我们使用Spark主要是用于做离线数仓,虽然Spark也可以做实时的,但是我们基本不用
实时数仓使用的是flink
spark可以做数仓,数仓中也可以分层。 离线场景:实现离线数据仓库中的数据清洗、数据分析、即席查询等应用 实时场景:实现实时数据流数据处理,相对而言功能和性能不是特别的完善,工作中建议使用Flink替代。 即席查询:即席查询类似于即兴发挥。普通查询类似于带着稿子发言。不管是普通查询还是即席查询,写的sql语句都是一样的,只是一个sql语句是固定的,写死的,类似于存储过程。用户自己随即查询的sql语句就是即席查询。
spark分为5个模式,
-
本地模式 (local)
-
standlone模式
-
Yarn模式 (工作中常用)
本地模式:Local:一般用于做测试,验证代码逻辑,不是分布式运行,只会启动1个进程来运行所有任务。 集群模式:Cluster:一般用于生产环境,用于实现PySpark程序的分布式的运行 Standalone:Spark自带的分布式资源平台,功能类似于YARN YARN:Spark on YARN,将Spark程序提交给YARN来运行,工作中主要使用的模式 Mesos:类似于YARN,国外见得多,国内基本见不到 K8s:基于分布式容器的资源管理平台,运维层面的工具。 解释:Spark是一个分布式的分析引擎,所以它部署的时候是分布式的,有用主节点,从节点这些内容。Standalone使用的是Spark自带的分布式资源平台,但是假如一个公司已经有Yarn分析平台了,就没必要再搭建spark分析平台,浪费资源。 学习过程中:本地模式 --> Standalone --> YARN ,将来spark在yarn上跑。
spark为什么会比MR任务快
-
MR任务走的是磁盘,计算效率较低
Spark任务走的是内存
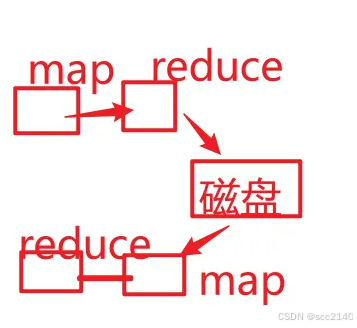
-
MR任务的进程级别的, 进程启动和销毁是比较耗时的
Spark任务是线程级别的
Spark支持DAG(有向无环图),一个Spark程序中的过程是不固定,由代码 所决定。
各大计算引擎的对比
Impala:集成Hive实现数据分析,优点是性能最好,缺点数据接口比较少,只支持Hive和Hbase数据源 。 是一个基于CDH的一个软件,Impala 能写sql,它写出来的sql,叫 Impala SQL (大部分跟我们普通的sql没啥区别) ,操作hive或者hbase 速度非常快!
Presto:集成Hive实现数据分析,优点性能适中,支持数据源非常广泛,与大数据接口兼容性比较差 。Presto也可以写sql,只是写的sql叫做 Presto SQL (大部分跟我们普通的sql没啥区别) ,特点:可以跨数据源。比如mysql的表可以和oracle中的一个表关联查询。
SparkSQL:集成Hive实现数据分析,优点功能非常全面、开发接口多,学习成本低,缺点实时计算不够完善。实时计算交给了Flink。
简单粗暴的理解:Impala和Presto 都可以进行大数据分析,但是数据量达到一定级别,就不太行,还得是SparkSQL。
复习软连接:
创建一个spark软连接
ln -s spark-local spark
当在不同目录使用相同文件时,可以使用ln命令链接,避免了重复占用磁盘空间。 例如:ln -s /bin/less /usr/local/bin/less 需要注意:第一,ln命令会保持每一处链接文件的同步性,也就是说,不论你改动了哪一处,其它的文件都会发生相同的变化; 第二,ln的链接分软链接和硬链接 软链接: ln -s ** **,它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间 硬链接: ln ** **,没有参数-s, 它会在你选定的位置上生成一个和源文件大小相同的文件 无论是软链接还是硬链接,文件都保持同步变化
复习一下zxvf各个字母的作用
z :表示 tar 包是被 gzip 压缩过的 (后缀是.tar.gz),所以解压时需要用 gunzip 解压 (.tar不需要) x :表示 从 tar 包中把文件提取出来 v :表示 显示打包过程详细信息 f :指定被处理的文件是什么
Spark本地模式的安装
由于使用spark 需要用到python3的环境(集群中自带的有python2的环境),所以我们还需要在集群上部署python环境
这里我们不直接安装python的环境,而是通过Anaconda 安装 ,因为这个软件不仅有python还有其他的功能,比单纯安装python功能要强大。
安装这个软件的另一个好处:具有资源环境隔离功能,方便基于不同版本不同环境进行测试开发
安装Anaconda:
# 添加执行权限
chmod u+x Anaconda3-2021.05-Linux-x86_64.sh
# 执行
sh ./Anaconda3-2021.05-Linux-x86_64.sh
# 过程
#第一次:【直接回车,然后按q】 【或者按多次空格即可】
Please, press ENTER to continue
>>>
#第二次:【输入yes】
Do you accept the license terms? [yes|no]
[no] >>> yes
#第三次:【输入解压路径:/opt/installs/anaconda3】(指定你的Anaconda3的安装路径)
[/root/anaconda3] >>> /opt/installs/anaconda3
#第四次:【输入yes,是否在用户的.bashrc文件中初始化
Anaconda3的相关内容】
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
[no] >>> yes
# 刷新环境变量
source /root/.bashrc
# 激活虚拟环境,如果需要关闭就使用:conda deactivate
conda activate在base环境中,我们的python环境是3版本的,而在默认中则是2版本的
配置环境变量(可有可无)
# 编辑环境变量
vi /etc/profile
# 添加以下内容
# Anaconda Home
export ANACONDA_HOME=/opt/installs/anaconda3
export PATH=$PATH:$ANACONDA_HOME/bin刷新环境变量,并且做一个软链接
# 刷新环境变量
source /etc/profile
小结:实现Linux机器上使用Anaconda部署Python
3:单机部署:Spark Python Shell
目标:掌握Spark Shell的基本使用
实施
功能:提供一个交互式的命令行,用于测试开发Spark的程序代码
Spark的客户端bin目录下:提供了多个测试工具客户端
启动
核心
# 创建软连接
ln -s /opt/installs/anaconda3/bin/python3 /usr/bin/python3
# 验证
echo $ANACONDA_HOME案例:WordCount需求及分析(比较重要)
实现思路:
读取文件,将文件的数据变成分布式集合数据
先过滤,将空行过滤掉
将每一行多个单词转换为一行一个单词
spark
spark
hue
hbase
hbase
hue
hue
hadoop
将每个单词转换成KeyValue的二元组(word,1)
spark 1
spark 1
hue 1
hbase 1
hbase 1
hue 1
hue 1
hadoop 1
spark 1
按照单词分组聚合
('hadoop', [1,1,1,1,1,1])
('hive', [1,1,1])
('hue', [1,1,1,1,1,1,1,1,1])
聚合:
('hadoop', 7)
('hive', 3)
('hue', 9)
.....实现步骤:
map:一对一函数
flatMap:将一行多个元素转换一行一个元素,类似于explode
filter:过滤数据
foreach:循环取出每个元素做打印
1、读取数据
# 将这个文件读取到Spark中,变成一个分布式列表对象
fileRdd = sc.textFile("/home/data.txt")
# 输出这个数据一共有多少行
fileRdd.count()
# 输出这个数据前3行的内容
fileRdd.take(3)
2、过滤空行
filterRdd = fileRdd.filter(lambda line :len(line.strip()) > 0)
filterRdd.count()
# 输出这个数据前3行的内容
filterRdd.take(3)
3、将每一行多个单词转换为一行一个单词
# 将每条数据中一行多个单词,变成一行一个单词
# [["hello","world"],["spark","hadoop"]] ==> ["hello","world","spark","hadoop"]
# 三体科幻电影中的二向箔
wordRdd = filterRdd.flatMap(lambda line :line.strip().split(" "))
#其实split() 就等于 split(" ") 默认就是切空格
wordRdd.count()
wordRdd.take(10)
4、将一个单词变为一个元组
tupleRdd = wordRdd.map(lambda word : (word,1))
tupleRdd.take(10)
5、按照单词进行分组聚合
# 按照Key进行分组并且进行聚合
# tmp 是前面计算的总和,item是本次需要计算的值 10,1 == 11,下一次 tem = 11 ,item = 1
rsRdd = tupleRdd.reduceByKey(lambda tmp,item : tmp+item)
6、循环遍历
rsRdd.foreach(lambda kv : print(kv))
7、保存到本地
rsRdd.saveAsTextFile("/home/wcoutput")还可以这样写: 把所有需要的算子连起来用
# 读取数据
inputRdd = sc.textFile("/home/data.txt")
# 转换数据
rsRdd = inputRdd.filter(lambda line : len(line.strip())> 0) .flatMap(lambda line :line.strip().split(r" ")).map(lambda word : (word,1)).reduceByKey(lambda tmp,item :tmp+item)
# 保存结果
rsRdd.saveAsTextFile("/home/wcoutput2")