课程L1 L2
1. 何为实模式、保护模式?
参考链接:链接 1
小结:实模式,即直接访问物理实际地址,模型为
段基址+左移4位 +段偏移
形如
数据段+左移4位+ 通用寄存器值 = 数据地址
栈段SS+左移4位 + SP = 栈地址
之所以 左移4位,是因为 早期cpu寄存器是16位的,地址线有20位。直接存不下物理地址
保护模式,cpu32位,地址32位,可以访问更大地址空间,和进行段地址权限控制,模型改动为,段寄存器 存 全局描述符表(GDT)的表项的索引值。表项存段基址
2. test.c test.i test.s test.o test.exe ?
小结:
预处理阶段。编译器首先对源代码进行预处理,处理以“#”开头的预处理指令,如“#include”和“#define”。预处理器根据这些指令修改源代码,生成一个扩展名为“.i”的预处理后的文件。
编译阶段。在编译阶段,编译器将预处理后的文件翻译成汇编代码,生成以“.s”结尾的汇编文件。这一阶段包括词法分析、语法分析、语义分析、中间代码生成、优化,最终生成与特定计算机体系结构相对应的汇编语言代码。
汇编阶段。汇编器将汇编代码翻译成机器代码,生成以“.o”结尾的目标文件。这一阶段的输出是二进制文件,其中包含可执行的机器指令。
链接阶段。链接器将目标文件和必要的库文件合并成一个完整的可执行文件。链接器负责解决外部函数和变量的引用,并确保不同的代码段(如指令和数据)正确地链接在一起。
即 test.i 称为预处理后的文件,test.s称为 汇编代码 具有段格式。test.o称为 链接可重定位文件 具有段格式,二进制格式。
3. 为什么分段及基本内存布局?
参考 《深入理解计算机》,“链接” 篇章
小结:最终的可执行文件 是分段的,数据段,代码段。分段的好处在与 将数据归类 便于查找 和加载到内存中。只是因为cpu 段寄存器的存在 导致了内存在逻辑上的分段,不存在物理分段。
分多个段 是因为 一个段偏移寄存器表示范围只有16位
P2小结:上电后 执行bios,加载bootseg后,bootseg将
1.setup及其剩余的操作系统代码加载到内存,
2.打印 启动日志,
3.将 控制权交到setup
实验二 :操作系统的引导
1.为什么 在屏幕上显示字符串要读取光标的位置?
参考:c获取光标位置_一步步编写操作系统 75 从显卡读取光标位置1-CSDN博客
即 显示字符串 本质上不需要读取光标位置,只跟显存有关,但加上这个操作是为了 引导用户看见
2. 为什么 增加对es的处理?
答:es:bp 为读取的msg地址,设置为 #0x07c0(系统加载boot的默认位置),而非 #9000(boot将自己重复制到的位置) 是因为本实验的目的只涉及 打印。
boot的基本流程:
Linux 的最前面部分是用 8086 汇编语言编写的(boot/bootsect.S),并保存在引导设备的第一个扇区 中。它将由 BIOS 读入到内存绝对地址 0x7C00(31KB)处。当它被执行时就会把自己移动到内存绝对 地址 0x90000(576KB)处,并把启动设备盘中后 2KB 字节代码(boot/setup.S)读入到内存 0x90200 处。 而内核的其他部分(system 模块)则被读入到从内存地址 0x10000(64KB)开始处。
3. 为什么 设置引导扇区标志 ( .org508)?
答:3.1 org的概念
ORG 2000H
START:MOV AX,#00H
汇编语言源程序中若没有ORG伪指令,则程序执行时,指令代码被放到自由内存空间的CS:0处;若有ORG伪指令,编译器则把其后的指令代码放到ORG伪指令指定的偏移地址。两个ORG伪指令之间,除了指令代码,若有自由空间,则用0填充。
3.2 .word 的概念
答:举例来说,
_rWTCON:
.word 0x15300000
就是在当前地址,即_rWTCON处放一个值0x15300000
翻译成intel的汇编语句就是:
_rWTCON dw 0x15300000
3.3 boot_flag的规定
答:规定必须位于 引导扇区的最后两个字节
3.4 暂不加载文件系统?
4. 复习 从指定扇区磁道读字节码
答:
5. rol指令
rol,汇编语言指令,功能是把目的地址中的数据循环左移COUNT次,每次从最高位(最左)移出的数据位都补充到最低位(最右),最后从最高位(最左)移出的数据位保存到CF标志位。
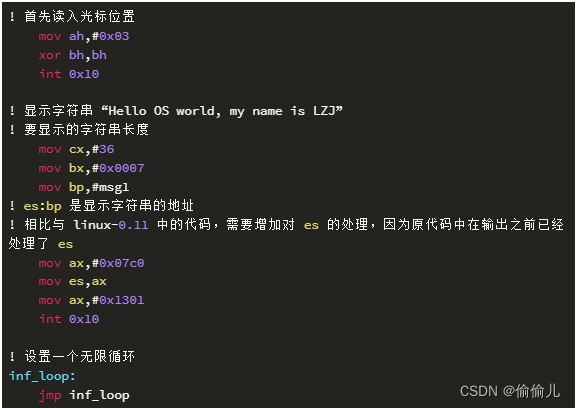
6. bootsect.s 在当前页光标处打印字符的核心代码
! 读取光标位置
mov ah,#0x03 !三号功能
xor bh,bh !参数传递 第0面
int 0x10! 显示字符串到光标位置
mov cx,#36 !显示多少个字符
mov bx,#0x0007 !bh 显示页面号,bl 字符属性
mov bp,#msg1
mov ax,#0x07c0
mov es,ax !es:bp 为读取的位置
mov ax,#0x1301 !ah=0x13 对应功能号,al=0x01为启用bl
int 0x10inf_loop:
jmp inf_loopmsg1:
.byte 13,10
.ascii "Hello os world, my name is dcw"
.byte 13,10,13,10
.org 510 !boot_flag必须位于引导扇区最后两个字节
boot_flag:
.word 0xAA55

7.从磁盘中读取setup.s到内存,并跳转setupseg
load_setup:
mov dx, #0x0000 !设置设备号 和 磁头(那一面)
mov cx, #0x0002 !设置扇区号 和 磁道号
mov bx, #0x0200 ! es:bx 为写入内存位置,BOOTSEG + 512字节
mov ax, #0x0200 + SETUPLEN !ah=0x02功能号,al = 0x02 读取的磁道数
int 0x13
jnc ok_load_setupok_load_setup:
jmpi 0,SETUPSEG
mov dx, #0x0000
mov ax, #0x0000 ! 复位软驱重新读取
int 0x13
jmp load_setup
setup.s 可暂时只打印字符 同 早期bootseg.s
效果图
8. 后续内容为 在setup.s 打印硬件参数 核心代码 为 16进制为字符转换、在光标处打印字符,与上雷同 可暂时略过。
课程L3 L4 L5
1.为什么跳转到systemseg 前启动保护模式?
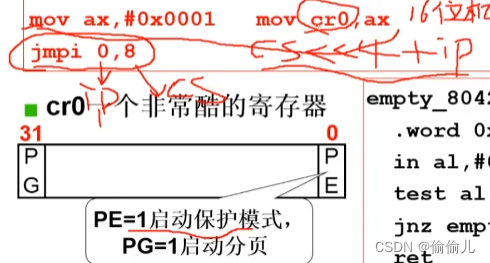
答:因为保护模式的 寄存器访存 为32位,约4GB。比实模式 16位左移 加 偏离为 20位 约 1MB大得多。
2. 根据gdt表项寻址
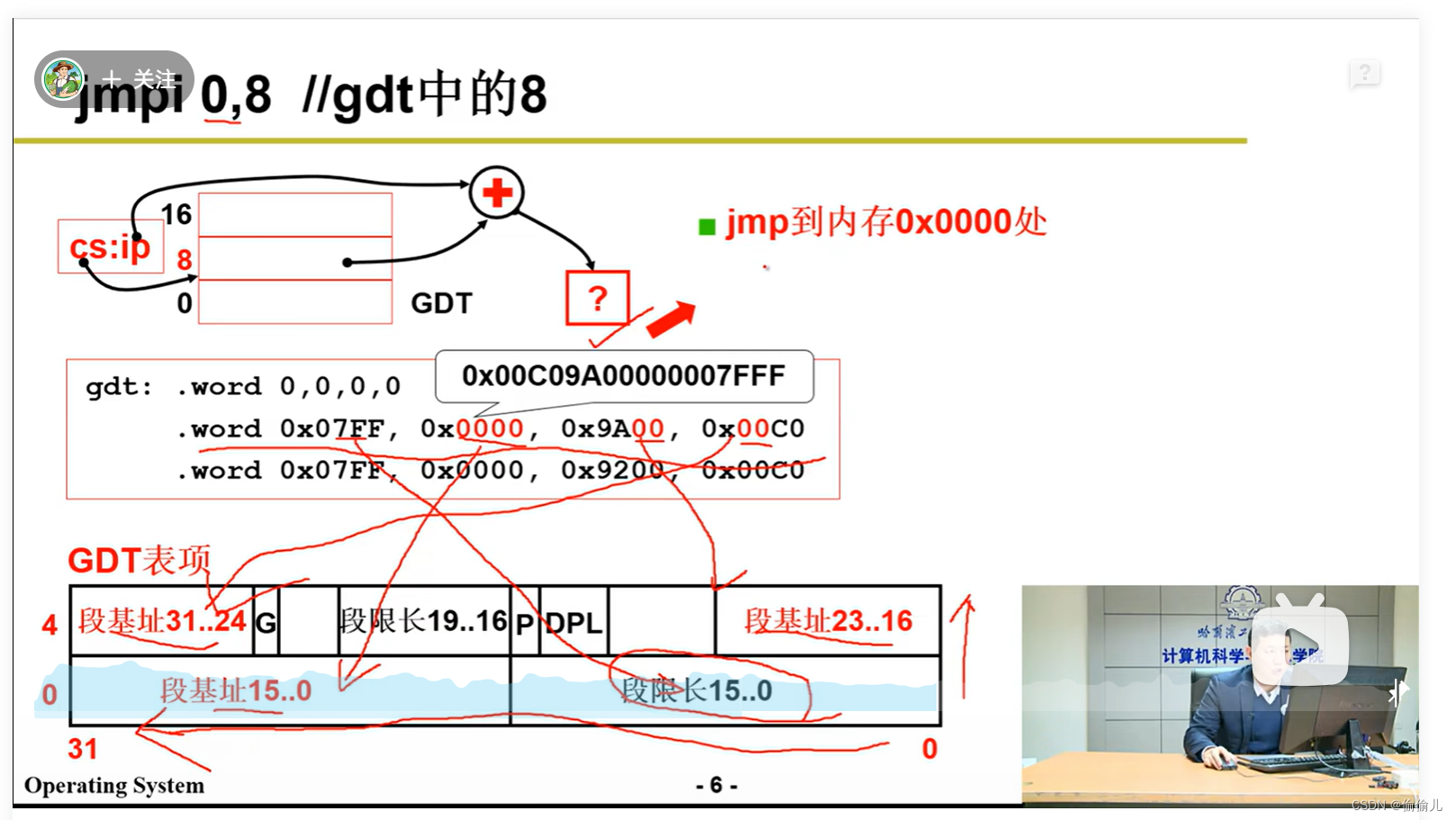
答:
2.1 在保护模式仍为 段基址 + 偏移,不过段基址保存在gdt表项中。段寄存器表示 表项的索引。
2.2 段寄存器 为 16位,在保护模式下的含义如下:
则 jmpi 0,8 即 8:0, 0x8, 高13位表示index = 1

2.3 如gdt表项图 段基址 共占 32位,需要对号入座后需要拼接在一起,
limit_low = 0x07FF
base_low = 0x000000 前24位
base_high = 0x00
2.4 则最后的线性地址为 0x00000000 + 0x0000
3. 宏展开

答:
4. 内联汇编
答:参考 C语言内联汇编-CSDN博客
实验3 系统调用
1.对设置IDT表项的内联汇编的解释

答:
__asm__ (
"movw %%dx,%%ax\n\t" \
"movw %0,%%dx\n\t" \
"movl %%eax,%1\n\t" \
"movl %%edx,%2" \
: \
: "i" ((short) (0x8000+(dpl<<13)+(type<<8))), \ 0x8000 + 0x6000 + 0x0f00
"o" (*((char *) (gate_addr))), \ &idt[0x80]
"o" (*(4+(char *) (gate_addr))), \ &idt[0x80] + 4
"d" ((char *) (addr)),"a" (0x00080000)) edx = &systemcall, eax = 0x00080000
1.
edx = &systemcall, eax = 0x00080000
2.ax = dx = &systemcall的低16位
dx = 0x8000 + 0x6000 + 0x0f00
&idt[0x80] = eax,表项的低32位
&idt[0x80] + 4 = edx,4字节 即表项的高32位。
3.
由此可知idt[0x80]被置为:
0~15位,偏移值低16位,&systemcall的低16位
16~31位,段选择子,0x0008
32~47位,属性值,0x0x8000 + 0x6000 + 0x0f00,其中p = 1, dpl= 1148~63位,偏移值高16位,0x0000
2.系统调用小结:
为什么调用系统api函数时,需要调用触发int 0x80?
答: 从上文 初始化idt表项可知,会将
1.dpl改为3
2.段选择子置为0x8,则cpl 为0,
3. 段偏移为 systemcall.s 的地址 ,则可gpt寻址到内核代码systemcall了。
4. systemcall.s里 就会根据 触发int 0x80的同时 在eax中保存的系统调用号,查找数组,执行到最终的 系统函数了。
3. 添加系统函数的步骤
答: 从系统调用原理可知
1. 编写api,在对应头文件的添加 宏定义
如 在linux-0.11/lib下添加test.c
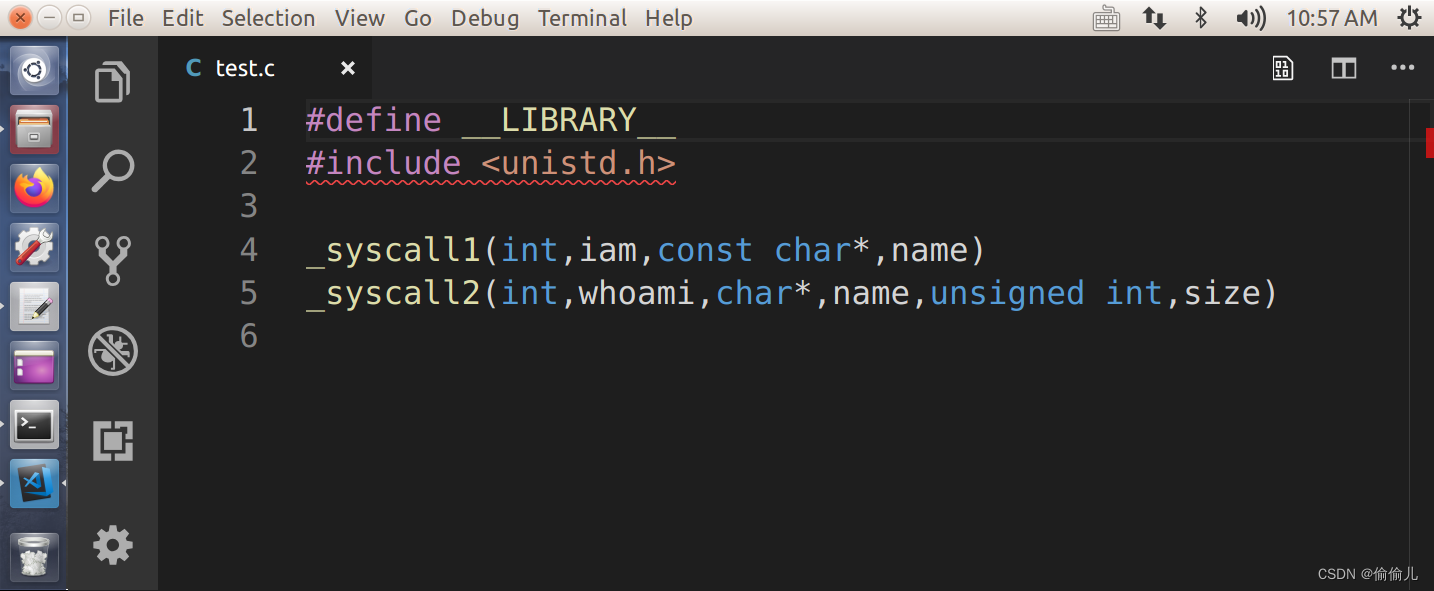
在 include/unistd.h中添加宏定义
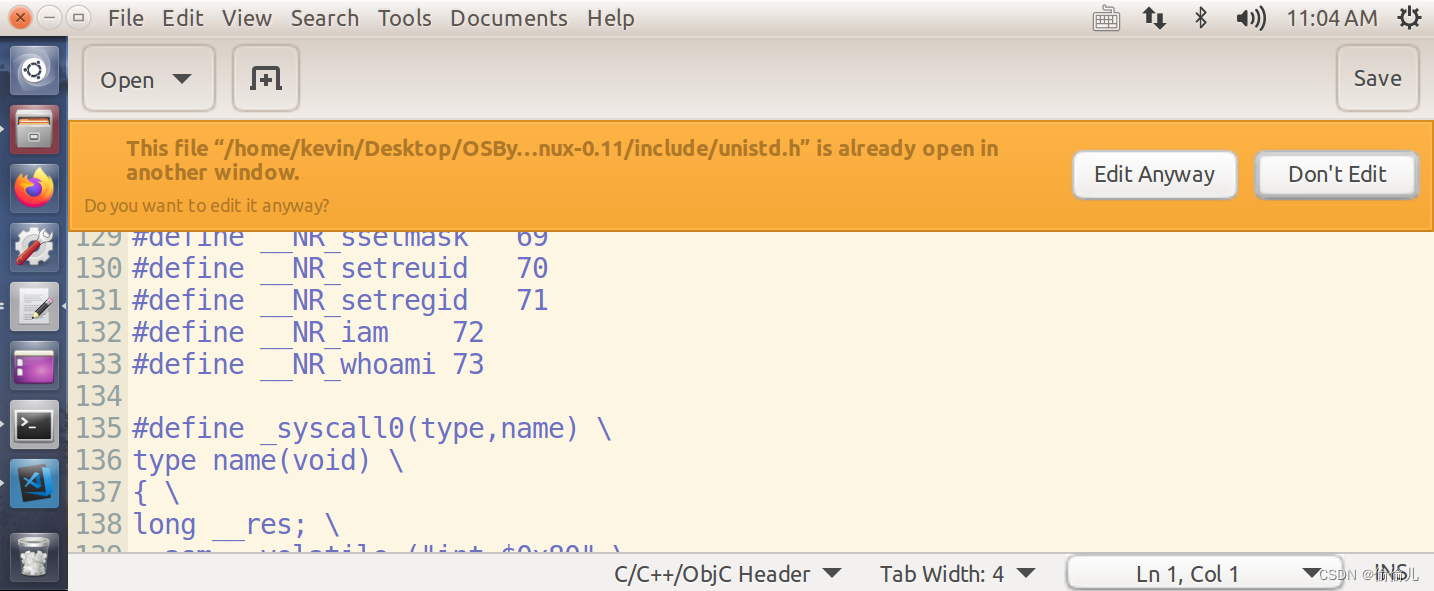
2. 实现 函数功能,并修改 system_call对应数组
修改include/linux/sys.h 中的system_call_table数组

实现函数
在 kenel下实现who.c
知识点:用户态和内核态传递数据,官方实验提示仅告知 从已有库函数抄

函数实现如下
#include <asm/segment.h>
#include <errno.h>
#include <string.h>char _myname[24];
int sys_iam(const char *name)
{
char str[25];
int i = 0;do
{
// get char from user input
str[i] = get_fs_byte(name + i);
} while (i <= 25 && str[i++] != '\0');if (i > 24)
{
errno = EINVAL;
i = -1;
}
else
{
// copy from user mode to kernel mode
strcpy(_myname, str);
}return i;
}int sys_whoami(char *name, unsigned int size)
{
int length = strlen(_myname);
printk("%s\n", _myname);if (size < length)
{
errno = EINVAL;
length = -1;
}
else
{
int i = 0;
for (i = 0; i < length; i++)
{
// copy from kernel mode to user mode
put_fs_byte(_myname[i], name + i);
}
}
return length;
}
3. 调用api测试
这里 可引入api文件,或直接api里直接写main
oslab下添加
/* iam.c */
#define __LIBRARY__
#include <unistd.h>
#include <errno.h>
#include <asm/segment.h>
#include <linux/kernel.h>
_syscall1(int, iam, const char*, name);
int main(int argc, char *argv[])
{
/*调用系统调用iam()*/
iam(argv[1]);
return 0;
}
/* whoami.c */
#define __LIBRARY__
#include <unistd.h>
#include <errno.h>
#include <asm/segment.h>
#include <linux/kernel.h>
#include <stdio.h>
_syscall2(int, whoami,char *,name,unsigned int,size);
int main(int argc, char *argv[])
{
char username[64] = {0};
/*调用系统调用whoami()*/
whoami(username, 24);
printf("%s\n", username);
return 0;
}
实验4 进程运行轨迹的追踪和统计
1.知识点 回顾
wait(&status): 回收所有子进程,返回子进程的状态,放在指针 &status 所指向的位置。
文件描述符:0 1 2 为固定文件描述符,dup(fd) 产生新的描述符,并指向同一文件。
2. 进程调度
参考 【哈工大李治军】操作系统课程笔记4:CPU和多进程 + 【实验 4】进程运行轨迹的跟踪与统计实验_哈工大李治军老师操作系统笔记【4】csdn-CSDN博客
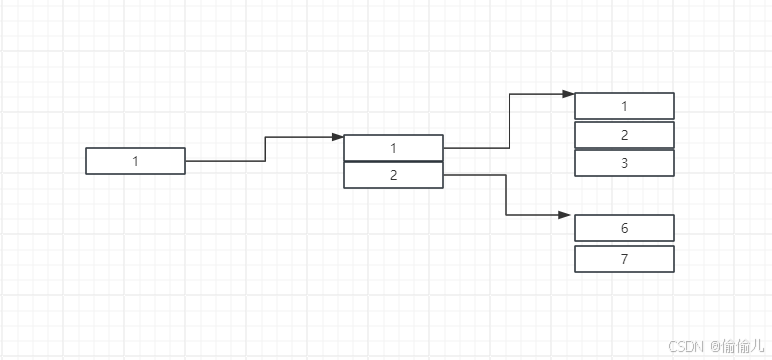
看懂sleep_on函数仅需要下面两张图



即
1.当前任务结构 加入链表的方式是:让链表头指针p指向自己,新产生的tmp(这样每个current对应一个tmp)指向旧的头(比当前任务先一步加入的任务)。
2.当 当前任务被唤醒后 会 返回继续执行 schedule()后面的 即163行后的,这样链表就会Last in Fisrt Out的依次被唤醒。
看懂 interruptible_sleep_on() 下面这张图。


即 由于当前任务 是属于 可被除wake_up()外的函数唤醒的话,被唤醒后 执行 schedule()后面的代码前 会检查 头指针是否等于 当前结构指针(谁执行当前代码 全局变量current就指向谁),若不是 就表明 我处在链表中间了,应该重新沉睡,等待被顺序唤醒。
看懂 调度函数 schedule
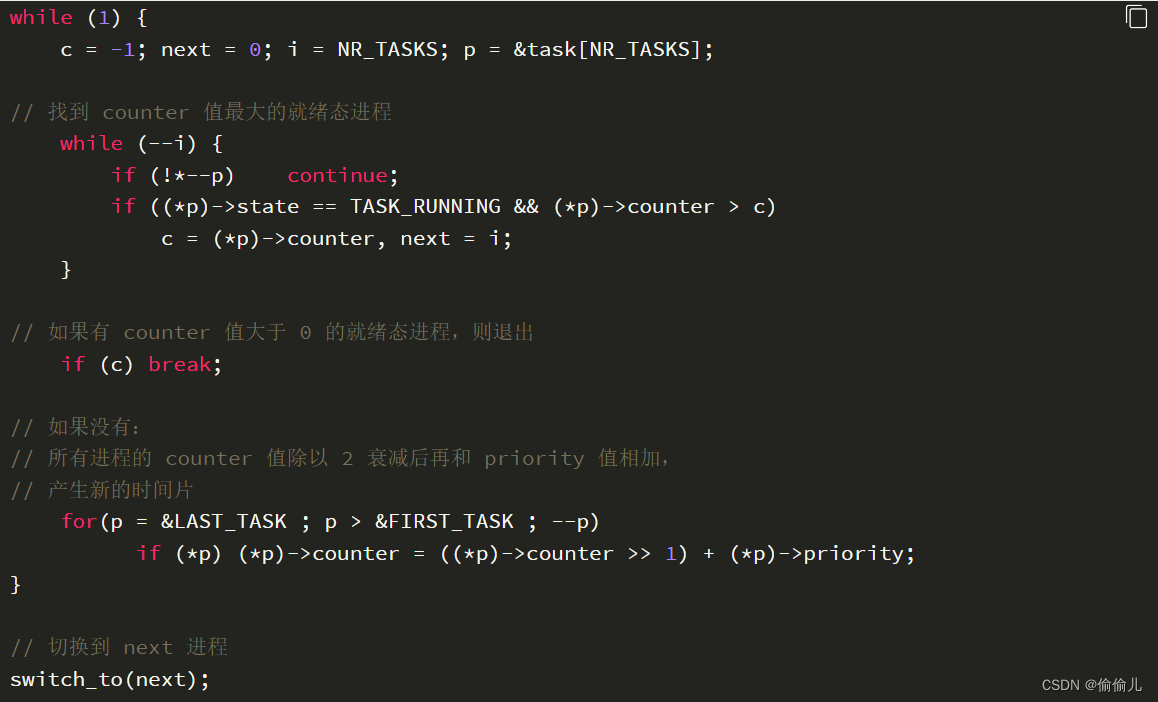
确实是 找到就绪状态 中 剩余时间片的任务 继续执行,即任何进程 只有当被唤醒(即状态被修改为 0/Task_running) 其时间片最大 才会继续执行。
看懂 主动睡眠sys_pause() 等


即 进入睡眠 只需要 两行代码 : 修改状态 ,调度函数。
之所以 sleep_on 还要额外 进入 阻塞队列中,是因为被动进入睡眠 是 需要按顺序唤醒的。
L12
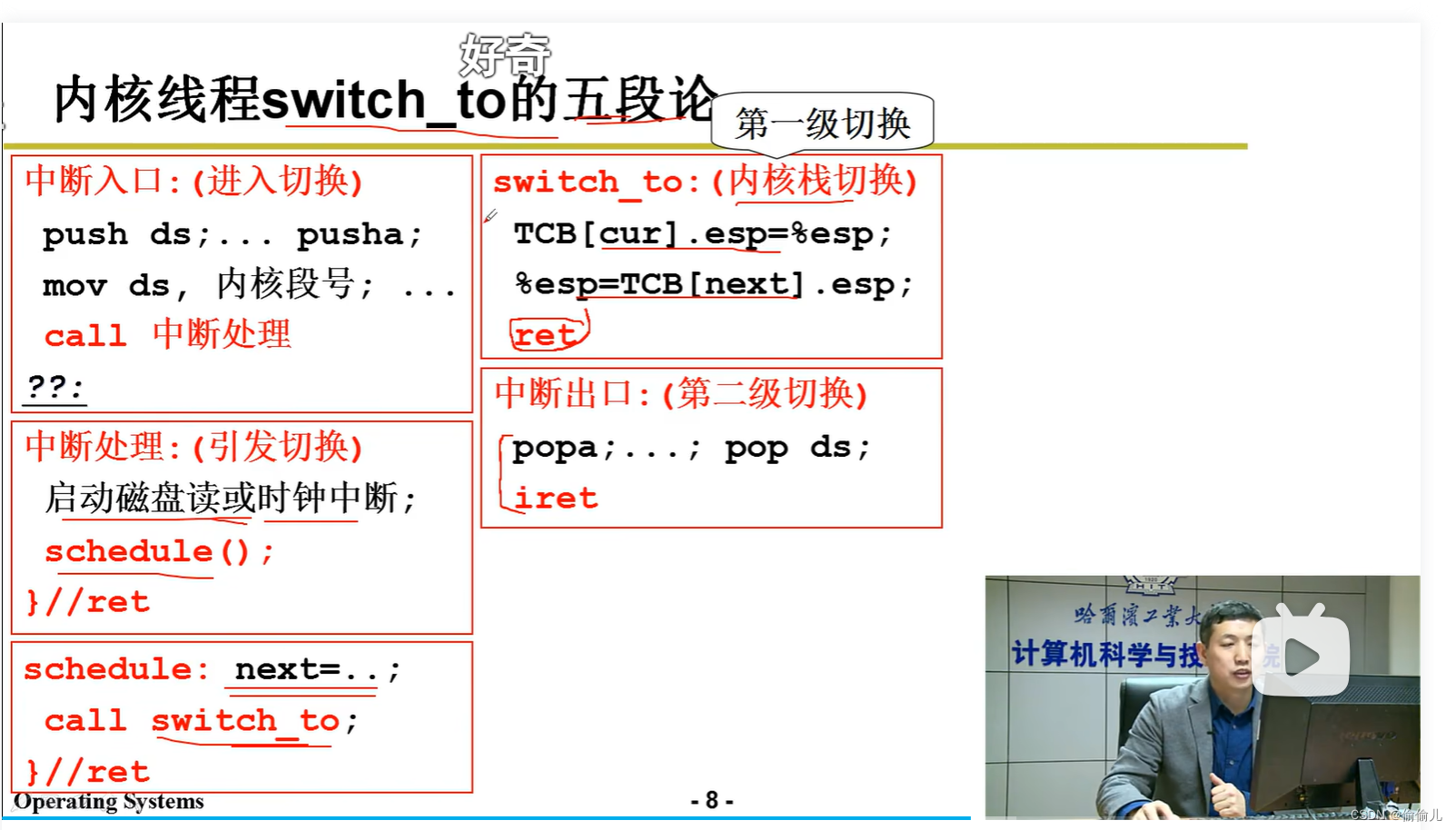
1. 用户栈 内核栈,以及如何相互切换(五段论) ?
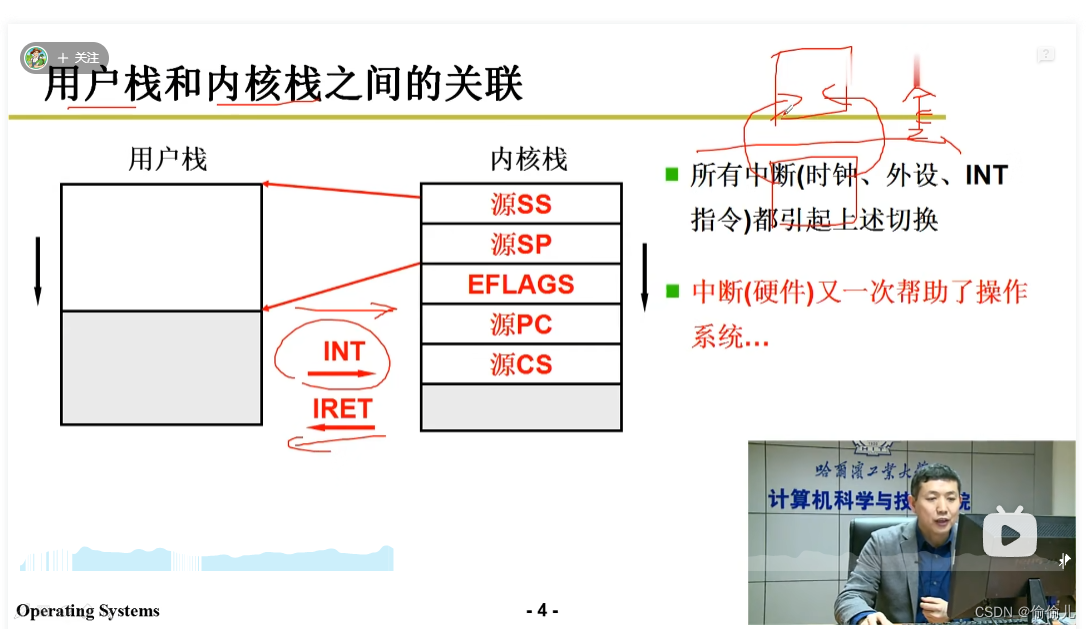
内核栈:
pc为模型机概念 为 cs:ip计算后得地址。
EFLAGS 标志寄存器
用户栈 =>内核栈,int0x80,压入固定得五个ss,sp,eflags,pc,cs
内核栈=>用户栈,iret 恢复中断前得状态 与 int指令 搭配。依次弹出这个五个
TCB切换,内核栈esp,TCB的概念 线程的五个信息。
L13
1. 时钟中断?
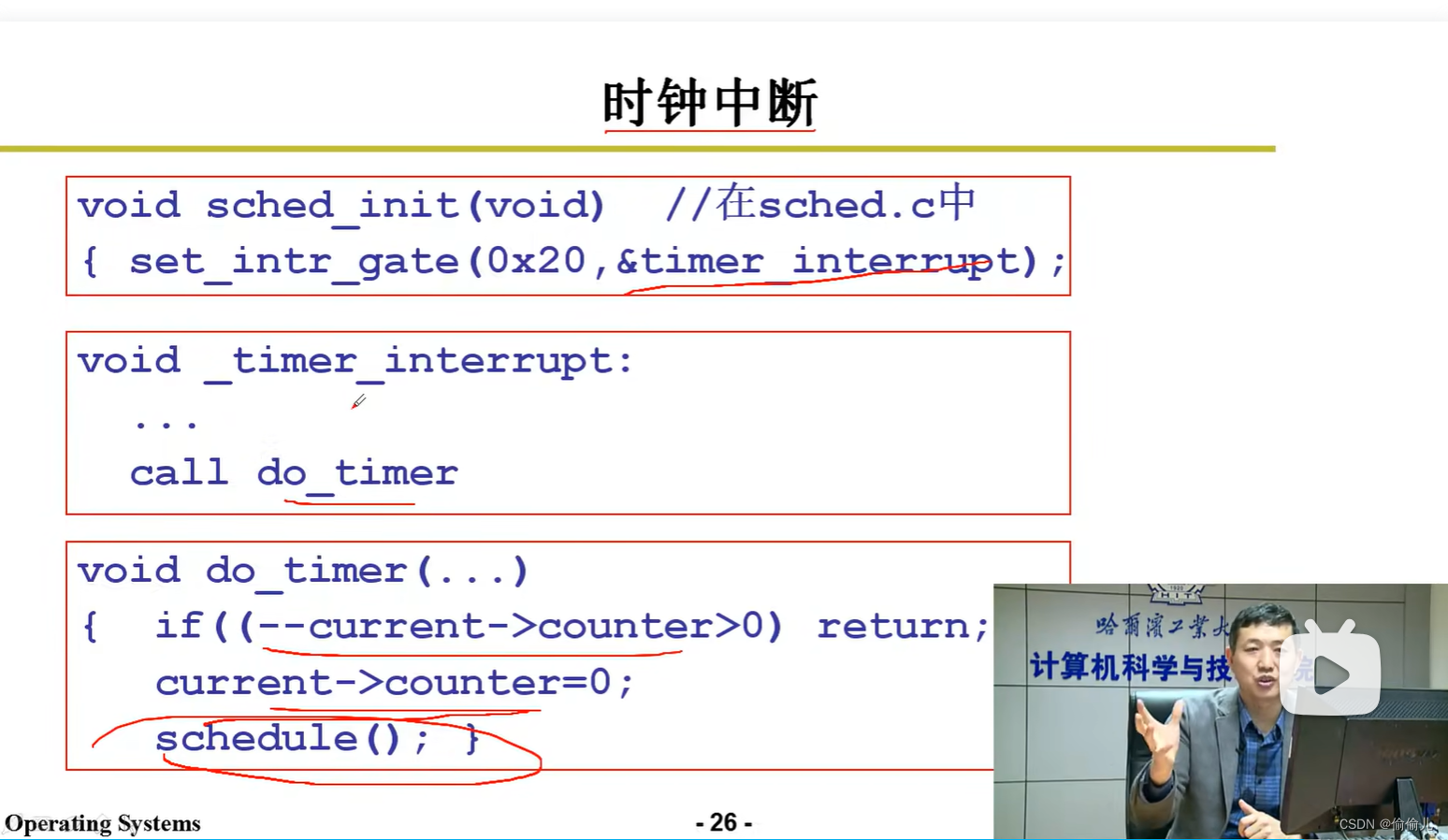
答: 定时中断信号可以由 系统定时器硬件产生,也可由进程的定时器产生。
2. PCB结构中的 元素 tss? eip ? esp?

答:
0. eip 保存了 父进程的 int0x80(sys_fork)后面的指令地址,则切换到子进程时就会从 fork()后执行。
1.tss包含了 如下图的寄存器内容,现在switch_to 是tcb.esp的直接切换,因为tss切换IO太多

2. 创建线程的时候 设置tss,设置tss.esp0 内核栈 对应tcb,tss.esp用户栈
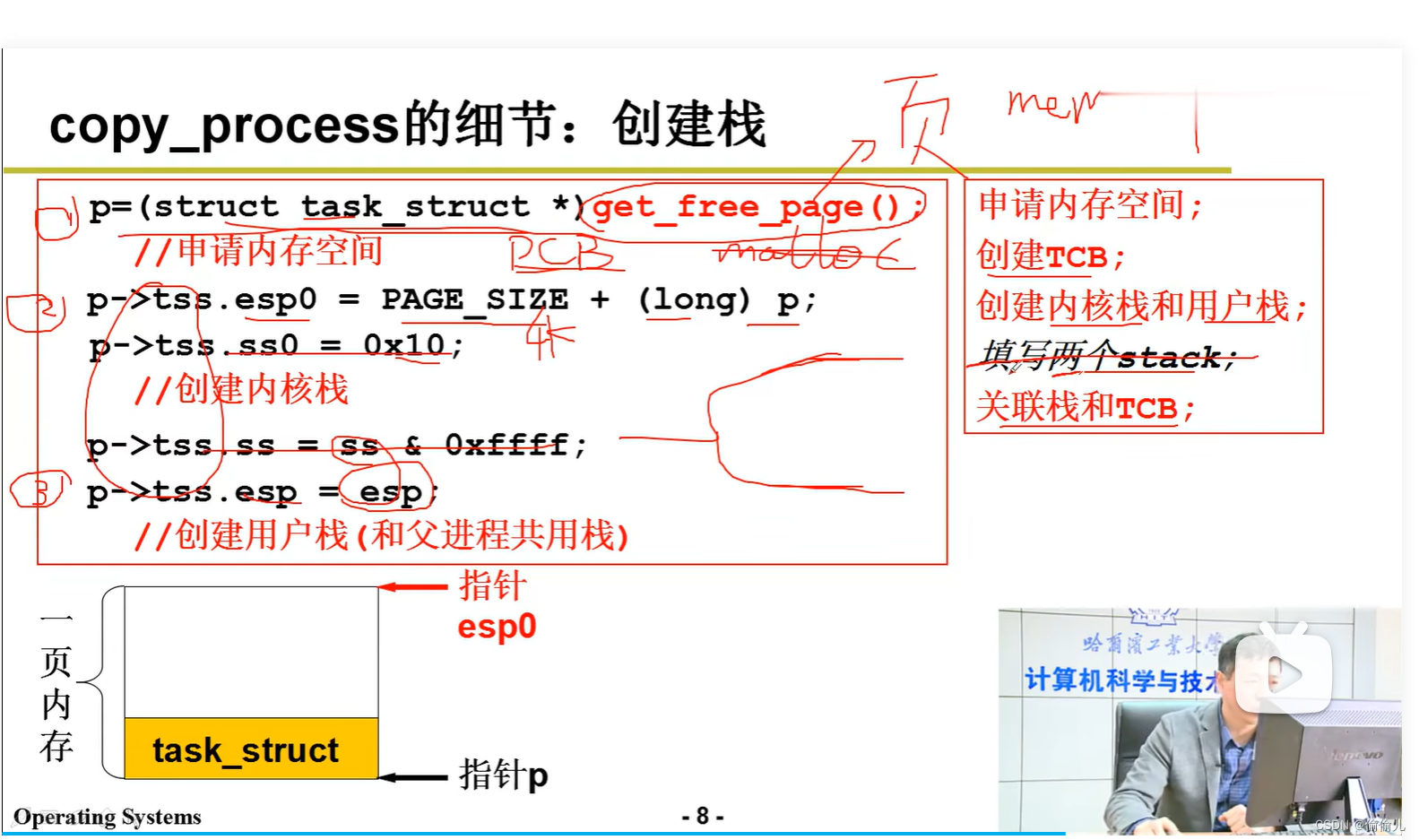
3.tss 小结:为进程的上下文信息,保存了几乎所有寄存器的信息。PCB的一部分。PCB具体结构参考 进程控制块:PCB之task_struct_tss与pcb-CSDN博客
4.tss 与 tcb 关系 => 线程与进程的关系:

即 早期只有 “task_struct”这个概念, pcb 这个任务既有 内存cpu资源 又有 任务切换, 线程理解为 共享进程资源的子任务 用tcb 表达。 猜想 可以把刚创建的进程 等价一个tcb(该进程就一个子任务 == 主任务)
实验5 基于内核栈切换的进程切换
1. 实验提示切换内容:
依次完成 PCB 的切换: current 指向下一个进程
TSS 中的内核栈指针的重写:由于共享同一个tss,则将一个进程的esp0 置过来
内核栈的切换: 寄存器 esp 指向下一个进程的esp.
LDT 的切换: 段表的切换
PC 指针(即 CS:EIP)的切换:即iret,执行下一个进程的用户代码,与reschedule成对出现的 ret_from_sys_call完成了这件事



2. 回顾五段论 具体需要切换哪些内容
核心就是 切换内核栈esp,然后iret 去支持用户代码。段表、页表等寻址资源也得切换,当然此版本未提及页表的概念。
L16~L19 信号量
讲的不好,不如参考《深入理解计算系统》相关章节:
1.从进度图的角度,论证了信号量如何保护线程安全的/互斥锁
2.在生产者 消费者模型中,除了引入了mutex信号量表示互斥,还引入了 货物数,剩余槽数作为信号量表示 立即通知 对立线程去工作 而非随机通知。
L22 多级页表思想
问题:绝大部分页表项 不会被使用,若直接去掉,则会导致 二分查找不如 连续时直接偏移定位,但不去又占内存空间。
方案:多级页表 每一小块之间是连续的。形如:弃掉未被使用的表项,分成连续的小块。
实验6 地址映射与共享
明白 段基址 + 段内偏移 = 虚拟地址 虚拟地址 = 页目录 + 页号+ 偏移 , 段基址 存在于段表LDT中。即地址翻译过程即可。可参考 《深入理解计算机》9.6节
L27 L28 键盘 屏幕等外设
基本概念:1.操作系统 将其统一封装为文件(open, write, read),2.从底层汇编指令 即 (in 端口,数据/寄存器),(out 端口,数据/寄存器)。
中间的封装的代码:偏向 设备驱动方向,可略。
L29 ~L30 生磁盘到文件的封装
可略
L31 L32 目录结构 与 文件系统
简要介绍了数据结构:多级索引结构,为了便于查找,树结构 节点仅保存下一级得索引号,inode数据单独存放