数据集净化作为一种主动防御手段,通过移除恶意训练样本来从源头上防止后门注入。本文首先揭示了当前先进的净化方法依赖于一个潜在假设:后门攻击中触发器与目标标签之间的连接比良性特征更容易学习。然而,我们证明这一假设并不总是成立,尤其是在全对全(A2A)和无目标(UT)攻击中。因此,依赖于分析输入-输出空间或最终隐藏层空间中中毒样本与良性样本分离的净化方法效果较差。
我们观察到,这种可分离性并不局限于单一层,而是在不同隐藏层之间变化。基于这一发现,我们提出了FLARE,一种通用的净化方法,用于应对各种后门攻击。FLARE 通过聚合所有隐藏层的异常激活来构建聚类表示。为了增强分离效果,FLARE 开发了一种自适应子空间选择算法,以隔离最佳空间,将整个数据集分为两个簇。FLARE 评估每个簇的稳定性,并将稳定性较高的簇识别为中毒样本。 在基准数据集上的广泛评估表明,FLARE 对 22 种代表性后门攻击(包括全对一(A2O)、全对全(A2A)和无目标(UT)攻击)具有显著效果,并且对自适应攻击具有鲁棒性。
中毒样本和良性样本并不总是在特定层中分离,而是在不同隐藏层中表现出差异,且差异随攻击类型而变化。
全谱学习分析以移除嵌入的中毒样本(FLARE)。FLARE 包括两个主要阶段:潜在表示提取和中毒样本检测。在第一阶段,FLARE 通过整合所有隐藏层特征图中的异常值,为每个训练样本构建全面的潜在表示。在第二阶段,FLARE 通过聚类分析检测中毒样本。具体来说,FLARE 将整个数据集分为两个不同的簇,并将稳定性较高的簇识别为中毒样本。
相关工作
根据防御发生的阶段,现有防御可以分为五大类:(1)数据集净化,专注于在模型训练前检测并移除可疑数据集中的中毒样本;(2)中毒抑制,通过修改训练过程来限制中毒样本的影响;(3)模型级后门检测 ,评估可疑模型是否包含隐藏的后门;(4)输入级后门检测,在推理阶段识别恶意输入;(5)后门缓解 ,在模型开发后直接移除后门
数据集净化:现有策略可分为四类:(1)基于潜在可分离性的净化,(2)基于早期收敛的净化,(3)基于主导触发器效应的净化(4)基于扰动一致性的净化。然而,本文发现现有方法在某些情况下表现不佳,尤其是针对 A2A 和 UT 攻击时。
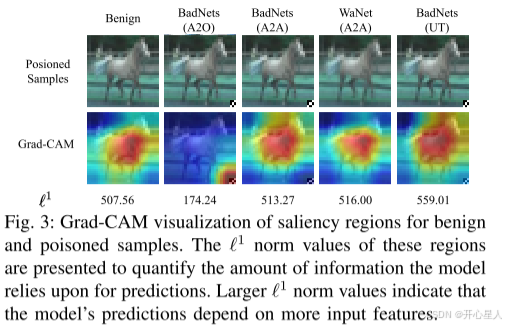
具体来说,基于潜在可分性的防御利用了中毒样本在特征空间中留下的可检测痕迹。例如,Chen et al. [3] 观察到,在最终隐藏层的特征空间中,目标类别的样本形成了两个明显的簇,较小的簇被识别为中毒样本。Ma et al. [30] 利用高阶统计(即Gram矩阵)来分析中毒样本和良性样本之间的差异;基于早期收敛的防御依赖于观察到DNN在中毒样本上比在良性样本上收敛得更快。在训练的初期阶段,中毒样本的损失迅速降至接近零,而良性样本的损失保持较高。例如,[19],[53] 中的研究者使用局部梯度上升技术,在前五个训练周期内捕捉到损失下降较快的样本。为了缓解类不平衡问题,Gao et al. [7] 通过选择每个类别中的最低损失样本来改进该方法,而不是在整个数据集上选择;基于主导触发器的防御假设后门触发器在DNN预测中占据主导地位。后门模型往往学习到一个极强的后门触发器信号,即使是小的局部触发器也能压倒其他语义特征并决定模型的预测。 例如,Chou et al. [5] 利用模型可解释性技术(如Grad-CAM [40])可视化输入图像的显著区域,识别出异常小的区域作为潜在的触发器区域。类似地,Huang et al. [15] 从输入图像中提取出影响模型预测的最小模式,并将含有异常小模式的图像识别为中毒样本;基于扰动一致性的防御假设中毒样本对扰动具有抗性。例如,Guo et al. [11] 观察到中毒样本在像素级放大下具有预测一致性,并提出通过分析这种一致性来区分中毒样本 。为了应对像素值的约束和对放大的不敏感性,Pal et al. [36] 针对选择性像素放大优化了一个掩膜;Qi et al. [38] 通过“忘记”回归模型的良性连接分析预测一致性;而Hou et al. [14] 研究了在无界权重放大下的预测一致性。
重新审视现有的数据集净化方法
然而,本文发现所有现有方法在某些情况下表现不佳。具体而言,第一类净化方法通常仅利用特定层的信息(例如,最后一个隐藏层),并且可以被高级攻击 [37] 轻松绕过。我们还将展示,最后三类方法依赖于一个不总是成立的假设,特别是在A2A和UT攻击下。如何设计有效的数据集净化方法仍然是一个重要的未解问题。
重新审视策略 :早期收敛
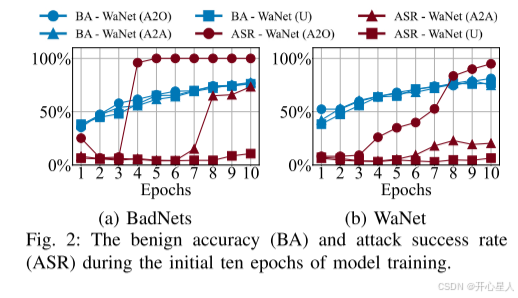
如图 2 所示,BadNets (A2O) 和 WaNet (A2O) 攻击的 ASR 迅速接近 100%。然而,其他攻击的 ASR 仍然低于 BA,UT 攻击甚至接近 0%。这些结果表明,在 A2A 和 UT 攻击中,DNN 对毒化样本的收敛速度并不快,这表明后门连接比良性连接更容易学习的假设在 A2A 和 UT 攻击中不成立。
重新审视策略 :主导触发器效应
重新审视策略 :扰动一致性

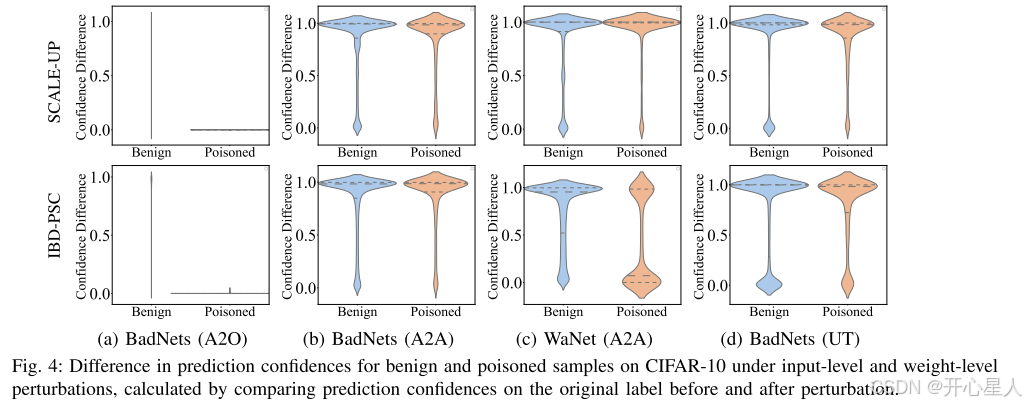
如图 4 所示,对于 BadNets (A2O),在像素级和权重级扰动下,差异始终接近于零。这表明这些毒化样本的预测不受此类扰动的影响。相比之下,在 A2A 和 UT 攻击下,毒化样本的置信度差异接近 1,表明扰动显著改变了毒化样本的预测。毒化样本对扰动的敏感性与良性样本相似,表明 DNN 在 A2A 和 UT 攻击中难以过度拟合毒化样本。因此,后门连接比良性连接更容易学习的假设在 A2A 和 UT 攻击中不成立。
重新审视特定层的潜在可分离性
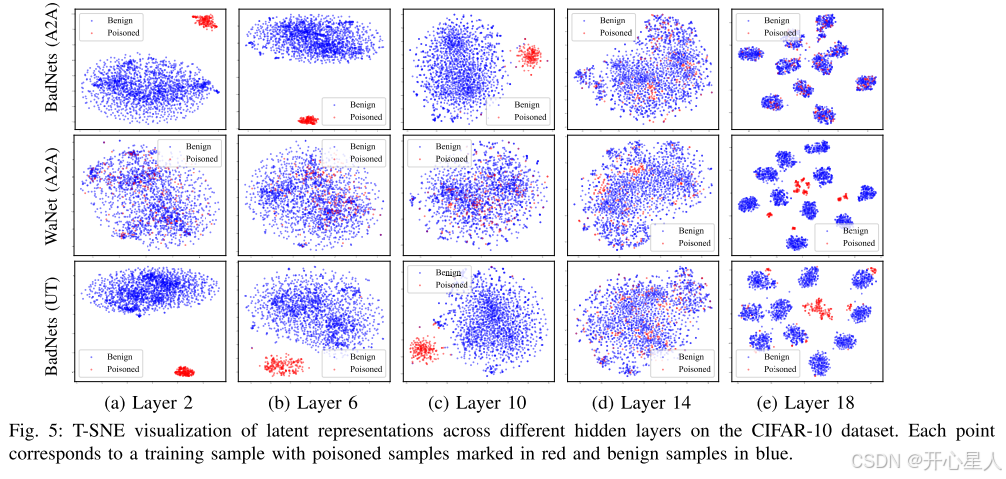
如图 5 所示,毒化和良性样本在特定层中并不总是表现出可分离性。例如,在 BadNets (A2A) 和 BadNets (UT) 攻击下,可分离性在浅层和中层(如第 6 层或第 10 层)中明显,但在深层中减弱。相比之下,在 WaNet (A2A) 下,大多数层中可分离性不明显。这些观察挑战了现有基于潜在可分离性的净化方法中的隐含假设,即后门触发器是稀疏嵌入的,并且主要影响深层特征表示,强调了在整个模型中评估毒化样本在多个层中的广泛影响的必要性,而不是将分析限制在单一层。
方法
FLARE由两个主要阶段组成:
(1)潜在表示提取:对于每个样本,FLARE通过合并所有隐藏层的特征图中的异常值来构建全面的潜在表示。具体而言,FLARE首先使用批处理归一化(BN)层的统计信息将所有特征图的值对齐到统一的比例。然后,对于每个训练样本,FLARE从每个对齐的特征图中提取异常大或异常小的值,并聚合所有隐藏层中的异常值以构建最终的潜在表示。
(2)中毒样本检测:FLARE通过聚类分析检测中毒样本。具体而言,FLARE降低每个最终潜在表示的维度,然后通过自适应地排除最后几个隐藏层的表示来选择稳定的子空间。FLARE在最佳子空间中执行聚类分析,将整个数据集分为两个聚类,并将聚类稳定性较高的聚类标识为中毒。
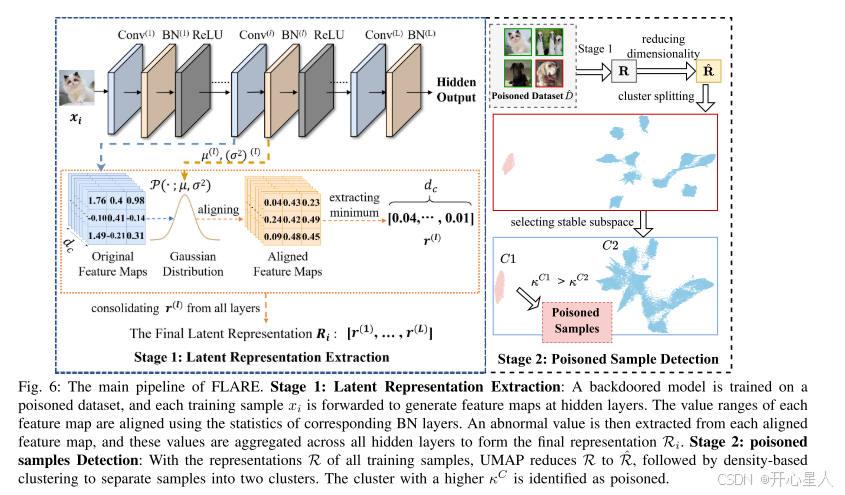

中毒样本检测是比较关键核心的部分


