如何实现英雄联盟全皮肤?
作为英雄联盟资深老玩家,想必大家都希望自己能拥有一套全皮肤,那么今天,小编就带着大家用网络爬虫的方式,爬取一套属于自己的全皮肤,冲!

第一步:
首先,打开我们全皮肤所在的网站”https://101.qq.com/#/hero“
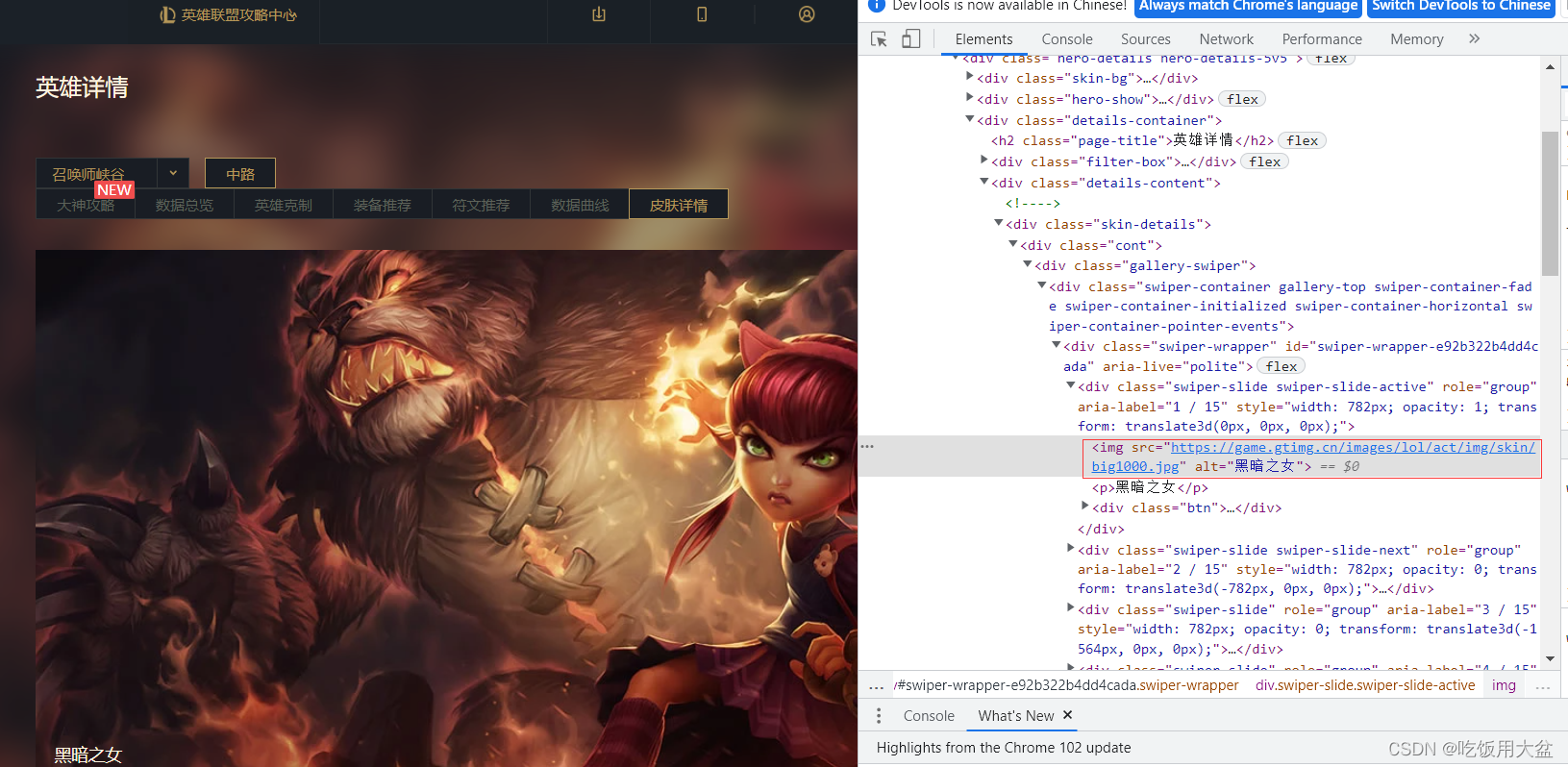
通过观察网页源代码,可以知道直接拿网页源代码是不行的,这个时候就需要通过接口去爬取,那现在我们找到皮肤所在的网络接口:
1.右键检查,找到Network,
2.点击一下网页左上方的刷新,就可以看到出现了很多json文件,
3.找到1.js那一栏,点击,
4.再点击1.js文件上方的Preview,就可以看到关于第一个英雄,安妮的所有信息,其中的mainImg那一栏就是皮肤所在的地址。

在我们知道地址过后,就可以开始敲代码了

第二步:安装并导入这次行动所需要的包,先爬取一个英雄的全皮肤。
"""
安装包:
pip install requests
pip install os
pip install re
"""
# 导入三方包
import requests
import os
import re
# 因为本次需要大概两个步骤,找到图片地址,保存下来,所以我们定义两个函数。
# 保存图片
def download_image(name, img_url: str):
response = requests.get(img_url)
# 打开文件夹lol,并把下载的图片保存在当前lol文件夹下
with open(f'lol/{name}.{img_url.split(".")[-1]}', 'wb') as f:
f.write(response.content)
print('下载成功!')
# 查找地址
def get_one_hero_skin():
url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/1.js'
response = requests.get(url)
# 将接口文件转化为json文件
result = response.json()
# prinr(result) 查看文件,发现安妮的信息都保存在字典中,其中皮肤地址保存在‘skins’这个键值对里。
# 对‘skins’进行遍历,查找需要的信息
for skin in result['skins']:
# 获取英雄名字
name = skin['name']
# 获取皮肤地址
img_url = skin['mainImg']
# 判断,是否为炫彩皮肤
if not img_url:
img_url = skin['chromaImg']
# 使用下载函数,保存图片
download_image(name, img_url)
if __name__ == '__main__':
# 执行函数
get_one_hero_skin()
这仅仅是一个英雄的全皮肤,还有那么多皮肤没有呢,那该怎么办呢?
第三步:添加循环,实现全英雄全皮肤爬取
# 更改第二步的查找地址代码,添加循环查找所有英雄的皮肤地址
def get_heroes_skin():
# 众所周知,现在lol更新有160个英雄,且range循环为左闭右开区间,故取区间为(1,161)
for page in range(1,161):
url = f'https://game.gtimg.cn/images/lol/act/img/js/hero/{page}.js'
response = requests.get(url)
result = response.json()
for skin in result['skins']:
# 查找英雄名字,作为文件夹的命名
hero_name = skin['heroName']
# 调用创建文件夹函数,创建文件夹
create_folder(hero_name)
name = skin['name']
img_url = skin['mainImg']
if not img_url:
img_url = skin['chromaImg']
download_image(hero_name, name, img_url)
print(f'{hero_name}下载成功!{page}')
# 添加一个创建文件夹函数,将每个英雄的皮肤放在当前英雄名字命名的文件夹下
def create_folder(hero_name):
path = './lol/' # 设置创建后文件夹存放的位置
# 将文件夹命名为英雄名字
isExists = os.path.exists(path + str(hero_name))
if not isExists: # 判断如果文件不存在,则创建
os.makedirs(path + str(hero_name))
else:
# 当目录已存在时,跳过
pass
本来我以为这就完了,可是苍天饶过谁?

想必大家都知道有款皮肤叫K/DA吧,这里的一个反斜杠,会在保存皮肤的时候,找不到文件,所以用一个替换函数,把/替换为.,就不会报错了。
if '/' in name:
name = name.replace('/', '.')
img_url = skin['mainImg']
第四步:查漏补缺
嘿嘿,如果大家觉得这就完了的话,还是太小看腾讯了,555。。。

在多次报错,多次修改过后,我终于找到了报错的原因,那就是皮肤所在的json地址,不是连续的,这是好大的一个坑,那我们就来把它解决了.
直接找到最后一个英雄,发现他的json地址为888,那我们就加一个判断,有我们就拿,沒有就跳过。
def get_heroes_skin():
for page in range(1, 890):
url = f'https://game.gtimg.cn/images/lol/act/img/js/hero/{page}.js'
response = requests.get(url)
# 把num定义为网页状态码
num = re.findall('[(\d{3})]', str(response))
list_1 = ['2', '0', '0']
# 当状态码为200时,进行信息查找,不为200时,跳过进行下一循环。
if num == list_1:
result = response.json()
# print('1')
for skin in result['skins']:
hero_name = skin['heroName']
create_folder(hero_name)
name = skin['name']
if '/' in name:
name = name.replace('/', '.')
img_url = skin['mainImg']
if not img_url:
img_url = skin['chromaImg']
download_image(hero_name, name, img_url)
print(f'{hero_name}下载成功!{page}')
else:
# print('2')
continue
总结:本次行动并不困难,小问题居多,如果细心一点,慢慢解决所有问题,相信大家都能做好,喜欢的朋友可以三连鼓励鼓励博主哦!!!
f’{hero_name}下载成功!{page}')
else:
# print(‘2’)
continue
总结:本次行动并不困难,小问题居多,如果细心一点,慢慢解决所有问题,相信大家都能做好,喜欢的朋友可以三连鼓励鼓励博主哦!!!