GoogLeNet-水果分类
1.数据集
官方下载地址:https://www.kaggle.com/datasets/karimabdulnabi/fruit-classification10-class?resource=download
备用下载地址:https://www.123684.com/s/xhlWjv-pRAPh
介绍:
十个类别:苹果、橙色、鳄梨、猕猴桃、芒果、凤梨、草莓、香蕉、樱桃、西瓜
2.训练
import copy
import time
import torch
from torch import nn
import torchvision
from torchvision import transforms
import torch.utils.data as Data
import matplotlib.pyplot as plt
import numpy as np
from model import GoogLeNet, Inception
import pandas as pd
def train_val_data_process():
ROOT_TARIN = './02框架学习/04经典卷积神经网络与实战-pao哥/06_GoogLeNet_fruit/dataset/train'
# 定义处理训练集的数据 Tensor会将数据转换为0-1之间的数据
train_transform = transforms.Compose([transforms.Resize((224,224)), transforms.ToTensor()])
# 加载数据集
train_data = torchvision.datasets.ImageFolder(root=ROOT_TARIN, transform=train_transform)
# 划分训练集验证集
train_data, val_data = Data.random_split(dataset=train_data,
lengths=[round(0.8*len(train_data)), round(0.2*len(train_data))])
train_dataloader = Data.DataLoader(dataset=train_data,
batch_size=64,
shuffle=True,
num_workers=3)
val_dataloader = Data.DataLoader(dataset=val_data,
batch_size=64,
shuffle=True,
num_workers=3)
return train_dataloader, val_dataloader
def train_model_process(model, train_dataloader, val_dataloader, epochs):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.CrossEntropyLoss()
# 将模型放入到训练设备
model = model.to(device)
# 最佳权重
best_model_wts = copy.deepcopy(model.state_dict)
# 参数
best_acc = 0.0
train_loss_all = []
val_loss_all = []
train_acc_all = []
val_acc_all = []
since = time.time()
for epoch in range(epochs):
print(f'epoch:{epoch} / {epochs-1}')
print('-'*10)
# 初始化参数
train_loss = 0.0
train_corrects = 0.0
val_loss = 0.0
val_corrects = 0.0
train_num = 0
val_num = 0
# 对每个batch进行训练
for step, (x, y) in enumerate(train_dataloader):
x = x.to(device)
y = y.to(device)
model.train()
# 前向传播
output = model(x)
# 查找每一行中最大的行标
pre_lab = torch.argmax(output, dim=1)
loss = loss_fn(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 对损失函数进行累加
train_loss += loss.item() * x.size(0)
# 如果预测正确,则准确度加1
train_corrects += torch.sum(pre_lab == y.data)
# 当前用于训练的样本数量
train_num += x.size(0)
# 对验证集进行验证
for step, (x, y) in enumerate(val_dataloader):
x = x.to(device)
y = y.to(device)
model.eval()
output = model(x)
# 查找每一行对应的最大的行标
pre_lab = torch.argmax(output, dim=1)
# 计算每一个batch对应的损失
loss = loss_fn(output, y)
# 对损失值进行累加
val_loss += loss.item() * x.size(0)
# 如果预测正确,则准确度加1
val_corrects += torch.sum(pre_lab == y.data)
# 当前用于训练的样本数量
val_num += x.size(0)
train_loss_all.append(train_loss / train_num)
train_acc_all.append(train_corrects.item() / train_num)
val_loss_all.append(val_loss / val_num)
val_acc_all.append(val_corrects.item() / val_num)
print(f'epoch:{epoch} train loss:{train_loss_all[-1]:.4f} train acc:{train_acc_all[-1]:.4f}')
print(f'epoch:{epoch} val loss:{val_loss_all[-1]:.4f} val acc:{val_acc_all[-1]:.4f}')
# 寻找最高准确度
if val_acc_all[-1] > best_acc:
# 保存当前最高的准确度和对应的权重
best_acc = val_acc_all[-1]
best_model_wts = copy.deepcopy(model.state_dict())
# 训练耗时
time_use = time.time() - since
print(f'训练和验证耗费的时间{time_use / 60:.0f}m:{time_use % 60:.0f}s')
# 选择最优的模型
torch.save(best_model_wts, 'best_model.pth')
train_process = pd.DataFrame(data = {
'epoch':range(epochs),
'train_loss_all':train_loss_all,
'train_acc_all':train_acc_all,
'val_loss_all':val_loss_all,
'val_acc_all':val_acc_all
})
return train_process
# 绘制
def matplot(train_process):
plt.figure(figsize=(12, 4))
plt.subplot(1,2,1)
plt.plot(train_process['epoch'], train_process.train_loss_all, 'ro-', label='train loss')
plt.plot(train_process['epoch'], train_process.val_loss_all, 'bo-', label='val loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.subplot(1,2,2)
plt.plot(train_process['epoch'], train_process.train_acc_all, 'ro-', label='train acc')
plt.plot(train_process['epoch'], train_process.val_acc_all, 'bo-', label='val acc')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('acc')
plt.show()
if __name__ == '__main__':
# 模型实例化
model = GoogLeNet(Inception)
train_dataloader, val_dataloader = train_val_data_process()
train_process = train_model_process(model, train_dataloader, val_dataloader, 51)
matplot(train_process)
训练了50轮,但是最终的效果不是很好

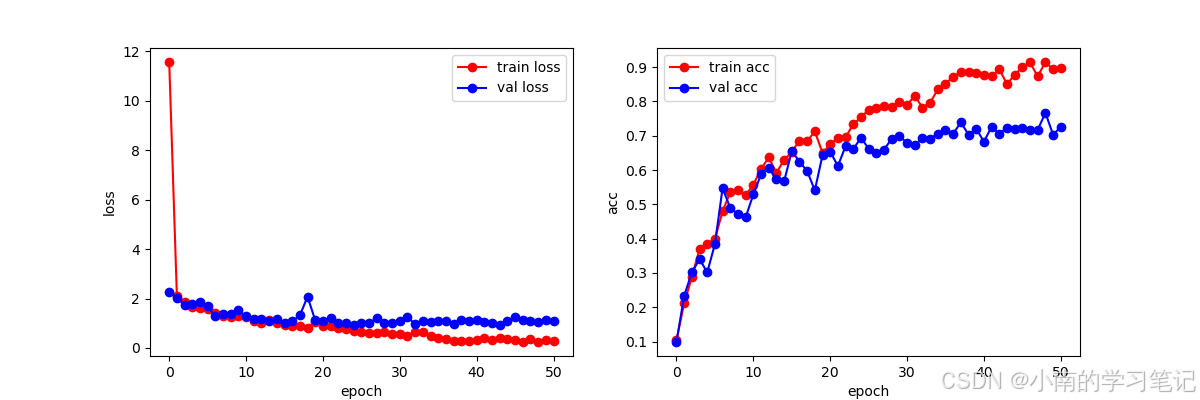
3.测试
"""
@author:Lunau
@file:model_test.py
@time:2024/09/19
"""
import torch
from torch import nn
from torchvision import transforms
import torchvision
import torch.utils.data as Data
import matplotlib.pyplot as plt
import numpy as np
from model import GoogLeNet, Inception
def test_data_process():
ROOT_TEST = './02框架学习/04经典卷积神经网络与实战-pao哥/05_GoogLeNet_catAndDog/dataset/test'
# 处理测试集的数据
test_transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])
# 加载数据集
test_data = torchvision.datasets.ImageFolder(root=ROOT_TEST, transform=test_transform)
test_dataloader = Data.DataLoader(dataset=test_data,
batch_size=32,
shuffle=True,
num_workers=3,
)
return test_dataloader
def test_model_process(model, test_dataloader):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 初始化参数
test_corrects = 0.0
test_num = 0
# 只进行前向传播
with torch.no_grad():
try:
for x, y in test_dataloader:
x = x.to(device)
y = y.to(device)
model.eval()
# 输出结果,是概率值
output = model(x)
# 查找每一行中最大的行标
prd_lab = torch.argmax(output, dim=1)
# 预测正确的数量
test_corrects += torch.sum(prd_lab == y.data)
# 将所有测试的样本数进行累加
test_num += x.size(0)
except Exception:
print('error and skip')
# 计算测试的准确率
test_acc = test_corrects.item() / test_num
print(f'测试的准确率为:{test_acc}')
def imshow(img):
img = img / 2 + 0.5 # 将图像归一化还原
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
if __name__ == '__main__':
# 加载模型结构
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = GoogLeNet(Inception).to(device)
# 加载模型权重
model.load_state_dict(torch.load('02框架学习\\04经典卷积神经网络与实战-pao哥\\05_GoogLeNet_catAndDog\\best_model.pth', weights_only=True))
test_loader = test_data_process()
test_model_process(model, test_loader)
测试的准确率确实有些低,训练轮次多一些可能会好一点

4.预测
对这张图片进行预测


"""
@author:Lunau
@file:model_test.py
@time:2024/09/19
"""
import torch
from torch import nn
from torchvision import transforms
import torch.utils.data as Data
import matplotlib.pyplot as plt
import numpy as np
from model import GoogLeNet, Inception
from PIL import Image
# 推理单张图片
if __name__ == '__main__':
# 加载模型结构
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = GoogLeNet(Inception).to(device)
# 加载模型权重
model.load_state_dict(torch.load('02框架学习\\04经典卷积神经网络与实战-pao哥\\06_GoogLeNet_fruit\\best_model.pth', weights_only=True))
image = Image.open('02框架学习\\04经典卷积神经网络与实战-pao哥\\06_GoogLeNet_fruit\\dataset/predict/0.jpeg')
# 将图像转为tensor
transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])
image = transform(image)
# 增加一批次维度
image = image.unsqueeze(0)
print(image.shape)
# 推理
model.eval()
with torch.no_grad():
image = image.to(device)
output = model(image)
output = torch.argmax(output, dim=1) # 输出最大值的索引 dim=1表示按行取最大值
classes = [
'Apple',
'Orange',
'Avocado',
'Kiwi',
'Mango',
'Pineapple',
'Strawberries',
'Banana',
'Cherry',
'Watermelon']
print(f'预测结果为:{classes[output.item()]}')