- 《opencv优秀文章集合》
- 《learnopencv系列一:使用神经网络进行特征匹配(LoFTR、XFeat、OmniGlue)、视频稳定化、构建Chrome Dino游戏机器人》
- 《learnopencv系列二:U2-Net/IS-Net图像分割(背景减除)算法、使用背景减除实现视频转ppt应用》
- 《learnopencv系列三:GrabCut和DeepLabv3分割模型在文档扫描应用中的实现》
一、视频转幻灯片应用
许多时候,在YouTube等平台上发布的讲座视频并未提供幻灯片。本文将介绍如何构建一个稳健的应用,使用基础帧差分和背景减除模型(如KNN和GMG) 将视频讲座转换为相应的幻灯片。
1.1 什么是背景减除?
1.1.1 背景减除简介
背景减除是一种用于将视频序列中的前景物体与背景分离的技术,其基本思想是对场景背景建模并从每一帧中减去,以获得前景物体。这在物体跟踪、活动识别和人群分析等许多计算机视觉应用中都非常有用。因此,我们可以将这一概念扩展到将幻灯片视频转换为相应幻灯片的任务,其中运动的概念体现在视频序列中的各种动画中。
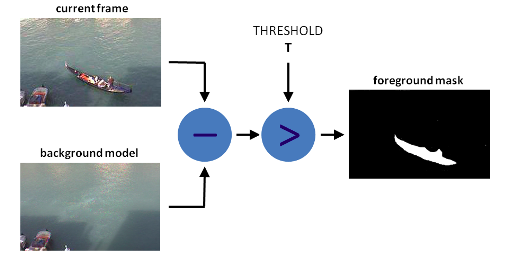
背景建模主要包括三个步骤:
- 背景模型初始化:通过一系列图像帧建立初始的背景模型。
- 前景检测:当前帧与背景模型进行差分,差异较大的像素点被视为前景。
- 背景模型更新:将当前帧的部分信息更新到背景模型中,以适应场景中的变化(如光照变化)。
背景估计也可以应用于运动跟踪应用,如交通分析和人群检测等。文章《background estimation for motion tracking 》将帮助您更好地理解这一概念。
1.1.2 bgslibrary
bgslibrary(Background Subtraction Library)是一个开源的背景减除(背景分割)库,基于C++开发,使用OpenCV进行图像处理,实现了40多种常用的背景建模和背景减除算法,并可在Windows、Linux和MacOS系统上运行。bgslibrary支持的算法包括但不限于:
- 基本算法:
- Frame Difference
- Static Frame Difference
- 统计模型:
- Gaussian Mixture Model (GMM)
- Kernel Density Estimation (KDE)
- Adaptive Background Learning
- 自适应模型:
- ViBe (Visual Background Extractor)
- PBAS (Pixel-Based Adaptive Segmenter)
- SuBSENSE
- 非参数方法:
- Fuzzy Choquet Integral
- Multi-Layer Background Subtraction
- 深度学习方法:还支持一些基于深度学习的背景减除算法(需要额外的依赖项)。
windows系统中直接使用pip install pybgs安装,如果是linux系统,可以通过以下步骤安装:
-
安装依赖项:需要先安装OpenCV,并确保CMake已安装。
-
克隆库:
git clone https://github.com/andrewssobral/bgslibrary.git -
构建和编译:
cd bgslibrary mkdir build cd build cmake .. make
示例代码:
import cv2
import pybgs
# 打开视频文件或摄像头
capture = cv2.VideoCapture("video.mp4") # 或者使用 0 打开摄像头
# 使用 SuBSENSE 算法进行背景减除
bgs = pybgs.SuBSENSE()
while True:
ret, frame = capture.read()
if not ret:
break
# 进行背景减除,获取前景掩码
foreground_mask = bgs.apply(frame)
# 显示原始帧和前景掩码
cv2.imshow("Frame", frame)
cv2.imshow("Foreground Mask", foreground_mask)
# 按下 'q' 键退出循环
if cv2.waitKey(30) & 0xFF == ord('q'):
break
# 释放视频对象并关闭窗口
capture.release()
cv2.destroyAllWindows()
更多示例见《bgslibrary-examples-python》。
1.2 OpenCV背景减除技术
一个常见的问题是,能否仅通过前后帧的差分来建模背景。虽然这种方法在静态帧的视频中有效,但对于动画显著的视频效果不佳。因此,对于有显著动画的视频,必须使用统计方法来建模背景,而不是简单的帧差分。OpenCV提供了多种背景分离方法:
| 背景减除算法 | 主要原理 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|---|
MOG2(Mixture of Gaussians) | 一种参数建模方法,利用高斯混合概率密度函数实现高效自适应算法 | 适应光照变化,支持阴影检测,适合动态背景以及具有多种颜色和纹理的复杂背景 | 会产生很多细小的噪点。对剧烈的光照变化、复杂场景效果有限 | 视频监控、交通监控、动态背景场景 |
KNN | 一种非参数建模方法,使用K近邻技术,利用历史帧信息判断背景和前景 | 对复杂背景和光线变化适应性强,适合动态环境 | 阴影处理能力弱,参数选择敏感 | 复杂环境的前景检测 |
GMG | 一种结合了统计学建模和贝叶斯估计的背景减除算法,通过短期的前景帧进行背景更新,并使用贝叶斯估计来获得最有可能的背景模型。 | 适应剧烈变化的环境,快速检测新运动物体 | 需要初始化时间较长,处理复杂场景效果不稳定 | 运动分析、场景剧烈变化的场合 |
-
MOG2背景减除算法函数解析:
cv2.createBackgroundSubtractorMOG2(history=500, varThreshold=16, detectShadows=True)history: 训练背景模型使用的帧数,值越大,背景模型对历史帧的考虑越多,适用于变化较慢的场景;值越小则适用于快速变化的场景。varThreshold: 决定是否将一个像素标记为前景的阈值。detectShadows: 是否启用阴影检测功能(True 时前景中的阴影部分会被标记为灰色区域)。
-
KNN背景减除算法函数解析
cv2.createBackgroundSubtractorKNN(history=500, dist2Threshold=400.0, detectShadows=True)history: 训练背景模型使用的帧数。dist2Threshold: 控制阈值,较大的值会减少误检。detectShadows: 是否检测阴影。
这些背景减除算法最终返回的是一个包含前景的掩模,移动的物体会被标记为白色,背景会被标记为黑色。背景减除算法的局限性:
- 光照变化:快速变化的光照可能会被误认为是前景。
- 动态背景:例如摇摆的树叶、波动的水面,这些场景中的变化难以通过简单的背景建模处理。
- 阴影处理:部分算法可以处理阴影,但阴影依旧可能导致误检。
在上述背景减除方法中,我们将使用GMG和KNN模型,因为它们相比于MOG2能够产生更好的效果。
1.3 差异哈希
在后处理部分,当我们使用帧差分或背景减除技术筛选并保存我们需要的视频帧之后,还是会有很多重复的帧,可以使用图像哈希技术进行处理,下面是 差异图像哈希的全文总结。
1.3.1 图像哈希技术
在FotoForensics平台,团队正计划启用新的色情内容过滤功能,以应对反复上传的少量违禁图像。目前的过滤器通过图像哈希来标记已知的违禁图片,但图像稍微变化就无法检测到。因此,需要一种方法来检测类似的图像。基本上,如果你有一个大型图片数据库并且想要找到相似的图片,那么你就需要一个生成加权比较的算法。
已尝试的几种哈希算法包括:
-
aHash(均值哈希):将图像缩小为8x8的灰度图,按像素亮度均值生成64位哈希。速度快,但误报率高。
-
pHash(感知哈希):使用离散余弦变换(DCT)基于频率生成哈希,准确性最好,但计算复杂,速度较慢。
-
dHash(差异哈希):按像素梯度生成哈希值,通过比较相邻像素的亮度变化生成64位哈希值,具有和aHash相当的速度但误报率更低。调整图像大小为9x8的差异哈希效果最佳,可忽略亮度、对比度变化甚至一些色彩校正的影响。
1.3.2 dHash算法
在dHash算法中,我们对图像进行处理,以生成一个简化的哈希值,用于描述图像的视觉特征。具体实现步骤如下:
-
缩小尺寸
有效去除高频细节最快方法是缩小图像。将图像缩小到一个9x8的灰度图,不仅能有效去除高频细节,也能确保生成的哈希值对图像的大小和比例变化保持一定的稳定性。- 为什么选择9x8?:9列提供8个水平差分值(即相邻像素亮度的差异),而8行产生64位哈希(8x8的差分矩阵)。这种尺寸使哈希对小的几何变换不敏感,比如轻微的拉伸或裁剪。
-
转为灰度图,去除色彩影响,
-
计算像素差异,生成哈希值
dHash的核心在于计算相邻像素间的亮度差异,以表示图像的局部梯度变化。具体步骤如下:- 对于缩小后的9x8图像中的每一行,从左到右,依次计算相邻像素的亮度差。
- 如果左侧像素亮度大于右侧像素,设置哈希位为1,否则设置为0。
- 每行生成8个位,总共8行,最终生成64位的哈希值。
-
哈希值的比较
dHash生成的64位哈希值通过汉明距离(Hamming Distance)来比较相似度:- 计算两个图像哈希之间的汉明距离,即两个哈希值的不同位数。
- 当距离接近0时,表示图像非常相似;距离越大,表明图像差异越大。通常设定一个阈值(如10),超过该阈值则认为两幅图像不同。
下面是一个Python示例代码,用于实现dHash算法:
from PIL import Image
def dhash(image, hash_size=8):
# 缩小图像并转换为灰度
resized = image.resize((hash_size + 1, hash_size), Image.ANTIALIAS).convert("L")
# 获取像素数据
pixels = list(resized.getdata())
# 计算像素差异
diff = []
for row in range(hash_size):
for col in range(hash_size):
left_pixel = pixels[row * (hash_size + 1) + col]
right_pixel = pixels[row * (hash_size + 1) + col + 1]
diff.append(1 if left_pixel > right_pixel else 0)
# 将二进制差异结果转为十六进制哈希
decimal_value = 0
hex_string = []
for index, value in enumerate(diff):
if value:
decimal_value += 2 ** (index % 8)
if index % 8 == 7:
hex_string.append(hex(decimal_value)[2:].rjust(2, '0'))
decimal_value = 0
return ''.join(hex_string)
# 使用示例
image = Image.open('example.jpg')
print(dhash(image))
1.3.3 图像哈希的速度和准确性测试
FotoForensics对150,000张图片进行了测试,以下是三种算法的测试结果和分析。
| 算法 | 速度 | 说明 | 适用场景 |
|---|---|---|---|
| 仅加载图像,不进行任何处理 | 16分钟 | 仅加载150,000张图像的情况下耗时16分钟,这为其他算法提供了一个速度基准。 | 文件加载基准 |
| 仅加载和缩放图像 | 3.75小时 | 图像缩放在大批量处理时会显著增加时间消耗 | 文件缩放基准 |
| aHash | 3.75小时 | 速度快,但误报率极高,比如一张应匹配32次的图片实际匹配到400多次 | 对准确性要求不高的大规模筛选 |
| pHash | 7小时以上 | 无误报,也无漏报(匹配的哈希差异值为2以下)。但计算复杂(需要离散余弦变换DCT),速度慢 | 精度要求高的场景 |
| dHash | 3.75小时 | 速度快(只需要简单的像素差分运算),误报少。比如一张应匹配2次的图片误报了4次,共匹配6次 | 需要平衡速度和准确性的快速筛选 |
通过对算法的实验测试表明,dHash在速度和准确性上是较优选择,但结合dHash和pHash可以获得更好的过滤效果,即先用dHash进行快速筛选,然后用pHash对筛选结果进一步确认,从而实现既高效又准确的匹配。FotoForensics也计划将dHash+pHash结合使用,过滤和检测违禁内容。
1.4 视频转幻灯片应用的工作流程
本应用应用同时采用帧差分技术(用于处理静态帧)和背景减除技术(用于处理动画较多的视频)来进行处理:
-
通过帧差分进行背景减除
- 灰度形式提取视频帧
- 计算连续帧之间的绝对差值,并经过一些形态学操作计算前景掩码的百分比
- 如果该百分比超过设定的阈值,我们将保存该帧。
-
背景减除技术
- 提取视频帧。
- 将每帧通过背景减除模型,生成二值掩码,并计算该帧中的前景像素百分比。
- 如果该百分比超过特定阈值 T1,则表示存在运动(在我们的例子中是动画),我们将等待运动稳定。一旦百分比降到阈值 T2 以下,我们将保存相应的帧。
1.5 项目代码
1.5.1 环境准备
以下是本项目的文件结构:
├── frame_differencing.py # 实现帧差分算法
├── post_process.py # 后处理模块
├── utils.py # 工具模块
└── video_2_slides.py # 主脚本,负责运行整个应用程序
文件video_2_slides.py包含运行应用的主要脚本,其他的是运行应用所需要的模块。注意: 你需要安装opencv-contrib-python才能应用GMG背景减除方法。另外,本项目使用的其他实用工具包括:
img2pdf:将生成的幻灯片图像转换为单个PDF文件。我们也可以使用PIL库将图像集转换为PDF,但该方法需要先打开每个图像,而使用img2pdf可以避免这个问题imagehash:使用一种被称为图像哈希的流行图像处理技术,去除所有相似生成的图像,用于生成相应的幻灯片图像之后进行的后处理步骤。
1.5.2 辅助模块
先介绍utils模块中create_output_directory函数,其作用是创建一个用于存储生成的幻灯片图像和最终PDF文件的输出目录。
def create_output_directory(video_path, output_path, type_bgsub):
# 从视频路径中提取文件名,并构造输出目录的完整路径
vid_file_name = video_path.rsplit('/')[-1].split('.')[0]
output_dir_path = os.path.join(output_path, vid_file_name,
type_bgsub)
# 如果已经存在输出目录,则删除。
if os.path.exists(output_dir_path):
shutil.rmtree(output_dir_path)
# 创建输出目录。
os.makedirs(output_dir_path, exist_ok=True)
print('Output directory created...')
print('Path:', output_dir_path)
print('***'*10,'\n')
return output_dir_path
video_path:视频文件的路径。output_path:生成的图像幻灯片要存储的输出目录路径。type_bgsub:要执行的背景减除算法,比如Frame_Diff、KNN或GMG。
接着是convert_slides_to_pdf函数,其作用是将生成的幻灯片图像转换为单个PDF文件,该函数接受create_output_directory的video_path和output_path。
def convert_slides_to_pdf(video_path, output_path):
pdf_file_name = video_path.rsplit('/')[-1].split('.')[0]+'.pdf'
output_pdf_path = os.path.join(output_path, pdf_file_name)
print('Output PDF Path:', output_pdf_path)
print('Converting captured slide images to PDF...')
with open(output_pdf_path, "wb") as f:
f.write(img2pdf.convert(sorted(glob.glob(f"{output_path}/*.png"))))
print('PDF Created!')
print('***'*10,'\n')
这两个函数共同工作,首先创建一个输出目录以存放生成的幻灯片,然后将这些幻灯片合并为一个PDF文件,简化了从视频到幻灯片的转换过程。
1.5.3 使用帧差分进行背景减除
# 1. 初始化变量
prev_frame = None
curr_frame = None
screenshots_count = 0 # 跟踪过程中保存的截图数量
capture_frame = False # 决定是否捕获当前帧(是否有明显变化)
frame_elapsed = 0 # 自上次捕获帧以来经过的帧数
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (7,7)) # 创建椭圆形7*7卷积核
# 2. 读取视频第一帧并保存(第一帧肯定是要保存在最终幻灯片图集里)
cap = cv2.VideoCapture(video_file)
success, first_frame = cap.read()
if success:
# 将帧转换为灰度。
first_frame_gray = cv2.cvtColor(first_frame, cv2.COLOR_BGR2GRAY)
prev_frame = first_frame_gray
screenshots_count+=1
filename = f"{screenshots_count:03}.png"
out_file_path = os.path.join(output_dir_path, filename)
print(f"Saving file at: {out_file_path}")
# 保存帧。
cv2.imwrite(out_file_path, first_frame)
循环处理后续帧:
- 将当前帧转换为灰度图像,并与前一帧进行比较,计算差异
- 对差异图像进行二值化处理,阈值设置为80。
- 对二值化后的差异图像进行膨胀操作,以捕捉更多的运动。
- 计算非零像素的百分比,如果这个百分比大于或等于
MIN_PERCENT_THRESH(保持为0.06),则认为当前帧有显著运动,设置capture_frame=True。 - 如果检测到显著运动,并且自上次捕获帧以来经过的帧数
frame_elapsed达到ELAPSED_FRAME_THRESH,则保存当前帧为图像文件,并重置capture_frame标志和帧间隔计数frame_elapsed。 - 更新
prev_frame为当前帧,以便在下一次迭代中使用。
# 3. 循环处理每一帧
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
curr_frame = frame_gray
frame_diff = cv2.absdiff(curr_frame, prev_frame)
_, frame_diff = cv2.threshold(frame_diff, 80, 255, cv2.THRESH_BINARY)
# 执行膨胀以捕获运动。
frame_diff = cv2.dilate(frame_diff, kernel)
# 计算帧中非零像素的百分比。
p_non_zero = (cv2.countNonZero(frame_diff) / (1.0*frame_gray.size))*100
if p_non_zero>=MIN_PERCENT_THRESH and not capture_frame:
capture_frame = True
elif capture_frame:
frame_elapsed+=1
if frame_elapsed >= ELAPSED_FRAME_THRESH:
capture_frame = False
frame_elapsed=0
screenshots_count+=1
filename = f"{screenshots_count:03}.png"
out_file_path = os.path.join(output_dir_path, filename)
print(f"Saving file at: {out_file_path}")
cv2.imwrite(out_file_path, frame)
# 4. 更新prev_frame为当前帧,以便在下一次迭代中使用
prev_frame = curr_frame
# 5. 统计并释放资源
print('***'*10,'\n')
print("Statistics:")
print('---'*5)
print(f'Total Screenshots captured: {screenshots_count}')
print('---'*10,'\n')
cap.release()

frame_elapsed 变量和 ELAPSED_FRAME_THRESH 阈值的设置是为了控制捕获帧的频率, 避免过度捕获,同时提高效率。如果每次检测到显著运动就立即保存帧,可能会导致连续保存多个相似的帧,尤其是在快速运动的场景中。这可能会导致输出的图像文件数量过多,且包含大量重复信息。
基于多次实验,设 ELAPSED_FRAME_THRESH=85 效果较好。不同的视频场景中,运动的频率和速度可能不同,需要适当调整。
1.5.2 使用OpenCV对背景像素进行统计建模
上述简单的帧差分方法只适用于视频中主要包含静态帧的场景。对于那些包含太多动画的视频,需要使用统计方法对背景像素进行建模,比如GMG,下面是完整流程:
import os
import time
import sys
import cv2
import argparse
from frame_differencing import capture_slides_frame_diff
from post_process import remove_duplicates
from utils import resize_image_frame, create_output_directory, convert_slides_to_pdf
# 初始化变量
FRAME_BUFFER_HISTORY = 15 # 用于背景建模的帧缓冲区历史长度
DEC_THRESH = 0.75 # 前景阈值
DIST_THRESH = 100 # 像素与样本之间距离的平方,用于决定像素是否接近该样本
MIN_PERCENT = 0.15 # 确定连续帧之间运动是否运动的阈值
MAX_PERCENT = 0.01 # 确定连续帧之间运动是否停止的阈值
def capture_slides_bg_modeling(video_path, output_dir_path, type_bgsub, history, threshold, MIN_PERCENT_THRESH, MAX_PERCENT_THRESH):
print(f"Using {type_bgsub} for Background Modeling...")
print('---'*10)
# 根据type_bgsub的值,初始化相应的背景减除器
if type_bgsub == 'GMG':
bg_sub = cv2.bgsegm.createBackgroundSubtractorGMG(initializationFrames=history, decisionThreshold=threshold)
elif type_bgsub == 'KNN':
bg_sub = cv2.createBackgroundSubtractorKNN(history=history, dist2Threshold=threshold, detectShadows=False)
capture_frame = False
screenshots_count = 0
# Capture video frames.
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print('Unable to open video file: ', video_path)
sys.exit()
start = time.time()
# 循环处理视频帧
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 复制原始帧以便后续保存
orig_frame = frame.copy()
# 调整帧大小至640宽度,保持宽高比
frame = resize_image_frame(frame, resize_width=640)
# 应用背景减除器得到前景掩码fg_mask
fg_mask = bg_sub.apply(frame)
# 计算前景掩码中非零像素的百分比p_non_zero
p_non_zero = (cv2.countNonZero(fg_mask) / (1.0 * fg_mask.size)) * 100
# 如果当前帧的前景像素百分比小于MAX_PERCENT阈值,这意味着帧中的运动已经停止
# 将capture_frame标志设置为True,准备捕获帧。
if p_non_zero < MAX_PERCENT_THRESH and not capture_frame:
capture_frame = True
screenshots_count += 1
png_filename = f"{screenshots_count:03}.png"
out_file_path = os.path.join(output_dir_path, png_filename)
print(f"Saving file at: {out_file_path}")
cv2.imwrite(out_file_path, orig_frame)
# 如果capture_frame已经被设置为True,但当前帧的前景像素百分比大于或等于MIN_PERCENT阈值
# 这意味着帧中又有新的运动发生,因此重置capture_frame为False,停止捕获帧。
elif capture_frame and p_non_zero >= MIN_PERCENT_THRESH:
capture_frame = False
# 统计和资源释放
end_time = time.time()
print('***'*10,'\n')
print("Statistics:")
print('---'*10)
print(f'Total Time taken: {round(end_time-start, 3)} secs')
print(f'Total Screenshots captured: {screenshots_count}')
print('---'*10,'\n')
cap.release()
video_path:视频文件的路径。output_dir_path:输出目录路径,其中快照和PDF将被存储。type_bgsub:我们想要选择的背景减除算法类型。例如,GMG或KNN。history:用于模拟背景的帧历史,默认15。threshold:相应背景减除算法所需的阈值。- 对于GMG,
decisionThreshold = 0.75,指超过该值就标记为前景的阈值, - 对于KNN,使用阈值
dist2Threshold =100(像素和样本之间的平方距离),以决定一个像素是否接近该样本。
- 对于GMG,
为了降低计算成本,我们禁用了detectShadows标志,并将帧调整到较低的尺寸,同时保持长宽比不变。下面是GMG背景减除和KNN背景减除的后得到的前景掩膜效果对比:
最后一步,我们可以将所有捕获的快照转换为单个pdf,也可以将快照转换为PowerPoint ppts!
1.5.3 后处理
现在我们已经使用背景建模获得了幻灯片图像,但此时许多生成的屏幕截图是大致相似。因此,我们需要消除这些图像中的相似或重复项。
我们使用图像哈希技术来识别相似的图像,而不是传统的加密哈希算法(如MD5或SHA-1),因为后者对像素值的微小差异过于敏感。目前有多种图像哈希方法,如平均哈希、感知哈希、差异哈希、小波哈希等。本应用选择使用差异哈希,因为它计算速度快,且比平均哈希和感知哈希更稳健。
我们使用imagehash库进行图像哈希处理,使用前可以通过pip install imagehash安装。差异哈希的函数调用形式为:
imagehash.dhash(PIL_Image, hash_size)
- 哈希算法的输入是PIL图像,而不是numpy数组
hash_size表示输出哈希值的大小(以位为单位)。例如,hash_size为8会产生一个64位的哈希值(8*8),以十六进制格式表示。- 增加哈希大小允许算法在其哈希中存储更多细节。对于我们的应用,设置
hash_size=12。
import imagehash
from PIL import Image
import os
# 该函数接受图像集目录路径和哈希大小作为参数
def find_similar_images(base_dir, hash_size=8):
# 对文件名进行排序
snapshots_files = sorted(os.listdir(base_dir))
hash_dict = {} # 存储图像集内的唯一哈希值
duplicates = [] # 存储相似图像文件
num_duplicates = 0 # 计算目录中重复图像的数量
print('---'*5,"Finding similar files",'---'*5)
# 遍历文件,更新hash_dict和duplicates列表,分别存储相似文件的哈希值和文件名。
for file in snapshots_files:
read_file = Image.open(os.path.join(base_dir, file))
comp_hash = str(imagehash.dhash(read_file, hash_size=hash_size))
if comp_hash not in hash_dict:
hash_dict[comp_hash] = file
else:
print('Duplicate file: ', file)
duplicates.append(file)
num_duplicates+=1
print('\nTotal duplicate files:', num_duplicates)
print("-----"*10)
return hash_dict, duplicates
后处理的最后一步是删除duplicates列表中的所有重复文件。
def remove_duplicates(base_dir):
_, duplicates = find_similar_images(base_dir, hash_size=12)
if not len(duplicates):
print('No duplicates found!')
else:
print("Removing duplicates...")
for dup_file in duplicates:
file_path = os.path.join(base_dir, dup_file)
# 对于每个重复文件,构建其完整路径并删除该文件。如果文件不存在,则打印一条消息。
if os.path.exists(file_path):
os.remove(file_path)
else:
print('Filepath: ', file_path, 'does not exists.')
print('All duplicates removed!')
print('***'*10,'\n')
1.5.4 命令行选项
如前所述,video_2_slides.py包含主执行脚本。它有以下参数来运行脚本。
parser = argparse.ArgumentParser(description="This script is used to
convert video frames into slide PDFs.")
parser.add_argument("-v", "--video_file_path", help="Path to the video
file", type=str)
parser.add_argument("-o", "--out_dir", default = 'output_results',
help="Path to the output directory", type=str)
parser.add_argument("--type", choices=['Frame_Diff', 'GMG', 'KNN'],
default = 'GMG', help = "type of background
subtraction to be used" , type=str)
parser.add_argument("--no_post_process", action="store_true",
default=False,
help="flag to apply post processing or not")
parser.add_argument("--convert_to_pdf", action="store_true",
default=False, help="flag to convert the entire
image set to pdf or not")
args = parser.parse_args()
video_file_path:输入视频文件的路径。out_dir:输出目录的路径,其中结果将被存储。type:要应用的背景减除方法类型。可以是:Frame_Diff、GMG(默认)或KNN之一。no_post_process:标志,指定是否应用后处理步骤。如果没有指定,后处理步骤始终作为默认应用。convert_to_pdf:标志,指定是否将图像集合转换为单个PDF文件。
1.6 GMG和KNN背景估计的比较
我们在几个幻灯片视频上运行了GMG和KNN方法,发现KNN背景估计方法的FPS几乎是其GMG的四倍。然而,在一些视频样本中,我们发现KNN方法遗漏了一些帧。
我们没有选择MOG2背景减除技术,因为它在过渡阶段捕获了大多数视频帧,并倾向于遗漏重要帧。如果进一步调参,可能有更好的结果。
1.7 改进与总结
本文的目标是构建一个简单的Python应用程序,将语音旁白视频讲座转换为幻灯片:
-
静态帧视频:对于大部分是静态帧的视频,简单的帧差分方法就能取得不错的结果。
-
动画场景:对于含有显著动画的场景,可以使用概率方法(如高斯混合模型GMG和KNN)来模拟背景像素。
-
当视频包含静态帧且同时有面部相机运动时,这些方法无法有效区分面部运动和动画,导致冗余帧的出现。即便在后处理阶段,通过图像哈希方法来检测相似帧,有时依然无法消除所有冗余的幻灯片。建议可以尝试用余弦相似度等更精准的相似性检测技术来判断帧的相似度,以减少冗余。
- 可能的改进方向:深度学习方法。
也可采用深度学习方法,通过面部特征提取,将提取到的面部特征传递给非参数化的监督学习分类器(如KNN分类器),用以区分面部移动和实际内容变化,从而获得更独特的关键帧样本,有效减少冗余帧的数量,尤其适用于面部移动明显的讲座场景。 - 适用场景:总体而言,这个应用在处理旁白讲座时效果非常好,因为此类讲座通常画面内容变化较少且以静态幻灯片为主。而对于包含互动的讲座,尤其是内容频繁变化或场景复杂的情况,文中提到的几种方法可能仍然不够理想,未来可能需要探索其他更复杂的技术来处理这类场景。
二、U2-Net图像分割:一种有效的背景减除方法
2.1 简介
U2-Net 是一种用于图像分割的深度学习模型,特别是在前景提取和物体分割方面表现出色,以其有效和直接的方法在广告、电影制作和医学成像等领域具有重要意义。另外本文还将讨论IS-Net,即U2-Net的增强版本,并展示其优越的结果。
传统的深度学习分割架构(如全卷积网络 FCNs)在通过多层网络提取局部特征时,虽然能够捕捉更多的语义信息,但由于多次池化操作,特征图分辨率降低,导致全局上下文信息的缺失。新方法如 DeepLab 通过多种膨胀卷积(atrons convolutions)增加网络感受野,从而减小信息损失,然而这会在高分辨率图像训练时带来显著的计算成本。
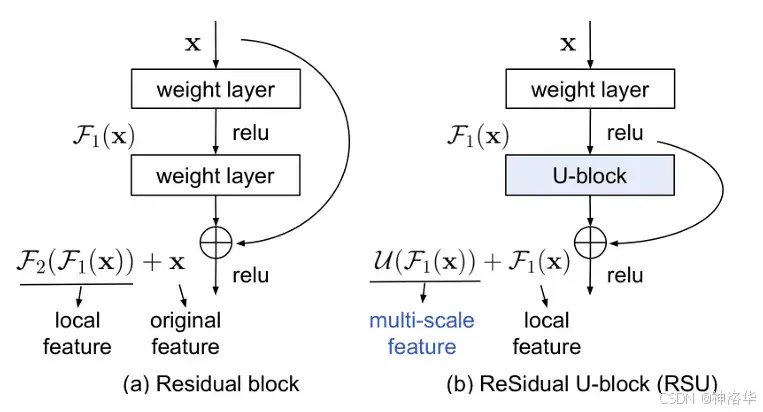
U2-Net 采用双层嵌套的修改版 U-Net 结构,能够同时处理多层深度特征提取和多尺度信息,平衡局部和全局上下文的捕获。其核心构件是 ReSidual U-block (RSU),结合了残差块和 U-Net 对称编码-解码结构的优点。
U2-Net 在训练时不依赖预训练的分类骨干网络,能够从头开始训练,表现更佳,同时减少了内存消耗和计算成本。接下来,将详细探讨 RSU 块的结构和特点。
2.2 RSU Block
2.2.1 RSU Block结构
RSU-L(L 表示编码器中的层数)块的结构可以表示为 RSU-L(Cin, M, Cout),其中:
- Cin 是输入特征图的通道数
- M 是编码器中间层的通道数
- Cout 是输出特征图的通道数
RSU-L 块的输出特征图的空间分辨率与输入特征图保持一致。
下面是RSU-7 block的结构图,其主要组成部分包括:
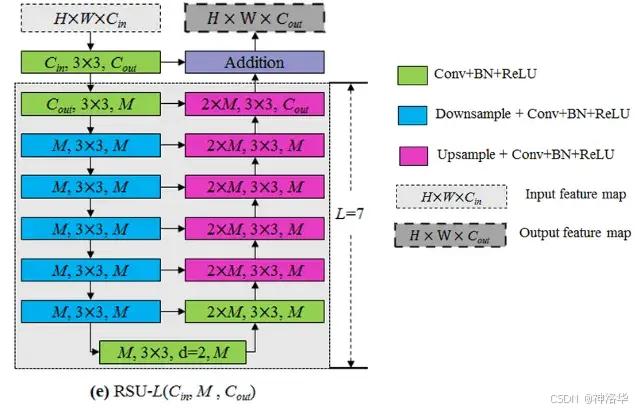
-
输入卷积层:将输入特征图(形状为 H × W × C i n H \times W \times C_{in} H×W×Cin)转换为中间特征图 F 1 ( x ) \mathcal{F}_1(x) F1(x)(形状为 H × W × C o u t H \times W \times C_{out} H×W×Cout),用于学习局部特征。
-
对称的 U-Net 编码-解码块:对特征图 F 1 ( x ) \mathcal{F}_1(x) F1(x) 进行编码,学习多尺度特征 U ( F 1 ( x ) ) \mathcal{U(F}_1(x)) U(F1(x))。这些多尺度特征从编码器层下采样后的特征图中提取,经过拼接、卷积和上采样等步骤,最终特征图的分辨率依然为 H × W × C o u t H \times W \times C_{out} H×W×Cout。
下采样通过池化操作完成,上采样使用“双线性”插值。
-
残差连接:通过加法融合局部特征和多尺度特征,形成 F 1 ( x ) + U ( F 1 ( x ) ) \mathcal{F}_1(x) + \mathcal{U(F}_1(x)) F1(x)+U(F1(x))。
RSU 块类似于残差块,但其学习的是多尺度特征,而不仅仅是局部特征。下图中,
F
1
\mathcal{F}_1
F1 和
F
2
\mathcal{F}_2
F2 是通过卷积层学习到的特征表示,而
U
(
F
1
(
x
)
)
\mathcal{U(F}_1(x))
U(F1(x)) 则是通过编码-解码块学习到的多尺度特征。
下面是RSU-7 block的详细结构图,输入特征图尺寸为320 x320 x3。
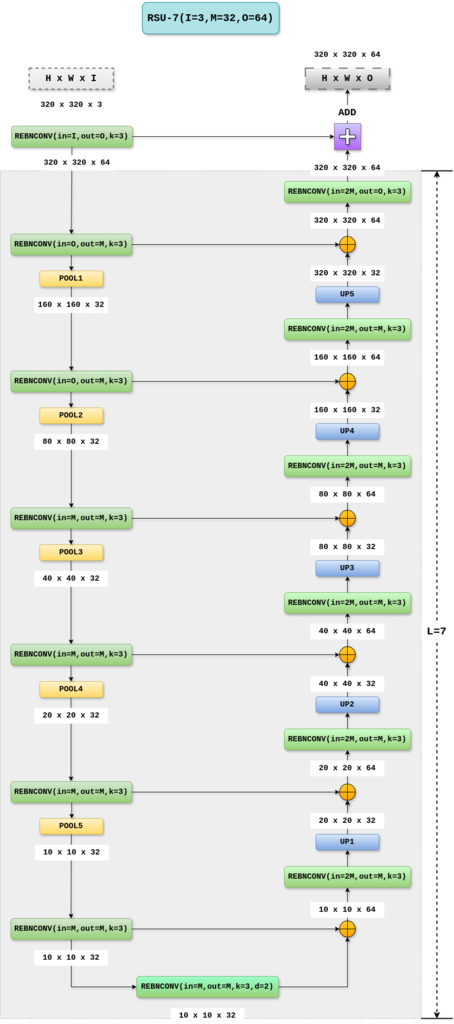
- 输入特征图的分辨率为
320x320x3,其中 I、M、O 分别表示输入、中间和最终输出通道的数量。图中还展示了卷积、池化、拼接和上采样后的形状。 REBNCONV块是常规卷积,后接批归一化和ReLU激活。- 填充和膨胀率均为 1*d,默认
d= 1。 - 图中 ⊕ 符号表示拼接操作。
通常卷积核会在输入特征图上逐像素滑动,采样相邻像素。如果设置膨胀率为 2,那么卷积核在采样时会隔开一个像素,只采样每隔一个像素的位置。类似地,如果膨胀率为 3,那么卷积核会采样每隔两个像素的位置。膨胀率的作用和优点:
- 扩大感受野:膨胀率可以在不增加卷积核大小的情况下扩展感受野,使模型能从更大区域获取上下文信息。这对图像中的全局和多尺度特征提取特别有用,尤其在图像分割、物体检测等需要捕捉大范围背景的任务中。
- 减少计算开销:相比直接增大卷积核尺寸,膨胀卷积无需增加额外参数,从而节省了计算资源。
- 保持分辨率:膨胀卷积可以在不进行下采样的情况下增大感受野,从而避免图像特征图分辨率的降低。这在需要高分辨率特征的任务(如前景分割)中非常有用。
2.2.2 RSU Block的代码实现
REBNCONV模块:对中间特征图应用卷积、Batch Norm 和 ReLU 激活(即通常的卷积操作链)。
class REBNCONV(nn.Module):
def __init__(self,in_ch=3,out_ch=3,dirate=1):
super(REBNCONV,self).__init__()
self.conv_s1 = nn.Conv2d(in_ch,out_ch,3,padding=1*dirate,dilation=1*dirate)
self.bn_s1 = nn.BatchNorm2d(out_ch)
self.relu_s1 = nn.ReLU(inplace=True)
def forward(self,x):
hx = x
xout = self.relu_s1(self.bn_s1(self.conv_s1(hx)))
return xout
- _upsample_like 函数:接收两个特征图
src和tar,并将src上采样至与tar具有相同的空间分辨率。
def _upsample_like(src,tar):
src = F.upsample(src,size=tar.shape[2:],mode='bilinear')
return src
- RSU7 模块的
__init__方法:用于初始化编码器、解码器和池化层
class RSU7(nn.Module):#UNet07DRES(nn.Module):
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
super(RSU7,self).__init__()
self.rebnconvin = REBNCONV(in_ch,out_ch,dirate=1)
self.rebnconv1 = REBNCONV(out_ch,mid_ch,dirate=1)
self.pool1 = nn.MaxPool2d(2,stride=2,ceil_mode=True)
self.rebnconv2 = REBNCONV(mid_ch,mid_ch,dirate=1)
self.pool2 = nn.MaxPool2d(2,stride=2,ceil_mode=True)
self.rebnconv3 = REBNCONV(mid_ch,mid_ch,dirate=1)
self.pool3 = nn.MaxPool2d(2,stride=2,ceil_mode=True)
self.rebnconv4 = REBNCONV(mid_ch,mid_ch,dirate=1)
self.pool4 = nn.MaxPool2d(2,stride=2,ceil_mode=True)
self.rebnconv5 = REBNCONV(mid_ch,mid_ch,dirate=1)
self.pool5 = nn.MaxPool2d(2,stride=2,ceil_mode=True)
self.rebnconv6 = REBNCONV(mid_ch,mid_ch,dirate=1)
self.rebnconv7 = REBNCONV(mid_ch,mid_ch,dirate=2)
self.rebnconv6d = REBNCONV(mid_ch*2,mid_ch,dirate=1)
self.rebnconv5d = REBNCONV(mid_ch*2,mid_ch,dirate=1)
self.rebnconv4d = REBNCONV(mid_ch*2,mid_ch,dirate=1)
self.rebnconv3d = REBNCONV(mid_ch*2,mid_ch,dirate=1)
self.rebnconv2d = REBNCONV(mid_ch*2,mid_ch,dirate=1)
self.rebnconv1d = REBNCONV(mid_ch*2,out_ch,dirate=1)
rebnconvin:该模块充当一个在编码-解码块外的附加层,用于转换输入特征图,以便传递给后续的编码-解码块。该层的输出特征图会在最终的解码器输出中相加。rebnconv1至rebnconv7:表示编码器中的各个块。最大池化层pool1至pool5用于对编码器块rebnconv1至rebnconv5的特征图进行下采样。rebnconv6d至rebnconv1d:表示解码器块,从下至上逐层提取多尺度特征。
- RSU7 模块的前向传播
def forward(self,x):
hx = x
hxin = self.rebnconvin(hx)
hx1 = self.rebnconv1(hxin)
hx = self.pool1(hx1)
hx2 = self.rebnconv2(hx)
hx = self.pool2(hx2)
hx3 = self.rebnconv3(hx)
hx = self.pool3(hx3)
hx4 = self.rebnconv4(hx)
hx = self.pool4(hx4)
hx5 = self.rebnconv5(hx)
hx = self.pool5(hx5)
hx6 = self.rebnconv6(hx)
hx7 = self.rebnconv7(hx6)
hx6d = self.rebnconv6d(torch.cat((hx7,hx6),1))
hx6dup = _upsample_like(hx6d,hx5)
hx5d = self.rebnconv5d(torch.cat((hx6dup,hx5),1))
hx5dup = _upsample_like(hx5d,hx4)
hx4d = self.rebnconv4d(torch.cat((hx5dup,hx4),1))
hx4dup = _upsample_like(hx4d,hx3)
hx3d = self.rebnconv3d(torch.cat((hx4dup,hx3),1))
hx3dup = _upsample_like(hx3d,hx2)
hx2d = self.rebnconv2d(torch.cat((hx3dup,hx2),1))
hx2dup = _upsample_like(hx2d,hx1)
hx1d = self.rebnconv1d(torch.cat((hx2dup,hx1),1))
return hx1d + hxin
在前向传播中,rebnconvin 层的输出会与解码器层 rebnconv1d 的输出进行最终的相加操作,以获得最终输出。
- RSU-KF 模块
此外,RSU 模块还有一个变体 RSU-KF 模块(K是编码器中的层数)。该模块用膨胀卷积代替编码-解码块中的池化和上采样操作,以缓解网络在更深层次上逐步丢失上下文信息的问题。
2.3 U2-Net架构
U2-Net 的核心结构是RSU Block,通过双层嵌套结构构建。外层结构采用 U 形结构,由 11 个stages组成,每个stage包含一个配置好的 RSU 块。
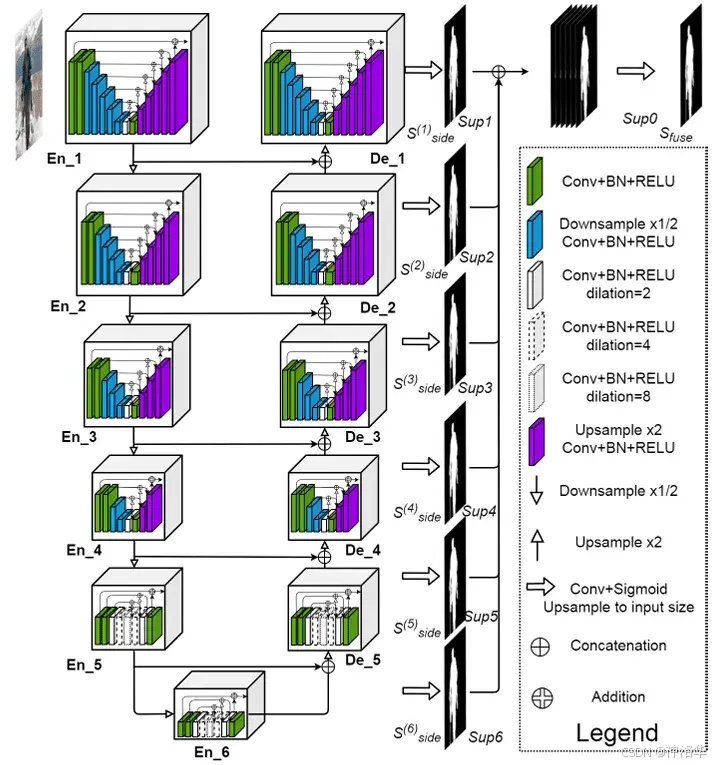
U2-Net 的结构包含以下三个组件:
-
六个编码器阶段:En_1 到 En_6,其中 En_1 至 En_4 分别使用 RSU-7、RSU-6、RSU-5 和 RSU-4 块,而 En_5 和 En_6 使用 RSU-4F 块。
-
五个解码器阶段:De_1 到 De_5,与相对称的编码器阶段对应。除 De_5 之外,每个解码器阶段的输入为其上一阶段的输出与相对称的编码器阶段输出的上采样拼接结果;De_5 结合了 En_5 和 En_6 的上采样拼接结果。
-
侧输出:解码器阶段 De_1 到 De_5 和编码器阶段 En_6 的输出特征图经过 3x3 卷积层,再上采样到输入图像的分辨率(320x320),生成六个侧输出 S s i d e ( 6 ) \mathcal{S}^{(6)}_{side} Sside(6) 到 S s i d e ( 1 ) \mathcal{S}^{(1)}_{side} Sside(1)。这些侧输出经过 Sigmoid 激活,生成概率图。然后将这些特征图拼接,并通过一个 1x1 卷积和 Sigmoid 激活生成最终的融合概率图 S f u s e \mathcal{S}_{fuse} Sfuse。
下表显示了U2-Net编码器和解码器级中RSU模块的完整配置参数:
U2-Net 模块中的最终侧输出的实现过程如下:
#side output
d1 = self.side1(hx1d)
d2 = self.side2(hx2d)
d2 = _upsample_like(d2,d1)
d3 = self.side3(hx3d)
d3 = _upsample_like(d3,d1)
d4 = self.side4(hx4d)
d4 = _upsample_like(d4,d1)
d5 = self.side5(hx5d)
d5 = _upsample_like(d5,d1)
d6 = self.side6(hx6)
d6 = _upsample_like(d6,d1)
d0 = self.outconv(torch.cat((d1,d2,d3,d4,d5,d6),1))
return F.sigmoid(d0), F.sigmoid(d1), F.sigmoid(d2), F.sigmoid(d3), F.sigmoid(d4), F.sigmoid(d5), F.sigmoid(d6)
-
侧输出计算:
d1到d6是 解码器De_1 到 De_5 和编码器 En_6 的输出特征图先经过 3x3 卷积层,再通过_upsample_like函数将其上采样至与d1相同的空间分辨率而得到的。这确保了在拼接时各个特征图的大小一致。 -
特征拼接:通过
torch.cat将所有上采样后的侧输出(d1到d6)在通道维度上拼接,并通过一个 1x1 的卷积层outconv处理,以获得更丰富的特征表示。 -
激活函数应用:最后,使用 Sigmoid 激活函数对所有单独的输出和拼接后的输出进行处理,生成最终的概率图,为模型的前景分割任务提供了丰富的信息。
U2-Net 还提供了一个缩小版模型 U2-NetP,适用于边缘设备推理,减少了 RSU 块的输入、中间和输出通道数。
2.4 U2-Net 的训练与评估策略
2.4.1 训练数据集与数据增强
- 数据集:作者使用了 DUTS 图像数据集进行二分类分割,包含 10,553 张图像。通过水平翻转,数据量增加到 21,106 张训练图像。
- 数据增强:训练过程中,图像先被调整为 320×320 像素,然后随机进行垂直翻转,最后随机裁剪为 228×288 像素。
2.4.2 损失函数与优化器
-
损失函数:训练损失定义为侧输出概率图和最终融合输出图的加权和:
L = ∑ m = 1 M w s i d e ( m ) l s i d e ( m ) + w f u s e l f u s e \mathcal{L} = \sum_{m=1}^{M} {w^{(m)}_{side}l^{(m)}_{side}} + w_{fuse}l_{fuse} L=m=1∑Mwside(m)lside(m)+wfuselfuse
其中 M M M 设置为 6,表示六个侧输出显著图,权重均为 1。每个损失项 l l l 使用标准的二元交叉熵损失:
l = − ∑ ( r , c ) ( H , W ) [ P G ( r , c ) log P S ( r , c ) + ( 1 − P G ( r , c ) ) log ( 1 − P S ( r , c ) ) ] l = - \sum_{(r,c)}^{(H,W)} {[P_{G(r,c)}\log P_{S(r,c)} + (1-P_{G(r,c)})\log (1-P_{S(r,c)})}] l=−(r,c)∑(H,W)[PG(r,c)logPS(r,c)+(1−PG(r,c))log(1−PS(r,c))]
其中 P G ( r , c ) P_{G(r,c)} PG(r,c) 和 P S ( r , c ) P_{S(r,c)} PS(r,c) 分别表示真实标签和预测概率的像素值。
-
优化器:使用 Adam 优化器,初始学习率为 1 e − 3 1e-3 1e−3,超参数设置为默认值,具体为 b e t a s = ( 0.9 , 0.999 ) betas=(0.9, 0.999) betas=(0.9,0.999), e p s = 1 e − 8 eps=1e-8 eps=1e−8, w e i g h t d e c a y = 0 weightdecay=0 weightdecay=0。
2.4.3 评估数据集、指标与结果
-
评估数据集:使用六个基准数据集进行评估,包括 DUT-OMRON(5168 张)、DUTS-TE(5019 张)、HKU-IS(4447 张)、ECSSD(1000 张)、PASCAL-S(850 张)和 SOD(300 张)。
-
评估指标:
- 精确率-召回曲线:PR曲线
- beta-F-score 衡量(分数越高越好): F β = ( 1 + β 2 ) × P r e c i s i o n × R e c a l l β 2 × P r e c i s i o n + R e c a l l F_{\beta} = \frac{(1+\beta^2) \times Precision \times Recall}{\beta^2 \times Precision + Recall} Fβ=β2×Precision+Recall(1+β2)×Precision×Recall
- MAE:表示真实掩膜和预测图之间的误差,值越低越好: M A E = 1 H × W ∑ r = 1 H ∑ c = 1 W ∣ P ( r , c ) − G ( r , c ) ∣ MAE = \frac{1}{H \times W}\sum_{r=1}^{H}\sum_{c=1}^{W}{|P(r,c) - G(r,c)|} MAE=H×W1r=1∑Hc=1∑W∣P(r,c)−G(r,c)∣
- 加权 F-score:用于克服可能的比较不公,分数越高越好: F β w = ( 1 + β 2 ) P r e c i s i o n w ⋅ R e c a l l w β 2 ⋅ P r e c i s i o n w + R e c a l l w F_{\beta}^{w} = (1+\beta^2)\frac{Precision^{w} \cdot Recall^w}{\beta^2 \cdot Precision^w + Recall^w} Fβw=(1+β2)β2⋅Precisionw+RecallwPrecisionw⋅Recallw
- S-measure:评估预测非二元显著图和真实图之间的结构相似性,分数越高越好: S = ( 1 − α ) S r + α S o S = (1-\alpha)S_r + \alpha S_o S=(1−α)Sr+αSo
- relax boundary F-measure:定量估计预测掩膜的边界质量,分数越高越好。
与20 种最先进方法进行对比,结果如下:

U2-Net 在 DUT-OMRON、HKU-IS 和 ECSSD 数据集上几乎达到了最先进的结果,在 DUTS-TE 和 SOD 数据集上接近第二名,在 PASCAL-S 数据集上得分接近前三名。
红色、绿色和蓝色分别表示最佳、第二佳和第三佳性能
2.5 U2-Net样例测试
接下来,我们将对一些示例图像进行推理,并可视化结果。完整代码见《U2_Net_Model_Inference.ipynb》。
- 加载模型
import os
from PIL import Image
import numpy as np
from torchinfo import summary
import torch
import torchvision.transforms as T
from u2net import U2NET, U2NETP
import torchvision.transforms.functional as F
DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"
# 初始化U2-Net和U2-NetP模型
u2net = U2NET(in_ch=3,out_ch=1)
u2netp = U2NETP(in_ch=3,out_ch=1)
#使用load_model辅助函数加载模型权重
def load_model(model, model_path, device):
model.load_state_dict(torch.load(model_path, map_location=device))
model = model.to(device)
return model
u2net = load_model(model=u2net, model_path="u2net.pth", device="cuda:0")
u2netp = load_model(model=u2netp, model_path="u2netp.pth", device="cuda:0")
U2-Net模型有大约44M个参数,U2-NetP模型比原始的U2-Net模型小38倍左右,仅包含约113万个参数。
- 图像预处理与批处理
分辨率设置为320x320,并使用ImageNet均值和标准差对其进行归一化。
# 数据预处理
MEAN = torch.tensor([0.485, 0.456, 0.406])
STD = torch.tensor([0.229, 0.224, 0.225])
resize_shape = (320,320)
transforms = T.Compose([T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)])
# 批处理,prepare_image_batch函数略
image_batch = prepare_image_batch(image_dir=TEST_IMAGE_DIR,
resize=resize_shape,
transforms=transforms,
device=DEVICE)
另外还将设置一个denim_image函数进行反向操作,将归一化的图像反归一化到 [0, 255],以便进行可视化。
def denorm_image(image, mean, std):
image_denorm = torch.addcmul(mean[:,None,None], image, std[:,None, None])
image = torch.clamp(image_denorm*255., min=0., max=255.)
image = torch.permute(image, dims=(1,2,0)).numpy().astype("uint8")
return image
- 推理
def prepare_predictions(model, image_batch):
model.eval()
all_results = []
for image in image_batch:
with torch.no_grad():
results = model(image.unsqueeze(dim=0))
all_results.append(torch.squeeze(results[0].cpu(), dim=(0,1)).numpy())
return all_results
predictions_u2net = prepare_predictions(u2net, image_batch)
predictions_u2netp = prepare_predictions(u2netp, image_batch)
下面是一些结果:
- U2-Net(中)效果好于U2-NetP(右)
- U2-NetP(右)的预测结果优于U2-Net(中)
- 两个模型效果都一般



2.6 IS-Net:改进的U2-Net图像分割算法
2.6.1 简介
U2-Net论文的作者提出了一种更为优秀的前景分割方法——IS-Net,主要改进体现在以下几个方面:

-
高维掩码级编码器:IS-Net使用了一个专门的真实编码器来学习高维掩码级特征,这一设计使得模型在处理复杂图像分割任务时能够提取更丰富的信息。
-
中间自监督学习:IS-Net引入了一种中间自监督策略(Intermediate Supervision, IS),模型能够利用自身生成的特征与真实掩码进行对比和学习,从而提高特征表示的质量
-
训练数据集:IS-Net基于DIS5K数据集进行训练,该数据集较大且标签更准确,有助于提升模型的分割性能。
-
简化的架构:与U2-Net不同,IS-Net的分割组件不使用融合的侧输出模块,简化了架构设计,同时依然保持了高效的特征提取能力。
-
新颖的评估指标:IS-Net提出了一种新的评估指标——HCE(Human Correction Efforts),用于评估模型在实际应用中修正错误所需的工作量,这为模型性能的评估提供了更直观的参考。
这些改进使IS-Net在前景分割任务中表现出更高的准确性和鲁棒性。
IS-Net架构包括两个组件:
- 真实编码器( ground truth encoder):用于学习高维的掩码级编码。
- 图像分割组件:与U2-Net相似,用于学习高分辨率的多阶段和多级图像特征。
图5. IS-Net baseline:(a) 显示了图像分割组件,(b) 阐明了基于中间监督(IS)组件构建的真实编码器。
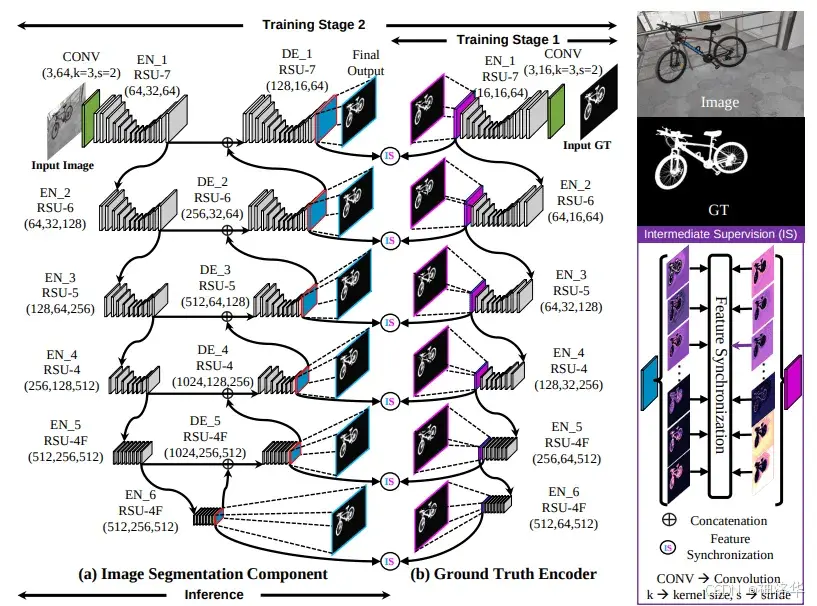
训练时输入图像分辨率为1024×1024,采用两阶段训练流程:
-
第一阶段:训练自监督的真实编码器模型,学习高维掩码级特征。编码器由6个阶段的RSU编码器块组成。
- 第一至第四阶段使用RSU-7、RSU-6、RSU-5和RSU-4模块,第五和第六阶段使用RSU-4F模块。
- 为了减少计算成本,512×512的高分辨率真实掩码被通过步幅为2的卷积下采样后传递给编码器阶段。
-
第二阶段:图像分割组件包括五个解码器阶段(DE_1-DE_5)和六个编码器阶段(EN_1-EN_6),模型从解码器级(DE_1 - DE_5)和最后的编码器级(EN_6)生成侧输出概率图和中间特征(未激活的logits)。
2.6.2 损失函数
-
引入均方误差(MSE)损失进行特征同步,通过中间监督进行学习。特征同步损失(Lfs)公式为:
L f s = ∑ d = 1 D λ f s ∣ ∣ f d I − f d G ∣ ∣ 2 L_{fs} = \sum_{d=1}^{D} \lambda ^{fs}||f^{I}_d - f^{G}_d||^2 Lfs=d=1∑Dλfs∣∣fdI−fdG∣∣2
其中, f d I f^{I}_d fdI 是从解码器阶段提取的图像特征, f d G f^{G}_d fdG 是在第一阶段学习的掩码级编码。D=6表示分割模型的阶段(DE_1-DE_5和EN_6)
-
使用二元交叉熵损失(BCE)来计算侧输出图与真实掩码之间的损失。分割组件的训练被视为优化问题:
a r g m i n θ s g ( L f s + L s g ) \underset{\theta _{sg}}{argmin}(L_{fs} + L_{sg}) θsgargmin(Lfs+Lsg)
请注意,IS-Net管道的推理过程中,仅使用分割组件,正如在之前的U2-Net模型中一样。
2.6.3 推理结果
接下来,我们将对一些示例图像进行推理,并可视化结果。完整代码见《IS_Net_Model_Inference.ipynb》。
from isnet import ISNetDIS
isnet = ISNetDIS(in_ch=3,out_ch=1)
isnet = load_model(model=isnet, model_path="isnet-general-use.pth", device="cuda:0")
预处理不变,但由于IS-Net管道不使用融合侧输出图,我们将在推理中使用第一个解码器阶段(DE_1)的侧输出:
def prepare_predictions(model, image_batch):
model.eval()
all_results = []
for image in image_batch:
with torch.no_grad():
results = model(image.unsqueeze(dim=0))
all_results.append(torch.squeeze(results[0][0].cpu(), dim=(0,1)).numpy())
return all_results
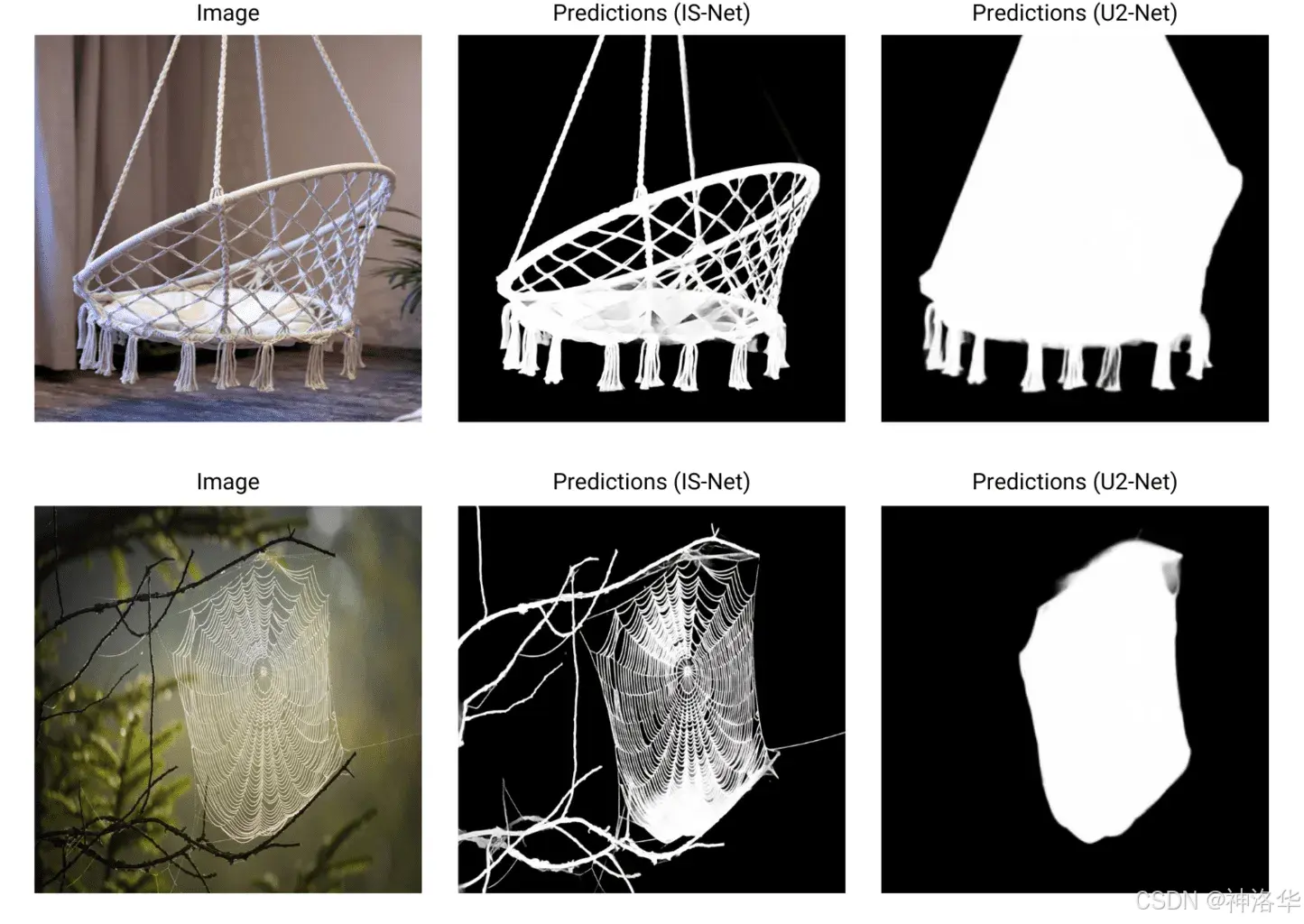
让我们可视化几个推理样本,并将它们与U2-Net(中)的样本进行比较:
通常情况下,IS-Net总是能生成比U2-Net更好的预测掩码,但某些场景下会反过来。我们可以通过使用OpenCV的阈值处理工具来改善IS-Net的预测掩码。在处理时,我们将阈值设置为10。
# 假设 prediction_mask 是IS-Net生成的预测掩码
prediction_mask = ... # 你的预测掩码
# 阈值处理
threshold_value = 10 # 阈值可以根据具体需求调整
_, thresholded_mask = cv2.threshold(prediction_mask, threshold_value, 255, cv2.THRESH_BINARY)
# 后处理(可选): 可以进一步使用形态学操作(如膨胀和腐蚀)来去除噪声或填补小孔。
kernel = np.ones((3, 3), np.uint8) # 定义一个3x3的结构元素
processed_mask = cv2.morphologyEx(thresholded_mask, cv2.MORPH_CLOSE, kernel) # 膨胀和腐蚀
# 保存并显示结果
cv2.imshow("Processed Mask", processed_mask)
cv2.waitKey(0)
cv2.destroyAllWindows()
2.7 总结
-
ReSidual-U块:ReSidual-U结构(RSU)在学习多尺度全局上下文的同时,也能从局部表示中学习,成为U2-Net和IS-Net管道的核心。
-
U2-Net:U2-Net是一个嵌套的双层RSU编码器-解码器结构,能够以最小的计算和内存成本,获取多层次和多尺度的深度特征表示,无需预训练的分类骨干网络。
-
中间监督策略:从目标分割掩码训练自监督的真实编码器,有助于捕捉高维掩码级特征。
-
IS-Net管道:IS-Net管道旨在利用训练好的真实编码器和多阶段特征图实现特征同步,同时通过分割组件(类似于U2-Net)学习阶段内和多层次的图像特征。