查阅该文件前 先看关于yolov5目标检测的文章 -- http://t.csdn.cn/iOR00
需要源码文件的话,后台私信,有看到就发。
介绍:
YOLOv3(You Only Look Once version 3,有时也缩写为YOLO3)是目标检测模型中的一种,由Joseph Redmon等人于2018年提出。它通过一次前向传递预测图像中的所有对象,因此可以比其他检测模型更快地处理大量数据。
YOLOv3使用了Darknet-53网络作为特征提取器,该网络具有53层卷积层和池化层。与早期版本相比,YOLOv3显著提高了准确度,同时在速度方面也有所改进。此外,YOLOv3还包含了Multi-Scale Training(多尺度训练)和类别感知的锚框(anchor)策略,这些方法都有助于提高其检测精度和鲁棒性。
YOLOv3目前已经成为最流行的目标检测模型之一,在工业和学术界都得到了广泛应用。
yolov3-tiny.pt
`yolov3-tiny.pt` 是一个预训练的权重模型文件,用于目标检测任务。它是 YOLOv3-tiny 模型的权重文件。YOLOv3-tiny 是 YOLOv3 的一个小型版本,包含了更少的卷积层和参数,因此速度更快但精度较低。该权重模型文件可以用于检测图像或视频中的多个对象,并输出对象的类别、位置和置信度等信息。对于每个检测到的对象,模型可以返回一个矩形框来表示物体的位置,以及该物体属于哪个类别。该模型可以应用于各种领域,如人脸识别、交通控制、智能安防、工业质检等。使用该权重文件需要一个相应的深度学习框架,如PyTorch、TensorFlow等,并且需要一些基本编程知识。通过加载该权重文件并在输入图片或视频帧上进行前向推断,即可实现目标检测的功能。
如何使用yolov3进行训练:
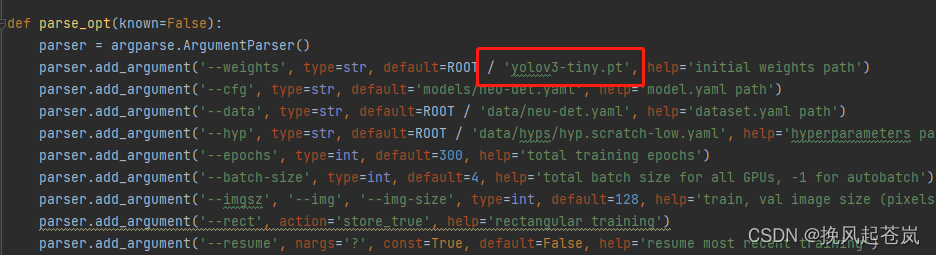
大致方法同yolov5训练方法一样
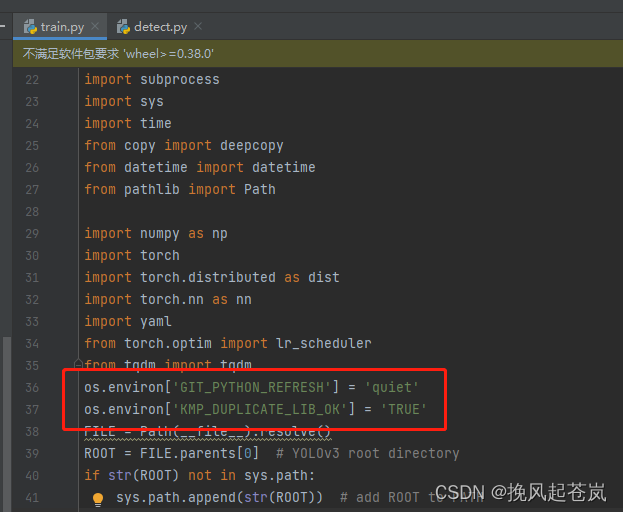
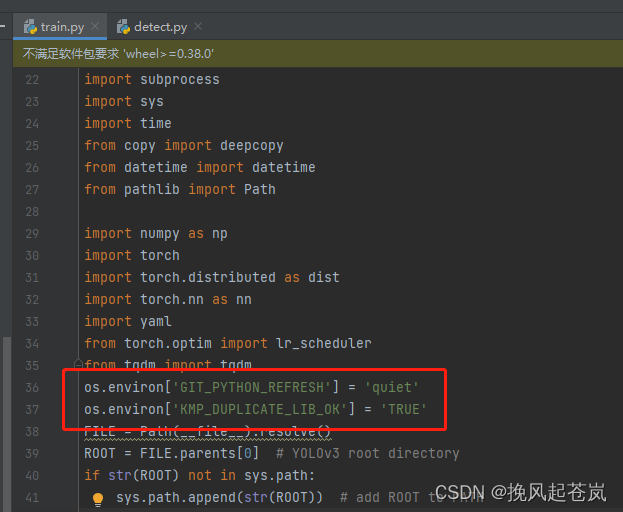
选定训练权重模型为yolov3-tiny.pt,其余操作一致,如果遇到GIT变量环境问题
可添加如下代码
os.environ['GIT_PYTHON_REFRESH'] = 'quiet'
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
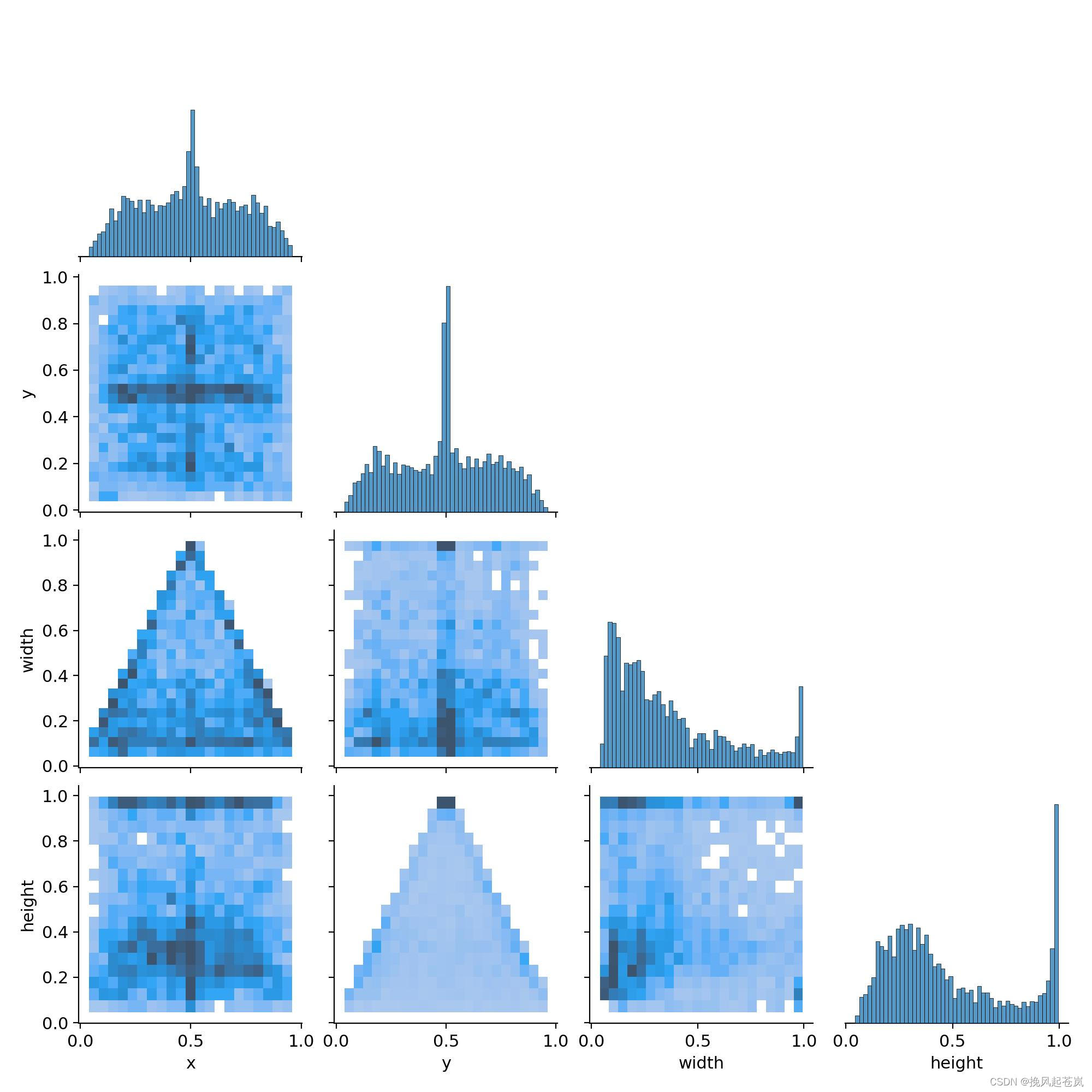
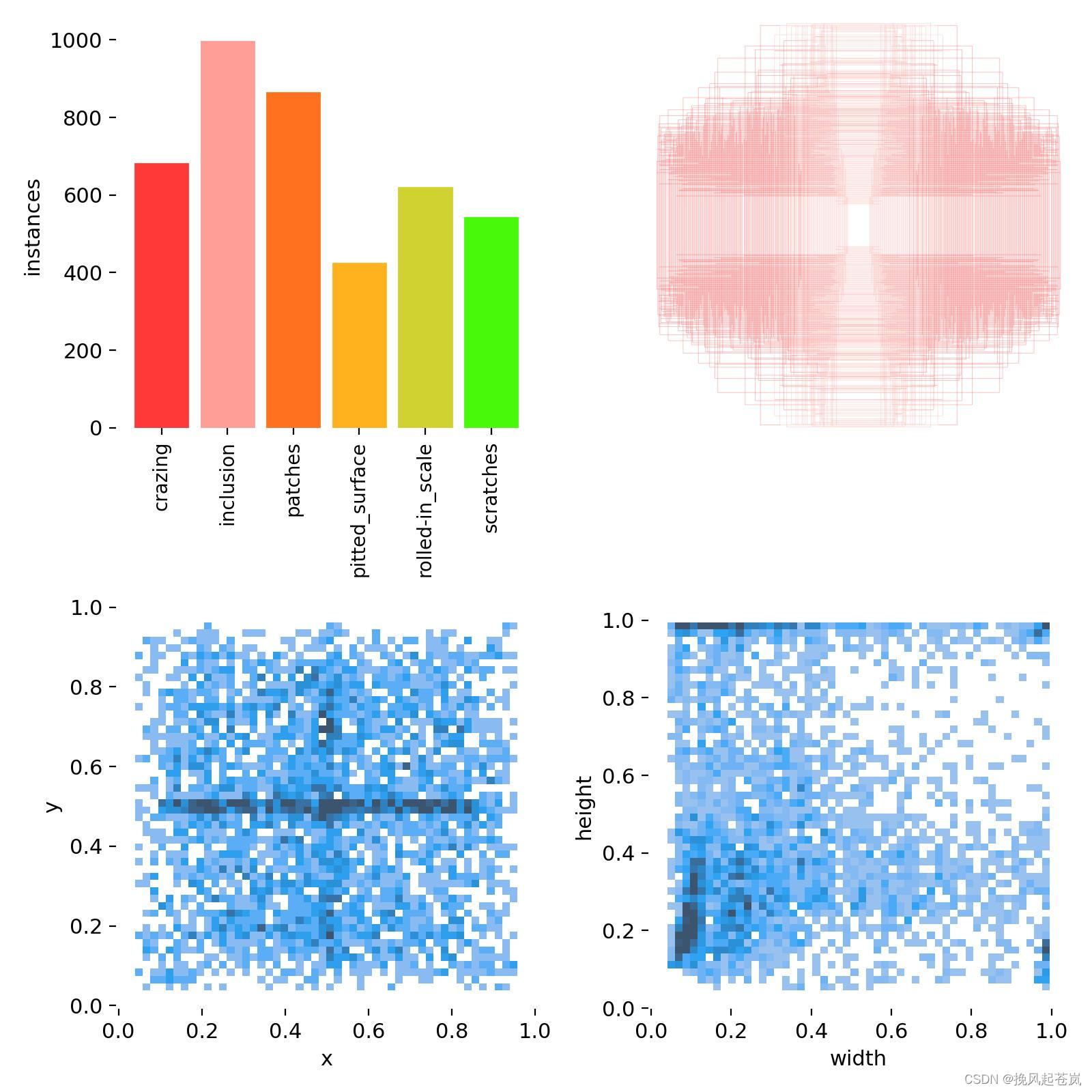
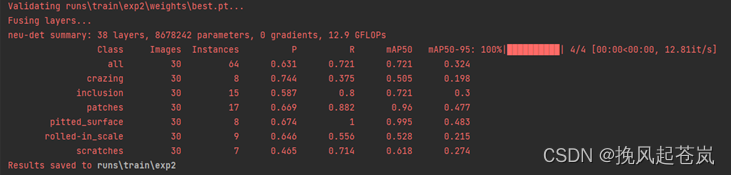
以下是训练了300次后模型得到的数据,结果还不错。
再使用训练得到的最好模型进行预测,看到得到的图像如何

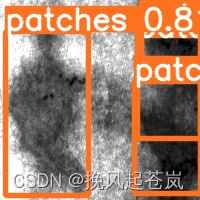
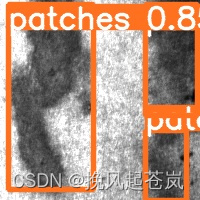















产品缺陷的大致轮廓都基本标出。
以下是训练过程中产生的一些信息