目录
前言
分布式理论
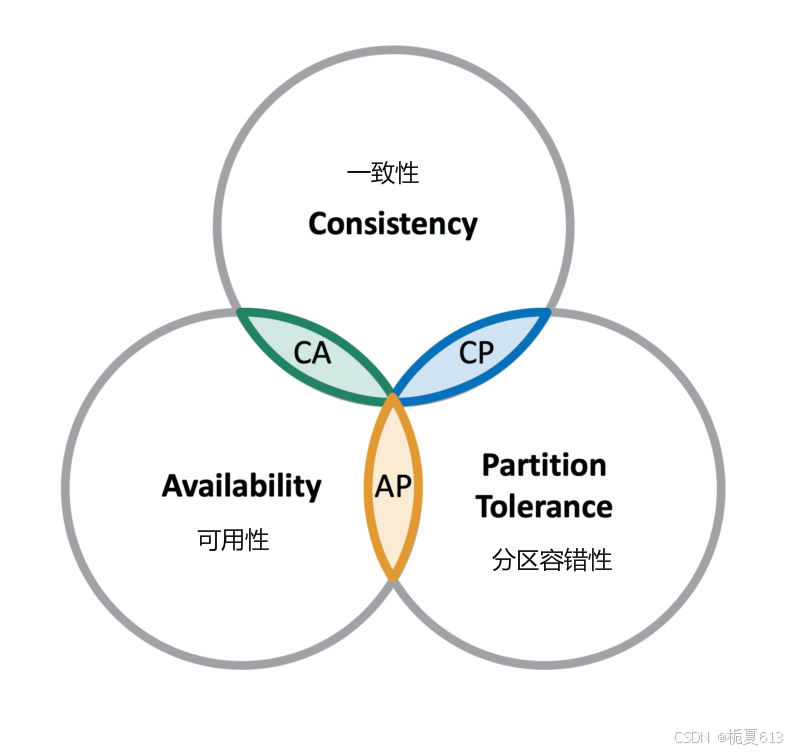
CAP 理论
CAP 理论指出对于一个分布式计算系统来说,不可能同时满足以下三点:
-
一致性:在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的特性,等同于所有节点访问同一份最新的数据副本。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
-
可用性:每次请求都能获取到正确的响应,但是不保证获取的数据为最新数据。
-
分区容错性:分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
在这三个基本需求中,最多只能同时满足其中的两项,P 是必须的,因此只能在 CP 和 AP 中选择。
BASE理论
BASE 是 Basically Available(基本可用)、Soft-state(软状态) 和 Eventually Consistent(最终一致性) 三个短语的缩写。
-
基本可用:在分布式系统出现故障,允许损失部分可用性(服务降级、页面降级)。
-
软状态:允许分布式系统出现中间状态。而且中间状态不影响系统的可用性。这里的中间状态是指不同的 data replication(数据备份节点)之间的数据更新可以出现延时的最终一致性。
-
最终一致性:data replications 经过一段时间达到一致性。
BASE 理论是对 CAP 中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
概述
ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。
ZooKeeper 的架构通过冗余服务实现高可用性。
Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
zookeeper 基于CAP理论,保证的是 CP。
特点
-
Zookeeper是由一个领导者(Leader),多个跟随者(Follower)组成的集群。
-
集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
-
全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
-
更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。
-
数据更新原子性,一次数据更新要么成功,要么失败。
-
实时性,在一定时间范围内,Client能读到最新数据。
数据结构
zookeeper 会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统:
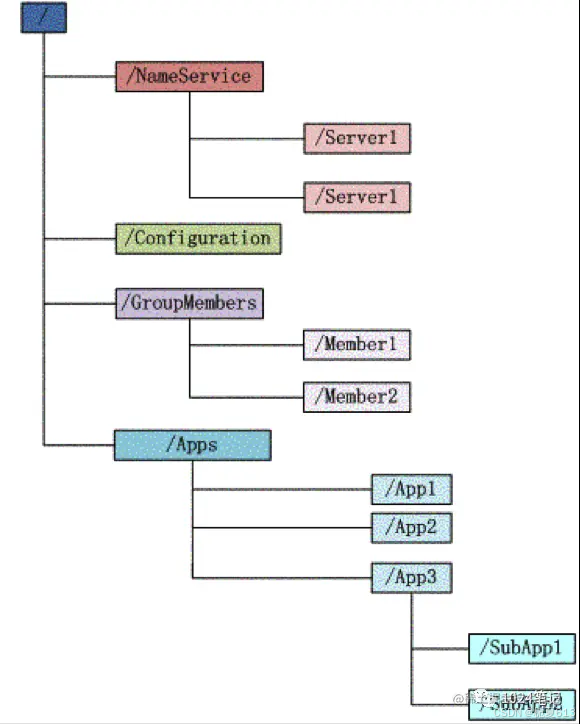
上图中的树形结构中的每个节点(目录项),比如NameService 都被称作为 znode(目录节点)。znode通过路径引用,路径必须是绝对的,因此他们必须由斜杠字符来开头。除此以外,它们必须是唯一的,也就是说每一个路径只有一个表示,因此这些路径不能改变。在zookeeper中,路径由Unicode字符串组成,并且有一些限制。字符串"/ZooKeeper"用以保存管理信息,比如关键配额信息。
znode同时具有文件和目录两种特点。既像文件一样维护着数据、元信息、访问控制列表、时间戳等数据结构,又可以像目录一样可以作为路径标识的一部分,能够自由的增加、删除znode。
每个znode都是由三部分组成:
-
stat:此为状态信息, 描述该znode的版本, 权限等信息
-
data:与该znode关联的数据
-
children:该znode下的子节点
需要注意的是同一个节点下的子节点名称不能相同,且命名是有规范的,它的路径是没有相对路径的概念的,都是绝对路径,任何开始都以"/"开始,最后就是,它存放数据的大小是有限制的。
应用场景
-
统一命名服务
-
命名服务是指通过指定的名字来获取资源或者服务的地址,利用zk创建一个全`局的路径,这个路径就可以作为一个名字,例如dubbo使用zk为其命名服务,维护全局的服务地址列表:
-
-
统一配置管理
-
使用zookeeper充当配置中心,统一管理一组服务的配置文件,如早期的kafka就使用zookeeper充当注册及配置中心;
配置信息可以直接写入ZooKeeper上的一个Znode,各个客户端服务器监听这个Znode。一旦Znode中的数据被修改,ZooKeeper将通知各个客户端服务器来拉取配置更新
-
-
统一集群管理
-
节点一旦注册到zookeeper,则zookeeper可以实现实时监控节点状态变化:
-
将节点信息写入ZooKeeper上的一个ZNode。
-
监听这个ZNode可获取它的实时状态变化。
-
-
服务节点动态上下线
-
负载均衡
服务器选取机制
zookeeper的角色
-
leader:处理所有的事务请求(写请求),也可以处理读请求;一个集群中只能有一个leader
-
follower:只能处理读请求,同时作为Leader的候选节点;如果Leader宕机,follower要参与新的leader选举,有可能成为新的Leader节点
-
observer:只能处理读请求,不能参与选举
zab协议
zab协议是为zookeeper专门设计的一种支持崩溃恢复的原子广播协议,是zk保证数据一致性的核心算法。与paxos和raft一样,是一种通用的分布式一致性共识算法。
zab协议可分为如下四个阶段:
-
leader election(选举阶段):节点 一开始都处于选举阶段,只要有一个节点得到超过半数的选票,它就可以当选为准leader
-
discovery(发现阶段):followers和准leader通信,同步followers最近接收到的事务提议;
-
synchronization(同步阶段):利用leader前一阶段获得的最新提议历史,同步集群中的所有副本。同步完成之后准Leader才会成为真正的leader
-
Broadcast(广播阶段):zk正式对外提供事务服务,leader可以进行消息广播,如果有新节点加入,也会对新节点进行同步
相关术语
-
SID:服务器Id,用来唯一标识 一台zk集群中的机器,每台机器不能重复,和myid一致
-
ZXID:事务id,用来标识 一次服务器状态的变更。在某一时刻,集群中的每台机器的zxid值不一定完全一致,这和zk服务器对于客户端“更新请求”的处理逻辑有关。
-
Epoch:每个leader任期的代号 。没有leader时同一轮投票过程中的逻辑时钟值是相同的,每投完一次这个数据就会增加
选举流程
首次选举
-
服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
-
服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING。
-
服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
-
服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
-
服务器5启动,同4一样当小弟
非首次选举
有leader的情况下:
-
当有服务器试图选举时,会被告知当前集群的leader信息,该服务器直接和leader建议连接即可
leader挂掉的情况:
-
假设zk由5台服务器组成,sid分别为1、2、3、4、5,zxid分别为8、8、8、7、7,并且此时sid为3的服务器是leader,某一刻,3和5同时挂掉,因此开始leader选举:
-
sid为1、2、4的机器投票情况:
-
服务器 epoch zxid sid 1 1 8 1 2 1 8 2 4 1 7 4 -
选举leader的规则 如下:
-
epoch大的直接胜出
-
epoch相同,zxid大的胜出
-
zxid相同,sid大的胜出
-
-
所以最终的leader是服务器2
部署
主机准备
| PORT | ROLE |
|---|---|
| 192.168.142.155 | slave02 |
| 192.168.142.156 | slave |
| 192.168.142.157 | master |
| 192.168.142.158 | slave03 |
安装 java
apt install -y openjdk-8-jdk配置环境变量
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
执行配置文件
. /etc/profile配置 hosts 文件
配置 hosts 文件,每台主机上都要配置
192.168.142.155 slave02
192.168.142.156 slave
192.168.142.157 master
192.168.142.158 slave03docker-compose.yml
四台主机的 docker-compose.yml 文件
services:
zookeeper:
image: zookeeper:3.7
container_name: zookeeper_master
restart: always
ports:
- "2181:2181"
- "2888:2888"
- "3888:3888"
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=master:2888:3888;2181 server.2=slave:2888:3888;2181 server.3=slave02:2888:3888;2181 server.4=slave03:2888:3888;2181
networks:
zookeeper_net:
aliases:
- master
networks:
zookeeper_net:
driver: bridge
几台主机的 docker-compose.yml 都大差不差,机台主机只有这几个地方需要修改
# master
ZOO_MY_ID: 1
# slave
ZOO_MY_ID: 2
# slave02
ZOO_MY_ID: 3
# slave03
ZOO_MY_ID: 4 networks:
zookeeper_net:
aliases:
- master
networks:
zookeeper_net:
aliases:
- slave
networks:
zookeeper_net:
aliases:
- slave02
networks:
zookeeper_net:
aliases:
- slave03 container_name: zookeeper_master
container_name: zookeeper_slave
container_name: zookeeper_slave02
container_name: zookeeper_slave03启动
docker-compose up -d查看集群状态
docker exec -it zookeeper_master /bin/bash
bin/zkServer.sh status
master
root@b3d69910d04d:/apache-zookeeper-3.7.2-bin# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
slave
root@slave:~# docker exec -it zookeeper_slave1 bash
root@02e82babb141:/apache-zookeeper-3.7.2-bin# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
slave02
root@slave02:~# docker exec -it zookeeper_slave2 bash
root@8007cd7a176d:/apache-zookeeper-3.7.2-bin# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
slave03
root@slave03:~# docker exec -it zookeeper_slave3 bash
root@38f7ea196a95:/apache-zookeeper-3.7.2-bin# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
关键信息
# master
Mode: follower
# slave
Mode: follower
# slave02
Mode: follower
# slave03
Mode: leader很明显,这个时候 slave03 是 lader 其他的节点都是 follower
至此,集群部署完成
另外
如果遇到这种问题
EndOfStreamException: Unable to read additional data from server sessionid 0x0, likely server has closed socket at org.apache.zookeeper.ClientCnxnSocketNIO.doIO(ClientCnxnSocketNIO.java:77) at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:350) at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1289)这种问题一般都出现在部署的是奇数个数的 zk 集群的情况下,最后一台在启动时日志中会出现这种报错
解决办法
https://blog.csdn.net/weixin_56321113/article/details/126236959