一、选择题
1.在假设检验问题中,犯第一类错误是指 ____B_____。
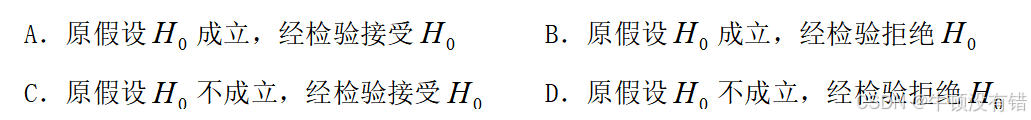



二、计算题
1、从发生交通事故的司机中抽取2 000名司机作随机样本,根据他们血液中是否含有酒精以及他们是否对事故负有责任将数据整理如下:
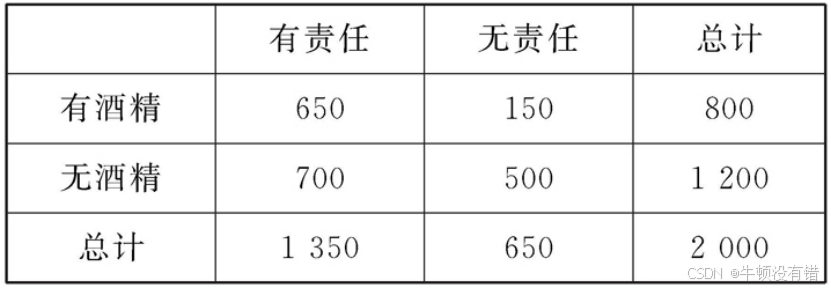
试分析血液中含有酒精与对事故负有责任是否有关系。

# 卡方独立性检验
import numpy as np
from scipy.stats import chi2_contingency
from scipy.stats import chi2
data1=np.array([[650, 700], [150, 500]]) #要检验的数据
g, p, dof, re, expctd,cv= chi2_independence(alpha1, data1)
if re==0:
result="接受假设"
else:
result="拒绝假设,认为事故责任与饮酒有关"
print("卡方值={},临界值cv={},自由度={},结论={}".format(round(g,2),round(cv,2),dof,result))2. 给定数据集test.-kmo-bartlett.xls,试编程进行KMO、Bartlett检验,判定该数据集是否具有相关性?是否适合进行因子分析?给出检验结果:Bartlett的p值,KMO值
# 数据处理
import pandas as pd
import numpy as np
# 绘图
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv("test-kmo-bartlett.csv", encoding='utf-8', index_col=0).reset_index(drop=True)
# Bartlett's球状检验
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
chi_square_value, p_value = calculate_bartlett_sphericity(df)
print("卡方值:{:.2f},p-value:{:.2f}".format(chi_square_value,p_value))
# KMO检验
from factor_analyzer.factor_analyzer import calculate_kmo
kmo_all, kmo_model = calculate_kmo(df)
print("kmo:{:.2f}".format(kmo_model))
-------------------------------------
适合进行因子分析
卡方值:216.20,p-value:0.00
kmo:0.84