc=80):
# write darknet *.data file
lines = ['classes = %g\n' % nc,
'train =../out/data_train.txt\n',
'valid =../out/data_test.txt\n',
'names =../out/data.names\n',
'backup = backup/\n',
'eval = coco\n']
with open(fname, 'a') as f:
f.writelines(lines)
def image_folder2file(folder='images/'): # from utils import *; image_folder2file()
# write a txt file listing all imaged in folder
s = glob.glob(f'{folder}*.*')
with open(f'{folder[:-1]}.txt', 'w') as file:
for l in s:
file.write(l + '\n') # write image list
def add_coco_background(path='../data/sm4/', n=1000): # from utils import *; add_coco_background()
# add coco background to sm4 in outb.txt
p = f'{path}background'
if os.path.exists(p):
shutil.rmtree(p) # delete output folder
os.makedirs(p) # make new output folder
# copy images
for image in glob.glob('../coco/images/train2014/*.*')[:n]:
os.system(f'cp {image} {p}')
# add to outb.txt and make train, test.txt files
f = f'{path}out.txt'
fb = f'{path}outb.txt'
os.system(f'cp {f} {fb}')
with open(fb, 'a') as file:
file.writelines(i + '\n' for i in glob.glob(f'{p}/*.*'))
split_rows_simple(file=fb)
def create_single_class_dataset(path='../data/sm3'): # from utils import *; create_single_class_dataset('../data/sm3/')
# creates a single-class version of an existing dataset
os.system(f'mkdir {path}_1cls')
def flatten_recursive_folders(path='../../Downloads/data/sm4/'): # from utils import *; flatten_recursive_folders()
# flattens nested folders in path/images and path/JSON into single folders
idir, jdir = f'{path}images/', f'{path}json/'
nidir, njdir = Path(f'{path}images_flat/'), Path(f'{path}json_flat/')
n = 0
# Create output folders
for p in [nidir, njdir]:
if os.path.exists(p):
shutil.rmtree(p) # delete output folder
os.makedirs(p) # make new output folder
for parent, dirs, files in os.walk(idir):
for f in tqdm(files, desc=parent):
f = Path(f)
stem, suffix = f.stem, f.suffix
if suffix.lower()[1:] in img_formats:
n += 1
stem_new = '%g_' % n + stem
image_new = nidir / (stem_new + suffix) # converts all formats to *.jpg
json_new = njdir / f'{stem_new}.json'
image = parent / f
json = Path(parent.replace('images', 'json')) / str(f).replace(suffix, '.json')
os.system("cp '%s' '%s'" % (json, json_new))
os.system("cp '%s' '%s'" % (image, image_new))
# cv2.imwrite(str(image_new), cv2.imread(str(image)))
print('Flattening complete: %g jsons and images' % n)
def coco91_to_coco80_class(): # converts 80-index (val2014) to 91-index (paper)
# https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/
x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, None, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, None, 24, 25, None,
None, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, None, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50,
51, 52, 53, 54, 55, 56, 57, 58, 59, None, 60, None, None, 61, None, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72,
None, 73, 74, 75, 76, 77, 78, 79, None]
return xcocojson2segtxt.py
import contextlib
import json
import cv2
import pandas as pd
from PIL import Image
from collections import defaultdict
from utils import *
classname = {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train',
7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign',
12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse',
18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe',
24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee',
30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat',
35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle',
40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana',
47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog',
53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant',
59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse',
65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster',
71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors',
77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
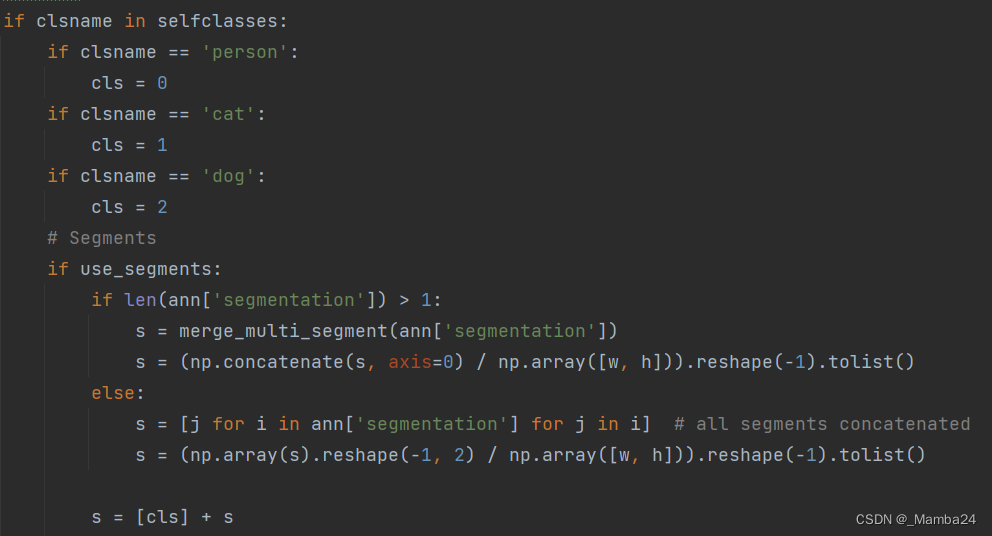
def convert_coco_json(json_dir,savepath, selfclasses,use_segments=False, cls91to80=False):
save_dir = make_dirs(savepath) # output directory
coco80 = coco91_to_coco80_class()
# print('coco80',coco80)
# Import json
for json_file in sorted(Path(json_dir).resolve().glob('*.json')):
fn = Path(save_dir) / 'labels' / json_file.stem.replace('instances_', '') # folder name
fn.mkdir()
with open(json_file) as f:
data = json.load(f)
# Create image dict
images = {'%g' % x['id']: x for x in data['images']}
# Create image-annotations dict
imgToAnns = defaultdict(list)
for ann in data['annotations']:
# print(ann)
imgToAnns[ann['image_id']].append(ann)
# Write labels file
for img_id, anns in tqdm(imgToAnns.items(), desc=f'Annotations {json_file}'):
img = images['%g' % img_id]
h, w, f = img['height'], img['width'], img['file_name']
bboxes = []
segments = []
for ann in anns:
if ann['iscrowd']:
continue
# The COCO box format is [top left x, top left y, width, height]
box = np.array(ann['bbox'], dtype=np.float64)
box[:2] += box[2:] / 2 # xy top-left corner to center
box[[0, 2]] /= w # normalize x
box[[1, 3]] /= h # normalize y
if box[2] <= 0 or box[3] <= 0: # if w <= 0 and h <= 0
continue
# print(ann)
cls = coco80[ann['category_id'] - 1] if cls91to80 else ann['category_id'] - 1 # class
box = [cls] + box.tolist()
if box not in bboxes:
bboxes.append(box)
clsname = classname[cls]
if clsname in selfclasses:
if clsname == 'person':
cls = 0
if clsname == 'cat':
cls = 1
if clsname == 'dog':
cls = 2
# Segments
if use_segments:
if len(ann['segmentation']) > 1:
s = merge_multi_segment(ann['segmentation'])
s = (np.concatenate(s, axis=0) / np.array([w, h])).reshape(-1).tolist()
else:
s = [j for i in ann['segmentation'] for j in i] # all segments concatenated
s = (np.array(s).reshape(-1, 2) / np.array([w, h])).reshape(-1).tolist()
s = [cls] + s
if s not in segments:
segments.append(s)
# Write
if len(segments)>0:
with open((fn / f).with_suffix('.txt'), 'a') as file:
for i in range(len(segments)):
# print(len(segments[i]))
line = *(segments[i] if use_segments else bboxes[i]), # cls, box or segments
# print(line)
file.write(('%g ' * len(line)).rstrip() % line + '\n')
def min_index(arr1, arr2):
"""Find a pair of indexes with the shortest distance.
Args:
arr1: (N, 2).
arr2: (M, 2).
Return:
a pair of indexes(tuple).
"""
dis = ((arr1[:, None, :] - arr2[None, :, :]) ** 2).sum(-1)
return np.unravel_index(np.argmin(dis, axis=None), dis.shape)
def merge_multi_segment(segments):
"""Merge multi segments to one list.
Find the coordinates with min distance between each segment,
then connect these coordinates with one thin line to merge all
segments into one.
Args:
segments(List(List)): original segmentations in coco's json file.
like [segmentation1, segmentation2,...],
each segmentation is a list of coordinates.
"""
s = []
segments = [np.array(i).reshape(-1, 2) for i in segments]
idx_list = [[] for _ in range(len(segments))]
# record the indexes with min distance between each segment
for i in range(1, len(segments)):
idx1, idx2 = min_index(segments[i - 1], segments[i])
idx_list[i - 1].append(idx1)
idx_list[i].append(idx2)
# use two round to connect all the segments
for k in range(2):
# forward connection
if k == 0:
for i, idx in enumerate(idx_list):
# middle segments have two indexes
# reverse the index of middle segments
if len(idx) == 2 and idx[0] > idx[1]:
idx = idx[::-1]
segments[i] = segments[i][::-1, :]
segments[i] = np.roll(segments[i], -idx[0], axis=0)
segments[i] = np.concatenate([segments[i], segments[i][:1]])
# deal with the first segment and the last one
if i in [0, len(idx_list) - 1]:
s.append(segments[i])
else:
idx = [0, idx[1] - idx[0]]
s.append(segments[i][idx[0]:idx[1] + 1])
else:
for i in range(len(idx_list) - 1, -1, -1):
if i not in [0, len(idx_list) - 1]:
idx = idx_list[i]
nidx = abs(idx[1] - idx[0])
s.append(segments[i][nidx:])
return s
if __name__ == '__main__':
source = 'COCO'
cocojsonpath = r'G:\XRW\Data\yolodata\json'
savepath = r'G:\XRW\Data\yolodata\save'
selfclasses = ['person', 'cat', 'dog']
if source == 'COCO':
convert_coco_json(cocojsonpath, # directory with *.json
savepath,
selfclasses,
use_segments=True,
cls91to80=True)
- cocojsonpath:CoCo数据集json文件存放路径
- savepath:生成的txt存放路径
- selfclasses:自己想要训练的类别
运行cocojson2segtxt.py

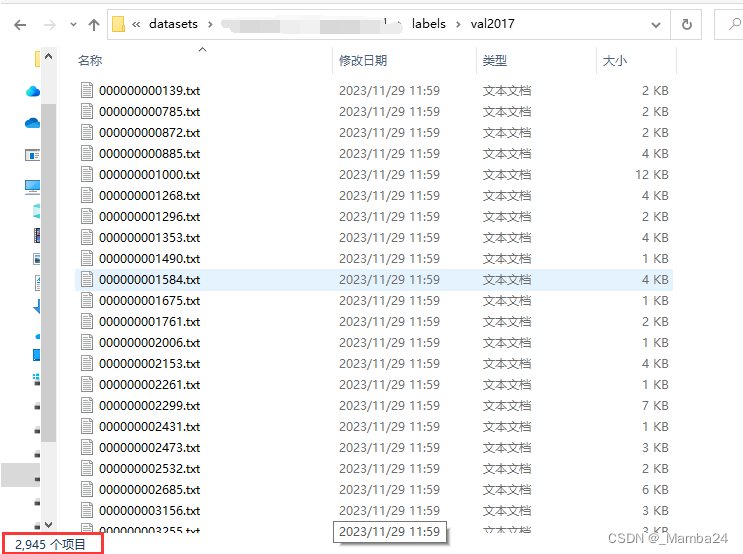
运行完成后得到的txt要少于上图显示的,因为这些txt只包含person、cat、dog类别

txt存放的数据格式如下(与官方一致):
<class-index> <x1> <y1> <x2> <y2> ... <xn> <yn><class-index>是对象类的索引,<x1> <y1> <x2> <y2> ... <xn> <yn>是对象分割掩码的边界坐标。坐标由空格分隔。(进行了归一化处理)

注意:我这里将person、cat、dog3类分别对应成0、1、2,可自行修改
以上步骤完成后只生成了txt,需要再将对应的图片copy到对应路径中。
import glob
import os
import shutil
imgpath = r'G:\CoCoData\val2017'
txtpath = r'G:\Yolov8\ultralytics-main\datasets\mysegdata\labels\val2017'
savepath = r'G:\Yolov8\ultralytics-main\datasets\mysegdata\images\val2017'
imglist = glob.glob(os.path.join(imgpath,'*.jpg'))
txtlist = glob.glob(os.path.join(txtpath,'*.txt'))
for img in imglist:
name = txtpath + '\\'+img.split('\\')[-1].split('.')[0]+'.txt'
if name in txtlist:
shutil.copy(img,savepath)
- imgpath CoCo数据集图片路径
- txtpath 生成的人猫狗txt路径
- savepath 保存图片的路径
CoCo数据

人猫狗类别的txt
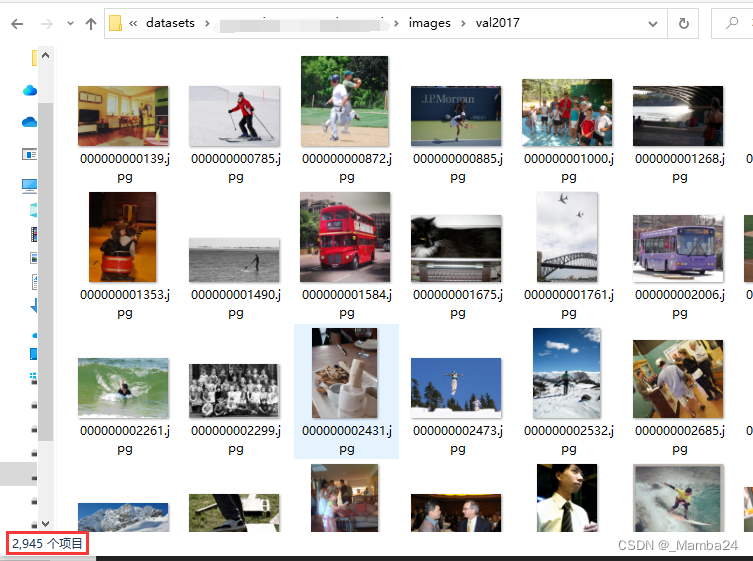
人猫狗类别的图片
这样CoCo数据集的人猫狗类别的Yolov8分割数据集就制作完成了。